Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, la business intelligence et le reporting. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité de copie dans des pipelines Azure Data Factory et Synapse Analytics pour copier des données vers et depuis une base de données MongoDB. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Important
Le nouveau connecteur MongoDB fournit une prise en charge native améliorée de MongoDB. Si vous utilisez le connecteur MongoDB hérité, pris en charge tel quel à des fins de compatibilité descendante uniquement, dans votre solution, consultez l’article Connecteur MongoDB (hérité).
Fonctionnalités prises en charge
Ce connecteur MongoDB est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité Copy (source/récepteur) | (1) (2) |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des magasins de données pris en charge en tant que sources et récepteurs, consultez la table Magasins de données pris en charge.
Plus précisément, ce connecteur MongoDB prend en charge les versions jusqu’à 4.2. Si votre travail nécessite des versions plus récentes que 4.2, envisagez d’utiliser MongoDB Atlas avec le connecteur MongoDB Atlas qui fournit des fonctionnalités et une prise en charge plus complètes.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Prise en main
Pour effectuer l’activité de copie avec un pipeline, vous pouvez utiliser l’un des outils ou kits sdk suivants :
- Outil Copier des données
- portail Azure
- Kit de développement logiciel (SDK) .NET
- Kit de développement logiciel (SDK) Python
- Azure PowerShell
- REST API
- Modèle Azure Resource Manager
Créer un service lié à MongoDB à l’aide de l’interface utilisateur
Suivez les étapes suivantes pour créer un service lié à MongoDB dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Mongo et sélectionnez le connecteur MongoDB.
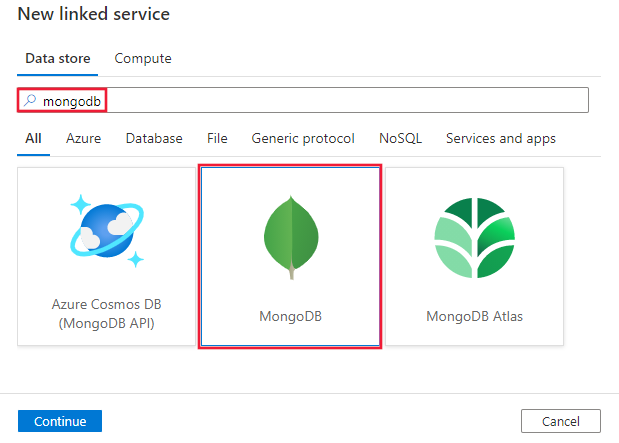
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
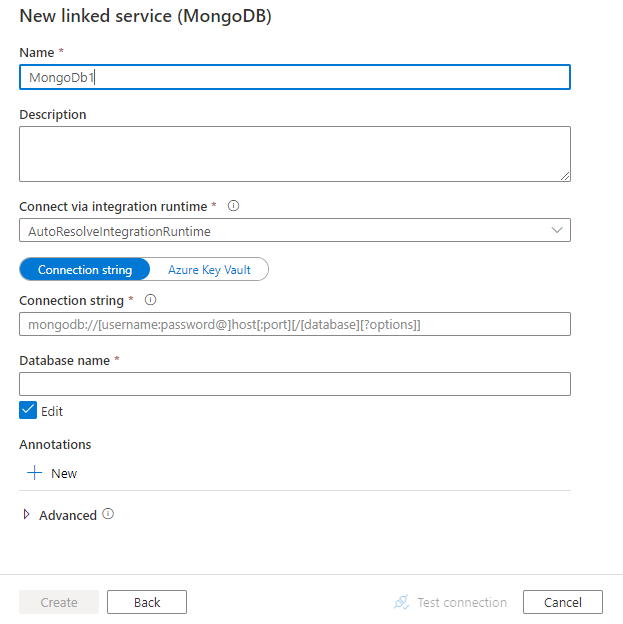
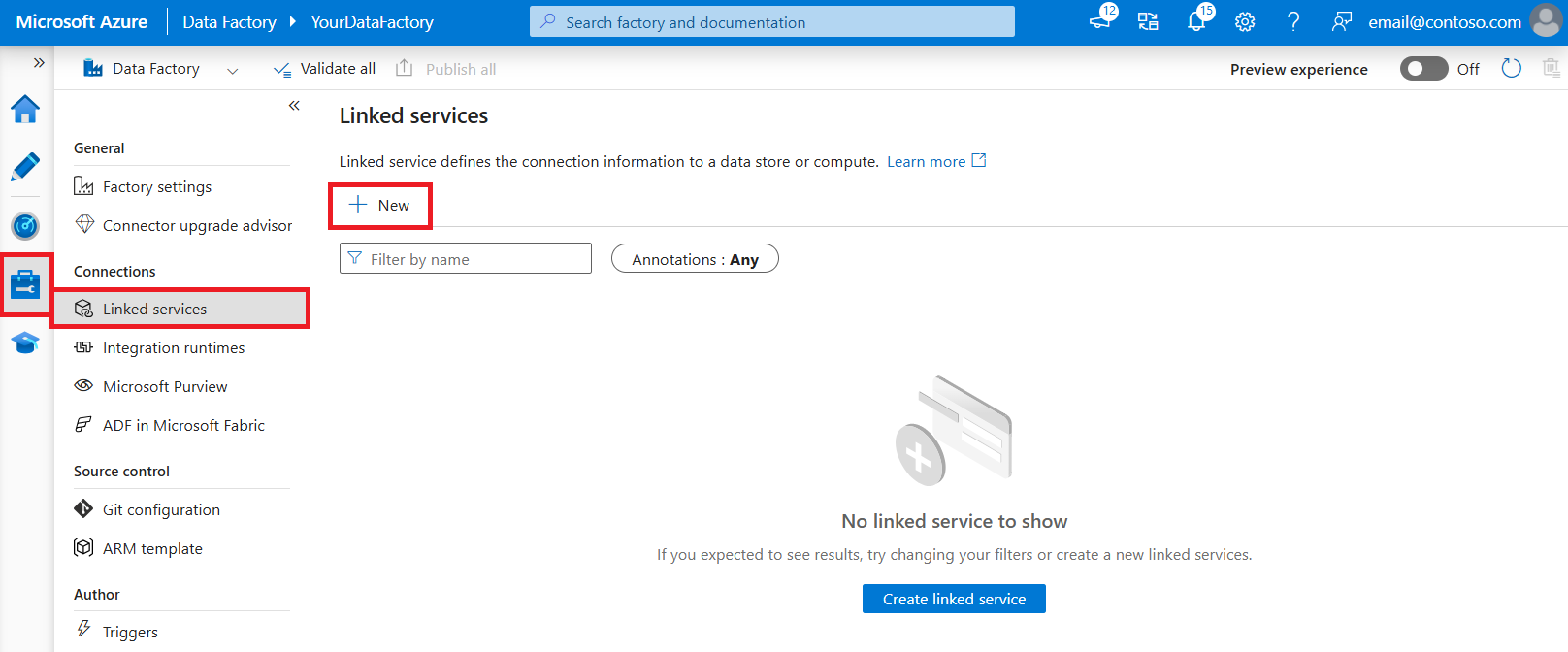
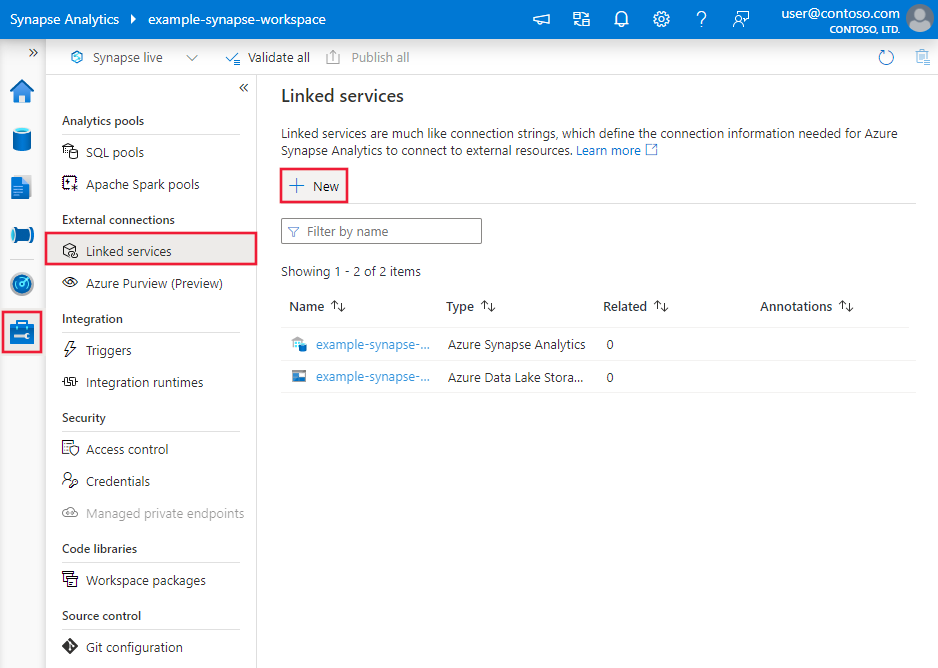
Détails de configuration du connecteur
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory spécifiques du connecteur MongoDB.
Propriétés du service lié
Les propriétés prises en charge pour le service lié MongoDB sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur : MongoDbV2 | Oui |
| connectionString | Spécifiez la chaîne de connexion MongoDB, par exemple mongodb://[username:password@]host[:port][/[database][?options]]. Pour plus d’informations, consultez le manuel MongoDB sur la chaîne de connexion. Vous pouvez également stocker une chaîne de connexion dans Azure Key Vault. Pour plus d’informations, consultez la section Stocker des informations d’identification dans Azure Key Vault. |
Oui |
| database | Nom de la base de données à laquelle vous souhaitez accéder. | Oui |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemple :
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDbV2",
"typeProperties": {
"connectionString": "mongodb://[username:password@]host[:port][/[database][?options]]",
"database": "myDatabase"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez Jeux de données et services liés. Les propriétés suivantes sont prises en charge pour le jeu de données MongoDB :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur : MongoDbV2Collection | Oui |
| collectionName | Nom de la collection dans la base de données MongoDB. | Oui |
Exemple :
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbV2Collection",
"typeProperties": {
"collectionName": "<Collection name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source et le récepteur MongoDB.
MongoDB en tant que source
Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité Copy doit être définie sur : MongoDbV2Source | Oui |
| Filter | Spécifie le filtre de sélection à l’aide d’opérateurs de requête. Pour retourner tous les documents dans une collection, omettez ce paramètre ou passez un document vide ({}). | Non |
| cursorMethods.project | Spécifie les champs à retourner dans les documents pour la projection. Pour retourner tous les champs dans les documents correspondants, omettez ce paramètre. | Non |
| cursorMethods.sort | Spécifie l’ordre dans lequel la requête retourne les documents correspondants. Voir cursor.sort(). | Non |
| cursorMethods.limit | Spécifie le nombre maximal de documents retournés par le serveur. Voir cursor.limit(). | Non |
| cursorMethods.skip | Spécifie le nombre de documents à ignorer, et à partir de quel endroit MongoDB commence à retourner des résultats. Voir cursor.skip(). | Non |
| batchSize | Spécifie le nombre de documents à retourner dans chaque lot de la réponse renvoyée par l’instance MongoDB. Dans la plupart des cas, la modification de la taille de lot n’affectera pas l’utilisateur ou l’application. Azure Cosmos DB limite la taille de chaque lot à 40 Mo, qui est la somme de la taille batchSize du nombre de documents. Par conséquent, diminuez cette valeur si la taille de votre document est trop grande. | Non (la valeur par défaut est 100) |
Conseil
Le service prend en charge la consommation de document BSON en mode Strict. Vérifiez que votre requête de filtre est en mode Strict plutôt qu’en mode Shell. Vous trouverez une description plus détaillée dans le manuel MongoDB.
Exemple :
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbV2Source",
"filter": "{datetimeData: {$gte: ISODate(\"2018-12-11T00:00:00.000Z\"),$lt: ISODate(\"2018-12-12T00:00:00.000Z\")}, _id: ObjectId(\"5acd7c3d0000000000000000\") }",
"cursorMethods": {
"project": "{ _id : 1, name : 1, age: 1, datetimeData: 1 }",
"sort": "{ age : 1 }",
"skip": 3,
"limit": 3
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
MongoDB en tant que récepteur
Les propriétés suivantes sont prises en charge dans la section sink de l’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur de l’activité de copie doit être définie sur MongoDbV2Sink. | Oui |
| writeBehavior | Décrit comment écrire des données dans MongoDB. Les valeurs autorisées sont insert et upsert. Le comportement de la valeur upsert consiste à remplacer le document si un document portant le même _id existe déjà ; sinon, le document est inséré.Remarque : le service génère automatiquement un _id pour un document si aucun _id n’est spécifié ni dans le document d’origine ni par le mappage de colonnes. Cela signifie que vous devez vérifier que votre document comporte un ID afin qu’upsert fonctionne comme prévu. |
Non (la valeur par défaut est insert) |
| writeBatchSize | La propriété writeBatchSize contrôle la taille des documents à écrire dans chaque lot. Vous pouvez essayer d’augmenter la valeur de writeBatchSize pour améliorer les performances et diminuer la valeur si la taille de votre document est grande. | Non (la valeur par défaut est 10 000) |
| writeBatchTimeout | Temps d’attente pour que l’opération d’insertion par lot soit terminée avant d’expirer. La valeur autorisée est timespan. | Non (la valeur par défaut est 00:30:00 – 30 minutes) |
Conseil
Pour importer des documents JSON en l’état, voir la section Importer ou exporter des documents JSON. Pour copier à partir de données sous forme tabulaire, voir Mappage de schéma.
Exemple
"activities":[
{
"name": "CopyToMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "MongoDbV2Sink",
"writeBehavior": "upsert"
}
}
}
]
Importer et exporter des documents JSON
À l’aide de ce connecteur Azure Cosmos MongoDB, vous pouvez facilement :
- Copier des documents entre deux collections MongoDB en l’état.
- Importer des documents JSON de différentes sources dans MongoDB, notamment depuis Azure Cosmos DB, le stockage Blob Azure, Azure Data Lake Store et d’autres magasins basés sur des fichiers pris en charge.
- Exporter des documents JSON d’une collection MongoDB vers différentes banques basées sur des fichiers.
Pour obtenir une telle copie indépendante du schéma, ignorez la section « structure » (également appelée schéma) dans le mappage de schéma et de jeu de données dans l’activité de copie.
Mappage de type de données pour MongoDB
Lors de la copie de données à partir de MongoDB, les mappages suivants sont utilisés des types de données MongoDB vers les types de données temporaires utilisés par le service en interne. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, voir Mappages de schémas et de types de données.
| Type de données MongoDB | Type de données de service intermédiaire |
|---|---|
| Date | Int64 |
| Identifiant d'objet (ObjectId) | Chaîne |
| Decimal128 | Chaîne |
| Horodatage | Les 32 bits les plus significatifs -> Int64 Les 32 bits les moins significatifs -> Int64 |
| Chaîne | Chaîne |
| Double | Chaîne |
| Int32 | Int64 |
| Int64 | Int64 |
| Booléen | Booléen |
| Null | Null |
| JavaScript | Chaîne |
| Expression régulière | Chaîne |
| Touche min | Int64 |
| Clé maximale | Int64 |
| Binary | Chaîne |
Cycle de vie et mise à niveau du connecteur MongoDB
Le tableau suivant présente l’étape de mise en production et les journaux des modifications pour différentes versions du connecteur MongoDB :
| Version | Phase de mise en production | Journal des modifications |
|---|---|---|
| MongoDB (hérité) | Fin du support | / |
| MongoDB | Version en disponibilité générale disponible | • Prise en charge des requêtes MongoDB équivalentes uniquement. • Le double est lu en tant que type de données String. |
Mettre à niveau le service lié MongoDB
Voici les étapes qui vous aideront à mettre à jour votre service associé et les requêtes associées :
Créez un service lié MongoDB et configurez-le en vous référant aux propriétés du service lié.
Si vous utilisez des requêtes SQL dans vos pipelines qui font référence à l'ancien service lié MongoDB, remplacez-les par les requêtes MongoDB équivalentes. Consultez le tableau suivant pour les exemples de remplacement :
requête SQL Requête MongoDB équivalente SELECT * FROM usersdb.users.find({})SELECT username, age FROM usersdb.users.find({}, {username: 1, age: 1})SELECT username AS User, age AS Age, statusNumber AS Status, CASE WHEN Status = 0 THEN "Pending" CASE WHEN Status = 1 THEN "Finished" ELSE "Unknown" END AS statusEnum LastUpdatedTime + interval '2' hour AS NewLastUpdatedTime FROM usersdb.users.aggregate([{ $project: { _id: 0, User: "$username", Age: "$age", Status: "$statusNumber", statusEnum: { $switch: { branches: [ { case: { $eq: ["$Status", 0] }, then: "Pending" }, { case: { $eq: ["$Status", 1] }, then: "Finished" } ], default: "Unknown" } }, NewLastUpdatedTime: { $add: ["$LastUpdatedTime", 2 * 60 * 60 * 1000] } } }])SELECT employees.name, departments.name AS department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.id;db.employees.aggregate([ { $lookup: { from: "departments", localField: "department_id", foreignField: "_id", as: "department" } }, { $unwind: "$department" }, { $project: { _id: 0, name: 1, department_name: "$department.name" } } ])
Contenu connexe
Consultez les banques de données prises en charge pour obtenir la liste des banques de données prises en charge en tant que sources et récepteurs par l’activité de copie.