Harjoitus: SQL- ja spark-poolien integrointi Azure Synapse Analyticsissa
Seuraavassa harjoituksessa tutkimme SQL- ja Apache Spark -poolien integrointia Azure Synapse Analyticsiin.
SQL- ja Apache Spark -varantojen integrointi Azure Synapse Analyticsissa
Haluat kirjoittaa erilliseen SQL-varantoon sen jälkeen, kun olet suorittanut tietotekniikkatehtäviä Sparkissa, ja viitata sitten SQL-varannon tietoihin lähteenä liittymistä varten Apache Spark DataFrameihin, jotka sisältävät tietoja muista tiedostoista.
Päätät käyttää Azure Synapse Apache Spark to Synapse SQL -liitintä tietojen tehokkaaseen siirtämiseen Spark-poolien ja SQL-poolien välillä Azure Synapse.
Tietojen siirtäminen Apache Spark -poolien ja SQL-poolien välillä voidaan tehdä JavaDataBaseConnectivityn (JDBC) avulla. Kuitenkin, kun otetaan huomioon kaksi hajautettua järjestelmää, kuten Apache Spark ja SQL-poolit, JDBC on yleensä pullonkaula sarjatiedonsiirrossa.
Azure Synapse Apache Spark -pooli Synapse SQL -liittimeen on tietolähteen toteutus Apache Sparkille. Se käyttää Azure Data Lake Storage Gen2:ta ja PolyBasea SQL-pooleissa tietojen siirtämiseksi tehokkaasti Spark-klusterin ja Synapse SQL -esiintymän välillä.
Jos haluamme käyttää Apache Spark -poolia Synapse SQL -liittimeen (
sqlanalytics), yksi vaihtoehto on luoda väliaikainen näkymä tiedoista DataFramessa. Suorita alla oleva koodi uudessa solussa luodaksesi näkymän nimeltätop_purchases:# Create a temporary view for top purchases topPurchases.createOrReplaceTempView("top_purchases")Loimme uuden väliaikaisen näkymän aiemmin luomastamme
topPurchasestietokehyksestä, joka sisältää litistetyt JSON-käyttäjien ostotiedot.Meidän on suoritettava koodia, joka käyttää Apache Spark -varantoa Synapse SQL -yhdistimeen Scalassa. Tätä varten lisäämme
%%sparktaikuutta soluun. Suorita alla oleva koodi uudessa solussa luettavaksi näkymästätop_purchases:%%spark // Make sure the name of the SQL pool (SQLPool01 below) matches the name of your SQL pool. val df = spark.sqlContext.sql("select * from top_purchases") df.write.sqlanalytics("SQLPool01.wwi.TopPurchases", Constants.INTERNAL)Huomautus
Solun suorittaminen voi kestää yli minuutin. Jos olet suorittanut tämän komennon aiemmin, saat virheilmoituksen, jossa todetaan, että "On jo ja objekti nimetty..." koska taulukko on jo olemassa.
Kun solu on suoritettu, katsotaanpa SQL-poolitaulukoiden luetteloa varmistaaksemme, että taulukko on luotu onnistuneesti.
Jätä muistikirja auki ja siirry sitten tietokeskukseen (jos se ei ole vielä valittuna).
Valitse Työtila-välilehti(1), laajenna SQL-pooli, valitse kolme pistettä (...) taulukoissa (2) ja valitse Päivitä (3). Laajenna taulukko ja sarakkeet
wwi.TopPurchases(4).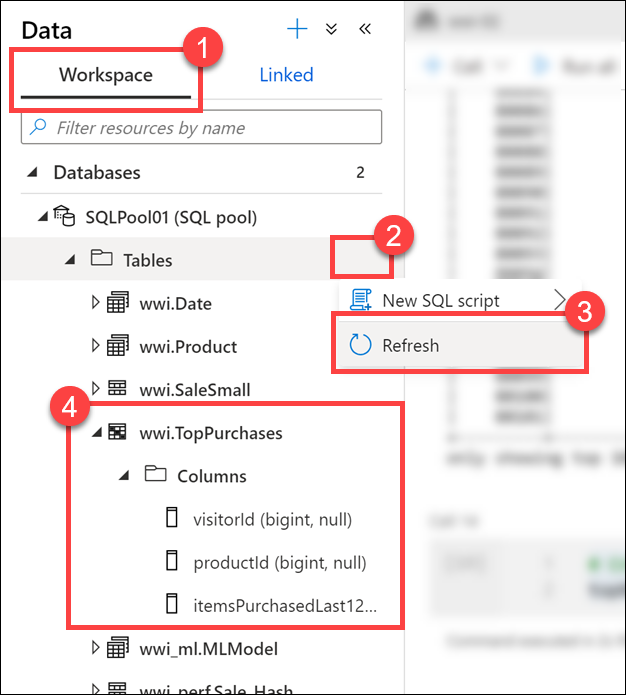
Kuten näet,
wwi.TopPurchasestaulukko luotiin meille automaattisesti Apache Spark DataFramen johdetun rakenteen perusteella. Apache Spark -pooli Synapse SQL -liittimeen vastasi taulukon luomisesta ja tietojen tehokkaasta lataamisesta siihen.Palaa muistikirjaan ja suorita alla oleva koodi uudessa solussa lukeaksesi myyntitiedot kaikista kansiossa olevista
sale-small/Year=2019/Quarter=Q4/Month=12/Parquet-tiedostoista:dfsales = spark.read.load('abfss://wwi-02@' + datalake + '.dfs.core.windows.net/sale-small/Year=2019/Quarter=Q4/Month=12/*/*.parquet', format='parquet') display(dfsales.limit(10))Huomautus
Tämän solun suorittaminen voi kestää yli 3 minuuttia.
Ensimmäiseen
datalakesoluun luomaamme muuttujaa käytetään tässä osana tiedostopolkua.
Vertaa yllä olevan solun tiedostopolkua ensimmäisen solun tiedostopolkuun. Tässä käytämme suhteellista polkua kaikkien joulukuun 2019 myyntitietojen lataamiseen Parquet-tiedostoista, jotka sijaitsevat kohteessa
sale-small, verrattuna vain 31. joulukuuta 2010 myyntitietoihin.Seuraavaksi ladataan
TopSalesaiemmin luomamme SQL-poolitaulukon tiedot uuteen Apache Spark DataFrameen ja liitetään ne sitten tähän uuteendfsalesDataFrameen. Tätä varten meidän on jälleen kerran käytettävä%%sparktaikuutta uudessa solussa, koska käytämme Apache Spark -varantoa Synapse SQL -liittimeen tietojen noutamiseen SQL-poolista. Sitten meidän on lisättävä DataFrame-sisältö uuteen väliaikaiseen näkymään, jotta voimme käyttää tietoja Pythonista.Suorita alla oleva koodi uudessa solussa luettavaksi SQL-poolitaulukosta
TopSalesja tallenna se väliaikaiseen näkymään:%%spark // Make sure the name of the SQL pool (SQLPool01 below) matches the name of your SQL pool. val df2 = spark.read.sqlanalytics("SQLPool01.wwi.TopPurchases") df2.createTempView("top_purchases_sql") df2.head(10)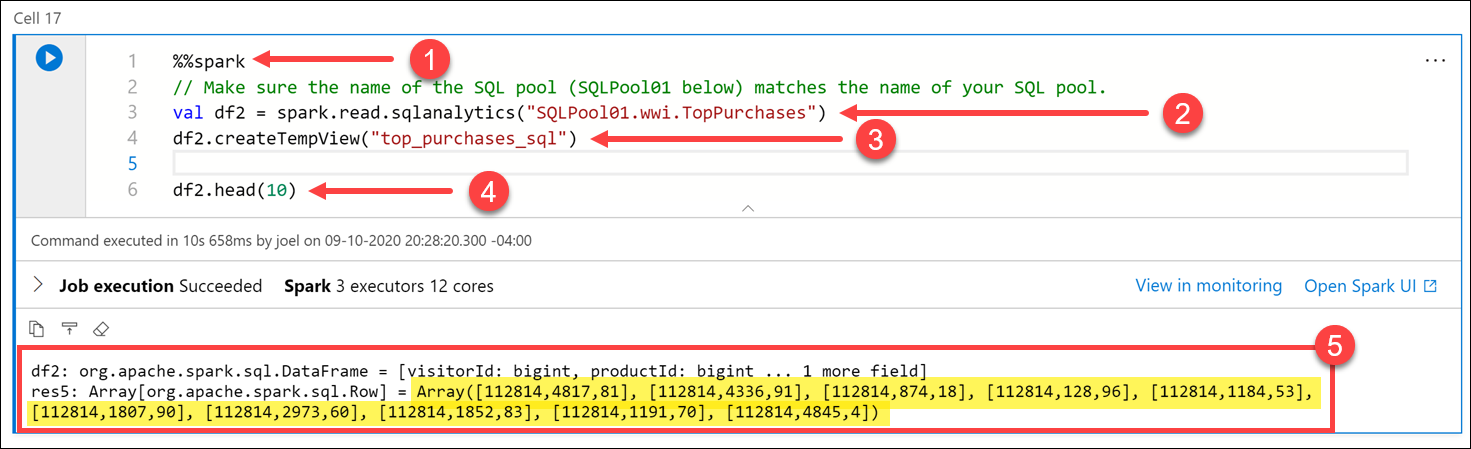
Solun kieli asetetaan
Scalakäyttämällä%%sparksolun yläreunassa olevaa taikuutta (1). Määritimme uuden muuttujan, jonka nimispark.read.sqlanalyticsondf2metodilla luotu uusi DataFrame, joka lukee SQL-poolin taulukostaTopPurchases(2). Sitten täytimme uuden väliaikaisen näkymän nimeltätop_purchases_sql(3). Lopuksi näytimme ensimmäiset 10 tietuetta rivillädf2.head(10))(4). Solutulosteessa näkyvät DataFrame-arvot (5).Suorita alla oleva koodi uudessa solussa luodaksesi uuden DataFrame-kehyksen Pythonissa väliaikaisesta näkymästä
top_purchases_sqlja näytä sitten ensimmäiset 10 tulosta:dfTopPurchasesFromSql = sqlContext.table("top_purchases_sql") display(dfTopPurchasesFromSql.limit(10))
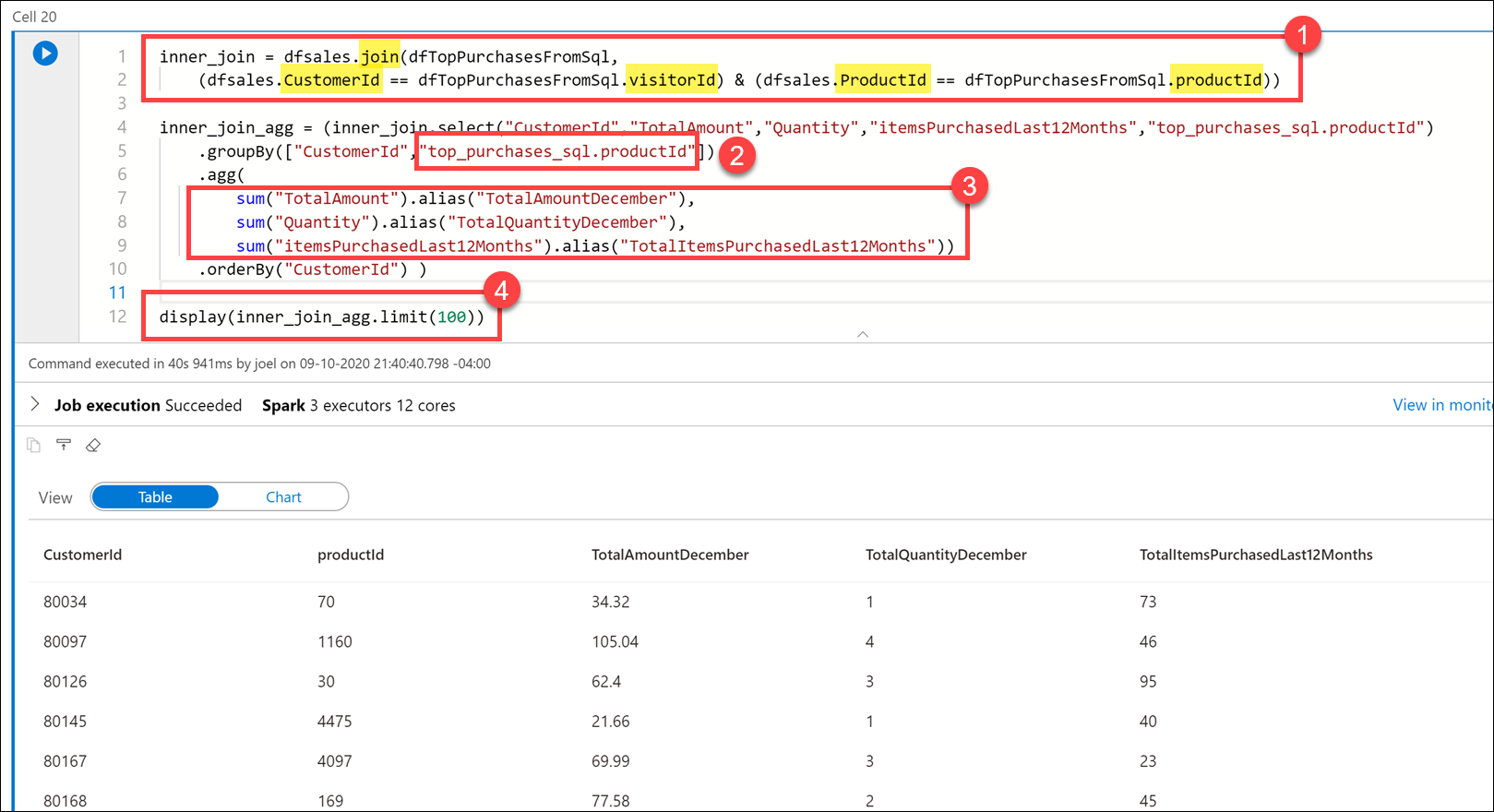
Suorita alla oleva koodi uudessa solussa liittääksesi tiedot Parquet-myyntitiedostoista ja SQL-poolista
TopPurchases:inner_join = dfsales.join(dfTopPurchasesFromSql, (dfsales.CustomerId == dfTopPurchasesFromSql.visitorId) & (dfsales.ProductId == dfTopPurchasesFromSql.productId)) inner_join_agg = (inner_join.select("CustomerId","TotalAmount","Quantity","itemsPurchasedLast12Months","top_purchases_sql.productId") .groupBy(["CustomerId","top_purchases_sql.productId"]) .agg( sum("TotalAmount").alias("TotalAmountDecember"), sum("Quantity").alias("TotalQuantityDecember"), sum("itemsPurchasedLast12Months").alias("TotalItemsPurchasedLast12Months")) .orderBy("CustomerId") ) display(inner_join_agg.limit(100))Kyselyssä yhdistimme
dfsalesja DataFramesdfTopPurchasesFromSql, jotka vastaavat jaCustomerId.ProductIdTämä liitos yhdistiTopPurchasesSQL-poolitaulukon tiedot joulukuun 2019 myynnin Parquet-tietoihin (1).Ryhmittelimme ja kenttien
ProductIdmukaanCustomerId. KoskaProductIdkentän nimi on moniselitteinen (se on molemmissa tietokehyksissä), meidän oli määriteltävä nimiProductIdkokonaan viittaamaan tietokehyksessäTopPurchasesolevaan nimeen (2).Sitten loimme koosteen, joka laski yhteen kuhunkin tuotteeseen joulukuussa käytetyn kokonaissumman, joulukuussa käytettyjen tuotenimikkeiden kokonaismäärän ja viimeisten 12 kuukauden aikana ostettujen tuotenimikkeiden kokonaismäärän (3).
Lopuksi näytimme yhdistetyt ja koostetut tiedot taulukkonäkymässä.
Voit vapaasti valita sarakeotsikot taulukkonäkymässä lajitellaksesi tulosjoukon.