Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, la business intelligence et le reporting. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité de copie dans des pipelines Azure Data Factory et Azure Synapse Analytics pour copier des données à partir de Google BigQuery. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Important
Le connecteur Google BigQuery V1 est à l’étape de suppression. Il est recommandé de mettre à niveau le connecteur Google BigQuery de V1 vers V2.
Fonctionnalités prises en charge
Ce connecteur Google BigQuery est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | (1) (2) |
| Activité de recherche | (1) (2) |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau banques de données prises en charge.
Le service fournit un pilote intégré pour permettre la connectivité. Vous n’avez donc pas besoin d’installer manuellement un pilote pour utiliser ce connecteur.
Remarque
Ce connecteur Google BigQuery repose sur les API BigQuery. N’oubliez pas que BigQuery limite le taux maximal de requêtes entrantes et applique des quotas appropriés sur une base par projet. Reportez-vous à Quotas et limites - requêtes d’API. Assurez-vous que vous ne déclenchez pas trop de demandes simultanées pour le compte.
Bien démarrer
Pour effectuer l’activité Copy avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- Outil Copier des données
- portail Azure
- Kit de développement logiciel (SDK) .NET
- Kit de développement logiciel (SDK) Python
- Azure PowerShell
- REST API
- Modèle Azure Resource Manager
Créer un service lié à Google BigQuery à l’aide de l’interface utilisateur
Suivez les étapes suivantes pour créer un service lié à Google BigQuery dans l’interface utilisateur du portail Azure.
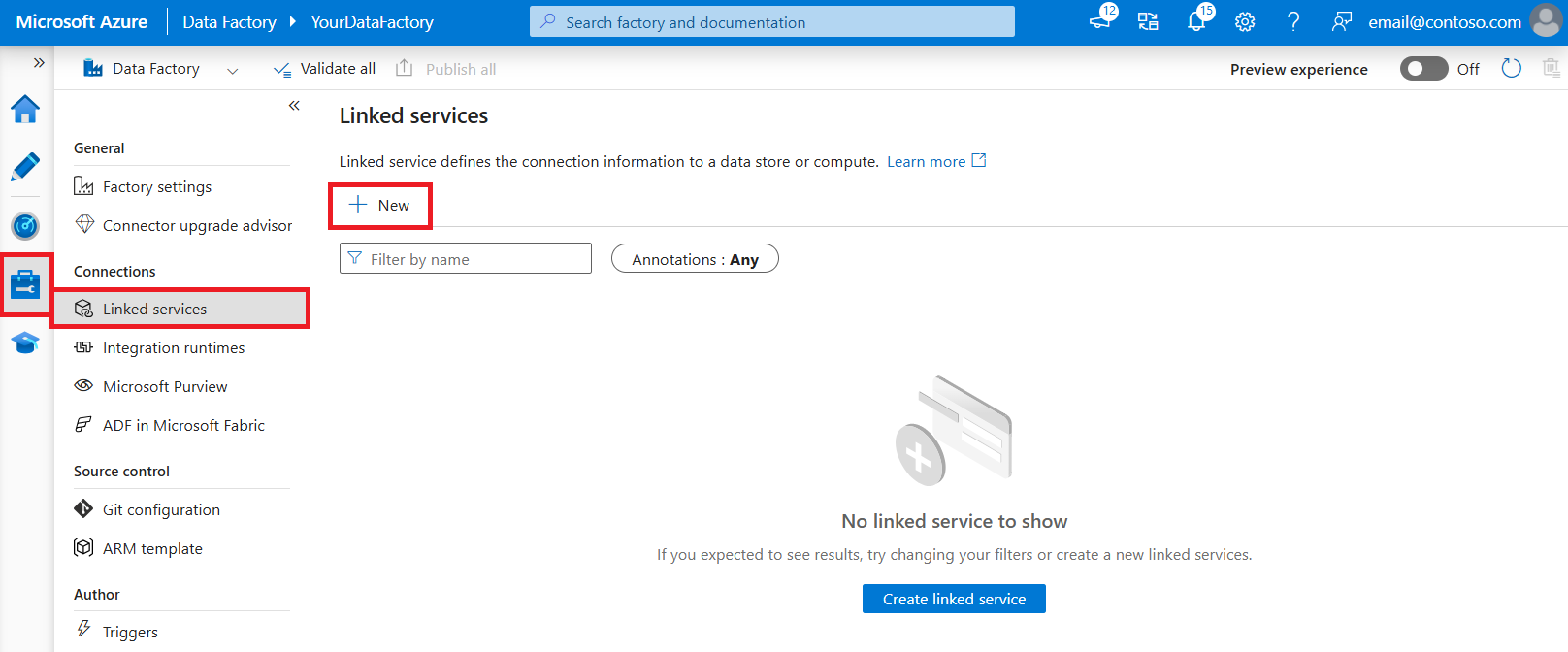
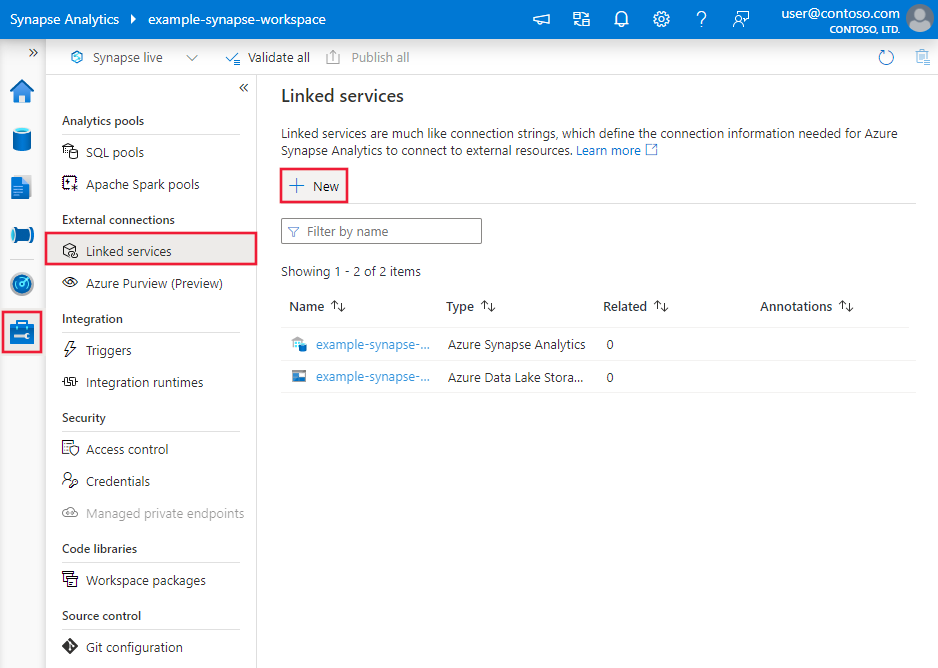
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Google BigQuery, puis sélectionnez le connecteur.
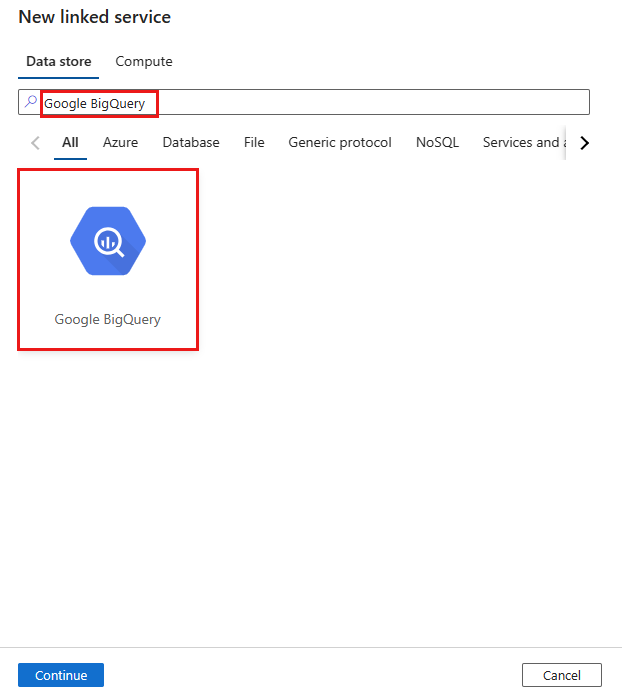
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
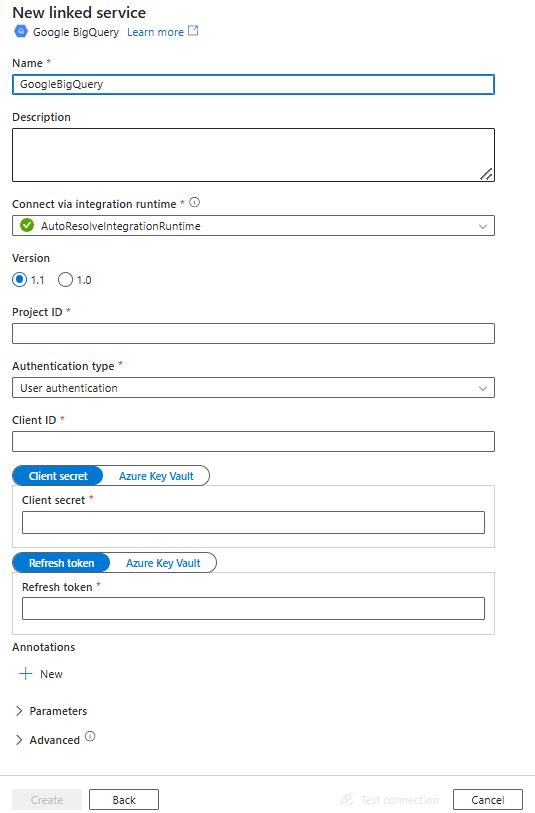
Détails de configuration du connecteur
Les sections suivantes fournissent des informations détaillées sur les propriétés utilisées pour définir les entités spécifiques du connecteur Google BigQuery.
Propriétés du service lié
Les propriétés prises en charge pour le service lié Google BigQuery sont les suivantes.
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type doit avoir la valeur GoogleBigQueryV2. | Oui |
| version | Version que vous spécifiez. Recommandez la mise à niveau vers la dernière version pour tirer parti des dernières améliorations. | Oui pour la version 1.1 |
| projectId | L’ID du projet BigQuery par défaut sur lequel exécuter la requête. | Oui |
| type d'authentification | Mécanisme d’authentification OAuth 2.0 utilisé pour l’authentification.
Les valeurs autorisées sont UserAuthentication et ServiceAuthentication. Reportez-vous aux sections suivant ce tableau pour accéder à d’autres propriétés et à des exemples JSON sur ces types d’authentification. |
Oui |
Utiliser l’authentification utilisateur
Définissez la valeur de la propriété « authenticationType » sur UserAuthentication et spécifiez les propriétés suivantes ainsi que les propriétés génériques décrites dans la section précédente :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| clientId | ID de l’application utilisée pour générer le jeton d’actualisation. | Oui |
| Secret du client | Secret de l’application utilisée pour générer le jeton d’actualisation. Marquez ce champ en tant que SecureString afin de le stocker de façon sécurisée, ou référencez un secret stocké dans Azure Key Vault. | Oui |
| refreshToken | Le jeton d’actualisation obtenu de Google servant à autoriser l’accès à BigQuery. Découvrez comment en obtenir un en consultant Obtention de jetons d’accès OAuth 2.0 et ce blog de communauté. Marquez ce champ en tant que SecureString afin de le stocker de façon sécurisée, ou référencez un secret stocké dans Azure Key Vault. | Oui |
Exemple :
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"version": "1.1",
"typeProperties": {
"projectId" : "<project ID>",
"authenticationType" : "UserAuthentication",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value":"<client secret>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Utiliser l’authentification du service
Définissez la valeur de la propriété « authenticationType » sur ServiceAuthentication et spécifiez les propriétés suivantes ainsi que les propriétés génériques décrites dans la section précédente.
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| keyFileContent | Fichier de clé au format JSON utilisé pour authentifier le compte de service. Marquez ce champ en tant que SecureString afin de le stocker de façon sécurisée, ou référencez un secret stocké dans Azure Key Vault. | Oui |
Exemple :
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"version": "1.1",
"typeProperties": {
"projectId": "<project ID>",
"authenticationType": "ServiceAuthentication",
"keyFileContent": {
"type": "SecureString",
"value": "<key file JSON string>"
}
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Google BigQuery.
Pour copier des données à partir de Google BigQuery, affectez à la propriété type du jeu de données la valeur GoogleBigQueryV2Object. Les propriétés prises en charge sont les suivantes :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit avoir la valeur : GoogleBigQueryV2Object | Oui |
| ensemble de données | Nom du jeu de données Google BigQuery. | Non (si « query » dans la source de l’activité est spécifié) |
| table | Nom de la table. | Non (si « query » dans la source de l’activité est spécifié) |
Exemple
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryV2Object",
"linkedServiceName": {
"referenceName": "<Google BigQuery linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"dataset": "<dataset name>",
"table": "<table name>"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par le type de source Google BigQuery.
GoogleBigQuerySource en tant que type de source
Pour copier des données à partir de Google BigQuery, affectez au type de source de l’activité Copy la valeur GoogleBigQueryV2Source. Les propriétés suivantes sont prises en charge dans la section source de l’activité de copie.
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité Copy doit avoir la valeur GoogleBigQueryV2Source. | Oui |
| requête | Utiliser la requête SQL personnalisée pour lire les données. par exemple "SELECT * FROM MyTable". Pour plus d’informations, consultez Syntaxe de requête. |
Non (si « dataset » et « table » dans le jeu de données sont spécifiés) |
Exemple :
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<Google BigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQueryV2Source",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mappage de type de données pour Google BigQuery V2
Lorsque vous copiez des données de Google BigQuery, les mappages suivants sont utilisés entre les types de données Google BigQuery et les types de données intermédiaires en interne dans le service. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, consultez Mappage de schéma dans l’activité de copie.
| Type de données Google BigQuery | Type de données de service intermédiaire |
|---|---|
| JSON | Chaîne |
| STRING | Chaîne |
| BYTES | Tableau d’octets |
| INTEGER | Int64 |
| FLOAT | Double |
| NUMÉRIQUE | Decimal |
| BIGNUMERIC | Chaîne |
| BOOLEAN | Booléen |
| TIMESTAMP | DateTimeOffset |
| DATE | Date et heure |
| TIME | TimeSpan |
| DateHeure | DateTimeOffset |
| GÉOGRAPHIE | Chaîne |
| RECORD/STRUCT | Chaîne |
| ARRAY | Chaîne |
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Cycle de vie et mise à niveau du connecteur Google BigQuery
Le tableau suivant présente la phase de publication et les journaux des modifications pour différentes versions du connecteur Google BigQuery :
| Version | Phase de mise en production | Journal des modifications |
|---|---|---|
| Google BigQuery V1 | Removed | Non applicable. |
| Google BigQuery V2 (version 1.0) | Version en disponibilité générale disponible | • L’authentification du service est prise en charge par le runtime d’intégration Azure et le runtime d’intégration auto-hébergé. Les propriétés trustedCertPath, useSystemTrustStoreemail et keyFilePath ne sont pas prises en charge, car elles sont disponibles uniquement sur le runtime d’intégration auto-hébergé. • requestGoogleDriveScope n’est pas pris en charge. Vous devez également appliquer l’autorisation dans le service Google BigQuery en consultant les articles Choisir les champs d’application de l’API Google Drive et Interroger des données Drive. • additionalProjects n’est pas pris en charge. En guise d’alternative, interrogez un ensemble de données public avec la console Google Cloud.• NUMBER est lu en tant que type de données décimal. • Timestamp et Datetime sont lus en tant que type de données DateTimeOffset. |
| Google BigQuery V2 (version 1.1) | Version en disponibilité générale disponible | • Correction d’un bogue : lors de l’exécution de plusieurs instructions, query renvoie désormais les résultats de la première instruction après avoir exclu les instructions d’évaluation, plutôt que de toujours retourner le résultat de la première instruction. |
Mise à jour du connecteur Google BigQuery
Pour mettre à niveau votre connecteur Google BigQuery :
De V1 à V2 :
Créez un service lié Google BigQuery et configurez-le en faisant référence aux propriétés du service lié.De V2 version 1.0 à la version 1.1 :
Dans la page Modifier le service lié , sélectionnez 1.1 pour la version. Pour plus d’informations, consultez Propriétés de service lié.
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité Copy.