Se connecter et gérer Azure Databricks dans Microsoft Purview
Cet article explique comment inscrire Azure Databricks et comment s’authentifier et interagir avec Azure Databricks dans Microsoft Purview. Pour plus d’informations sur Microsoft Purview, consultez l’article d’introduction.
Fonctionnalités prises en charge
| Extraction de métadonnées | Analyse complète | Analyse incrémentielle | Analyse délimitée | Classification | Étiquetage | Stratégie d’accès | Traçabilité | Partage de données | Affichage en direct |
|---|---|---|---|---|---|---|---|---|---|
| Oui | Oui | Non | Oui | Non | Non | Non | Oui | Non | Non |
Remarque
Ce connecteur apporte des métadonnées à partir du metastore Hive dans l’étendue de l’espace de travail Azure Databricks. Pour analyser les métadonnées dans Azure Databricks Unity Catalog, reportez-vous au connecteur Azure Databricks Unity Catalog.
Lors de l’analyse du metastore Hive Azure Databricks, Microsoft Purview prend en charge :
Extraction de métadonnées techniques, notamment :
- Espace de travail Azure Databricks
- Serveur Hive
- Bases de données
- Tables incluant les colonnes, les clés étrangères, les contraintes uniques et la description du stockage
- Affichages, y compris les colonnes et la description du stockage
Extraction de la relation entre les tables externes et les ressources d’objets blob Azure Data Lake Storage Gen2/Azure (emplacements externes).
Extraction de la traçabilité statique entre les tables et les vues en fonction de la définition de la vue.
Lors de la configuration de l’analyse, vous pouvez choisir d’analyser l’intégralité du metastore Hive ou d’étendre l’analyse à un sous-ensemble de schémas.
Comparaison avec l’analyse via le connecteur de metastore Hive générique au cas où vous l’utiliseriez pour analyser Azure Databricks précédemment :
- Vous pouvez configurer directement l’analyse des espaces de travail Azure Databricks sans accès DIRECT HMS. Il utilise le jeton d’accès personnel Databricks pour l’authentification et se connecte à un cluster pour effectuer l’analyse.
- Les informations de l’espace de travail Databricks sont capturées.
- La relation entre les tables et les ressources de stockage est capturée.
Limitations connues
Lorsque l’objet est supprimé de la source de données, l’analyse suivante ne supprime pas automatiquement la ressource correspondante dans Microsoft Purview.
Configuration requise
Vous devez disposer d’un compte Azure avec un abonnement actif. Créez un compte gratuitement.
Vous devez disposer d’un compte Microsoft Purview actif.
Vous avez besoin d’un Key Vault Azure et d’accorder à Microsoft Purview des autorisations d’accès aux secrets.
Vous avez besoin des autorisations Administrateur de source de données et Lecteur de données pour inscrire une source et la gérer dans le portail de gouvernance Microsoft Purview. Pour plus d’informations sur les autorisations, consultez Contrôle d’accès dans Microsoft Purview.
Configurez le dernier runtime d’intégration auto-hébergé. Pour plus d’informations, consultez Créer et configurer un runtime d’intégration auto-hébergé. La version Integration Runtime auto-hébergée minimale prise en charge est 5.20.8227.2.
Vérifiez que JDK 11 est installé sur l’ordinateur sur lequel le runtime d’intégration auto-hébergé est installé. Redémarrez la machine après avoir installé le JDK pour qu’il prenne effet.
Vérifiez que Visual C++ Redistributable (version Visual Studio 2012 Update 4 ou ultérieure) est installé sur l’ordinateur sur lequel le runtime d’intégration auto-hébergé est en cours d’exécution. Si cette mise à jour n’est pas installée, téléchargez-la maintenant.
Dans votre espace de travail Azure Databricks :
Générez un jeton d’accès personnel et stockez-le en tant que secret dans Azure Key Vault.
Créez un cluster. Notez l’ID de cluster : vous pouvez le trouver dans l’espace de travail Azure Databricks -> Calcul -> votre cluster -> Étiquettes - Étiquettes ajoutées> automatiquement ->
ClusterId.Vérifiez que l’utilisateur dispose des autorisations suivantes pour se connecter au cluster Azure Databricks :
- L’autorisation Peut attacher à pour se connecter au cluster en cours d’exécution.
- Peut redémarrer l’autorisation pour déclencher automatiquement le démarrage du cluster si son état est arrêté lors de la connexion.
Inscrire
Cette section explique comment inscrire un espace de travail Azure Databricks dans Microsoft Purview à l’aide du portail de gouvernance Microsoft Purview.
Accédez à votre compte Microsoft Purview.
Sélectionnez Data Map dans le volet gauche.
Sélectionner Inscription.
Dans Inscrire des sources, sélectionnez Azure Databricks>Continuer.
Dans l’écran Inscrire des sources (Azure Databricks), procédez comme suit :
Pour Nom, entrez un nom que Microsoft Purview listera comme source de données.
Pour Abonnement Azure et Nom de l’espace de travail Databricks, sélectionnez l’abonnement et l’espace de travail que vous souhaitez analyser dans la liste déroulante. L’URL de l’espace de travail Databricks est automatiquement remplie.
Sélectionnez une collection dans la liste.
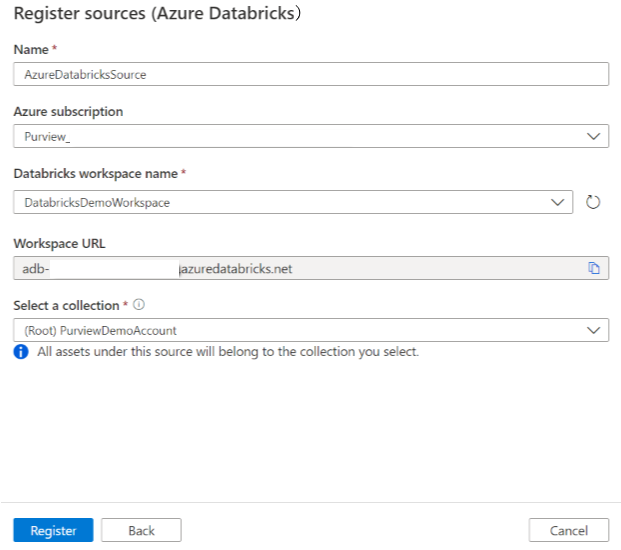
Sélectionnez Terminer.
Analyser
Conseil
Pour résoudre les problèmes liés à l’analyse :
- Vérifiez que vous avez suivi toutes les conditions préalables.
- Consultez notre documentation sur la résolution des problèmes d’analyse.
Procédez comme suit pour analyser Azure Databricks afin d’identifier automatiquement les ressources. Pour plus d’informations sur l’analyse en général, consultez Analyses et ingestion dans Microsoft Purview.
Dans le Centre de gestion, sélectionnez Runtimes d’intégration. Assurez-vous qu’un runtime d’intégration auto-hébergé est configuré. S’il n’est pas configuré, suivez les étapes décrites dans Créer et gérer un runtime d’intégration auto-hébergé.
Accédez à Sources.
Sélectionnez l’instance Azure Databricks inscrite.
Sélectionnez + Nouvelle analyse.
Fournissez les détails suivants :
Nom : entrez un nom pour l’analyse.
Méthode d’extraction : Indiquez pour extraire les métadonnées du metastore Hive ou du catalogue Unity. Sélectionnez Metastore Hive.
Se connecter via le runtime d’intégration : sélectionnez le runtime d’intégration auto-hébergé configuré.
Informations d’identification : sélectionnez les informations d’identification pour vous connecter à votre source de données. Veillez à :
- Sélectionnez Authentification par jeton d’accès lors de la création d’informations d’identification.
- Indiquez le nom secret du jeton d’accès personnel que vous avez créé dans Prérequis dans la zone appropriée.
Pour plus d’informations, consultez Informations d’identification pour l’authentification source dans Microsoft Purview.
ID de cluster : spécifiez l’ID de cluster auquel Microsoft Purview se connecte et alimente l’analyse. Vous pouvez le trouver dans l’espace de travail Azure Databricks -> Calcul -> votre cluster -> Étiquettes -> Étiquettes ajoutées automatiquement ->
ClusterId.Points de montage : fournissez le point de montage et la chaîne d’emplacement source stockage Azure lorsque vous avez un stockage externe monté manuellement sur Databricks. Utilisez le format
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net. Il est utilisé pour capturer la relation entre les tables et les ressources de stockage correspondantes dans Microsoft Purview. Ce paramètre est facultatif. S’il n’est pas spécifié, cette relation n’est pas récupérée.Vous pouvez obtenir la liste des points de montage dans votre espace de travail Databricks en exécutant la commande Python suivante dans un notebook :
dbutils.fs.mounts()Il imprime tous les points de montage comme ci-dessous :
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]Dans cet exemple, spécifiez les points de montage suivants :
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.netSchéma : sous-ensemble de schémas à importer, exprimé sous la forme d’une liste de schémas séparée par des points-virgules. Par exemple :
schema1;schema2. Tous les schémas utilisateur sont importés si cette liste est vide. Tous les schémas et objets système sont ignorés par défaut.Les modèles de nom de schéma acceptables peuvent être des noms statiques ou contenir des caractères génériques . Par exemple :
A%;%B;%C%;D- Commencer par A ou
- Terminer par B ou
- Contenir C ou
- Égal à D
L’utilisation de NOT et de caractères spéciaux n’est pas acceptable.
Remarque
Ce filtre de schéma est pris en charge sur les Integration Runtime auto-hébergés version 5.32.8597.1 et ultérieures.
Mémoire maximale disponible : mémoire maximale (en gigaoctets) disponible sur l’ordinateur du client pour les processus d’analyse à utiliser. Cette valeur dépend de la taille d’Azure Databricks à analyser.
Remarque
En règle générale, fournissez 1 Go de mémoire pour 1 000 tables.

Cliquez sur Continuer.
Pour Déclencheur d’analyse, choisissez de configurer une planification ou d’exécuter l’analyse une seule fois.
Passez en revue votre analyse et sélectionnez Enregistrer et exécuter.
Une fois l’analyse terminée, découvrez comment parcourir et rechercher des ressources Azure Databricks.
Afficher vos analyses et exécutions d’analyse
Pour afficher les analyses existantes :
- Accédez au portail Microsoft Purview. Dans le volet gauche, sélectionnez Mappage de données.
- Sélectionnez la source de données. Vous pouvez afficher une liste des analyses existantes sur cette source de données sous Analyses récentes, ou vous pouvez afficher toutes les analyses sous l’onglet Analyses .
- Sélectionnez l’analyse qui contient les résultats que vous souhaitez afficher. Le volet affiche toutes les exécutions d’analyse précédentes, ainsi que les status et les métriques pour chaque exécution d’analyse.
- Sélectionnez l’ID d’exécution pour case activée les détails de l’exécution de l’analyse.
Gérer vos analyses
Pour modifier, annuler ou supprimer une analyse :
Accédez au portail Microsoft Purview. Dans le volet gauche, sélectionnez Mappage de données.
Sélectionnez la source de données. Vous pouvez afficher une liste des analyses existantes sur cette source de données sous Analyses récentes, ou vous pouvez afficher toutes les analyses sous l’onglet Analyses .
Sélectionnez l’analyse que vous souhaitez gérer. Vous pouvez ensuite :
- Modifiez l’analyse en sélectionnant Modifier l’analyse.
- Annulez une analyse en cours en sélectionnant Annuler l’exécution de l’analyse.
- Supprimez votre analyse en sélectionnant Supprimer l’analyse.
Remarque
- La suppression de votre analyse ne supprime pas les ressources de catalogue créées à partir d’analyses précédentes.
Parcourir et rechercher des ressources
Après avoir analysé votre azure Databricks, vous pouvez parcourir Catalogue unifié ou rechercher Catalogue unifié pour afficher les détails de la ressource.
À partir de la ressource de l’espace de travail Databricks, vous pouvez trouver le metastore Hive associé et les tables/vues. L’option inversée s’applique également.



Traçabilité
Reportez-vous à la section Fonctionnalités prises en charge pour les scénarios Azure Databricks pris en charge. Pour plus d’informations sur la traçabilité en général, consultez le guide de l’utilisateur sur la traçabilité et la traçabilité des données.
Accédez à l’onglet Ressource de table/vue Hive -> Traçabilité. Vous pouvez voir la relation de ressource le cas échéant. Pour la relation entre les ressources de stockage de table et externes, vous voyez que la ressource de table Hive et la ressource de stockage sont directement connectées bidirectionnellement, car elles s’impactent mutuellement. Si vous utilisez le point de montage dans l’instruction create table, vous devez fournir les informations de point de montage dans les paramètres d’analyse pour extraire cette relation.

Étapes suivantes
Maintenant que vous avez inscrit votre source, utilisez les guides suivants pour en savoir plus sur Microsoft Purview et vos données :