Eri klusterointityyppien arvioiminen
Klusterointimallin harjoittaminen
Klusterointiin voi käyttää useita algoritmeja. Yksi yleisimmin käytetyistä algoritmeista on K-Means klusterointi, joka yksinkertaisimmassa muodossaan koostuu seuraavista vaiheista:
- Ominaisuuksien arvot on vectorisoitu määrittämään n-dimensiokoordinaatit (joissa n on ominaisuuksien määrä). Kukka-esimerkissä meillä on kaksi ominaisuutta: terälehtien määrä ja lehtien määrä. Ominaisuusvektorilla on siis kaksi koordinaatteja, joiden avulla voimme piirtää arvopisteet käsitteellisesti kaksiulotteiseen tilaan.
- Päätät, kuinka monta klusteria haluat käyttää kukkien ryhmittelyssä. Kutsu tätä arvoa k. Voit esimerkiksi luoda kolme klusteria käyttämällä k arvoa 3. Sitten k arvopisteet piirretään satunnaiskoordinaatteihin. Näistä pisteistä tulee kunkin klusterin keskipisteitä, joten niitä kutsutaan senroideja.
- Jokainen arvopiste (tässä tapauksessa kukka) määritetään sen lähimpään senttimetriin.
- Jokainen sentroidi siirretään sille määritettyjen arvopisteiden keskelle pisteiden välisen keskiarvoetäisyyden perusteella.
- Kun centroid on siirretty, arvopisteet voivat nyt olla lähempänä eri sentriidiä, joten arvopisteet määritetään uudelleen klustereita uuden lähimmän droidimäärän perusteella.
- Centroid liikkeen ja klusterin uudelleenkohdentamisvaiheet toistetaan, kunnes klusterit muuttuvat vakaiksi tai kunnes iteraatioiden ennalta määritetty suurin määrä saavutetaan.
Seuraava animaatio näyttää tämän prosessin:

Hierarkkinen klusterointi
Hierarkkinen klusterointi on toinen klusterointialgoritmin tyyppi, jossa klusterit itse kuuluvat suurempiin ryhmiin, jotka kuuluvat vielä suurempiin ryhmiin ja niin edelleen. Tuloksena saadaan se, että arvopisteet voivat olla eri tarkkuusasteissa sijaitsevia klustereita, joissa on suuri määrä hyvin pieniä ja tarkkoja ryhmiä, tai pieni määrä suurempia ryhmiä.
Jos esimerkiksi sovellamme klusteroitumista sanojen merkitykseen, voimme saada ryhmän, joka sisältää tunteisiin liittyviä adjektiiveja ('vihainen', 'onnellinen'' ja niin edelleen). Tämä ryhmä kuuluu ryhmään, joka sisältää kaikki ihmiseen liittyvät adjektiivit ('onnellinen', 'komea', 'nuori'), joka kuuluu vielä suurempaan ryhmään, joka sisältää kaikki adjektiivit ('onnellinen', 'vihreä'' 'komea', 'kova'' ja niin edelleen).
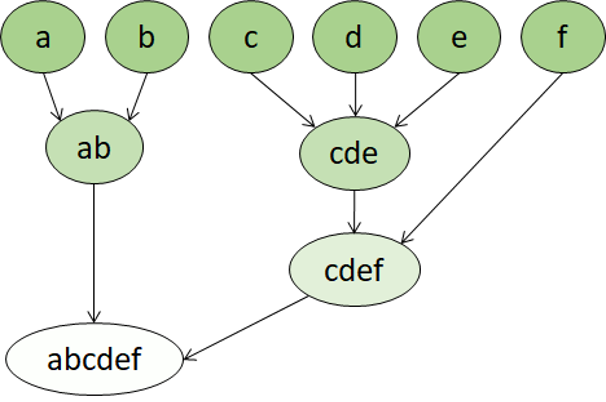
Hierarkkisen klusteroinnin avulla voit paitsi jakaa tietoja ryhmiin, myös ymmärtää näiden ryhmien välisiä suhteita. Hierarkkisen klusteroinnin suurin etu on se, että se ei edellytä etukäteen määritettävien klustereiden määrää. Ja se voi joskus tuottaa helpommin tulkittavia tuloksia kuin epähierarkkiset lähestymistavat. Tärkeimpiä haittapuolia on se, että näiden lähestymistapojen käsittely voi kestää kauemmin kuin yksinkertaisemmatkin lähestymistavat, eivätkä ne joskus sovellu suurille tietojoukoille.