Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Unity Catalog est une solution unifiée de gouvernance des données et de l’IA intégrée directement à la plateforme Azure Databricks. Il s’agit d’une vue d’ensemble des concepts clés du catalogue Unity et de la façon d’utiliser Unity Catalog pour régir les données.
Les principaux piliers du catalogue Unity sont les suivants :
- Contrôle d’accès unifié : Unity Catalog offre un emplacement unique pour gérer les autorisations pour les tables, les fichiers, les modèles et d’autres objets à partir d’une seule interface.
- Découverte des données : Unity Catalog permet aux utilisateurs de rechercher et de comprendre les ressources de données via une interface pouvant faire l’objet d’une recherche enrichie avec des balises, des descriptions et des métadonnées.
- Suivi automatisé de la traçabilité : Effectuez automatiquement le suivi du flux de données et de la façon dont elles sont transformées de la source aux vues et tableaux de bord finaux.
- Audit: Conservez un enregistrement complet de l’accès aux données et de l’activité système pour répondre aux exigences de sécurité et à la conformité réglementaire.
- Surveillance de la qualité des données : Effectuez le suivi proactif de l’intégrité de vos ressources de données avec le profilage et les alertes intégrés qui interceptent les anomalies avant d’atteindre les consommateurs en aval.
- Partage de données sécurisé : Échangez en toute sécurité des données en temps réel entre les organisations et les clouds en utilisant le protocole ouvert Delta Sharing, ce qui élimine la nécessité d'une ETL complexe ou d'une copie des données.
Unity Catalog est également disponible en tant qu’implémentation open source. Consultez le blog d’annonce et le dépôt GitHub du catalogue Unity public.
Modèle objet du catalogue Unity
Dans le catalogue Unity, chaque ressource que vous régissez est modélisée en tant qu’objet. Plus précisément, ces objets sont appelés objets sécurisables dans le catalogue Unity. Vous pouvez utiliser des stratégies de contrôle d’accès et des métadonnées telles que des balises pour régir ces objets sécurisables.
Les objets sécurisables vivent dans la hiérarchie du modèle objet catalogue Unity, enracinés dans un objet spécial appelé metastore. Sous celui-ci, les ressources de données telles que les tables, les vues, les volumes, les fonctions et les modèles suivent un espace de noms à trois niveaux (catalog.schema.object). D’autres objets, tels que les informations d’identification de stockage, les emplacements externes, les connexions et les partages, se trouvent directement sous le metastore.
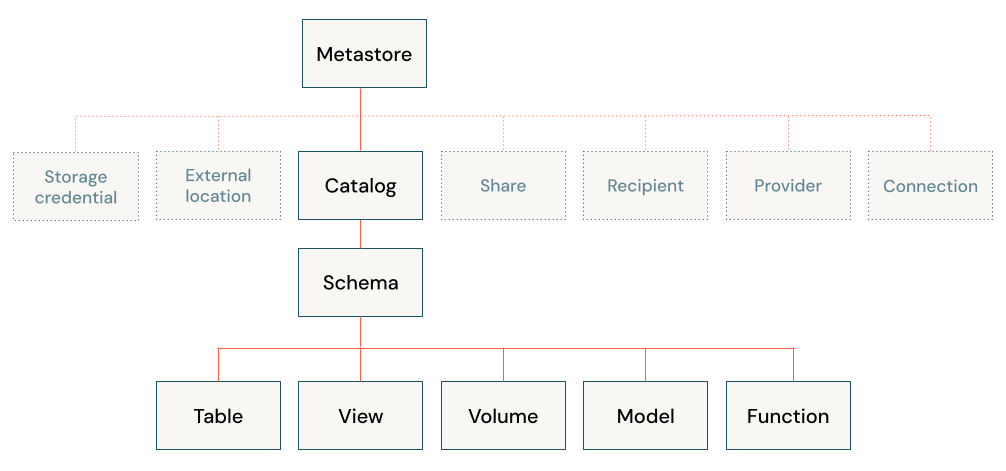
Cette hiérarchie est la base de la façon dont Unity Catalog organise les ressources et applique la gouvernance. Pour comprendre plus en détail le modèle d'objet du Catalogue Unity et chaque objet sécurisable, consultez la référence des objets sécurisables du Catalogue Unity. Pour comprendre le fonctionnement du modèle d’autorisations dans le contexte du modèle objet Unity Catalog, consultez les concepts du modèle d’autorisations du Unity Catalog.
Rôles d’administrateur
Les administrateurs sont responsables de la supervision de la gouvernance dans le catalogue Unity. Voici les différents niveaux de rôles d’administrateur et leurs privilèges par défaut :
- Les administrateurs de compte peuvent créer des metastores, lier des espaces de travail à des metastores, ajouter des utilisateurs et attribuer des privilèges sur les metastores.
- Les administrateurs d’espace de travail peuvent ajouter des utilisateurs à un espace de travail et gérer de nombreux objets spécifiques à l’espace de travail, tels que des travaux et des notebooks. Selon l’espace de travail, les administrateurs d’espace de travail peuvent également avoir de nombreux privilèges sur le metastore attaché à l’espace de travail.
- Les administrateurs de metastore sont des rôles facultatifs qui peuvent gérer le stockage de tables et de volumes au niveau du metastore. Il est également pratique de gérer les données de manière centralisée sur plusieurs espaces de travail d’une région.
Pour plus d’informations, consultez Privilèges d’administrateur dans le catalogue Unity.
Octroi et révocation de l’accès aux objets sécurisables
Les utilisateurs privilégiés peuvent accorder et révoquer l’accès aux objets sécurisables à n’importe quel niveau de la hiérarchie, y compris le metastore lui-même. L’accès à un objet accorde implicitement le même accès à tous les enfants de cet objet, sauf si l’accès est révoqué.
Vous pouvez utiliser les commandes SQL ANSI classiques pour accorder et révoquer l’accès aux objets dans Unity Catalog. Par exemple :
GRANT CREATE TABLE ON SCHEMA mycatalog.myschema TO `finance-team`;
Vous pouvez également utiliser Catalog Explorer, l’interface CLI Databricks et les API REST pour gérer les autorisations d’objets.
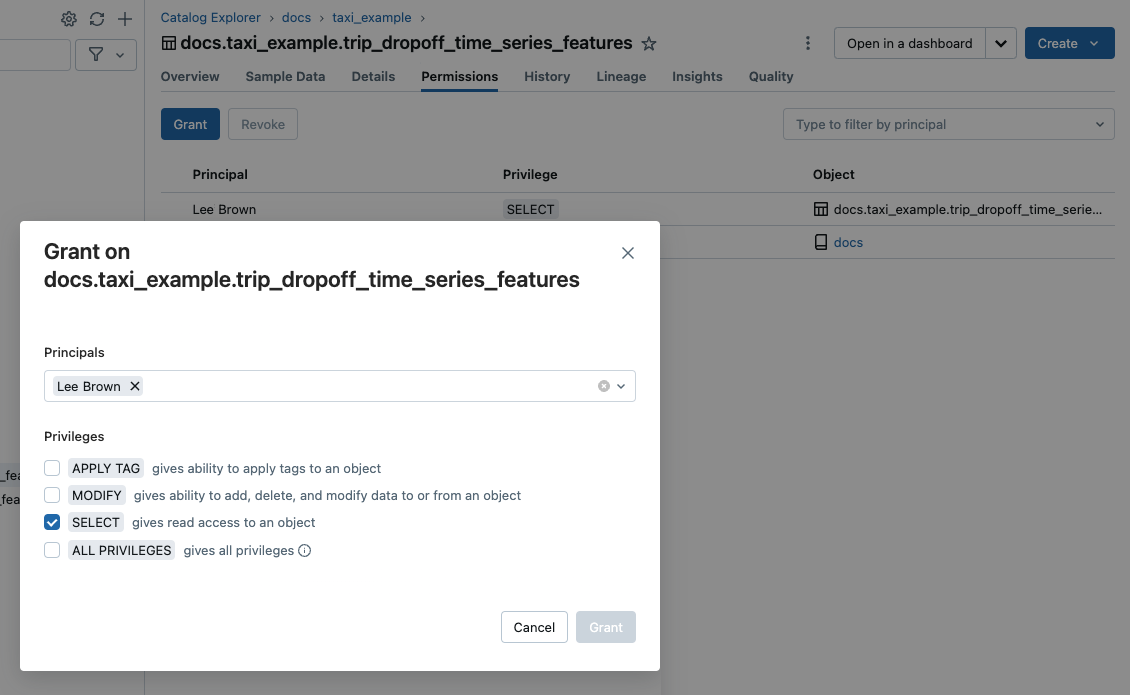
Les administrateurs de metastore, les propriétaires d’un objet et les utilisateurs disposant de l’objet MANAGE privilege peuvent accorder et révoquer l’accès. Pour savoir comment gérer les privilèges dans le catalogue Unity, consultez Gérer les privilèges dans le catalogue Unity.
Accès par défaut aux objets de base de données dans Unity Catalog
Unity Catalog opère selon principe du privilège minimum, à savoir que les utilisateurs disposent de l’accès minimum nécessaire pour effectuer leurs tâches requises. Lorsqu’un espace de travail est créé, les utilisateurs non administrateurs n’ont accès qu’au catalogue d’espaces de travail approvisionné automatiquement, ce qui permet aux utilisateurs d’essayer le processus de création et d’accès aux objets de base de données dans le catalogue Unity. Consultez les privilèges du catalogue d’espaces de travail.
Comparaison entre les tables et les volumes managés et externes
Les tables et les volumes peuvent être managés ou externes.
- Les tables managées sont entièrement gérées par Unity Catalog, ce qui signifie que Unity Catalog gère à la fois la gouvernance et les fichiers de données sous-jacents pour chaque table managée. Les tables managées sont stockées à un emplacement managé par Unity Catalog dans votre stockage cloud. Les tables managées utilisent toujours le format Delta Lake. Vous pouvez stocker les tables managées au niveau du metastore, du catalogue ou du schéma.
- Les tables externes sont des tables dont l’accès à partir d’Azure Databricks est géré par Unity Catalog, mais dont le cycle de vie des données et la disposition des fichiers sont gérés à l’aide de votre fournisseur de cloud et d’autres plateformes de données. En règle générale, les tables externes servent à inscrire de grandes quantités de données existantes dans Azure Databricks ou sont également utilisées si vous avez besoin d’un accès en écriture aux données à l’aide d’outils extérieurs à Azure Databricks. Les tables externes sont prises en charge dans plusieurs formats de données. Une fois qu'une table externe est inscrite dans un métastore Unity Catalog, vous pouvez gérer et auditer l'accès à Azure Databricks—et l'utiliser—tout comme vous pouvez avec des tables gérées.
- Les volumes managés sont entièrement gérés par Unity Catalog, ce qui signifie que Unity Catalog gère l’accès à l’emplacement de stockage du volume dans votre compte de fournisseur de cloud. Lorsque vous créez un volume managé, il est automatiquement stocké dans l’emplacement de stockage managé affecté au schéma conteneur.
- Les volumes externes représentent des données existantes dans des emplacements de stockage gérés en dehors d’Azure Databricks, mais inscrits dans Unity Catalog pour contrôler et auditer l’accès à partir d’Azure Databricks. Lorsque vous créez un volume externe dans Azure Databricks, vous spécifiez son emplacement, qui doit se trouver sur un chemin défini dans un emplacement externe du catalogue Unity.
Databricks recommande des tables et des volumes managés pour la plupart des cas d’usage, car ils vous permettent de tirer pleinement parti des fonctionnalités de gouvernance et d’optimisations des performances du catalogue Unity. Pour plus d’informations sur les cas d’utilisation classiques pour les tables et les volumes externes, consultez Les tables managées et externes et les volumes managés et externes.
Voir aussi :
- Tables gérées du Unity Catalog dans Azure Databricks pour Delta Lake et Apache Iceberg
- Utiliser des tables externes
- Volumes managés et externes.
Stockage cloud et isolation des données
Unity Catalog utilise le stockage cloud de deux manières principales :
- Stockage managé : emplacements par défaut pour les tables gérées et les volumes managés (données non structurées et non tabulaires) que vous créez dans Azure Databricks. Ces emplacements de stockage managé peuvent être définis au niveau du metastore, du catalogue ou du schéma. Vous créez des emplacements de stockage managés dans votre fournisseur de cloud, mais leur cycle de vie est entièrement géré par le catalogue Unity.
- Emplacements de stockage où les tables et volumes externes sont stockés. Il s’agit de tables et de volumes dont l’accès à partir d’Azure Databricks est géré par Unity Catalog, mais dont le cycle de vie des données et la disposition des fichiers sont gérés à l’aide de votre fournisseur de cloud et d’autres plateformes de données. En règle générale, vous utilisez des tables ou des volumes externes pour inscrire de grandes quantités de vos données existantes dans Azure Databricks, ou si vous avez également besoin d’un accès en écriture aux données à l’aide d’outils en dehors d’Azure Databricks.
Gouvernance de l’accès au stockage cloud à l’aide d’emplacements externes
Les emplacements de stockage managé et les emplacements de stockage où les tables externes et les volumes sont stockés utilisent des objets sécurisables d’emplacement externe pour gérer l’accès à partir d’Azure Databricks. Les objets d’emplacement externe référencent un chemin de stockage cloud et les informations d’identification de stockage requises pour y accéder. Les informations d’identification de stockage sont elles-mêmes des objets sécurisables du catalogue Unity qui inscrivent les informations d’identification requises pour accéder à un chemin de stockage particulier. Ensemble, ces éléments sécurisables garantissent que l’accès au stockage est contrôlé et suivi par le catalogue Unity.
Le diagramme ci-dessous montre comment les emplacements externes référencent les informations d’identification de stockage et les emplacements de stockage cloud.
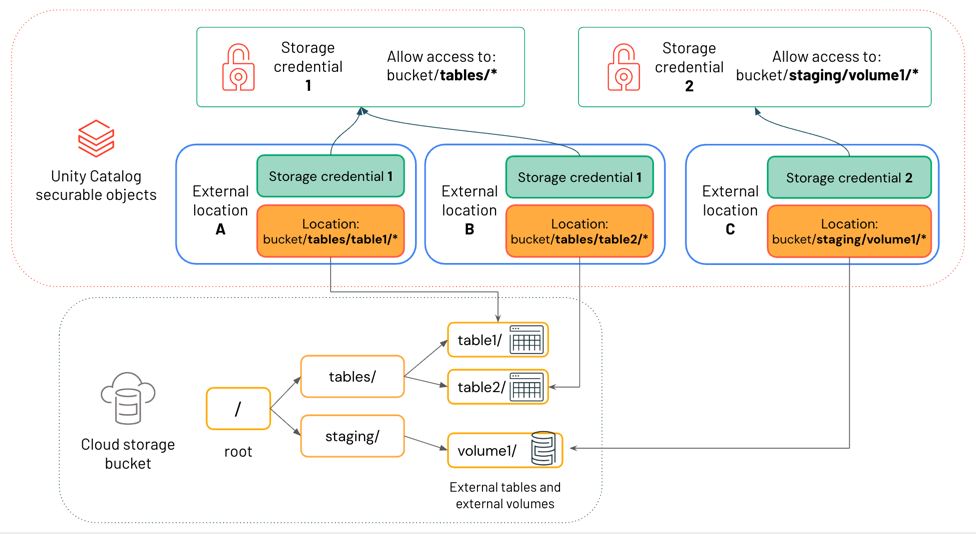
Dans ce diagramme :
- Chaque emplacement externe fait référence à des informations d’identification de stockage et à un emplacement de stockage cloud.
- Plusieurs emplacements externes peuvent référencer les mêmes informations d’identification de stockage.
Les informations d’identification de stockage 1 accordent l’accès à tout sous le chemin d’accès
bucket/tables/*, de sorte que l’emplacement externe A et l’emplacement externe B le référencent.
Pour plus d’informations, consultez Comment le catalogue Unity régit-t-il l’accès au stockage cloud ?.
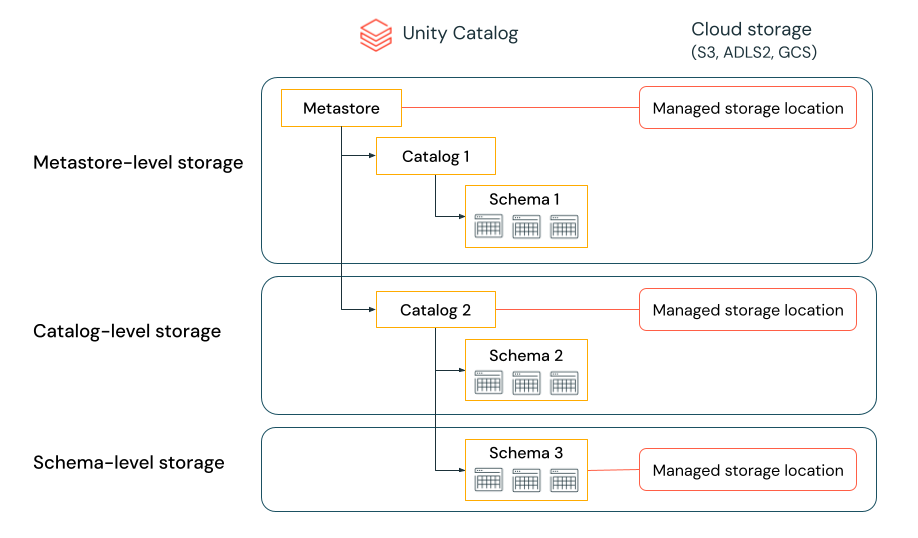
Hiérarchie des emplacements de stockage managé
Le niveau auquel vous définissez un stockage géré dans le catalogue Unity dépend de votre modèle d’isolation de données préféré. Votre organisation peut exiger que certains types de données soient stockés dans des comptes ou compartiments spécifiques dans votre locataire cloud.
Le catalogue Unity vous permet de configurer des emplacements de stockage managés au niveau du metastore, du catalogue ou du schéma pour répondre à ces exigences.
Par exemple, supposons que votre organisation dispose d’une stratégie de conformité d’entreprise qui nécessite des données de production relatives aux ressources humaines pour résider dans le conteneur abfss://mycompany-.hr-prod@storage-account.dfs.core.windows.net Dans le catalogue Unity, vous pouvez obtenir cette exigence en définissant un emplacement au niveau du catalogue, en créant un catalogue appelé, par exemple hr_prod, et en lui affectant l’emplacement abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Cela signifie que les tables ou volumes gérés créés dans le catalogue hr_prod (par exemple, à l'aide de CREATE TABLE hr_prod.default.table …) stockent leurs données dans abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Si vous le souhaitez, vous pouvez choisir de fournir des emplacements au niveau du schéma pour organiser les données dans hr_prod catalog à un niveau plus granulaire.
Si l’isolation du stockage n’est pas exigée pour certains catalogues, vous pouvez éventuellement définir un emplacement de stockage au niveau du metastore. Cet emplacement sert d’emplacement par défaut pour les tables managées et les volumes dans les catalogues et les schémas qui n’ont pas de stockage affecté. Cependant, Databricks vous recommande généralement d’attribuer des emplacements de stockage managés distincts pour chaque catalogue.
Le système évalue la hiérarchie des emplacements de stockage du schéma au catalogue, puis au metastore.
Par exemple, si une table myCatalog.mySchema.myTable est créée dans my-region-metastore, l’emplacement de stockage de la table est déterminé en fonction de la règle suivante :
- Si un emplacement a été fourni pour
mySchema, elle sera stockée là. - Si ce n’est pas le cas et qu’un emplacement a été fourni sur
myCatalog, elle sera stockée là. - Enfin, si aucun emplacement n’a été fourni sur
myCatalog, elle sera stockée à l’emplacement associé àmy-region-metastore.
Pour plus d’informations, consultez Spécifier un emplacement de stockage managé dans le catalogue Unity.
Isolation de l’environnement à l’aide de la liaison entre l'espace de travail et le catalogue
Par défaut, les propriétaires de catalogue (et les administrateurs de metastore, s’ils sont définis pour le compte) peuvent rendre un catalogue accessible aux utilisateurs dans plusieurs espaces de travail attachés au même metastore Unity Catalog.
Les exigences organisationnelles et de conformité spécifient souvent que vous conservez certaines données, telles que les informations d’identification personnelle, accessibles uniquement dans certains environnements. Vous pouvez également conserver les données de production isolées des environnements de développement ou vous assurer que certains jeux de données et domaines ne sont jamais regroupés.
Dans Azure Databricks, l’espace de travail est l’environnement de traitement des données principal et les catalogues sont le domaine de données principal. Le catalogue Unity permet aux administrateurs de metastore, aux propriétaires de catalogue et aux utilisateurs disposant de l’autorisation MANAGE d’attribuer ou de « lier » des catalogues à des espaces de travail spécifiques. Ces liaisons prenant en charge l’environnement vous permettent de vous assurer que seuls certains catalogues sont disponibles dans un espace de travail, quels que soient les privilèges spécifiques sur les objets de données accordés à un utilisateur. Cependant, si vous utilisez des espaces de travail pour isoler l’accès aux données utilisateur, vous avez peut-être intérêt à limiter l’accès au catalogue à des espaces de travail spécifiques dans votre compte, afin de garantir que certains types de données ne soient traités que dans ces espaces de travail. Vous pouvez souhaiter disposer d’espaces de travail de production et de développement distincts, par exemple, ou d’un espace de travail distinct pour le traitement des données sensibles. Il s’agit de la liaison catalogue-espace de travail. Consultez Limiter l’accès au catalogue à des espaces de travail spécifiques.
Remarque
Pour une isolation accrue des données, vous pouvez également lier l’accès au stockage cloud et l’accès au service cloud à des espaces de travail spécifiques. Voir (Facultatif) Affecter des informations d’identification de stockage à des espaces de travail spécifiques, (Facultatif) Affecter un emplacement externe à des espaces de travail spécifiques et (Facultatif) Affecter des informations d’identification de service à des espaces de travail spécifiques.
Comment faire configurer le catalogue Unity pour mon organisation ?
Pour utiliser Unity Catalog, votre espace de travail Azure Databricks doit être activé pour Unity Catalog, ce qui signifie que l’espace de travail est attaché à un metastore Unity Catalog.
Comment un espace de travail est-il attaché à un metastore ? Cela dépend du compte et de l’espace de travail :
- En règle générale, lorsque vous créez un espace de travail Azure Databricks dans une région pour la première fois, le metastore est créé automatiquement et attaché à l’espace de travail.
- Pour certains comptes anciens, un administrateur de compte doit créer le metastore et affecter les espaces de travail de cette région au metastore. Pour obtenir des instructions, consultez Créer un metastore de catalogue Unity.
- Si un compte dispose déjà d’un metastore affecté pour une région, un administrateur de compte peut décider s’il faut attacher automatiquement le metastore à tous les nouveaux espaces de travail de cette région. Consultez Activer l’attribution automatique d’un metastore à de nouveaux espaces de travail.
Que votre espace de travail ait été activé automatiquement ou non pour Unity Catalog, les étapes suivantes sont également nécessaires pour commencer à utiliser Unity Catalog :
- Création de catalogues et de schémas en vue d’accueillir les objets de base de données comme les tables et les volumes.
- Création d’emplacements de stockage managés pour stocker les tables et les volumes managés dans ces catalogues et schémas.
- Octroi d’un accès utilisateur aux catalogues, schémas et objets de base de données.
Les espaces de travail qui sont automatiquement activés pour le catalogue Unity approvisionnent un catalogue d’espaces de travail avec des privilèges étendus accordés à tous les utilisateurs de l’espace de travail. Ce catalogue est un point de départ pratique pour essayer Unity Catalog.
Pour obtenir des instructions d’installation détaillées, consultez Prise en main du catalogue Unity.
Mise à niveau d’un espace de travail existant vers le catalogue Unity
Pour savoir comment mettre à niveau un espace de travail de catalogue non Unity vers Unity Catalog, consultez Mettre à niveau un espace de travail Azure Databricks vers Unity Catalog.
Exigences et restrictions de Unity Catalog
Unity Catalog exige certains types de calcul et de formats de fichiers, dont vous trouverez la description ci-dessous. De même, vous trouverez ensuite mention de certaines fonctionnalités Azure Databricks qui ne sont pas entièrement prises en charge dans Unity Catalog sur toutes les versions de Databricks Runtime.
Prise en charge des régions
Toutes les régions prennent en charge Unity Catalog. Pour plus d’informations, consultez les régions Azure Databricks.
Exigences de calcul
Unity Catalog est pris en charge sur les clusters qui exécutent Databricks Runtime 11.3 LTS ou version ultérieure. Le catalogue Unity est pris en charge par défaut sur toutes les versions de calcul de l’entrepôt SQL .
Les clusters s’exécutant sur des versions antérieures de Databricks Runtime ne prennent pas en charge toutes les fonctionnalités et fonctionnalités d’Unity Catalog GA.
Pour accéder aux données dans le catalogue Unity, les clusters doivent être configurés avec le mode d’accès approprié. Unity Catalog est sécurisé par défaut. Si un cluster n’est pas configuré avec le mode d’accès standard ou dédié, le cluster ne peut pas accéder aux données dans le catalogue Unity. Consultez les modes d’accès.
Pour plus d’informations sur les modifications des fonctionnalités du catalogue Unity dans chaque version de Databricks Runtime, consultez les notes de publication.
Prise en charge des formats de fichiers
Unity Catalog prend en charge les formats de tableau suivants :
-
Les tables gérées doivent utiliser le format
delta, ouicebergformat de table. -
Les tables externes peuvent utiliser
delta,CSVJSONavroparquetORCou .text
Limites
Unity Catalog présente les limitations suivantes. Certaines d’entre elles sont propres aux anciennes versions de Databricks Runtime et aux modes d’accès au calcul.
Les charges de travail Structured Streaming présentent d’autres limitations, qui dépendent de Databricks Runtime et du mode d’accès. Consultez les exigences et limitations de calcul standard , ainsi que les exigences et limitations de calcul dédiées.
Databricks publie régulièrement de nouvelles fonctionnalités qui réduisent cette liste.
Les groupes créés antérieurement dans un espace de travail (c’est-à-dire, des groupes au niveau de l’espace de travail) ne peuvent pas être utilisés dans les instructions
GRANTde Unity Catalog. Cela permet d’obtenir une vue cohérente des groupes qui peuvent s’étendre sur plusieurs espaces de travail. Pour utiliser des groupes dans les instructionsGRANT, créez vos groupes au niveau du compte et mettez à jour toute automatisation pour la gestion des principals ou des groupes (par exemple, les connecteurs SCIM, Okta et Microsoft Entra ID, et Terraform) pour se référer aux points de terminaison de compte au lieu de ceux de l’espace de travail. Consultez Sources de groupe.Les charges de travail en langage R ne prennent pas en charge les vues dynamiques dans le cadre de la sécurité au niveau des lignes ou des colonnes sur un calcul exécutant Databricks Runtime 15.3 et les versions antérieures.
- Utilisez une ressource de calcul dédiée exécutant Databricks Runtime 15.4 LTS ou une version ultérieure pour les charges de travail dans R qui interrogent des vues dynamiques. Ces charges de travail nécessitent également un espace de travail qui supporte le calcul sans serveur. Pour plus d’informations, consultez Contrôle d’accès affiné sur le calcul dédié.
Une table managée peut être clonée en mode superficiel vers une autre table managée sur Databricks Runtime 13.3 LTS et versions ultérieures. Une table externe peut être superficiellement clonée vers une autre table externe sur Databricks Runtime 14.2 et versions ultérieures. Une table managée ne peut pas être clonée de manière superficielle en une table externe. En outre, une table externe ne peut pas être clonée de manière superficielle dans une table gérée. Pour plus d’informations, consultez Clonage peu profond pour les tables du catalogue Unity.
Le compartimentage n’est pas pris en charge pour les tables Unity Catalog. Si vous exécutez des commandes qui tentent de créer une table compartimentée dans Unity Catalog, une exception est levée.
Écrire dans le même chemin ou dans la même table Delta Lake depuis des espaces de travail situés dans plusieurs régions peut entraîner une performance peu fiable si certains clusters accèdent à Unity Catalog et d'autres non.
Manipulation de partitions pour des tables externes à l’aide de commandes telles que
ALTER TABLE ADD PARTITIONqui nécessite l’activation de la journalisation des métadonnées de partition. Consultez Découverte de partition pour les tables externes.Lorsque vous utilisez le mode de remplacement pour les tables non au format Delta, l’utilisateur doit avoir le CREATE TABLE privilège sur le schéma parent et doit être le propriétaire de l’objet existant OU avoir le privilège MODIFY sur l’objet.
Les UDF Python ne sont pas prises en charge dans Databricks Runtime 12.2 LTS et versions inférieures. Cela englobe les fonctions UDAF, UDTF et Pandas sur Spark (
applyInPandasetmapInPandas). Les fonctions UDF scalaires Python sont prises en charge dans Databricks Runtime 13.3 LTS et versions supérieures.Les fonctions définies par l’utilisateur Scala ne sont pas prises en charge dans Databricks Runtime 14.1 et versions antérieures avec le mode d’accès standard. Les fonctions UDF scalaires sont prises en charge dans Databricks Runtime 14.2 et les versions ultérieures avec le mode d'accès standard sur les machines de calcul.
Les pools de threads Scala standard ne sont pas pris en charge. En lieu et place, utilisez les pools de threads spéciaux dans
org.apache.spark.util.ThreadUtils, par exemple,org.apache.spark.util.ThreadUtils.newDaemonFixedThreadPool. Toutefois, les pools de threads suivants dansThreadUtilsne sont pas pris en charge :ThreadUtils.newForkJoinPoolet tout pool de threadsScheduledExecutorService.
- Les journaux de diagnostic Azure journalisent uniquement les événements du catalogue Unity au niveau de l’espace de travail. Pour afficher les actions au niveau du compte, vous devez utiliser la table système du journal d’audit. Consultez Référence de table système du journal d’audit.
Les modèles inscrits dans Unity Catalog présentent d’autres limitations. Voir Limitations.
Quotas de ressources
Unity Catalog applique des quotas de ressources sur tous les objets sécurisables. Ces quotas sont répertoriés dans les limites des ressources. Si vous prévoyez de dépasser ces limites de ressources, contactez l’équipe de votre compte Azure Databricks.
Vous pouvez surveiller l’utilisation de vos quotas à l’aide des API de quotas de ressources d’Unity Catalog. Consultez Surveiller votre utilisation des quotas de ressources du catalogue Unity.