La mise en cache est une technique courante qui vise à améliorer les performances et l’extensibilité d’un système. Il met les données en cache en copiant temporairement les données fréquemment consultées sur un stockage rapide situé à proximité de l'application. Si cet espace de stockage rapide des données se trouve plus près de l’application que la source d’origine, la mise en cache peut améliorer sensiblement les temps de réponse des applications clientes en fournissant les données plus rapidement.
La mise en cache est plus efficace quand une instance client lit à plusieurs reprises les mêmes données, en particulier si le magasin de données d’origine réunit les conditions suivantes :
- Il reste relativement statique.
- Il est lent par rapport à la vitesse du cache.
- Il est soumis à un niveau élevé de contention.
- Il est éloigné quand la latence du réseau peut ralentir l’accès.
Mise en cache dans les applications distribuées
Les applications distribuées implémentent généralement une des deux stratégies suivantes ou les deux lors de la mise en cache des données :
- Elles utilisent un cache privé, où les données sont conservées localement sur l'ordinateur qui exécute une instance d'une application ou d'un service.
- Elles utilisent un cache partagé, servant de source commune à laquelle peuvent accéder plusieurs processus et machines.
Dans les deux cas, la mise en cache peut être effectuée côté client et côté serveur. La mise en cache côté client est effectuée par le processus qui fournit l’interface utilisateur pour un système, tel qu’un navigateur web ou une application de bureau. La mise en cache côté serveur est effectuée par le processus qui fournit les services professionnels exécutés à distance.
Mise en cache privée
Le type de cache le plus élémentaire est un magasin en mémoire. Il est maintenu dans l’espace d’adressage d’un processus unique, et le code qui s’exécute dans ce processus y accède directement. L’accès à ce type de cache est rapide. Il peut également fournir un moyen efficace de stocker des quantités modestes de données statiques. La taille d’un cache est généralement limitée par la quantité de mémoire disponible sur l’ordinateur qui héberge le processus.
Si vous avez besoin de mettre en cache davantage d’informations que ce qui est physiquement possible en mémoire, vous pouvez écrire les données mises en cache dans le système de fichiers local. L'accès à ce processus sera plus lent que pour les données conservées en mémoire, mais il devrait néanmoins être plus rapide et plus fiable que la récupération de données sur un réseau.
Si plusieurs instances d’une application utilisant ce modèle s’exécutent simultanément, chaque instance a son propre cache indépendant contenant sa propre copie des données.
Il faut considérer un cache comme une capture instantanée des données d’origine à un moment donné dans le passé. Si ces données ne sont pas statiques, il est probable que différentes instances de l'application détiennent différentes versions des données dans leurs caches. Par conséquent, une même requête effectuée par ces instances peut renvoyer des résultats différents, comme l’illustre la Figure 1.
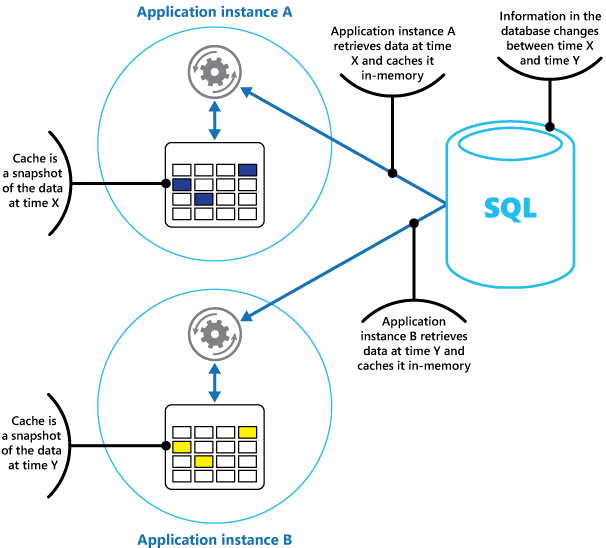
Figure 1 : Utilisation d’un cache en mémoire dans différentes instances d’une application.
Shared Caching (mise en cache partagé)
L'utilisation d'un cache partagé permet d'éviter que les données ne soient différentes dans chaque cache, ce qui peut se produire avec la mise en cache en mémoire. La mise en cache partagé garantit que les différentes instances d’application ont accès à la même vue des données mises en cache. Il place le cache dans un emplacement séparé, qui est généralement hébergé dans le cadre d'un service distinct, comme le montre la figure 2.
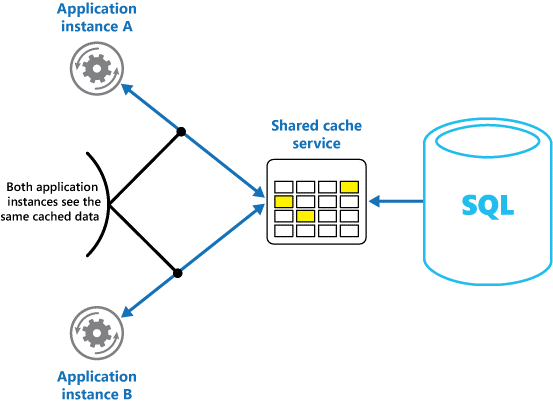
Figure 2 : Utilisation d’un cache partagé.
Un avantage important de l’approche de la mise en cache partagé est l’extensibilité qu’elle offre. De nombreux services de cache partagé sont implémentés à l'aide d'un cluster de serveurs et utilisent des logiciels qui distribuent les données dans le cluster de manière transparente. Une instance d’application envoie simplement une demande au service de cache (Cache Service). L’infrastructure sous-jacente détermine l’emplacement des données mises en cache dans le cluster. Vous pouvez facilement faire évoluer le cache en ajoutant des serveurs.
L’approche de mise en cache partagé présente essentiellement deux inconvénients :
- L'accès au cache est plus lent car il n'est plus conservé localement dans chaque instance de l'application.
- La nécessité d’implémenter un service de cache séparé peut compliquer la solution.
Considérations sur l’utilisation de la mise en cache
Les sections suivantes décrivent plus en détail les éléments à prendre en compte pour la conception et l’utilisation d'un cache.
Décider quand mettre en cache des données
La mise en cache peut améliorer considérablement les performances, l'extensibilité et la disponibilité. Plus vous avez de données et d’utilisateurs devant y accéder, plus la mise en cache est avantageuse. La mise en cache réduit la latence et les conflits associés au traitement de grands volumes de demandes simultanées dans le magasin de données d'origine.
Par exemple, une base de données peut prendre en charge un nombre limité de connexions concurrentielles. Toutefois, la récupération de données à partir d’un cache partagé plutôt qu’à partir de la base de données sous-jacente permet à une application cliente d’accéder à ces données, même si le nombre de connexions disponibles est épuisé. En outre, si la base de données devient indisponible, les applications clientes peuvent continuer à utiliser les données mises en cache.
Envisagez de mettre en cache des données fréquemment lues mais rarement modifiées (par exemple, des données faisant l’objet d’un plus grand nombre d’opérations de lecture que d’opérations d’écriture). Toutefois, il est déconseillé d’utiliser le cache comme magasin de référence pour des informations critiques. Au lieu de cela, assurez-vous que toutes les modifications que votre application ne peut pas se permettre de perdre sont toujours enregistrées dans un magasin de données persistant. Si le cache est indisponible, votre application peut continuer à fonctionner en utilisant le magasin de données, et vous ne perdrez pas d'informations importantes.
Déterminer comment mettre en cache des données de façon efficace
L’important lors de l’utilisation du cache est effectivement de déterminer les données les plus appropriées à mettre en cache et l’heure la plus adaptée pour cette opération. Les données peuvent être ajoutées au cache à la demande la première fois qu'elles sont récupérées par une application. L'application n'a besoin d'aller chercher les données qu'une seule fois dans le magasin de données, et cet accès ultérieur peut être satisfait en utilisant le cache.
Un cache peut aussi être partiellement ou entièrement rempli de données à l’avance, généralement au démarrage de l’application. On parle dans ce cas d’amorçage. Toutefois, il peut être déconseillé d’implémenter l’amorçage d’un cache volumineux, car cette approche peut imposer une charge élevée et soudaine au magasin de données d’origine au début de l’exécution de l’application.
Souvent, une analyse des modèles d’utilisation peut vous aider à décider s’il convient de préremplir entièrement ou partiellement un cache, ainsi qu’à choisir les données à mettre en cache. Par exemple, vous pouvez ensemencer le cache avec les données statiques du profil utilisateur pour les clients qui utilisent l'application régulièrement (peut-être tous les jours), mais pas pour les clients qui n'utilisent l'application qu'une fois par semaine.
En général, la mise en cache fonctionne bien avec les données non modifiables ou qui changent rarement. Il peut s’agir d’informations de référence telles qu’un produit et un prix dans une application de commerce électronique, ou de ressources statiques partagées dont la construction est onéreuse. Une partie ou la totalité des données peut être chargée dans le cache au démarrage de l'application afin de réduire la sollicitation des ressources et d'améliorer les performances. Vous pouvez également avoir un processus en arrière-plan qui met régulièrement à jour les données de référence dans le cache pour vous assurer qu’elle est à jour. Ou, le processus en arrière-plan peut actualiser le cache lorsque les données de référence changent.
La mise en cache est moins utile pour des données dynamiques, même s’il existe des exceptions (pour plus d’informations, voir la section Mise en cache de données hautement dynamiques, plus loin dans cet article). Lorsque les données originales changent régulièrement, soit les informations mises en cache deviennent rapidement périmées, soit les frais de synchronisation du cache avec le magasin de données originales réduisent l'efficacité de la mise en cache.
Un cache ne doit pas nécessairement inclure les données complètes d'une entité. Par exemple, si un élément de données représente un objet à valeurs multiples, comme un client de banque avec un nom, une adresse et un solde de compte, certains de ces éléments peuvent rester statiques, comme le nom et l'adresse. D’autres éléments, tels que le solde du compte, peuvent être plus dynamiques. Dans ces situations, il peut être utile de mettre en cache les parties statiques des données et de récupérer (ou calculer) uniquement les informations restantes lorsqu'elles sont nécessaires.
Nous vous recommandons de tester les performances et d’analyser l’utilisation pour déterminer si un préremplissage ou un chargement à la demande du cache sont appropriés. La décision doit être basée sur la volatilité et le modèle d’utilisation des données. L'utilisation du cache et l'analyse des performances sont importantes dans les applications qui rencontrent de fortes charges et doivent être hautement évolutives. Par exemple, dans des scénarios hautement évolutifs, vous pouvez ensemencer le cache pour réduire la charge sur le magasin de données aux heures de pointe.
La mise en cache peut également permettre d’éviter de répéter des calculs lors de l’exécution de l’application. Si une opération transforme les données ou effectue un calcul complexe, elle peut enregistrer les résultats de l'opération dans le cache. Si le même calcul est requis par la suite, l’application peut simplement extraire les résultats du cache.
Une application peut modifier des données contenues dans un cache. Toutefois, nous vous recommandons de considérer le cache comme magasin de données temporaire, susceptible de disparaître à tout moment. Ne stockez pas uniquement les données précieuses dans le cache ; veillez à conserver également les informations dans le magasin de données d'origine. Vous réduisez ainsi le risque de perdre des données en cas d’indisponibilité du cache.
Mise en cache de données hautement dynamiques
Le stockage d’informations qui changent rapidement dans un magasin de données persistant peut entraîner une surcharge du système. Par exemple, prenons un appareil qui signale continuellement un état ou tout autre mesure. Si une application ne met pas en cache ces données parce que les informations mises en cache risquent d’être presque toujours obsolètes, le même raisonnement peut s’appliquer au stockage et à la récupération de ces informations dans le magasin de données. Les données risquent de changer pendant le temps nécessaire à leur enregistrement et à leur extraction.
Dans ce cas, pesez les avantages d’un stockage des informations dynamiques directement dans le cache plutôt que dans le magasin de données persistant. Si les données ne sont pas critiques et ne nécessitent pas d'audit, il importe peu qu'une modification occasionnelle soit perdue.
Gérer l’expiration des données dans un cache
Le plus souvent, les données conservées dans un cache sont une copie de celles contenues dans le magasin de données d’origine. Les données du magasin de données d'origine peuvent changer après leur mise en cache, entraînant l’expiration des données mises en cache. De nombreux systèmes de mise en cache permettent de configurer le cache de manière à faire expirer les données et à réduire la période pendant laquelle les données peuvent être obsolètes.
Lorsque les données en cache arrivent à expiration, elles sont supprimées du cache et l’application doit les récupérer à partir du magasin de données d’origine (elle peut remettre en cache les informations qui viennent d’être lues). Vous pouvez définir une stratégie d'expiration par défaut lorsque vous configurez le cache. Dans de nombreux services de cache, vous pouvez également stipuler la période d’expiration pour des objets individuels lorsque vous stockez ceux-ci par programme dans le cache. Certains caches vous permettent de spécifier la période d'expiration sous la forme d'une valeur absolue ou d'une valeur glissante qui fait que l'élément est retiré du cache s'il n'est pas consulté dans le délai spécifié. Ce paramètre remplace les stratégies d'expiration du cache, mais uniquement pour les objets spécifiés.
Notes
Réfléchissez attentivement à la période d'expiration du cache et aux objets qu'il contient. Si cette période est trop courte, les objets expirent trop rapidement et vous limitez les avantages de l'utilisation du cache. Si la période est trop longue, les données risquent de devenir obsolètes.
Il est également possible que le cache soit saturé si des données peuvent y résider pendant une longue période. Dans ce cas, toute demande d’ajout d’éléments au cache peut entraîner la suppression forcée d’autres éléments. On parle alors d’éviction. Les services de cache suppriment généralement les données les moins récemment utilisées (LRU), mais vous pouvez généralement remplacer cette stratégie et empêcher l’éviction des éléments. Toutefois, si vous adoptez cette approche, vous risquez un dépassement de la mémoire disponible dans le cache. Dans ce cas, si une application tente d’ajouter un élément au cache, l’opération échoue et lève une exception.
Certaines implémentations de la mise en cache peuvent nécessiter des stratégies d’éviction supplémentaires. Il existe plusieurs types de stratégies d’éviction. notamment :
- La politique la plus récemment utilisée (dans l'espoir que les données ne seront plus requises).
- Stratégie dite du premier entré, premier sorti (les données les plus anciennes sont supprimées en premier).
- Stratégie de suppression explicite basée sur un événement déclenché (par exemple, des données en cours de modification).
Annulation de la validité des données dans un cache côté client
Des données contenues dans un cache côté client sont généralement considérées comme étant extérieures au service qui fournit les données au client. Un service ne peut pas forcer directement un client à ajouter ou supprimer des informations d'un cache côté client.
Cela signifie qu’il est possible qu’un client utilisant un cache mal configuré continue à utiliser des informations obsolètes. Par exemple, si les stratégies d’expiration du cache ne sont pas correctement implémentées, un client risque d’utiliser des informations obsolètes mises en cache localement alors que les informations contenues dans la source de données d’origine ont été modifiées.
Si vous construisez une application web qui sert des données via une connexion HTTP, vous pouvez implicitement forcer un client web (tel qu'un navigateur ou un proxy web) à récupérer les informations les plus récentes. Vous pouvez faire cela si une ressource est mise à jour par une modification de son URI. Les clients web utilisent généralement l’URI d’une ressource comme clé dans le cache côté client. Par conséquent, en cas de modification de l’URI, le client web ignore les versions précédemment mises en cache d’une ressource et extrait la nouvelle version à la place.
Gestion de l'accès concurrentiel dans un cache
Les caches sont souvent conçus pour être partagés par plusieurs instances d'une application. Chaque instance de l'application peut lire et modifier les données du cache. Pas conséquent, les problèmes d’accès concurrentiel résultant du partage d’un magasin de données s’appliquent également à un cache. Dans une situation où une application doit modifier des données contenues dans le cache, vous devrez peut-être vous assurer que les mises à jour effectuées par une instance de l'application n'écrasent pas les modifications apportées par une autre instance.
Selon la nature des données et la probabilité de collisions, vous pouvez adopter une des deux approches d'accès concurrentiel suivantes :
- Accès concurrentiel optimiste. Juste avant la mise à jour des données, l’application vérifie si les données mises en cache ont été modifiées depuis leur récupération. Si les données sont toujours identiques, la modification peut être apportée. Dans le cas contraire, l’application doit décider s’il convient de les mettre à jour. (La logique métier sur laquelle cette décision s’appuie est spécifique de l’application). Cette approche est appropriée pour les situations où les mises à jour sont peu fréquentes ou celles où les collisions sont peu probables.
- Accès concurrentiel pessimiste. Lors de la récupération des données, l’application les verrouille dans le cache pour empêcher qu’une autre instance les modifie. Ce processus permet d'éviter les collisions, mais celles-ci peuvent également bloquer d'autres instances qui doivent traiter les mêmes données. Un accès concurrentiel pessimiste pouvant affecter l’extensibilité d’une solution, il n’est conseillé que pour des opérations à durée de vie limitée. Cette approche peut être appropriée dans les cas où des collisions sont probables, en particulier si une application met à jour plusieurs éléments du cache et doit veiller à ce que ces modifications soient appliquées de manière cohérente.
Implémenter une disponibilité et une extensibilité élevées, et améliorer les performances
Évitez d’utiliser un cache comme référentiel principal de données. Il s’agit du rôle du magasin de données d’origine à partir duquel le cache est rempli. Le magasin de données d'origine est responsable de la persistance des données.
Veillez à ne pas introduire de dépendances critiques sur la disponibilité d'un service de cache partagé dans vos solutions. Une application doit pouvoir continuer à fonctionner si le service fournissant le cache partagé n’est pas disponible. L'application ne doit pas devenir insensible ou échouer en attendant que le service de cache reprenne.
Par conséquent, l'application doit pouvoir détecter la disponibilité du service de cache et revenir au magasin de données d'origine si le cache n'est pas accessible. Le modèle du disjoncteur est utile dans ce scénario. Le service qui fournit le cache peut être récupéré et, dès qu’il est disponible, le cache peut être rempli à nouveau à mesure que des données sont lues à partir du magasin de données d’origine, en suivant une stratégie telle que le mode de type cache-aside.
Toutefois, l’extensibilité du système peut être affectée si l’application revient au magasin de données d’origine lorsque le cache n’est temporairement pas disponible. Durant la récupération du magasin de données, le magasin d’origine peut être submergé de demandes de données, ce qui entraîne des délais d’attente et des échecs de connexion.
Songez à implémenter un cache local privé dans chaque instance d’une application, en plus du cache partagé auquel toutes les instances de l’application accèdent. Quand l’application récupère un élément, elle peut vérifier le cache local, puis le cache partagé, puis le magasin de données d’origine. Le cache local peut être rempli à l’aide des données du cache partagé ou de la base de données si le cache partagé n’est pas disponible.
Cette approche nécessite une configuration soigneuse pour éviter que le cache local devienne trop caduque par rapport au cache partagé. Toutefois, le cache local fait office de tampon si le cache partagé est inaccessible. La figure 3 illustre cette structure.
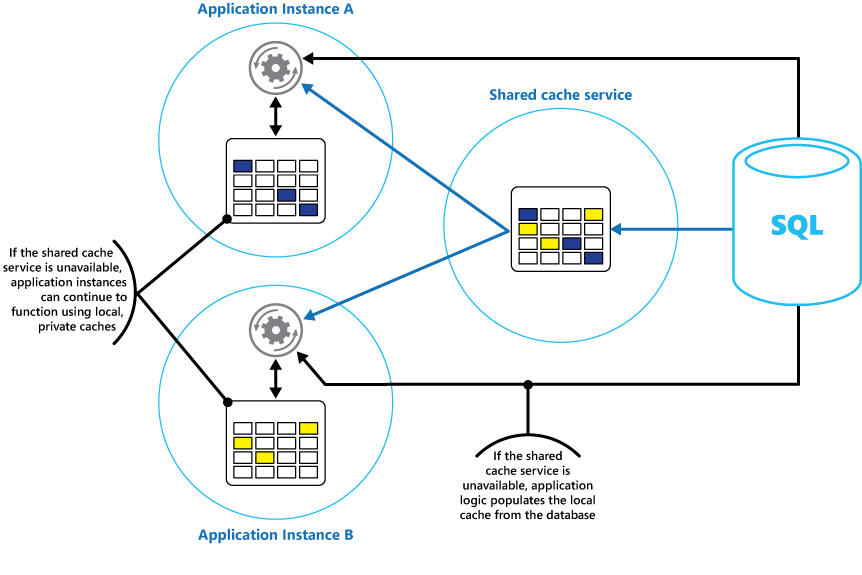
Figure 3 : Utilisation d’un cache privé local avec un cache partagé.
Pour prendre en charge des caches volumineux qui contiennent des données à long terme, certains services de cache offrent une option de haute disponibilité qui implémente le basculement automatique si le cache devient indisponible. Cette approche implique généralement une réplication des données mises en cache sur un serveur de cache principal vers un serveur de cache secondaire, et un basculement vers le serveur secondaire en cas d’échec du serveur principal ou de perte de la connectivité.
Pour réduire la latence associée à l’écriture vers plusieurs destinations, la réplication vers le serveur secondaire peut se produire en mode asynchrone lors de l’écriture de données dans le cache sur le serveur principal. Cette approche entraîne la possibilité que certaines informations mises en cache soient perdues en cas de panne, mais la proportion de ces données devrait être faible, par rapport à la taille globale du cache.
Si un cache partagé est volumineux, il peut être avantageux de partitionner les données mises en cache sur des nœuds afin de réduire les risques de contention et d’améliorer l’extensibilité. De nombreux caches partagés prennent en charge la possibilité d'ajouter (et de supprimer) dynamiquement des nœuds et de rééquilibrer les données sur plusieurs partitions. Cette approche peut impliquer un clustering. La collection de nœuds est alors présentée aux applications clientes comme un cache unique transparent. Toutefois, en interne, les données sont réparties sur plusieurs nœuds selon une stratégie de distribution prédéfinie qui équilibre la charge uniformément. Pour plus d’informations sur les stratégies de partitionnement possibles, consultez Conseils sur le partitionnement des données.
Un clustering peut également augmenter la disponibilité du cache. Si un nœud échoue, le reste du cache est toujours accessible. Un clustering est fréquemment utilisé conjointement avec une réplication et un basculement. Chaque nœud peut être répliqué, et le réplica peut être mis en ligne rapidement en cas de défaillant du nœud.
De nombreuses opérations de lecture et d’écriture peuvent produire des valeurs ou objets de données uniques. Toutefois, il est parfois nécessaire stocker ou de récupérer rapidement de grands volumes de données. Par exemple, l’amorçage d’un cache peut impliquer l’écriture des centaines, voire de milliers d’éléments dans le cache. Il se peut également qu’une application doive récupérer un grand nombre d’éléments connexes à partir du cache dans le cadre de la même demande.
De nombreux caches à grande échelle offrent des opérations de traitement par lots à ces fins. Cela permet à une application cliente d’empaqueter un volume important d’éléments dans une seule demande, et réduit la surcharge associée à l’exécution d’un grand nombre de petites demandes.
Mise en cache et cohérence finale
Pour le modèle de type cache-aside, l’instance de l’application qui remplit le cache doit avoir accès à la version la plus récente et la plus cohérente des données. Cela peut ne pas être le cas dans un système qui implémente la cohérence finale (par exemple, un magasin de données répliqué).
Une des instances d'une application peut modifier un élément de données et invalider la version mise en cache de cet élément. Une autre instance de l’application peut tenter de lire cet élément à partir d’un cache, ce qui entraîne l’échec d’une opération dans le cache. Elle lit alors les données du magasin de données et les ajoute au cache. Toutefois, si le magasin de données n'a pas été entièrement synchronisé avec les autres répliques, l'instance d'application pourrait lire et remplir le cache avec l'ancienne valeur.
Pour plus d’informations sur la gestion de la cohérence des données, consultez l’article Data consistency primer (Introduction à la cohérence des données).
Protéger les données mises en cache
Quel que soit le service de cache que vous utilisez, songez à la manière de protéger les données contenues dans le cache contre un accès non autorisé. Il existe deux problèmes principaux :
- confidentialité des données dans le cache ;
- confidentialité des données lorsqu’elles circulent entre le cache et l’application utilisant le cache.
Pour protéger des données dans le cache, le service de cache peut implémenter un mécanisme d’authentification qui requiert que les applications spécifient les éléments suivants :
- les identités pouvant accéder aux données dans le cache ;
- les opérations (lecture et écriture) que ces identités sont autorisées à effectuer.
Pour réduire la surcharge associée à la lecture et à l’écriture de données, une fois que l’identité a obtenu un accès en écriture ou en lecture au cache, elle peut utiliser toutes les données de celui-ci.
Si vous devez restreindre l’accès à des sous-ensembles des données mises en cache, vous pouvez effectuer les opérations suivantes :
- fractionner le cache en partitions (à l’aide de différents serveurs de cache) et accorder uniquement aux identités l’accès aux partitions qu’elles sont autorisées à utiliser ;
- chiffrer les données dans chaque sous-ensemble en utilisant différentes clés, et fournir les clés de chiffrement uniquement aux identités qui doivent avoir accès à chaque sous-ensemble. Il se peut qu’une application cliente soit toujours être en mesure de récupérer toutes les données du cache, mais elle ne peut déchiffrer que les données pour lesquelles elle possède les clés.
Vous devez également protéger les données échangées avec le cache. Pour ce faire, vous dépendez des fonctionnalités de sécurité fournies par l’infrastructure réseau que les applications clientes utilisent pour se connecter au cache. Si le cache est implémenté à l’aide d’un serveur local de l’organisation qui héberge les applications clientes, il se peut que l’isolation du réseau lui-même ne nécessite aucune mesure supplémentaire. Si le cache est distant et requiert une connexion TCP ou HTTP via un réseau public (comme Internet), songez à implémenter le protocole SSL.
Considérations liées à l’implémentation de la mise en cache dans Azure
Azure Cache pour Redis est une implémentation du cache Redis open source qui s’exécute en tant que service dans un centre de données Azure. Il fournit un service de mise en cache qui est accessible à partir de n'importe quelle application Azure, que l'application soit implémentée comme un service cloud, un site web, ou soit située à l'intérieur d'une machine virtuelle Azure. Les caches peuvent être partagés par les applications clientes qui possèdent la clé d'accès appropriée.
Azure Cache pour Redis est une solution de mise en cache très performante qui offre disponibilité, extensibilité et sécurité. Il s’exécute généralement en tant que service réparti sur une ou plusieurs machines dédiées. Il tente de stocker autant d’informations que possible en mémoire pour assurer un accès rapide. Cette architecture est conçue pour fournir une latence faible et un haut débit en réduisant la nécessité d'effectuer des opérations d'E/S lentes.
Azure Cache pour Redis est compatible avec de nombreuses API utilisées par des applications clientes. Si vous avez des applications existantes qui utilisent déjà Azure Cache pour Redis localement, celui-ci fournit un chemin de migration rapide vers une mise en cache dans le cloud.
Fonctionnalités de Redis
Redis est plus qu’un simple serveur de cache. Il fournit une base de données en mémoire distribuée avec un jeu de commandes complet qui prend en charge de nombreux scénarios courants. Ceux-ci sont décrits plus loin dans ce document, dans la section Utilisation de la mise en cache Redis. Cette section décrit quelques-unes des fonctionnalités clés que fournit Redis.
Redis comme base de données en mémoire
Redis prend en charge les opérations de lecture et d’écriture. Redis permet de protéger les écritures contre une défaillance du système en les stockant régulièrement dans un fichier de capture instantanée local ou dans un fichier journal en mode Ajout uniquement. Cette situation n'est pas le cas dans de nombreux caches, qui doivent être considérés comme des magasins de données transitoires.
Toutes les écritures sont asynchrones et ne bloquent pas la lecture et l'écriture des données par les clients. Lorsque Redis commence à s’exécuter, il lit les données à partir du fichier journal ou de l'instantané et les utilise pour construire le cache en mémoire. Pour plus d’informations, voir Persistance Redis sur le site web de Redis.
Notes
Redis ne garantit pas que toutes les écritures seront sauvegardées en cas d'échec catastrophique, mais au pire, vous ne perdrez que quelques secondes de données. N'oubliez pas qu'un cache n'est pas destiné à faire autorité en tant que source de données et qu'il incombe aux applications utilisant le cache de s'assurer que les données critiques sont sauvegardées avec succès dans un magasin de données approprié. Pour plus d'informations, consultez Modèle Cache-Aside.
Types de données Redis
Redis est un magasin de clés-valeurs, où les valeurs peuvent contenir des types simples ou des structures de données complexes telles que des hachages, des listes et des ensembles. Il prend en charge un ensemble d'opérations atomiques pour ces types de données. Les clés peuvent être permanentes ou marquées avec une durée de vie limitée, qui a pour effet que la clé et la valeur correspondante sont automatiquement supprimées du cache. Pour plus d’informations sur les valeurs et clés Redis, voir la page présentant les types de données et abstractions Redis sur le site web de Redis.
Réplication et clustering Redis
Redis prend en charge la réplication primaire/subordonnée pour garantir la disponibilité et maintenir le débit. Les opérations d’écriture sur un nœud principal Redis sont répliquées sur un ou plusieurs nœuds subordonnés. Les opérations de lecture peuvent être effectuées par le principal ou l’un des subordonnés.
En cas de partition du réseau, les subordonnés peuvent continuer à servir les données, puis se resynchroniser de manière transparente avec le primaire lorsque la connexion est rétablie. Pour plus d'informations, visitez la page Réplication sur le site web Redis.
Redis offre également un clustering qui permet de partitionner les données de manière transparente sur des serveurs et de répartir la charge. Cette fonctionnalité améliore l’extensibilité, car de nouveaux serveurs Redis peuvent être ajoutés, et les données réparties à mesure que la taille du cache augmente.
En outre, chaque serveur du cluster peut être répliqué à l’aide d’une réplication primaire/subordonné. Cela garantit la disponibilité sur chaque nœud du cluster. Pour plus d’informations sur le clustering et le partitionnement, voir le didacticiel sur le cluster Redis sur le site web de Redis.
Utilisation de la mémoire Redis
Un cache Redis a une taille limitée dépendant des ressources disponibles sur l’ordinateur hôte. Lorsque vous configurez un serveur Redis, vous pouvez spécifier la quantité maximale de mémoire qu'il peut utiliser. Vous pouvez également configurer une clé dans un cache Redis pour qu'elle ait un temps d'expiration, après quoi elle est automatiquement retirée du cache. Cette fonctionnalité peut empêcher le remplissage du cache en mémoire avec des données anciennes ou caduques.
À mesure que la mémoire se remplit, Redis peut automatiquement supprimer les clés et leurs valeurs en suivant un certain nombre de stratégies. La valeur par défaut est LRU (le moins récemment utilisé), mais vous pouvez également sélectionner d'autres politiques telles que l'éviction de clés au hasard ou la désactivation totale de l'éviction (dans ce cas, les tentatives d'ajout d'éléments dans le cache échouent si celui-ci est plein). Pour plus d’informations, voir la page Utilisation de Redis comme cache LRU .
Transactions et lots Redis
Redis permet à une application cliente d’envoyer une série d'opérations qui lisent et écrivent des données dans le cache en tant que transaction atomique. Toutes les commandes de la transaction sont exécutées de façon séquentielle, et aucune commande émise par d’autres clients concurrentiels n’est insérée entre elles.
Cependant, il ne s'agit pas de véritables transactions telles qu'elles seraient effectuées par une base de données relationnelle. Le traitement des transactions comprend deux phases : la première consiste en une mise en attente des commandes, et la seconde en leur exécution. Durant la phase de mise en file d'attente des commandes, les commandes qui composent la transaction sont envoyées par le client. Si une erreur se produit à ce stade (par exemple, une erreur de syntaxe ou un nombre incorrect de paramètres), Redis refuse de traiter toute la transaction et l’ignore.
Pendant la phase d’exécution, Redis exécute successivement chaque commande en file d’attente. Si une commande échoue pendant cette phase, Redis continue avec la prochaine commande en file d'attente et n'annule pas les effets des commandes qui ont déjà été exécutées. Cette forme simplifiée de transaction aide à maintenir les performances et à éviter des problèmes de performances résultant d’une contention.
Redis implémente une forme de verrouillage optimiste pour aider à maintenir la cohérence. Pour plus d'informations sur les transactions et le verrouillage avec Redis, visitez la page Transactions sur le site web de Redis.
Redis prend également en charge le traitement par lot non transactionnel des demandes. Le protocole Redis que les clients utilisent pour envoyer des commandes à un serveur Redis permet à un client d'envoyer une série d'opérations dans le cadre de la même demande. Cela peut aider à réduire la fragmentation des paquets sur le réseau. Lorsque le lot est traité, chaque commande est exécutée. Si l'une de ces commandes est malformée, elle sera rejetée (ce qui n'arrive pas avec une transaction), mais les autres commandes seront exécutées. Il n'y a pas non plus de garantie quant à l'ordre dans lequel les commandes du lot seront traitées.
Sécurité Redis
Redis se concentre strictement sur la fourniture d’un accès rapide aux données, et est conçu pour s’exécuter au sein d’un environnement approuvé auquel seuls des clients approuvés peuvent accéder. Redis prend en charge un modèle de sécurité limitée basé sur une authentification par mot de passe. (Il est possible de supprimer complètement l'authentification, bien que nous ne le recommandions pas).
Tous les clients authentifiés partagent le même mot de passe global et ont accès aux mêmes ressources. Si vous avez besoin d’une sécurité de connexion plus complète, vous devez implémenter votre propre couche de sécurité devant le serveur Redis, et toutes les demandes des clients doivent transiter par cette couche supplémentaire. Redis ne devrait pas être directement exposé à des clients non fiables ou non authentifiés.
Vous pouvez restreindre l’accès aux commandes en les désactivant ou en les renommant (et en fournissant les nouveaux noms uniquement aux clients dotés de privilèges).
Redis ne supporte pas directement toute forme de cryptage de données, donc tout le codage doit être effectué par les applications clientes. En outre, Redis ne fournit aucune forme de sécurité de transport. Si vous avez besoin protéger des données transitant sur le réseau, nous vous recommandons d’implémenter un proxy SSL.
Pour plus d’informations, voir la page Sécurité Redis sur le site web de Redis.
Notes
Azure Cache pour Redis dispose de sa propre couche de sécurité via laquelle les clients se connectent. Les serveurs Redis sous-jacents ne sont pas exposés au réseau public.
Cache Redis Azure
Azure Cache pour Redis donne accès à des serveurs Redis hébergés dans un centre de données Azure. Il agit comme une façade assurant la sécurité et le contrôle d’accès. Vous pouvez déployer un cache à l’aide du portail Azure.
Le portail fournit un certain nombre de configurations prédéfinies. Celles-ci vont d’un cache de 53 Go opérant en tant que service dédié qui prend en charge les communications SSL (pour la confidentialité) et la réplication maître/subordonné avec un contrat SLA garantissant une disponibilité de 99,9 %, à un cache de 250 Mo sans réplication (aucune garantie de disponibilité) s’exécutant sur du matériel partagé.
Le portail Azure vous permet également de configurer la stratégie d’éviction du cache et de contrôler l’accès au cache en ajoutant des utilisateurs aux rôles fournis . Ces rôles qui définissent les opérations que les membres peuvent effectuer sont Propriétaire, Collaborateur et Lecteur. Par exemple, les membres du rôle Propriétaire ont un contrôle complet du cache (y compris la sécurité) et de son contenu, les membres du rôle Collaborateur peuvent lire et écrire des informations dans le cache, et les membres du rôle Lecteur peuvent uniquement récupérer des données à partir du cache.
La plupart des tâches d’administration sont effectuées via le portail Azure. Pour cette raison, de nombreuses commandes administratives disponibles dans la version standard de Redis ne sont pas disponibles, y compris la possibilité de modifier la configuration de manière programmatique, d'arrêter le serveur Redis, de configurer des subordonnés supplémentaires ou d'enregistrer de force des données sur le disque.
Le portail Azure inclut un affichage graphique pratique qui vous permet d’analyser les performances du cache. Par exemple, vous pouvez afficher le nombre de connexions établies, le nombre de demandes effectuées, le volume de lectures et écritures, ainsi que le nombre de correspondances dans le cache par rapport aux absences dans le cache. Ces informations vous permettent de déterminer l’efficacité du cache et, si nécessaire, de basculer vers une autre configuration ou de modifier la stratégie d’éviction.
En outre, vous pouvez créer des alertes qui envoient des messages électroniques à un administrateur si une ou plusieurs mesures critiques sont comprises dans une plage attendue. Par exemple, vous pouvez décider d’alerter un administrateur quand le nombre d’absences dans le cache au cours de la dernière heure dépasse une valeur spécifiée, car cela signifie que le cache pourrait être trop petit ou que des données pourraient être évincées trop rapidement.
Vous pouvez également surveiller le processeur, la mémoire et l’utilisation du réseau pour le cache.
Pour plus d'informations et pour obtenir des exemples illustrant la procédure de création et de configuration d’un Azure Cache pour Redis, visitez la page Tour d’horizon d’Azure Cache pour Redis sur le blog Azure.
État de session de mise en cache et sortie HTML
Si vous concevez des applications web ASP.NET qui s’exécutent à l’aide de rôles web Azure, vous pouvez enregistrer la sortie HTML et les informations d’état de session dans un Azure Cache for Redis. Le fournisseur d'état de session pour Azure Cache for Redis vous permet de partager les informations de session entre différentes instances d'une application web ASP.NET. Il est très utile dans les situations de fermes web où l'affinité client-serveur n'est pas disponible et où la mise en cache des données de session en mémoire ne serait pas appropriée.
L’utilisation du fournisseur d'état de session avec Azure Cache pour Redis offre plusieurs avantages, notamment :
- partage d’état de session avec un grand nombre d’instances d’applications web ASP.NET ;
- extensibilité améliorée ;
- prise en charge d’un accès contrôlé concurrentiel aux mêmes données d’état de session pour plusieurs lecteurs et un seul enregistreur ;
- utilisation d’une compression pour économiser la mémoire et améliorer les performances réseau.
Pour plus d'informations, consultez Fournisseur d'état de session ASP.NET pour Azure Cache pour Redis.
Notes
N'utilisez pas le fournisseur d'état de session pour Azure Cache for Redis avec des applications ASP.NET qui s'exécutent en dehors de l'environnement Azure. La latence de l’accès au cache depuis l’extérieur d'Azure peut éliminer les avantages en matière de performances de la mise en cache de données.
De même, le fournisseur de caches de sortie pour Azure Cache pour Redis vous permet d’enregistrer les réponses HTTP générées par une application web ASP.NET. L’utilisation du fournisseur de caches de sortie avec Azure Cache pour Redis peut améliorer les temps de réponse d’applications qui restituent une sortie HTML complexe. Des instances d’application qui génèrent des réponses similaires peuvent utiliser des fragments de sortie partagés dans le cache au lieu de générer entièrement cette sortie HTML. Pour plus d’informations, consultez Fournisseur de caches de sortie ASP.NET pour Azure Cache pour Redis.
Création d'un cache Redis personnalisé
Azure Cache pour Redis agit comme façade devant les serveurs Redis sous-jacents. Si vous avez besoin d'une configuration avancée qui n'est pas couverte par le cache Azure Redis (comme un cache de plus de 53 Go), vous pouvez construire et héberger vos propres serveurs Redis en utilisant des machines virtuelles Azure.
Il s’agit d’un processus potentiellement complexe, car vous devrez peut-être créer plusieurs machines virtuelles faisant office de nœuds principaux et subordonnés si vous souhaitez implémenter une réplication. En outre, si vous souhaitez créer un cluster, vous avez besoin de plusieurs serveurs principaux et de serveurs subordonnés. Une topologie de réplication en cluster minimale offrant un niveau élevé de disponibilité et d’évolutivité comprend au moins six machines virtuelles organisées sous la forme de trois paires de serveurs principaux/subordonnés (un cluster devant contenir au moins trois nœuds principaux).
Chaque paire principal/subordonné doit être proche pour réduire la latence. Toutefois, chaque ensemble de paires peut s’exécuter dans différents centres de données Azure situés dans différentes régions, si vous souhaitez rechercher des données mises en cache à proximité des applications les plus susceptibles de les utiliser. Pour découvrir un exemple de création et de configuration d’un nœud Redis s’exécutant en tant que machine virtuelle Azure, consultez l’article Running Redis on a CentOS Linux VM in Azure (Exécution de Redis sur une machine virtuelle Linux CentOS dans Azure).
Notes
Si vous implémentez votre propre cache Redis de cette manière, vous êtes responsable de la surveillance, de la gestion et de la sécurisation du service.
Partitionnement d’un cache Redis
Le partitionnement du cache implique le fractionnement du cache sur plusieurs ordinateurs. Cette structure présente plusieurs avantages par rapport à l'utilisation d'un serveur de cache unique, notamment :
- Création d'un cache beaucoup plus volumineux que ce qui peut être stocké sur un serveur unique.
- Distribution des données entre serveurs, en améliorant la disponibilité. Si un serveur est défaillant ou devient inaccessible, les données qu’il contient sont indisponibles, mais les données des autres serveurs restent accessibles. Pour un cache, ce n'est pas crucial car les données mises en cache ne sont qu'une copie transitoire des données contenues dans une base de données. Les données mises en cache sur un serveur qui devient inaccessible peuvent être mises en cache sur un autre serveur à la place.
- Répartition de la charge entre les serveurs, ce qui améliore les performances et l'extensibilité.
- Géolocalisation des données à proximité des utilisateurs qui y accèdent, ce qui réduit la latence.
Pour un cache, la forme la plus courante est le partitionnement. Dans le cadre de cette stratégie, chaque partition est un cache Redis à part entière. Les données sont dirigées vers une partition spécifique à l'aide de la logique de partitionnement, qui peut utiliser plusieurs méthodes. Le modèle de partitionnement fournit des informations supplémentaires sur l’implémentation du partitionnement.
Pour implémenter le partitionnement dans un cache Redis, vous pouvez adopter l’une des approches suivantes :
- Routage des demandes côté serveur. Dans cette technique, une application cliente envoie une demande à un des serveurs Redis qui composent le cache (probablement le serveur le plus proche). Chaque serveur Redis stocke les métadonnées décrivant la partition qu’il contient, et contient également les informations relatives aux partitions présentes sur d’autres serveurs. Le serveur Redis examine la demande du client. Si elle peut être résolue localement, il effectue l’opération demandée. Dans le cas contraire, il transfère la demande au serveur approprié. Ce modèle est mis en œuvre à l’aide du clustering Redis et est décrit plus en détail dans le didacticiel sur les clusters Redis sur le site web de Redis. Le clustering Redis est transparent pour les applications clientes et il est possible d’ajouter des serveurs Redis supplémentaires au cluster (et aux données repartitionnées) sans devoir reconfigurer les clients.
- Partitionnement côté client. Dans ce modèle, l'application cliente contient la logique (éventuellement sous la forme d'une bibliothèque) qui achemine les demandes vers le serveur Redis approprié. Cette approche peut être utilisée avec Azure Cache pour Redis. Créez plusieurs Azure Cache pour Redis (un par partition de données) et implémentez la logique côté client qui achemine les demandes vers le cache adéquat. Si le schéma de partitionnement change (par exemple, si des caches Azure Cache pour Redis supplémentaires sont créés), il se peut que des applications clientes doivent être reconfigurées.
- Partitionnement assisté par un proxy. Dans ce schéma, les applications clientes envoient des demandes à un service proxy intermédiaire qui comprend la façon dont les données sont partitionnées puis achemine la demande ver le serveur Redis approprié. Cette approche est également valable avec Azure Cache pour Redis. Le service proxy peut être implémenté en tant que service cloud Azure. Cette approche nécessite un niveau supplémentaire de complexité pour implémenter le service, et l’exécution des demandes peut prendre plus de temps qu’en utilisant un partitionnement côté client.
La page sur le partitionnement et le fractionnement des données entre plusieurs instances Redis sur le site web de Redis fournit des informations supplémentaires concernant la mise en œuvre du partitionnement avec Redis.
Implémenter des applications clientes de cache Redis
Redis prend en charge les applications clientes écrites dans plusieurs langages de programmation. Si vous créez de nouvelles applications en utilisant le .NET Framework, nous vous recommandons d'utiliser la bibliothèque client StackExchange.Redis. Cette bibliothèque fournit un modèle objet .NET Framework qui résume les détails de connexion à un serveur Redis, l'envoi de commandes et la réception des réponses. Il est disponible dans Visual Studio sous la forme d'un paquet NuGet. Vous pouvez utiliser cette bibliothèque pour vous connecter à Azure Cache pour Redis ou à un cache Redis personnalisé hébergé sur une machine virtuelle.
Pour vous connecter à un serveur Redis, utilisez la méthode Connect statique de la classe ConnectionMultiplexer. La connexion créée par cette méthode est conçue pour être utilisée pendant la durée de vie de l’application cliente, et la même connexion peut être utilisée par plusieurs threads simultanés. Ne vous reconnectez pas et ne vous déconnectez pas à chaque fois que vous effectuez une opération Redis car cela peut dégrader les performances.
Vous pouvez spécifier les paramètres de connexion, tels que l'adresse de l'hôte Redis et le mot de passe. Si vous utilisez Azure Cache for Redis, le mot de passe est la clé primaire ou secondaire qui est générée pour Azure Cache for Redis en utilisant le portail Azure.
Une fois que vous vous êtes connecté au serveur Redis, vous pouvez obtenir un handle sur la base de données Redis qui agit comme cache. La connexion Redis fournit la méthode GetDatabase correspondante. Vous pouvez ensuite récupérer les éléments dans le cache et stocker des données dans le cache à l'aide des méthodes StringGet et StringSet. Ces méthodes attendent une clé en tant que paramètre. Elles renvoient l’élément du cache ayant une valeur correspondante (StringGet) ou ajoutent l’élément au cache avec cette clé (StringSet).
Selon l’emplacement du serveur Redis, de nombreuses opérations peuvent entraîner une latence pendant la transmission d’une demande au serveur et le renvoi d’une réponse au client. La bibliothèque StackExchange fournit des versions asynchrones de la plupart des méthodes qu'elle expose pour aider les applications clientes à rester réactives. Ces méthodes prennent en charge le modèle asynchrone basé sur des tâches dans .NET Framework.
L’extrait de code suivant illustre une méthode nommée RetrieveItem. Il illustre une implémentation du modèle de type cache-aside basée sur Redis et la bibliothèque StackExchange. La méthode accepte une valeur de clé de type chaîne, et tente de récupérer l’élément correspondant à partir du cache Redis en appelant la méthode StringGetAsync (version asynchrone de StringGet).
Si l'élément n'est pas trouvé, il est récupéré dans la source de données sous-jacente à l'aide de la méthode GetItemFromDataSourceAsync(qui est une méthode locale et ne fait pas partie de la bibliothèque StackExchange). Il est alors ajouté au cache à l’aide de la méthode StringSetAsync , de sorte qu’il peut être récupéré plus rapidement par la suite.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Les méthodes StringGet et StringSet ne sont pas limitées à l’extraction ou au stockage de valeurs de type chaîne. Elles peuvent accepter tout élément qui est sérialisé en tant que tableau d’octets. Si vous avez besoin d’enregistrer un objet .NET, vous pouvez le sérialiser en tant que flux d’octets et utiliser la méthode StringSet pour l’écrire dans le cache.
De même, vous pouvez lire un objet à partir du cache à l’aide de la méthode StringGet et le désérialiser en tant qu’objet .NET. Le code suivant illustre un ensemble de méthodes d’extension pour l’interface IDatabase (la méthode GetDatabase d’une connexion Redis renvoie un objet IDatabase), ainsi qu’un exemple de code utilisant ces méthodes pour lire et écrire un objet BlogPost dans le cache :
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Le code suivant illustre une méthode nommée RetrieveBlogPost qui utilise ces méthodes d'extension pour lire et écrire un objet BlogPost sérialisable dans le cache selon le mode de type cache-aside :
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis prend en charge la mise en pipeline des commandes si une application cliente envoie plusieurs demandes asynchrones. Redis peut appliquer un multiplexage aux demandes à l'aide de la même connexion plutôt que de recevoir et de répondre aux commandes dans une séquence stricte.
Cette approche permet de réduire la latence grâce à une utilisation plus efficace du réseau. L'extrait de code suivant montre un exemple qui récupère simultanément les détails de deux clients. Le code envoie deux demandes, effectue d'autres traitements (non illustrés), puis attend de recevoir les résultats. La méthode Wait de l’objet cache est similaire à la méthode .NET Framework Task.Wait :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Pour plus d’informations sur l’écriture d’applications clientes pouvant utiliser Azure Cache pour Redis, consultez la documentation Azure Cache pour Redis. D’autres informations sont également accessibles sur StackExchange.Redis.
La page Pipelines et multiplexeurs sur le même site web fournit des informations supplémentaires sur les opérations asynchrones et le traitement en pipeline avec Redis et la bibliothèque StackExchange.
Utilisation de la mise en cache Redis
L’utilisation la plus simple de Redis pour la mise en cache consiste à recourir à des paires clé-valeur où la valeur est une chaîne non interprétée de longueur arbitraire qui peut contenir des données binaires quelconques. (Il s’agit essentiellement d’un tableau d’octets qui peut être traité en tant que chaîne). Ce scénario est illustré dans la section Implémenter des applications clientes de cache Redis, plus haut dans cet article.
Notez que ces clés contiennent également des données non interprétées, afin que vous puissiez utiliser tout type d’informations binaires comme clé. Toutefois, plus la clé est longue, plus il faut d’espace pour la stocker et plus les opérations de recherche prennent de temps. Pour faciliter l’utilisation et la maintenance, concevez votre espace de clés soigneusement et utilisez des clés explicites (mais pas longues).
Par exemple, utilisez des clés structurées telles que « client:100 » pour représenter la clé pour le client avec l'ID 100 plutôt que simplement « 100 ». Ce schéma permet de facilement faire la différence entre les valeurs qui stockent les différents types de données. Par exemple, vous pouvez également utiliser la clé « orders:100 » pour représenter la clé pour la commande avec l'ID 100.
Indépendamment des chaînes binaires unidimensionnelles, une valeur d’une paire clé/valeur Redis peut également contenir des informations plus structurées, dont des listes, des ensembles (triés et non triés) et des hachages. Redis fournit un ensemble de commandes complet qui permet de manipuler ces types. Bon nombre de ces commandes sont accessibles par les applications .NET Framework via une bibliothèque cliente telle que StackExchange. La page Présentation des types de données et abstractions Redis du site web de Redis fournit une vue plus détaillée de ces types et des commandes que vous pouvez utiliser pour les manipuler.
Cette section récapitule quelques utilisations habituelles de ces types de données et commandes.
Exécuter des opérations atomiques et par lots
Redis prend en charge une série d'opérations get et set atomiques sur les valeurs de chaîne. Ces opérations suppriment les risques de conditions de concurrence possibles qui peuvent se produire lors de l'utilisation de commandes GET et SET distinctes. Les opérations disponibles sont les suivantes :
INCR,INCRBY,DECRetDECRBYeffectuent des opérations d’incrémentation et de décrémentation atomiques sur les valeurs de données numériques entières. La bibliothèque StackExchange fournit des versions surchargées des méthodesIDatabase.StringIncrementAsyncetIDatabase.StringDecrementAsyncpour effectuer ces opérations et renvoyer la valeur résultante stockée dans le cache. L'extrait de code suivant illustre l’utilisation de ces méthodes :ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSETrécupère la valeur associée à une clé et la remplace par une autre. La bibliothèque StackExchange donne accès à cette opération via la méthodeIDatabase.StringGetSetAsync. L'extrait de code ci-dessous montre un exemple de cette méthode. Ce code retourne la valeur actuelle associée à la clé « data:counter » de l’exemple précédent. Il réinitialise ensuite la valeur de cette clé à zéro, le tout dans le cadre de la même opération :ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETetMSETpeuvent renvoyer ou modifier un ensemble de valeurs de chaîne en une seule opération. Les méthodesIDatabase.StringGetAsyncetIDatabase.StringSetAsyncsont surchargées pour prendre en charge cette fonctionnalité, comme illustré dans l'exemple suivant :ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Vous pouvez également combiner plusieurs opérations en une seule opération Redis, comme décrit dans la section Transactions et lots Redis plus haut dans cet article. La bibliothèque StackExchange prend en charge les transactions via l’interface ITransaction.
Vous créez un objet ITransaction à l’aide de la méthode IDatabase.CreateTransaction. Vous appelez des commandes à la transaction à l’aide des méthodes fournies par l’objet ITransaction .
L’interface ITransaction donne accès à un ensemble de méthodes similaires à celles auxquelles l’interface IDatabase, sauf que toutes les méthodes sont asynchrones. Cela signifie qu’elles sont exécutées uniquement lors de l’appel de la méthode ITransaction.Execute . La valeur renvoyée par la méthode ITransaction.Execute indique si la transaction a été créée avec succès (true) ou a échoué (false).
L'extrait de code suivant montre un exemple qui incrémente et décrémente deux compteurs dans le cadre d’une même transaction :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
N'oubliez pas que les transactions Redis sont peu probables dans les bases de données relationnelles. La méthode Execute met simplement en file d’attente toutes les commandes qui composent la transaction à exécuter. Si l’une d’elles est mal formée, la transaction est arrêtée. Si toutes les commandes ont été correctement mises en file d’attente, chacune d’elles s’exécute en mode asynchrone.
Si une commande échoue, le traitement des autres continue. Pour vérifier qu’une commande a été correctement exécutée, vous devez extraire les résultats de la commande à l’aide de la propriété Result de la tâche correspondante, comme illustré dans l’exemple ci-dessus. La lecture de la propriété Result bloque le thread appelant jusqu’à ce que la tâche soit accomplie.
Pour plus d’informations, consultez Transactions dans Redis.
Lors de l’exécution des opérations par lot, vous pouvez utiliser l’interface IBatch de la bibliothèque StackExchange. Cette interface donne accès à un ensemble de méthodes similaires à celles auxquelles accède l’interface IDatabase , sauf que toutes les méthodes sont asynchrones.
Vous créez un objet IBatch à l’aide de la méthode IDatabase.CreateBatch, puis exécutez le lot à l’aide de la méthode IBatch.Execute, comme indiqué dans l’exemple suivant. Ce code définit simplement une valeur de chaîne, incrémente et décrémente les compteurs utilisés dans l’exemple précédent, puis affiche les résultats :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Il est important de comprendre qu’à la différence d’une transaction, si une commande du lot échoue parce qu’elle est mal formée, les autres commandes peuvent continuer à s’exécuter. La méthode IBatch.Execute ne retourne pas d’indication de réussite ou d’échec.
Effectuer des opérations de cache « fire and forget »
Redis prend en charge les opérations « fire and forget » à l’aide d’indicateurs de commande. Dans ce cas, le client lance simplement une opération mais n’est pas intéressé par le résultat et n'attend pas la fin de la commande. L’exemple ci-dessous montre comment exécuter la commande INCR en tant qu’opération « fire and forget » :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Spécifier une expiration automatique des clés
Lorsque vous stockez un élément dans un cache Redis, vous pouvez spécifier un délai après lequel l'élément est automatiquement supprimé du cache. Vous pouvez également demander le temps restant avant qu’une clé expire à l’aide de la commande TTL . Cette commande est disponible pour des applications StackExchange à l’aide de la méthode IDatabase.KeyTimeToLive .
L’extrait de code suivant montre comment définir un délai d’expiration de 20 secondes sur une clé et demander la durée de vie restante de la clé :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Vous pouvez également définir le délai d’expiration sur une date et une heure spécifiques à l’aide de la commande EXPIRE, disponible dans la bibliothèque StackExchange en tant que méthode KeyExpireAsync :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Conseil
Vous pouvez supprimer manuellement un élément du cache à l’aide de la commande DEL, disponible par le biais de la bibliothèque StackExchange en tant que méthode IDatabase.KeyDeleteAsync.
Utiliser des balises pour établir une corrélation croisée entre des éléments mis en cache
Un ensemble Redis est constitué de plusieurs éléments qui partagent une clé unique. Vous pouvez créer un ensemble à l'aide de la commande SADD. Vous pouvez récupérer les éléments d’un ensemble à l'aide de la commande SMEMBERS. La bibliothèque StackExchange implémente la commande SADD avec la méthode IDatabase.SetAddAsync, et la commande SMEMBERS avec la méthode IDatabase.SetMembersAsync.
Vous pouvez également combiner les ensembles existants pour créer de nouveaux ensembles à l'aide des commandes SDIFF (différence ensembliste), SINTER (intersection ensembliste) et SUNION (union ensembliste). La bibliothèque StackExchange unifie ces opérations dans la méthode IDatabase.SetCombineAsync . Le premier paramètre de cette méthode spécifie l’opération ensembliste à effectuer.
Les extraits de code suivants montrent comment les ensembles peuvent être utiles pour rapidement stocker et récupérer des collections d'éléments connexes. Ce code utilise le type BlogPost décrit dans la section Implémenter des applications clientes de cache Redis, plus haut dans cet article.
Un objet BlogPost contient quatre champs : un ID, un titre, un classement et une collection de balises. Le premier extrait de code ci-dessous montre les exemples de données utilisés pour remplir une liste C# d’objets BlogPost :
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Vous pouvez stocker les balises pour chaque objet BlogPost en tant qu’ensemble dans un cache Redis, puis associer chaque ensemble avec l’ID de l’objet BlogPost. Cela permet à une application de trouver rapidement toutes les balises appartenant à un billet de blog spécifique. Pour activer la recherche dans le sens opposé et rechercher tous les billets de blog qui partagent une balise spécifique, vous pouvez créer un autre ensemble qui contient les billets de blog faisant référence à l'ID de balise dans la clé :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Ces structures permettent d'effectuer de nombreuses requêtes courantes de manière très efficace. Par exemple, vous pouvez rechercher et afficher toutes les balises du billet de blog 1 comme suit :
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Vous pouvez rechercher toutes les balises qui sont communes aux billets de blog 1 et 2 en effectuant une opération d'intersection ensembliste, comme suit :
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Vous pouvez également rechercher tous les billets de blog qui contiennent une balise spécifique :
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Rechercher des éléments consultés récemment
Une tâche requise courante de nombreuses applications est celle de trouver les éléments consultés le plus récemment. Par exemple, un blog peut souhaiter afficher des informations sur les billets de blog les plus récemment consultés.
Vous pouvez implémenter cette fonctionnalité en utilisant une liste Redis. Celle-ci contient plusieurs éléments qui partagent la même clé. Elle agit comme une file d’attente à deux extrémités. Vous pouvez envoyer des éléments vers chaque extrémité de la liste à l’aide des commandes LPUSH (push à gauche) et RPUSH (push à droite). Vous pouvez récupérer des éléments à partir d’une des extrémités de la liste en utilisant les commandes LPOP et RPOP. Vous pouvez également renvoyer un ensemble d'éléments à l'aide des commandes LRANGE et RRANGE.
Les extraits de code ci-dessous montrent comment vous pouvez effectuer ces opérations à l'aide de la bibliothèque StackExchange. Ce code utilise le type BlogPost issu des exemples précédents. Quand un utilisateur lit un billet de blog, la méthode IDatabase.ListLeftPushAsync pousse son titre vers une liste associée à la clé « blog:recent_posts » dans le cache Redis.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Lors de la lecture des autres billets de blog, leurs titres sont envoyés à la même liste. La liste est organisée selon la séquence d’ajout des titres. Les billets de blog consultés le plus récemment figurent à l’extrémité gauche de la liste. (Si un même billet de blog est lu plusieurs fois, il a plusieurs entrées dans la liste.)
Vous pouvez afficher les titres des billets de blog consultés le plus récemment à l’aide de la méthode IDatabase.ListRange . Cette méthode prend la clé qui contient la liste, un point de départ et un point de fin. L’extrait de code suivant récupère le titre des 10 billets de blog (éléments de 0 à 9) à l’extrémité la plus à gauche de la liste :
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Notez que la méthode ListRangeAsync ne supprime pas d’éléments de la liste. Pour ce faire, vous pouvez utiliser les méthodes IDatabase.ListLeftPopAsync et IDatabase.ListRightPopAsync.
Pour empêcher la liste de croître indéfiniment, vous pouvez régulièrement éliminer les éléments de la liste. L’extrait de code ci-dessous montre comment supprimer tous les éléments de la liste, sauf les cinq les plus à gauche :
await cache.ListTrimAsync(redisKey, 0, 5);
Implémenter un classement
Par défaut, les éléments d’un ensemble ne sont pas conservés dans un ordre spécifique. Vous pouvez créer un ensemble ordonné en utilisant la commande ZADD (méthode IDatabase.SortedSetAdd dans la bibliothèque StackExchange). Les éléments sont classés à l’aide d’une valeur numérique appelée « score », fournie en tant que paramètre à la commande.
L'extrait de code suivant ajoute le titre d'un billet de blog à une liste ordonnée. Dans cet exemple, chaque billet de blog comporte également un champ de score contenant son classement.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Vous pouvez récupérer les titres et scores de billet de blog dans l’ordre croissant des scores à l’aide de la méthode IDatabase.SortedSetRangeByRankWithScores :
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Notes
La bibliothèque StackExchange fournit également la méthode IDatabase.SortedSetRangeByRankAsync qui renvoie les données dans l’ordre des scores, mais ne renvoie pas les scores.
Vous pouvez également récupérer des éléments dans l’ordre décroissant des scores et limiter le nombre d’éléments renvoyés en fournissant des paramètres supplémentaires à la méthode IDatabase.SortedSetRangeByRankWithScoresAsync. L'exemple suivant affiche les titres et les scores des 10 premiers billets de blog classés :
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
L’exemple suivant utilise la méthode IDatabase.SortedSetRangeByScoreWithScoresAsync qui permet de limiter les éléments qui sont retournés à ceux qui s’inscrivent dans une plage de scores donnée :
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Message à l’aide de canaux
Outre son utilisation comme cache de données, un serveur Redis fournit la messagerie via un mécanisme éditeur/abonné hautes performances. Les applications clientes peuvent s'abonner à un canal, et les autres applications ou services peuvent publier des messages dans le canal. Les applications abonnées reçoivent ensuite ces messages pour les traiter.
Redis fournit la commande SUBSCRIBE que les applications clientes doivent utiliser pour s’abonner à des canaux. Cette commande attend le nom d'un ou de plusieurs canaux sur lesquels l'application acceptera les messages. La bibliothèque StackExchange inclut l’interface ISubscription qui permet à une application .NET Framework de s’abonner à des canaux et de publier sur ceux-ci.
Vous créez un objet ISubscription à l’aide de la méthode GetSubscriber de la connexion au serveur Redis. Vous écoutez ensuite des messages sur un canal à l’aide de la méthode SubscribeAsync de cet objet. L'exemple de code suivant montre comment s'abonner à un canal nommé « messages:blogPosts » :
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Le premier paramètre de la méthode Subscribe est le nom du canal. Ce nom suit les conventions qu’utilisent les clés dans le cache. Le nom peut contenir n'importe quelle donnée binaire, mais nous vous recommandons d'utiliser des chaînes relativement courtes et significatives pour garantir de bonnes performances et une bonne maintenabilité.
Notez également que l’espace de noms que les canaux utilisent diffère de celui utilisé par les clés. Cela signifie que vous pouvez avoir des canaux et des clés portant le même nom, même si cela risque de compliquer la gestion du code de votre application.
Le deuxième paramètre est un délégué Action. Ce délégué s'exécute en mode asynchrone chaque fois qu'un nouveau message apparaît dans le canal. Cet exemple affiche simplement le message dans la console (le message contient le titre d'un billet de blog).
Pour publier vers un canal, une application peut utiliser la commande Redis PUBLISH. La bibliothèque StackExchange fournit la méthode IServer.PublishAsync pour effectuer cette opération. L'extrait de code suivant montre comment publier un message sur le canal « messages:blogPosts » :
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Il existe plusieurs points que vous devez comprendre sur le mécanisme éditeur/abonné :
- Plusieurs utilisateurs peuvent s’abonner au même canal. Tous recevront les messages publiés sur celui-ci.
- Les abonnés ne reçoivent que les messages qui ont été publiés après le début de leur abonnement. Les canaux ne sont pas mis en mémoire tampon. Quand un message est publié, l’infrastructure Redis l’envoie à chaque abonné, puis le supprime.
- Par défaut, les messages sont reçus par les abonnés dans l'ordre dans lequel ils sont envoyés. Dans un système très actif avec un grand nombre de messages et de nombreux abonnés et éditeurs, garantir la remise de messages séquentielle peut ralentir les performances du système. Si chaque message est indépendant et si l’ordre est sans importance, vous pouvez activer un traitement simultané par le système Redis, qui peut contribuer à améliorer la réactivité. Vous pouvez faire cela dans un client StackExchange en définissant l’élément PreserveAsyncOrder de la connexion utilisée par l’abonné sur false :
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Considérations relatives à la sérialisation
Lorsque vous choisissez un format de sérialisation, tenez compte des compromis à trouver entre les performances, l’interopérabilité, le contrôle de version, la compatibilité avec les systèmes existants, la compression des données et la surcharge de la mémoire. Lorsque vous évaluez les performances, n’oubliez pas que les benchmarks sont fortement dépendants du contexte. Ils risquent de ne pas refléter votre charge de travail réelle et de ne pas prendre en compte les bibliothèques ou versions plus récentes. Il n’existe aucun sérialiseur ultrarapide répondant à lui seul aux besoins de tous les scénarios.
Voici certaines options à prendre en considération :
Protocol Buffers (également appelé protobuf) est un format de sérialisation développé par Google qui permet de sérialiser efficacement les données structurées. Il utilise des fichiers de définition fortement typés pour définir les structures des messages. Ces fichiers de définition sont ensuite compilés sous la forme d’un code propre au langage pour la sérialisation et la désérialisation des messages. Protobuf est utilisable sur des mécanismes RPC existants ou peut générer un service RPC.
Apache Thrift applique une approche similaire, impliquant des fichiers de définition fortement typés et une étape de compilation pour générer le code de sérialisation et les services RPC.
Apache Avro offre des fonctionnalités comparables à Protocol Buffers et à Thrift, mais ne comporte pas d’étape de compilation. À la place, les données sérialisées incluent toujours un schéma qui décrit la structure.
JSON est une norme ouverte qui utilise des champs de texte explicites. Ce format offre une prise en charge multiplateforme étendue. JSON n’utilise pas de schémas de message. Étant donné que ce format repose sur du texte, il ne se révèle pas très efficace sur le réseau. Toutefois, vous pouvez parfois renvoyer directement à un client des éléments mis en cache par le biais du protocole HTTP ; dans ce cas, le stockage de données JSON permet d’économiser les coûts de désérialisation à partir d’un autre format et de sérialisation vers JSON.
binary JSON (BSON) est un format de sérialisation binaire qui utilise une structure analogue à JSON. BSON a été conçu pour offrir un format plus léger, plus facile à analyser et plus rapidement sérialisable et désérialisable que JSON. Ses charges utiles présentent une taille comparable à celles du format JSON. Selon les données, une charge utile BSON peut être plus modeste ou plus volumineuse qu’une charge utile JSON. BSON comporte certains types de données supplémentaires qui ne sont pas disponibles au format JSON, en particulier BinData (pour les tableaux d’octets) et Date.
MessagePack est un format de sérialisation binaire conçu pour se révéler compact dans le cadre des transmissions sur le réseau. Il ne comporte aucun schéma de message ni contrôle du type de message.
Bond est une infrastructure multiplateforme permettant d’utiliser des données schématisées. Il prend en charge la sérialisation et la désérialisation interlangage. Les différences notables entre Bond et les autres systèmes répertoriés ici concernent la prise en charge de l’héritage, des alias de type et des génériques.
gRPC est un système RPC open source développé par Google. Par défaut, il utilise Protocol Buffers comme langage de définition et format d’échange de messages sous-jacent.
Étapes suivantes
- Documentation sur Azure Cache pour Redis
- FAQ sur Azure Cache pour Redis
- Modèle asynchrone basé sur des tâches
- Documentation Redis
- StackExchange.Redis
- Conseils sur le partitionnement des données
Ressources associées
Les modèles suivants peuvent également être pertinents dans votre cas si vous implémentez une mise en cache dans vos applications :
Modèle Cache-Aside : ce modèle décrit comment charger des données à la demande dans un cache à partir d’un magasin de données. Il permet également de maintenir la cohérence entre les données en cache et les données du magasin de données d’origine.
Le modèle de partitionnement fournit des informations sur l’implémentation d’un partitionnement horizontal pour vous aider à améliorer l’extensibilité lors du stockage de grands volumes de données et de l’accès à ceux-ci.