Tutoriel : Copier des données sur Azure Data Box Disk et procéder à une vérification
Copier des données sur un disque Azure Data Box et procéder à une validation
Une fois les disques connectés et déverrouillés, vous pouvez copier des données de votre serveur de données source sur vos disques. Une fois la copie des données terminée, vous devez valider les données pour garantir qu’elles seront correctement chargées dans Azure.
Important
Azure Data Box prend désormais en charge l'affectation de niveau d'accès au niveau d'un objet blob. Les étapes de ce tutoriel reflètent le processus de copie de données mis à jour et sont spécifiques aux objets blob de blocs.
Pour plus de renseignements sur la détermination du niveau d'accès approprié pour vos objets blob de blocs de données, consultez la section Déterminer les niveaux d'accès appropriés pour les objets blob de blocs. Suivez les étapes de la section Copier les données sur les disques pour copier vos données sur le niveau d'accès approprié.
Les informations contenues dans cette section s'appliquent aux ordres de commande passés après le 1er avril 2024.
Attention
Cet article fait référence à CentOS, une distribution Linux proche de l’état EOL (End Of Life). Faites le point sur votre utilisation pour vous organiser de manière appropriée.
Ce tutoriel décrit comment copier des données à partir de votre ordinateur hôte et générer des sommes de contrôle pour vérifier l'intégrité des données.
Dans ce tutoriel, vous allez apprendre à :
- Déterminer les niveaux d'accès appropriés pour les objets blob de blocs
- Copier des données sur un disque Data Box
- Vérifier les données
Prérequis
Avant de commencer, assurez-vous que :
- Vous avez terminé le Tutoriel : Installer et configurer votre offre Azure Data Box Disk.
- Vos disques sont déverrouillés et connectés à un ordinateur client.
- L'ordinateur client utilisé pour copier les données sur les disques exécute un Système d'exploitation pris en charge.
- Le type de stockage prévu pour vos données correspond aux Types de stockage pris en charge.
- Vous venez de réviser les Limites des disques managés dans les limites de la taille des objets Azure.
Déterminer les niveaux d'accès appropriés pour les objets blob de blocs
Important
Les informations contenues dans cette section s'appliquent aux ordres de commande passés après le 1er avril 2024.
Le Stockage Azure vous permet de stocker des objets blob de blocs de données dans plusieurs niveaux d'accès au sein d'un même compte de stockage. Cette fonction permet d'organiser et de stocker plus efficacement les données en fonction de leur fréquence d'accès. Le tableau suivant contient des informations et des suggestions sur les niveaux d'accès au Stockage Azure.
| Niveau | Recommandation | Bonnes pratiques |
|---|---|---|
| Chaud | Utile pour les données en ligne fréquemment consultées ou modifiées. Ce niveau a les coûts de stockage les plus élevés, mais les coûts d’accès les plus bas. | Les données de ce niveau doivent faire l'objet d'une utilisation régulière et active. |
| Froid | Utile pour les données en ligne rarement consultées ou modifiées. Ce niveau a des coûts de stockage inférieurs et des coûts d'accès supérieurs à ceux du niveau d'accès chaud. | Les données de ce niveau doivent être stockées pendant au moins 30 jours. |
| Froid | Utile pour les données en ligne rarement consultées ou modifiées, mais nécessitant une recherche rapide. Ce niveau a des coûts de stockage plus faibles et des coûts d'accès plus élevés que le niveau de stockage sporadique. | Les données de ce niveau doivent être stockées pendant au moins 90 jours. |
| Archive | Utile pour les données hors connexion rarement consultées et dont les exigences en matière de latence sont moindres. | Les données de ce niveau doivent être stockées pendant au moins 180 jours. Les données supprimées du niveau archive dans les 180 jours sont soumises à des frais de suppression anticipée. |
Pour plus d'informations sur les niveaux d'accès aux objets blob, consultez Niveaux d'accès aux données d'objets blob. Pour plus d'informations sur les meilleures pratiques, consultez Meilleures pratiques pour l'utilisation des niveaux d'accès aux objets blob.
Vous pouvez transférer vos objets blob de blocs de données vers le niveau d'accès approprié en les copiant dans le dossier correspondant de Data Box Disk. Ce processus est décrit plus en détail dans la section Copier des données sur des disques.
Copier des données sur des disques
Passez en revue les considérations suivantes avant de commencer la copie des données sur les disques :
Il vous incombe de copier les données locales sur le partage correspondant au format de données approprié. Vous pourrez par exemple copier des objets blob de blocs de données sur le partage BlockBlob. Copiez des disques durs virtuels dans le partage PageBlob. Si le format des données locales ne correspond pas au dossier approprié pour le type de stockage choisi, le chargement des données vers Azure échouera au cours d'une prochaine étape.
Vous ne pouvez pas copier des données directement dans le dossier racine d’un partage. Vous pourrez en revanche créer un dossier dans le partage approprié et y copier vos données.
Les dossiers situés à la racine du partage PageBlob correspondent aux conteneurs de votre compte de stockage. Un nouveau conteneur est créé pour tout dossier dont le nom ne correspond pas à un conteneur existant dans votre compte de stockage.
Les dossiers situés à la racine du partage AzFile correspondent à des partages de fichiers Azure. Un nouveau partage de fichiers est créé pour tout dossier dont le nom ne correspond pas à un partage de fichiers existant dans votre compte de stockage.
Le niveau racine du partage BlockBlob contient un dossier correspondant à chaque niveau d'accès. Lorsque vous copiez des données sur le partage BlockBlob, créez un sous-dossier dans le dossier de premier niveau correspondant au niveau d'accès souhaité. Tout comme pour le partage PageBlob, un nouveau conteneur est créé pour tout dossier dont le nom ne correspond pas à un conteneur existant. Les données contenues dans le conteneur sont copiées dans le niveau correspondant au parent de premier niveau du sous-dossier.
Un conteneur est également créé pour tout dossier résidant à la racine du partage BlockBlobet les données qu’il contient sont copiées dans le niveau d’accès par défaut du conteneur. Pour vous assurer que vos données sont copiées au niveau d'accès souhaité, ne créez pas de dossiers au niveau de la racine.
Important
Les données chargées vers le niveau archive restent hors connexion et doivent être réhydratées avant d'être lues ou modifiées. Les données copiées dans le niveau archive doivent être stockées pendant au moins 180 jours ou être soumises à des frais de suppression anticipée. Le niveau archive n'est pas pris en charge pour les comptes ZRS, GZRS ou RA-GZRS.
Lors de la copie des données, assurez-vous que la taille des données est conforme aux limites de taille décrites dans l'article Stockage Azure et limites des Data Box Disk.
Ne désactivez pas le chiffrement BitLocker sur les Data Box Disks. La désactivation du chiffrement BitLocker entraîne un échec de chargement une fois les disques retournés. La désactivation de BitLocker laisse également des disques dans un état déverrouillé, ce qui crée des problèmes de sécurité.
Pour préserver les métadonnées telles que les ACL, les timestamps et les attributs de fichiers lors du transfert de données vers Azure Files, suivez les instructions de l'article Préserver les ACL, les attributs et les timestamps de fichiers avec Azure Data Box Disk.
Si vous utilisez simultanément Data Box Disk et d’autres applications pour charger des données, vous risquez de constater des défaillances dans les tâches de chargement et une altération des données.
Important
Si vous avez spécifié des disques managés en tant que destination de stockage pendant la création de commandes, la section suivante s’applique.
Vérifiez que les disques durs virtuels (VHD) chargés dans les dossiers précréés ont des noms uniques au sein des groupes de ressources. Les disques managés doivent avoir des noms uniques au sein d'un groupe de ressources pour tous les dossiers précréés sur Data Box Disk. Si vous utilisez plusieurs Data Box Disks, les noms des disques managés doivent être uniques pour tous les dossiers et tous les disques. Lorsque des VHD ayant des noms en double sont trouvés, seul l'un d'entre eux est converti en disque managé portant ce nom. Les VHD restants sont chargés sous forme d’objets blob de pages dans le compte de stockage de mise en lots.
Vous devez toujours copier les disques durs virtuels dans l’un des dossiers pré-créés. Les VHD placés en dehors de ces dossiers ou dans un dossier que vous avez créé sont chargés dans les comptes de Stockage Azure en tant qu’objets blob de pages et non en tant que disques managés.
Seuls les VHD corrigés peuvent être chargés pour créer des disques managés. Les VHD dynamiques, les VHD différentiels et les fichiers VHDX ne sont pas pris en charge.
Les outils Data Box Disk Split Copy et Validation,
DataBoxDiskSplitCopy.exeetDataBoxDiskValidation.cmd, signalent des défaillances lorsque de longs chemins d'accès sont traités. Ces échecs sont fréquents lorsque les chemins d'accès longs ne sont pas activés sur le client et que les chemins d'accès, ainsi que les noms de fichiers de votre copie de données dépassent 256 caractères. Pour éviter ces échecs, suivez les instructions de l'article sur l'activation des chemins d'accès longs sur votre client Windows.
Procédez comme suit pour vous connecter et copier des données à partir de votre ordinateur vers le disque Data Box.
Affichez le contenu du disque déverrouillé. La liste des dossiers et sous-dossiers précréés dans le lecteur varie en fonction des options sélectionnées lors de l’ordre de commande du Data Box Disk. La création de dossiers supplémentaires n'est pas autorisée, car la copie de données dans un dossier créé par l'utilisateur entraîne des défaillances de chargement.
Destination de stockage sélectionnée Type de compte de stockage Type de compte de stockage de préproduction Dossiers et sous-dossiers Compte de stockage GPv1 ou GPv2 N/D BlockBlob - Archivage
- Froid
- Froid
- Chaud
AzureFileCompte de stockage Compte de stockage d’objets blob N/D BlockBlob - Archivage
- Froid
- Froid
- Chaud
Disques managés N/D GPv1 ou GPv2 ManagedDisk - PremiumSSD
- StandardSSD
- StandardHDD
Compte de stockage
Disques managésGPv1 ou GPv2 GPv1 ou GPv2 BlockBlob - Archivage
- Froid
- Froid
- Chaud
AzureFile
ManagedDisk- PremiumSSD
- StandardSSD
- StandardHDD
Compte de stockage
Disques managésCompte de stockage d’objets blob GPv1 ou GPv2 BlockBlob - Archivage
- Froid
- Froid
- Chaud
- PremiumSSD
- StandardSSD
- StandardHDD
La capture d'écran suivante représente un ordre de commande dans lequel un compte de stockage GPv2 et un niveau archive ont été spécifiés :
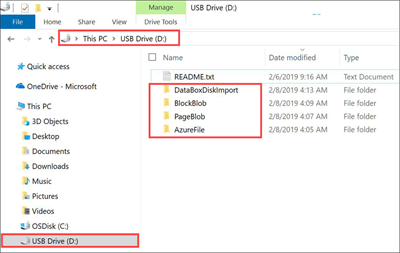
Copiez des données VHD ou VHDX dans le dossier PageBlob. Tous les fichiers copiés dans le dossier PageBlob sont copiés dans un conteneur
$rootpar défaut dans le compte de Stockage Azure. Un conteneur est créé dans le compte de stockage Azure pour chaque sous-dossier du dossier PageBlob.Copiez les données que vous souhaitez placer dans les partages de fichiers Azure dans un sous-dossier du dossier AzureFile. Tous les fichiers copiés dans le dossier AzureFile sont copiés en tant que fichiers dans un conteneur par défaut de type
databox-format-[GUID]. Par exemple :databox-azurefile-7ee19cfb3304122d940461783e97bf7b4290a1d7.Vous ne pouvez pas copier des fichiers directement dans le dossier racine de BlockBlob. Dans le dossier racine, vous trouvez un sous-dossier correspondant à chaque niveau d’accès disponible. Pour copier vos données d'objets blob, vous devez d'abord sélectionner le dossier correspondant à l'un des niveaux d'accès. Ensuite, créez un sous-dossier dans le dossier de ce niveau pour stocker vos données. Enfin, copiez vos données dans le sous-dossier nouvellement créé. Votre nouveau sous-dossier représente le conteneur créé dans le compte de stockage lors de l’ingestion. Vos données sont chargées dans ce conteneur sous forme d'objets blob. Tout comme pour le partage AzureFile, un nouveau conteneur de stockage d’objets blob est créé pour chaque sous-dossier situé dans le dossier racine du BlockBlob. Les données contenues dans ces dossiers sont sauvegardées selon le niveau d’accès par défaut du compte de stockage.
Avant de procéder à la copie des données, vous devez déplacer tous les fichiers et dossiers qui se trouvent dans le dossier racine vers un autre dossier.
Important
Tous les conteneurs, objets blob et fichiers doivent respecter les conventions de nommage Azure. Si ces règles ne sont pas respectées, le chargement des données vers Azure échoue.
Lorsque vous copiez des fichiers, vérifiez qu'ils ne dépassent pas 4,7 Tio pour les objets blob de blocs, 8 Tio pour les objets blob de pages et 1 Tio pour les fichiers Azure Files.
Vous pouvez utiliser la fonction glisser-déposer d'Explorateur de fichiers pour copier les données. Vous pouvez également utiliser n’importe quel outil de copie de fichier SMB, comme Robocopy, pour copier vos données.
L'un des avantages de l'utilisation d'un outil de copie de fichiers est la possibilité de lancer plusieurs travaux de copie, tel qu'illustré dans l'exemple suivant, qui utilise l'outil Robocopy :
Robocopy <source> <destination> * /MT:64 /E /R:1 /W:1 /NFL /NDL /FFT /Log:c:\RobocopyLog.txtRemarque
Les paramètres utilisés dans cet exemple sont basés sur l'environnement adopté lors des tests internes. Vos paramètres et valeurs sont probablement différents.
Les paramètres et options de la commande sont utilisés comme suit :
Paramètres/Options Description Source Spécifie le chemin d’accès au répertoire source. Destination Spécifie le chemin d’accès au répertoire de destination. /E Copie les sous-répertoires, y compris les répertoires vides. /MT[:n] Créez des copies multithread avec des threads n où n est un entier entre 1 et 128.
La valeur par défaut de n est 8./R: <n> Spécifie le nombre de nouvelles tentatives en cas d’échec de la copie.
La valeur par défaut de n est de 1 000 000 de tentatives./W: <n> Spécifie le délai d’attente entre les tentatives, en secondes.
La valeur par défaut de n est 30, et elle équivaut à un temps d'attente de 30 secondes./NFL Indique que les noms de fichiers ne sont pas enregistrés dans le journal. /NDL Spécifie que les noms de répertoires ne doivent pas être enregistrés. /FFT Prend pour hypothèse la durée des fichiers FAT avec une précision de résolution de deux secondes. /Log:<Log File> Écrit la sortie d'état dans le fichier journal.
Tout fichier journal existant est remplacé.Plusieurs disques peuvent être utilisés en parallèle, avec plusieurs travaux s’exécutant sur chaque disque. N'oubliez pas que les noms de fichiers en double sont écrasés ou entraînent une erreur de copie.
Vérifiez l’état de l’opération de copie pendant l’exécution du travail. L’exemple suivant affiche la sortie de la commande robocopy pour copier les fichiers sur le disque Data Box.
C:\Users>robocopy ------------------------------------------------------------------------------- ROBOCOPY :: Robust File Copy for Windows ------------------------------------------------------------------------------- Started : Thursday, March 8, 2018 2:34:53 PM Simple Usage :: ROBOCOPY source destination /MIR source :: Source Directory (drive:\path or \\server\share\path). destination :: Destination Dir (drive:\path or \\server\share\path). /MIR :: Mirror a complete directory tree. For more usage information run ROBOCOPY /? **** /MIR can DELETE files as well as copy them ! C:\Users>Robocopy C:\Repository\guides \\10.126.76.172\AzFileUL\templates /MT:64 /E /R:1 /W:1 /FFT ------------------------------------------------------------------------------- ROBOCOPY :: Robust File Copy for Windows ------------------------------------------------------------------------------- Started : Thursday, March 8, 2018 2:34:58 PM Source : C:\Repository\guides\ Dest : \\10.126.76.172\devicemanagertest1_AzFile\templates\ Files : *.* Options : *.* /DCOPY:DA /COPY:DAT /MT:8 /R:1000000 /W:30 ------------------------------------------------------------------------------ 100% New File 206 C:\Repository\guides\article-metadata.md 100% New File 209 C:\Repository\guides\content-channel-guidance.md 100% New File 732 C:\Repository\guides\index.md 100% New File 199 C:\Repository\guides\pr-criteria.md 100% New File 178 C:\Repository\guides\pull-request-co.md 100% New File 250 C:\Repository\guides\pull-request-ete.md 100% New File 174 C:\Repository\guides\create-images-markdown.md 100% New File 197 C:\Repository\guides\create-links-markdown.md 100% New File 184 C:\Repository\guides\create-tables-markdown.md 100% New File 208 C:\Repository\guides\custom-markdown-extensions.md 100% New File 210 C:\Repository\guides\file-names-and-locations.md 100% New File 234 C:\Repository\guides\git-commands-for-master.md 100% New File 186 C:\Repository\guides\release-branches.md 100% New File 240 C:\Repository\guides\retire-or-rename-an-article.md 100% New File 215 C:\Repository\guides\style-and-voice.md 100% New File 212 C:\Repository\guides\syntax-highlighting-markdown.md 100% New File 207 C:\Repository\guides\tools-and-setup.md ------------------------------------------------------------------------------ Total Copied Skipped Mismatch FAILED Extras Dirs : 1 1 1 0 0 0 Files : 17 17 0 0 0 0 Bytes : 3.9 k 3.9 k 0 0 0 0 Times : 0:00:05 0:00:00 0:00:00 0:00:00 Speed : 5620 Bytes/sec. Speed : 0.321 MegaBytes/min. Ended : Thursday, August 31, 2023 2:34:59 PMPour optimiser les performances, utilisez les paramètres robocopy suivants lors de la copie des données.
Plateforme Principalement des fichiers de petite taille (< 512 Ko) Principalement des fichiers de taille moyenne (entre 512 Ko et 1 Mo) Principalement des gros fichiers (> 1 Mo) Data Box Disk 4 sessions Robocopy*
16 threads par session2 sessions Robocopy*
16 threads par session2 sessions Robocopy*
16 threads par session*Chaque session Robocopy peut avoir un maximum de 7 000 répertoires et 150 millions de fichiers.
Pour plus d'informations sur la commande Robocopy, lisez l'article Robocopy et quelques exemples.
Ouvrez le dossier cible pour afficher et vérifier les fichiers copiés. Si vous rencontrez des erreurs au cours du processus de copie, téléchargez les fichiers journaux pour résoudre les problèmes. La sortie de la commande Robocopy spécifie l'emplacement des fichiers journaux.

Fractionner et copier des données sur plusieurs disques
L'outil Data Box Split Copy permet de fractionner et de copier des données sur deux ou plusieurs Azure Data Box Disks. L'outil ne peut être utilisé que sur un ordinateur Windows. Cette procédure facultative est utile lorsque vous avez un grand jeu de données qui doit être fractionné et copié sur plusieurs disques.
Important
L'outil Data Box Split Copy peut également valider vos données. Si vous utilisez l’outil Data Box Split Copy pour copier des données, vous pouvez ignorer l’étape de validation. L'outil Split Copy n'est pas pris en charge avec des disques managés.
L’outil Data Box Split Copy doit avoir été téléchargé et extrait dans un dossier local de votre ordinateur Windows. Cet outil est inclus dans le jeu d'outils Data Box Disk pour Windows.
Ouvrez l’Explorateur de fichiers. Notez la lettre de lecteur de la source de données et les lettres de lecteur attribuées à Data Box Disk.
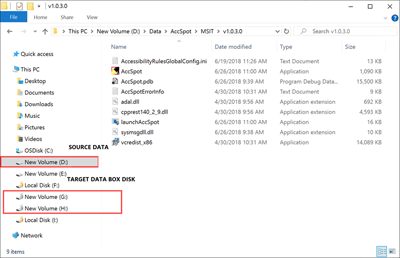
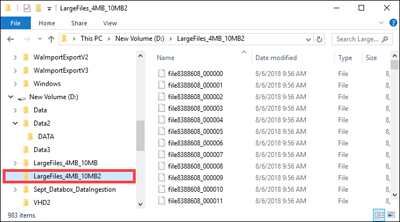
Identifiez les données sources à copier. Par exemple, dans ce cas précis :
Les données d'objet blob de blocs ci-après ont été identifiées.
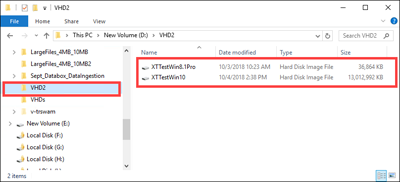
Les données d'objet blob de pages ci-après ont été identifiées.
Accédez au dossier dans lequel le logiciel a été extrait et localisez le fichier
SampleConfig.json. Il s'agit d'un fichier en lecture seule que vous pouvez modifier et enregistrer.
Modifiez le fichier
SampleConfig.json.Fournissez un nom de travail. Un dossier portant ce nom est créé sur Data Box Disk. Le nom est également utilisé pour créer un conteneur dans le compte de stockage Azure associé à ces disques. Le nom de la tâche doit respecter les conventions d'affectation de noms des conteneurs Azure.
Fournissez un chemin source en notant le format du chemin d'accès dans le
SampleConfigFile.json.Entrez les lettres de lecteur correspondant aux disques cibles. Les données sont extraites du chemin d'accès source et copiées sur plusieurs disques.
Fournissez un chemin d’accès pour les fichiers journaux. Par défaut, les fichiers journaux sont envoyés dans le répertoire où se trouve le fichier
.exe.Pour valider le format de fichier, accédez à
JSONlint.
Enregistrez le fichier sous le nom
ConfigFile.json.
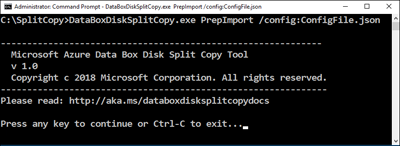
Ouvrez une fenêtre d'invite de commandes avec des privilèges élevés et exécutez
DataBoxDiskSplitCopy.exeà l'aide de la commande suivante.DataBoxDiskSplitCopy.exe PrepImport /config:ConfigFile.jsonLorsque vous y êtes invité, appuyez sur n'importe quelle touche pour poursuivre l'exécution de l'outil.
Une fois le jeu de données fractionné et copié, le résumé de l'outil Split Copy pour la session de copie est présenté comme indiqué dans l'échantillon de sortie suivant.
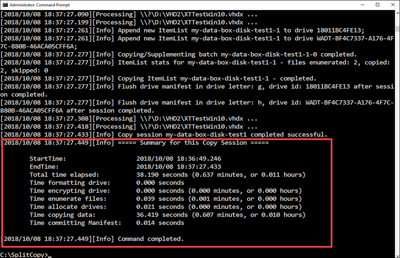
Vérifiez que les données ont été fractionnées entre les disques cibles.
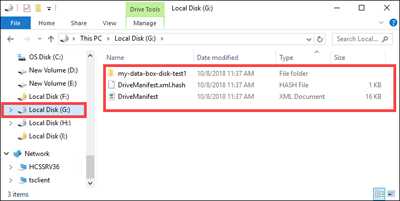
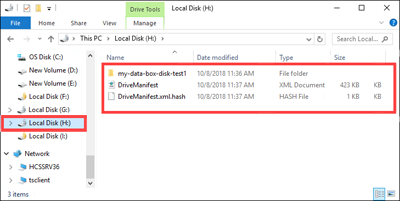
Examinez les contenus du lecteur
H:et vérifiez que les deux sous-dossiers correspondant aux données des formats d'objet blob de blocs et d'objet blob de pages ont été créés.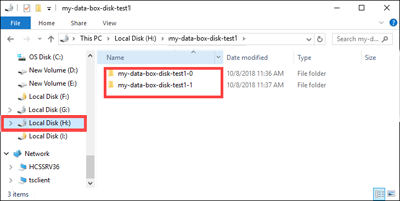
Si la session de copie échoue, utilisez la commande suivante pour la récupérer et la reprendre :
DataBoxDiskSplitCopy.exe PrepImport /config:ConfigFile.json /ResumeSession










Si vous détectez des erreurs lorsque vous utilisez l'outil Split Copy, suivez les étapes décrites dans l'article détecter les erreurs de l'outil Split Copy.
Important
L'outil Data Box Split Copy valide également vos données. Si vous utilisez l’outil Data Box Split Copy pour copier des données, vous pouvez ignorer l’étape de validation. L'outil Split Copy n'est pas pris en charge avec des disques managés.
Valider des données
Si vous n'avez pas utilisé l'outil Data Box Split Copy pour copier les données, vous devez valider vos données. Vérifiez les données en suivant les étapes suivantes sur chacun de vos Data Box Disks. Si vous détectez des erreurs pendant la validation, suivez les étapes décrites dans l'article détecter les erreurs de validation.
Exécutez
DataBoxDiskValidation.cmdpour la validation des sommes de contrôle dans le dossier DataBoxDiskImport de votre lecteur. Cet outil n'est disponible que pour l'environnement Windows. Les utilisateurs de Linux doivent s'assurer que les données sources copiées sur le disque répondent aux conditions préalables d'Azure Data Box.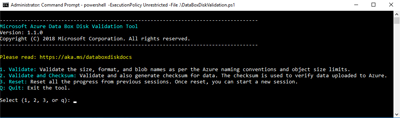
Choisissez l'option de validation appropriée lorsque vous y êtes invité. Nous vous recommandons de toujours valider les fichiers et générer des sommes de contrôle en sélectionnant l’option 2. Quittez la fenêtre de commande une fois le script terminé. Le temps nécessaire à la validation dépend de la taille de vos données. L'outil vous informe de toutes les erreurs détectées lors de la validation et de la génération de la somme de contrôle. De plus, il vous fournit un lien vers les journaux d'erreurs.
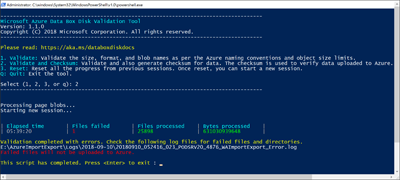
Conseil
- Réinitialisez l’outil entre deux exécutions.
- Le processus de somme de contrôle peut prendre plus de temps si vous avez un grand jeu de données contenant de nombreux fichiers qui utilisent une capacité de stockage relativement faible. Si vous validez les fichiers et ignorez la création de la somme de contrôle, vous devez vérifier indépendamment l'intégrité des données sur Data Box Disk avant de supprimer toute copie. Cette vérification comprend en principe la génération de sommes de contrôle.


Étapes suivantes
Dans ce tutoriel, vous avez appris à effectuer les tâches suivantes avec Azure Data Box Disk :
- Copier des données sur un disque Data Box
- Vérifier l’intégrité des données
Passez au didacticiel suivant pour savoir comment renvoyer le disque Data Box et vérifier le chargement des données dans Azure.
Copier des données sur des disques
Effectuez les étapes suivantes pour vous connecter et copier des données à partir de votre ordinateur vers le Data Box Disk.
Affichez le contenu du disque déverrouillé. La liste des dossiers et sous-dossiers précréés sur le disque varie selon les options sélectionnées au moment de la commande Data Box Disk.
Copiez les données dans des dossiers qui correspondent au format de données approprié. Par exemple, copiez les données non structurées dans le dossier BlockBlob, les données VHD ou VHDX dans le dossier PageBlob et les fichiers dans le dossier AzureFile. Si le format des données ne correspond pas au dossier (type de stockage), les données ne pourront pas être chargées vers Azure.
- Assurez-vous que tous les conteneurs, objets blob et fichiers respectent les conventions de nommage Azure et les limites de taille d’objet Azure. Si ces règles ou limites ne sont pas respectées, le chargement des données vers Azure échoue.
- Si votre commande comporte Disques managés comme l’une des destinations de stockage, consultez les conventions de nommage pour les disques managés.
- Un conteneur est créé dans le compte de stockage Azure de chaque sous-dossier dans les dossiers BlockBlob et PageBlob. Tous les fichiers des dossiers BlockBlob et PageBlob sont copiés dans le conteneur $root par défaut dans le compte de stockage Azure. Tous les fichiers présents dans le conteneur $root sont systématiquement chargés en tant qu’objets blob de blocs.
- Créez un sous-dossier dans le dossier AzureFile. Ce sous-dossier est mappé à un partage de fichiers dans le cloud. Copiez les fichiers dans le sous-dossier. Les fichiers copiés directement dans le dossier AzureFile échouent et sont chargés en tant qu’objets blob de blocs.
- Si des fichiers et dossiers existent dans le répertoire racine, ils doivent être déplacés vers un autre dossier avant que la copie des données puisse commencer.
Utilisez la fonction glisser-déplacer avec l’Explorateur de fichiers ou n’importe quel outil de copie de fichier compatible SMB, comme Robocopy, pour copier vos données. Plusieurs travaux de copie peuvent être lancés simultanément à l’aide de la commande suivante :
Robocopy <source> <destination> * /MT:64 /E /R:1 /W:1 /NFL /NDL /FFT /Log:c:\RobocopyLog.txtOuvrez le dossier cible pour afficher et vérifier les fichiers copiés. Si vous rencontrez des erreurs au cours du processus de copie, téléchargez les fichiers journaux pour résoudre les problèmes. L’emplacement des fichiers journaux est spécifié dans la commande robocopy.
Appliquez la procédure facultative de fractionnement et copie quand vous utilisez plusieurs disques et que vous disposez d’un jeu de données volumineux qui doit être fractionné et copié sur la totalité des disques.
Valider des données
Vérifiez vos données en procédant comme suit :
Exécutez le fichier
DataBoxDiskValidation.cmdpour la validation des sommes de contrôle dans le dossier DataBoxDiskImport de votre lecteur.Utilisez l’option 2 pour valider vos fichiers et générer des sommes de contrôle. Selon la taille de vos données, cette étape peut prendre un certain temps. Si des erreurs se produisent pendant la validation et la génération des sommes de contrôle, vous en êtes averti, et un lien d’accès aux journaux d’activité des erreurs vous est également fourni.
Pour plus d’informations sur la validation de données, consultez Valider les données. Si des erreurs se produisent lors de la validation, consultez Résoudre les erreurs de validation.