Configurer un groupe de basculement pour Azure SQL Managed Instance
S’applique à :![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Cet article explique comment configurer un groupe de basculement pour Azure SQL Managed Instance à l’aide du portail Azure et d’Azure PowerShell.
Pour qu’un script PowerShell de bout en bout crée les deux instances dans un groupe de basculement, consultez Ajouter une instance à un groupe de basculement.
Prérequis
Prenez en compte les prérequis suivants :
- L’instance managée secondaire doit être vide, c’est-à-dire ne contenir aucune base de données utilisateur.
- Ces deux instances doivent avoir le même niveau de service et la même capacité de stockage. Bien que ce ne soit pas obligatoire, il est vivement recommandé que les deux instances aient une taille de calcul égale, pour s’assurer que l’instance secondaire puisse traiter durablement les modifications répliquées à partir de l’instance principale, y compris pendant les périodes de pic d’activité.
- La plage d’adresses IP pour le réseau virtuel de l’instance principale ne doit pas chevaucher la plage d’adresses du réseau virtuel pour l’instance gérée secondaire ou avec tout autre réseau virtuel appairé avec le réseau virtuel principal ou secondaire.
- Lorsque vous créez votre instance secondaire gérée, vous devez spécifier l’ID de zone DNS de l’instance primaire comme valeur du paramètre
DnsZonePartner. Si vous ne spécifiez pas une valeur pourDnsZonePartner, l’ID de zone est généré sous forme de chaîne aléatoire lors de la création de la première instance dans chaque réseau virtuel, et le même ID est attribué à toutes les autres instances dans le même sous-réseau. Une fois attribué, la zone DNS ne peut pas être modifiée. - Les règles des groupes de sécurité réseau (NSG) sur l’instance d’hébergement de sous-réseau doivent avoir le port 5022 (TCP) et la plage de ports 11000-11999 (TCP) ouverts pour les connexions entrantes et sortantes avec le sous-réseau hébergeant l’autre instance gérée. Cela s’applique aux deux sous-réseaux hébergeant les instances principale et secondaire.
- Le classement et le fuseau horaire de l’instance gérée secondaire doivent correspondre à ceux de l’instance gérée principale.
- Pour des raisons de performances, les instances gérées devraient être déployées dans des régions jumelées. Les instances managées résidant dans des régions jumelées géographiquement bénéficient d’une vitesse de géoréplication sensiblement supérieure à celle de la géoréplication entre régions non jumelées.
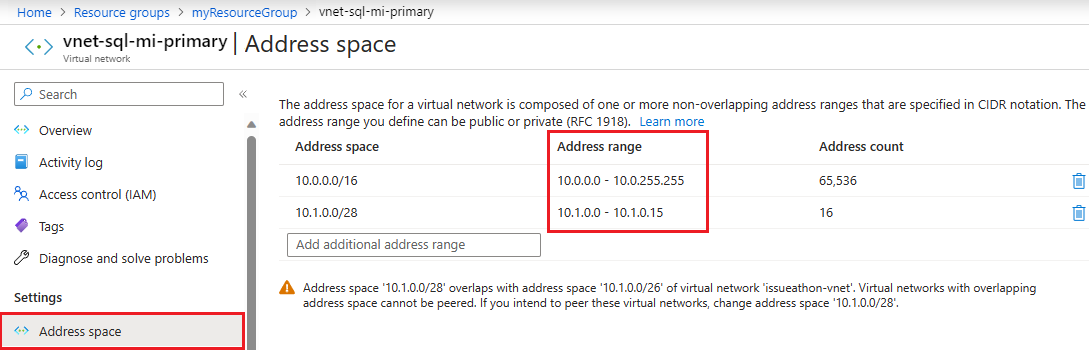
Plage d’espace d’adresses
Pour case activée l’espace d’adressage de l’instance principale, accédez à la ressource de réseau virtuel de l’instance principale et sélectionnez Espace d’adresses sous Paramètres. Vérifiez la plage sous Plage d’adresses :
Spécifier l’ID de la zone d’instance primaire
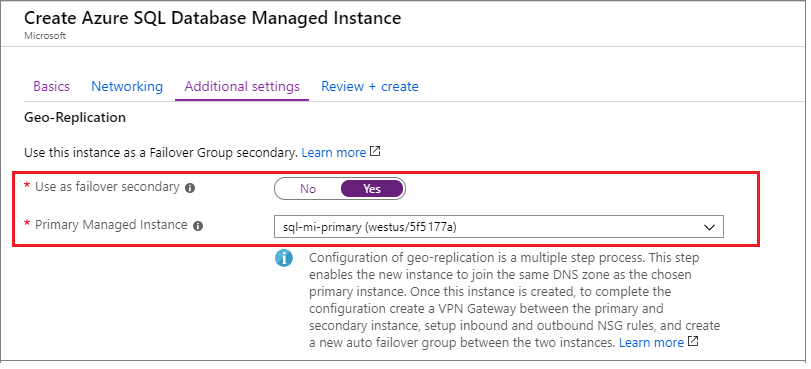
Lorsque vous créez votre instance secondaire, vous devez spécifier l’ID de zone de l’instance primaire comme DnsZonePartner.
Si vous créez votre instance secondaire dans le portail Azure, sous l’onglet Paramètres supplémentaires, sous Géoréplication, sélectionnez Oui à Utiliser comme basculement secondaire, puis sélectionnez l’instance primaire dans la liste déroulante :
Activation de la connectivité entre les instances
La connectivité entre les sous-réseaux de réseau virtuel hébergeant les instances principale et secondaire doit être établie pour un flux de trafic de géoréplication ininterrompu. Il existe plusieurs façons d’établir une connexion entre des instances gérées situées dans des régions Azure différentes :
- Appairage global de réseaux virtuels
- Azure ExpressRoute
- Passerelles VPN
Un appairage de réseaux virtuels est recommandé comme un moyen solide d’établir la connectivité entre les instances dans un groupe de basculement. L’appairage de réseaux virtuels fournit une connexion privée à faible latence et à bande passante élevée entre les réseaux virtuels appairés à l’aide de l’infrastructure principale de Microsoft. Aucun chiffrement supplémentaire et aucune connexion Internet publique, ni passerelle ne sont nécessaires pour que les réseaux virtuels d’homologues communiquent.
Important
Les autres façons de connecter des instances impliquant des appareils réseau supplémentaires peuvent compliquer la résolution des problèmes de connectivité ou de vitesse de réplication, ce qui peut nécessiter une implication active des administrateurs réseau et éventuellement prolonger considérablement le temps de résolution.
Quel que soit le mécanisme de connectivité, il existe des exigences qui doivent être remplies pour que le trafic de géoréplication soit acheminé :
- La table de route et les groupes de sécurité réseau attribués aux sous-réseaux d’instance managée ne sont pas partagés entre les deux réseaux virtuels appairés.
- Les règles du groupe de sécurité réseau (NSG) sur le sous-réseau hébergeant l’instance primaire autorisent :
- Le trafic entrant sur le port 5022 et la plage de ports 11000-11999 à partir du sous-réseau hébergeant l’instance secondaire.
- Le trafic sortant sur le port 5022 et plage de ports 11000-11999 vers le sous-réseau hébergeant l’instance secondaire.
- Les règles de groupe de sécurité réseau (NSG) sur le sous-réseau hébergeant l’instance secondaire autorisent :
- Le trafic entrant sur le port 5022 et la plage de ports 11000-11999 à partir du sous-réseau hébergeant l’instance principale.
- Le trafic sortant sur le port 5022 et plage de ports 11000-11999 vers le sous-réseau hébergeant l’instance principale.
- Les plages d’adresses IP des réseaux virtuels hébergeant les instances principale et secondaire ne doivent pas se chevaucher.
- Il n’existe aucun chevauchement indirect de la plage d’adresses IP entre les réseaux virtuels hébergeant les instances principale et secondaire ou les autres réseaux virtuels auxquels ils sont appairés via l’appairage de réseaux virtuels locaux ou par d’autres moyens.
En outre, si vous utilisez d’autres mécanismes pour fournir une connectivité entre les instances que le peering de réseaux virtuels globaux recommandé, vous devez vérifier ce qui suit :
- Aucun appareil réseau utilisé, comme les pare-feu ou les appliances virtuelles réseau (NVA), ne bloque pas le trafic sur les ports mentionnés précédemment.
- Le routage est correctement configuré et que le routage asymétrique est évité.
- Si vous déployez des groupes de basculement dans une topologie de réseau en étoile à travers la région, le trafic de réplication doit aller directement entre les deux sous-réseaux d’instances gérées plutôt que de passer par les réseaux en étoile. Cela vous aide à éviter les problèmes de connectivité et de vitesse de réplication.
- Dans le portail Azure, accédez à la ressource Réseau virtuel pour votre instance gérée principale.
- Sélectionnez Peerings sous Paramètres, puis sélectionnez + Ajouter.
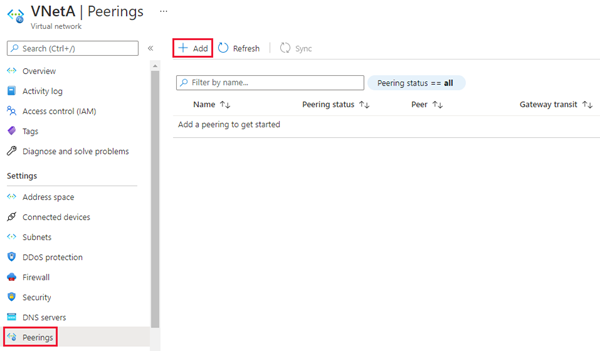
:
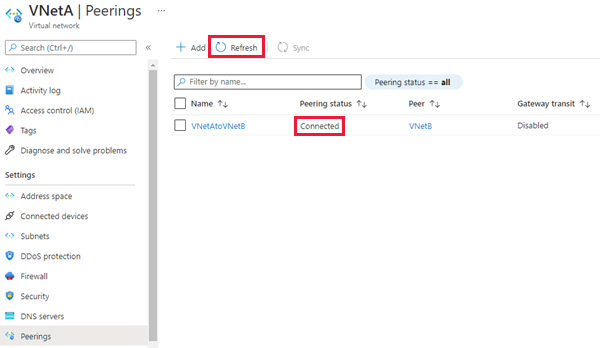
Paramètres Description Ce réseau virtuel Nom du lien de peering Le nom du peering doit être unique dans le réseau virtuel. Trafic vers le réseau virtuel distant Sélectionnez Autoriser (par défaut) pour activer la communication entre les deux réseaux virtuels via le flux VirtualNetworkpar défaut. L’activation de la communication entre les réseaux virtuels permet aux ressources connectées à ceux-ci de communiquer entre elles avec les mêmes bande passante et latence que si elles étaient connectées au même réseau virtuel. Toute communication entre les ressources des deux réseaux virtuels passe par le réseau privé Azure.Trafic transféré à partir du réseau virtuel distant Les options Autoriser (par défaut) et Bloquer fonctionnent pour ce tutoriel. Pour plus d’informations, consultez Créer un peering. Passerelle ou serveur de routes de réseau virtuel Sélectionnez Aucun. Pour plus d’informations sur les autres options disponibles, consultez Créer un peering. Réseau virtuel distant Nom du lien de peering Nom du même peering à utiliser dans l’instance secondaire d’hébergement de réseau virtuel. Modèle de déploiement de réseau virtuel Sélectionnez Resource Manager. Je connais mon ID de ressource Laissez cette case à cocher désactivée. Abonnement Sélectionnez l’abonnement Azure du réseau virtuel hébergeant l’instance secondaire avec laquelle vous souhaitez établir un peering. Réseau virtuel Sélectionnez le réseau virtuel hébergeant l’instance secondaire avec laquelle vous souhaitez établir un peering. Si le réseau virtuel est répertorié mais grisé, c’est peut-être parce que l’espace d’adressage du réseau virtuel chevauche l’espace d’adressage de ce réseau. Si les espaces d’adressage de réseaux virtuels se chevauchent, il n’est pas possible de les appairer. Trafic vers le réseau virtuel distant Sélectionnez Autoriser (par défaut). Trafic transféré à partir du réseau virtuel distant Les options Autoriser (par défaut) et Bloquer fonctionnent pour ce tutoriel. Pour plus d’informations, consultez Créer un peering. Passerelle ou serveur de routes de réseau virtuel Sélectionnez Aucun. Pour plus d’informations sur les autres options disponibles, consultez Créer un peering. Sélectionnez Ajouter pour configurer le peering (ou appairage) avec le réseau virtuel que vous avez sélectionné. Après quelques secondes, sélectionnez le bouton Actualiser pour que l’état de peering passe de Mise à jour à Connecté.
Créer le groupe de basculement
Créez le groupe de basculement pour vos instances gérées à l’aide du portail Azure ou de PowerShell.
Créez le groupe de basculement pour vos instances gérées SQL à l’aide du portail Azure ou de PowerShell.
Dans le menu de gauche du Portail Azure, sélectionnez Azure SQL. Si Azure SQL ne figure pas dans la liste, sélectionnez Tous les services, puis tapez « Azure SQL » dans la zone de recherche. (Facultatif) Sélectionnez l’étoile en regard d’Azure SQL pour l’ajouter en tant qu’élément favori dans le volet de navigation de gauche.
Sélectionnez l’instance managée principale que vous souhaitez ajouter au groupe de basculement.
Sous Paramètres, accédez à Groupes de basculement d'instance, puis choisissez Ajouter un groupe pour ouvrir la page de création de groupe de basculement d'instance.
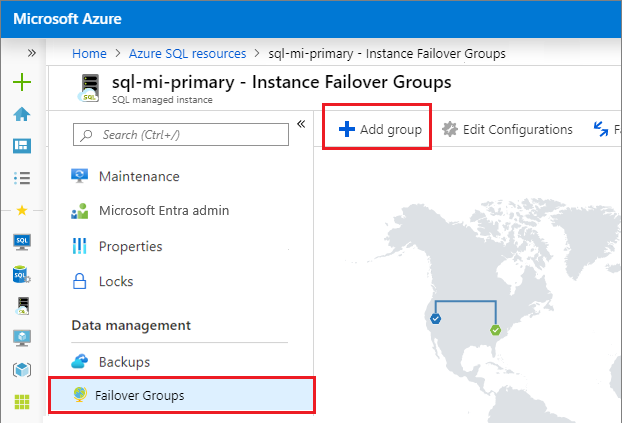
Dans la page Groupe de basculement d’instance, tapez le nom de votre groupe de basculement, puis choisissez l’instance managée secondaire dans la liste déroulante. Sélectionnez Créer pour créer votre groupe de basculement.
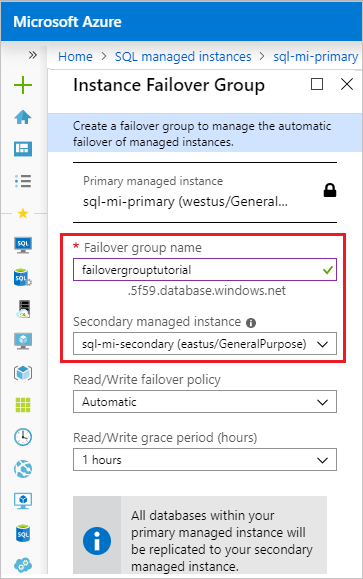
Une fois le déploiement du groupe de basculement terminé, vous serez redirigé vers la page Groupe de basculement.
Test de basculement
Testez le basculement de votre groupe de basculement à l’aide du portail Azure ou de PowerShell.
Testez le basculement de votre groupe de basculement à l’aide du portail Azure.
Accédez à votre instance gérée secondaire dans le Portail Azure et sélectionnez Groupes de basculement d’instance sous les paramètres.
Notez les instances gérées dans les rôles principal et secondaire.
Sélectionnez Basculement, puis cliquez sur Oui dans l’avertissement concernant les sessions TDS sur le point d’être déconnectées.
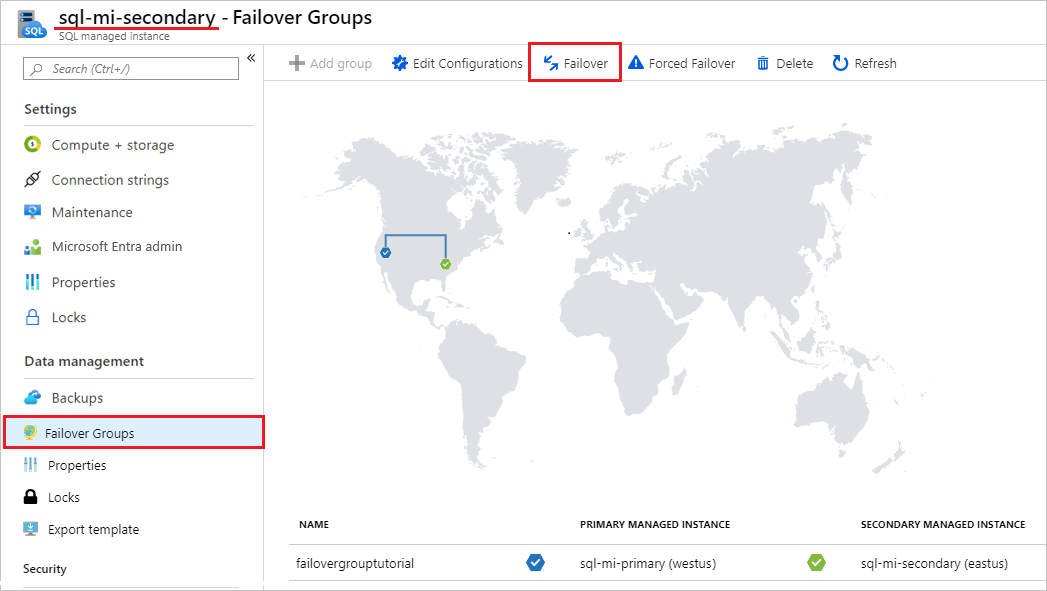
Notez les instances gérées dans les rôles principal et secondaire. Si le basculement a réussi, les deux instances doivent avoir échangé leur rôle.

Important
Si les rôles n’ont pas changé, vérifiez la connectivité entre les instances et les règles de groupe de sécurité réseau et de pare-feu associées. Ne passez à l’étape suivante qu’après la permutation des rôles.
- Accédez à la nouvelle instance managée secondaire et sélectionnez de nouveau Basculement pour rebasculer l’instance principale vers le rôle principal.
Localiser le point de terminaison de l’écouteur
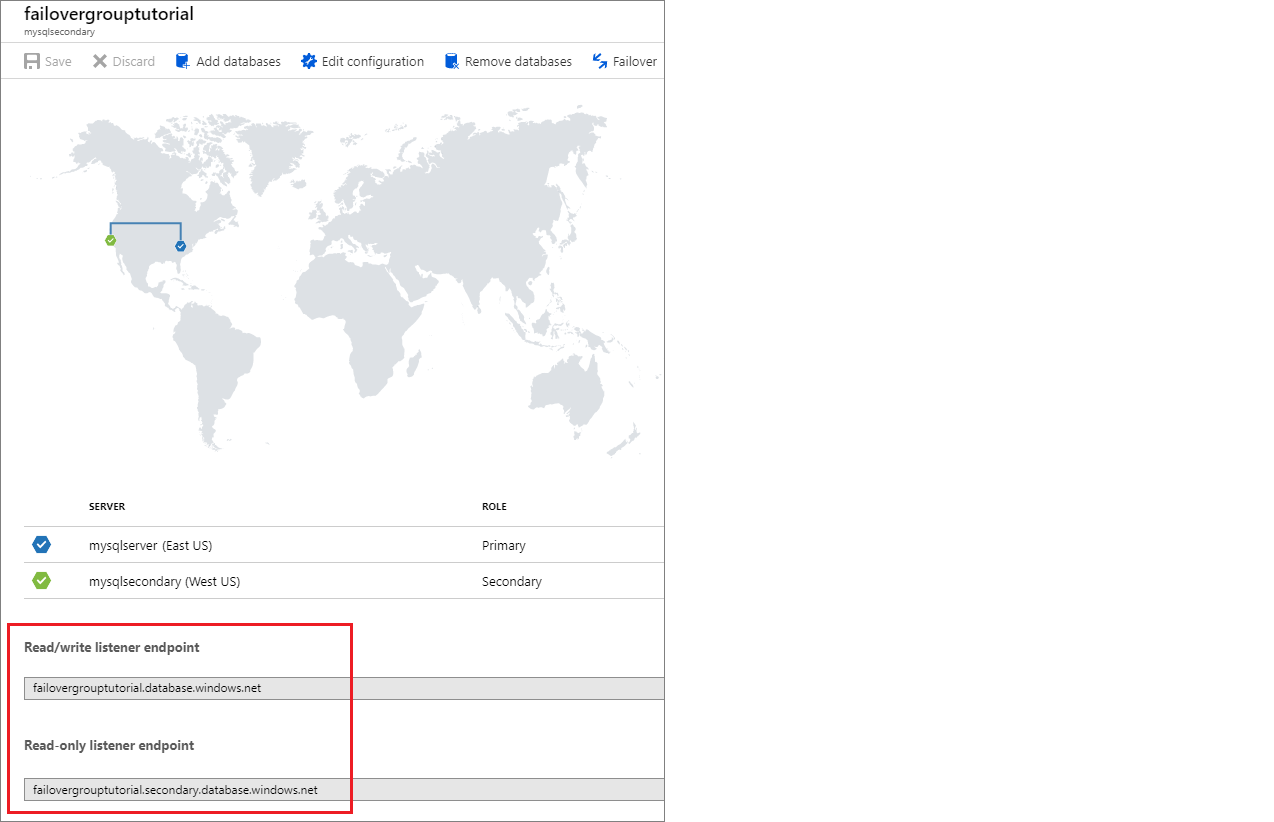
Une fois votre groupe de basculement configuré, mettez à jour la chaîne de connexion de votre application sur le point de terminaison de l’écouteur. Ainsi, votre application reste connectée à l’écouteur du groupe de basculement, plutôt qu’à la base de données primaire, au pool élastique ou à la base de données d’instance. De cette façon, vous n’avez pas besoin de mettre à jour manuellement la chaîne de connexion chaque fois que votre entité de base de données fait l’objet d’un basculement et le trafic est acheminé vers l’entité qui fait office d’entité principale.
Le point de terminaison de l’écouteur se présente sous la forme, fog-name.database.windows.net et est visible dans le Portail Azure, quand vous affichez le groupe de basculement :
Créer un groupe entre des instances de différents abonnements
Vous pouvez créer un groupe de basculement entre des SQL Managed Instances dans deux abonnements différents, à condition que les abonnements soient associés au même locataire Microsoft Entra.
- Lorsque vous utilisez l’API PowerShell, vous pouvez le faire en spécifiant le paramètre
PartnerSubscriptionIdpour l’instance SQL Managed Instance secondaire. - Lors de l’utilisation de l’API REST, chaque ID d’instance inclus dans le paramètre
properties.managedInstancePairspeut avoir son propre ID d’abonnement. - Le portail Azure ne prend pas en charge la création de groupes de basculement sur différents abonnements.
Important
Le portail Azure ne prend pas en charge la création de groupes de basculement sur différents abonnements. Pour les groupes de basculement sur différents abonnements et/ou groupes de ressources, le basculement ne peut pas être lancé manuellement en utilisant le portail Azure depuis l’instance SQL Managed Instance principale. Initiez-le plutôt à partir de l’instance géosecondaire.
Empêcher la perte de données critiques
En raison de la latence élevée des réseaux étendus, la géoréplication utilise un mécanisme de réplication asynchrone. La réplication asynchrone rend la possibilité de perte de données inévitable en cas de défaillance de la base de données primaire. Pour protéger les transactions critiques d’une perte de données, le développeur d’applications peut appeler la procédure stockée sp_wait_for_database_copy_sync immédiatement après la validation de la transaction. L’appel de sp_wait_for_database_copy_sync bloque le thread appelant jusqu’à ce que la dernière transaction validée ait été transmise et renforcée dans le journal des transactions de la base de données secondaire. Toutefois, il n’attend pas que les transactions transmises soient relues (réeffectuées) sur la base de données secondaire. sp_wait_for_database_copy_sync est limité à un lien de géoréplication spécifique. Tout utilisateur disposant de droits de connexion à la base de données primaire peut appeler cette procédure.
Notes
sp_wait_for_database_copy_sync empêche la perte de données après un géobasculement pour des transactions spécifiques, mais ne garantit pas une synchronisation complète pour l’accès en lecture. Le délai causé par un appel de procédure sp_wait_for_database_copy_sync peut être significatif et dépend de la taille du journal des transactions pas encore transmis à la base de données primaire au moment de l’appel.
Modifier la région secondaire
Supposons que l’instance A est l’instance principale, que l’instance B est l’instance secondaire existante et que l’instance C est la nouvelle instance secondaire dans la troisième région. Pour faire la transition, suivez ces étapes :
- Créez l’instance C avec la même taille que A et dans la même zone DNS.
- Supprimez le groupe de basculement entre les instances A et B. À ce stade, les tentatives de connexion commencent à échouer car les alias SQL des écouteurs du groupe de basculement ont été supprimés et la passerelle ne reconnaît pas le nom du groupe de basculement. Les bases de données secondaires sont déconnectées des bases de données primaires et deviennent des bases de données en lecture-écriture.
- Créez un groupe de basculement avec le même nom entre l’instance A et l’instance C. Suivez les instructions du guide à la configuration du groupe de basculement. Il s’agit d’une opération de taille de données qui se termine dès lors que toutes les bases de données de l’instance A ont été amorcées et synchronisées.
- Si vous n’en avez plus besoin, supprimez l’instance B pour éviter des frais inutiles.
Notes
Après l’étape 2 et tant que l’étape 3 n’est par terminée, les bases de données de l’instance A restent non protégées contre une défaillance irrémédiable de l’instance A.
Modifier la région primaire
Supposons que l’instance A est l’instance principale, que l’instance B est l’instance secondaire existante et que l’instance C est la nouvelle instance principale dans la troisième région. Pour faire la transition, suivez ces étapes :
- Créez l’instance C avec la même taille que B et dans la même zone DNS.
- Connectez-vous à l’instance B et basculez manuellement pour passer de l’instance principale à l’instance B. L’instance A devient automatiquement la nouvelle instance secondaire.
- Supprimez le groupe de basculement entre les instances A et B. À ce stade, les tentatives de connexion à l’aide de points de terminaison de groupe de basculement échouent. Les bases de données secondaires sur A sont déconnectées des bases de données primaires et deviennent des bases de données en lecture-écriture.
- Créez un groupe de basculement avec le même nom entre l’instance B et l’instance C. Suivez les instructions du guide au groupe de basculement. Il s’agit d’une opération de taille de données qui se termine dès lors que toutes les bases de données de l’instance A ont été amorcées et synchronisées. À ce stade, les tentatives de signature cessent d’échouer.
- Basculer manuellement pour commuter l’instance C vers le rôle primaire. L’instance B devient automatiquement la nouvelle instance secondaire.
- Si vous n’en avez plus besoin, supprimez l’instance A pour éviter des frais inutiles.
Attention
Après l’étape 3 et tant que l’étape 4 n’est par terminée, les bases de données de l’instance A restent non protégées contre une défaillance irrémédiable de l’instance A.
Important
Une fois le groupe de basculement supprimé, les enregistrements DNS des points de terminaison de l’écouteur sont également supprimés. À ce stade, il existe une probabilité non nulle qu’une personne crée un groupe de basculement avec le même nom. Étant donné que les noms de groupe de basculement doivent être globalement uniques, vous ne pourrez pas réutiliser le même nom. Pour réduire au minimum ce risque, n’utilisez pas des noms de groupe de basculement génériques.
Activer les scénarios dépendant des objets des bases de données système
Les bases de données système ne sont pas répliquées vers l’instance secondaire dans un groupe de basculement. Pour permettre les scénarios qui dépendent des objets des bases de données système, assurez-vous de créer les mêmes objets sur l’instance secondaire et de les maintenir synchronisés avec ceux de l’instance primaire.
Par exemple, si vous envisagez d’utiliser les mêmes connexions sur l’instance secondaire, veillez à les créer avec un ID de sécurité identique.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Pour en savoir plus, consultez Réplication des connexions et des tâches de l’agent.
Synchronisation des propriétés des instances et des instances de stratégies de rétention
Les instances d’un groupe de basculement restent des ressources Azure distinctes, et aucune modification apportée à la configuration de l’instance primaire n’est automatiquement répliquée sur l’instance secondaire. Veillez à effectuer toutes les modifications pertinentes à la fois sur l’instance primaire et sur l’instance secondaire. Par exemple, si vous modifiez la redondance du stockage de sauvegarde ou la stratégie de rétention des sauvegardes à long terme sur l’instance primaire, veillez à la modifier également sur l’instance secondaire.
Mise à l’échelle des instances
Vous pouvez effectuer un scale-up ou un scale-down des instances primaires et secondaires à une taille de calcul différente au sein du même niveau de service ou vers un autre niveau de service. Lors du scale-up au sein du même niveau de service, nous vous recommandons de commencer par la base de données géo-secondaire, puis de terminer avec la base de données primaire. Lors du scale-down au sein du même niveau de service, inversez l’ordre : commencez par la base de données primaire, puis terminez par la base de données secondaire. Quand vous faites passer une instance à un niveau de service supérieur ou inférieur, cette recommandation s’applique.
La séquence est recommandée dans le but spécifique d’éviter le problème de surcharge des bases de données géosecondaires avec une référence SKU inférieure. Celles-ci doivent alors être réalimentées dans le cadre du passage à une version ultérieure ou antérieure.
Autorisations
Les autorisations pour un groupe de basculement sont gérées via un contrôle d’accès en fonction du rôle Azure (Azure RBAC).
L’accès en écriture à RBAC Azure est nécessaire pour créer et gérer des groupes de basculement. Le rôle Contributeur SQL Managed Instance dispose des autorisations nécessaires pour gérer des groupes de basculement.
Le tableau suivant répertorie les étendues d’autorisation spécifiques pour Azure SQL Managed Instance :
| Action | Permission | Étendue |
|---|---|---|
| Créer un groupe de basculement | Accès en écriture à RBAC Azure | Instance gérée principale Instance gérée secondaire |
| Mettre à jour un groupe de basculement | Accès en écriture à RBAC Azure | Groupe de basculement Toutes les bases de données dans l’instance gérée |
| Faire basculer un groupe de basculement | Accès en écriture à RBAC Azure | Groupe de basculement sur une nouvelle instance gérée principale |
Limites
Notez les limitations suivantes :
- Il n’est pas possible de créer des groupes de basculement entre deux instances au sein de la même région Azure.
- Les groupes de basculement ne peuvent pas être renommés. Vous devrez supprimer le groupe puis le recréer sous un autre nom.
- Un groupe de basculement contient exactement deux instances managées. L’ajout d’instances supplémentaires au groupe de basculement n’est pas pris en charge.
- Une instance ne peut participer qu’à un seul groupe de basculement à tout moment.
- Un groupe de basculement ne peut pas être créé entre deux instances appartenant à différents locataires Azure.
- Un groupe de basculement entre deux instances appartenant à différents abonnements Azure ne peut pas être créé à l’aide du portail Azure ou d’Azure CLI. Utilisez plutôt Azure PowerShell ou l’API REST pour créer un tel groupe de basculement. Une fois créé, le groupe de basculement avec plusieurs abonnements est régulièrement visible dans le portail Azure, et toutes les opérations suivantes, y compris les basculements, peuvent être créées à partir du portail Azure ou d’Azure CLI.
- Le renommage de base de données n’est pas pris en charge pour les bases de données situées dans un groupe de basculement. Vous devez supprimer temporairement le groupe de basculement pour pouvoir renommer une base de données.
- Les bases de données système ne sont pas répliquées vers l’instance secondaire dans un groupe de basculement. Par conséquent, les scénarios qui dépendent des objets des bases de données système (tels que les identifiants de serveurs ou des travaux d’agent) requièrent que les objets soient créés manuellement sur les instances secondaires et soient également synchronisés manuellement après toute modification apportée à l’instance principale. La seule exception est la clé principale de Service (SMK) pour SQL Managed Instance, qui est répliquée automatiquement vers l’instance secondaire lors de la création du groupe de basculement. Toutefois, toute modification ultérieure de SMK sur l’instance principale n’est pas répliquée vers l’instance secondaire. Pour en savoir plus, découvrez comment activer les scénarios dépendant des objets des bases de données système.
- Les groupes de basculement ne peuvent pas être créés entre des instances si l’un d’eux se trouve dans un pool d’instances.
Gérer programmatiquement des groupes de basculement
Les groupes de basculement peuvent aussi être gérés programmatiquement en utilisant Azure PowerShell, Azure CLI et l’API REST. Les tableaux ci-dessous décrivent l’ensemble des commandes disponibles. Les groupes de basculement comprennent un ensemble d’API Azure Resource Manager pour la gestion, notamment API REST de base de données Azure SQL et Azure PowerShell cmdlets. Ces API nécessitent l’utilisation de groupes de ressources et la prise en charge du contrôle d’accès en fonction du rôle (RBAC). Pour plus d’informations sur l’implémentation de rôles d’accès, consultez la page sur le contrôle d’accès en fonction du rôle Azure (RBAC Azure).
| Applet de commande | Description |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | Cette commande crée un groupe de basculement et l’enregistre dans les instances principale et secondaire |
| Set-AzSqlDatabaseInstanceFailoverGroup | Modifie la configuration d’un groupe de basculement |
| Get-AzSqlDatabaseInstanceFailoverGroup | Récupère la configuration d’un groupe de basculement |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Déclenche le basculement d’un groupe de basculement vers l’instance secondaire |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Supprime un groupe de basculement |
Étapes suivantes
Pour obtenir des instructions sur la configuration d’un groupe de basculement, consultez le guide Ajouter une instance gérée à un groupe de basculement.
Pour obtenir une vue d’ensemble de la fonctionnalité, consultez Groupe de basculement. Pour savoir comment économiser sur les coûts de licence, consultez Configurer un réplica de secours.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour