Modèle de partitionnement
Divisez un magasin de données en un ensemble de partitions horizontales ou de partitions de base de données. Cela peut améliorer l’extensibilité lors du stockage et de l’accès à grands volumes de données.
Contexte et problème
Un magasin de données hébergé par un serveur unique peut être soumis aux limitations suivantes :
Espace de stockage. Un magasin de données pour une application cloud à grande échelle est censé contenir un volume considérable de données qui peut augmenter sensiblement au fil du temps. En général, un serveur ne fournit qu’une quantité fixe de stockage sur disque, mais vous pouvez remplacer les disques existants par de plus gros disques, ou ajouter des disques supplémentaires à une machine à mesure que les volumes de données augmentent. Toutefois, il arrivera un moment où il ne sera plus possible d’augmenter facilement la capacité de stockage sur un serveur donné.
Ressources informatiques. Une application cloud est requise pour prendre en charge un grand nombre d’utilisateurs simultanés, qui exécutent tous des requêtes pour récupérer des informations à partir du magasin de données. Si un seul serveur héberge le magasin de données, il n’est pas toujours en mesure de fournir la puissance de traitement nécessaire pour prendre en charge cette charge. Cela allonge les temps de réponse pour les utilisateurs et entraîne des défaillances fréquentes lorsque les applications qui tentent de stocker et de récupérer des données atteignent le délai d’expiration. Il est possible d’ajouter de la mémoire ou de mettre à niveau les processeurs, mais le système arrivera à sa limite lorsqu’il ne sera plus possible d’augmenter les ressources de traitement.
Bande passante réseau. Enfin, les performances d’un magasin de données exécuté sur un serveur unique sont régies par le débit auquel le serveur peut recevoir des requêtes et envoyer des réponses. Il est possible que le volume de trafic réseau dépasse la capacité du réseau utilisé pour se connecter au serveur, ce qui entraîne l’échec des requêtes.
Géographie. Il peut être nécessaire de stocker les données générées par des utilisateurs spécifiques dans leur région pour des raisons juridiques, de conformité ou de performances, ou pour réduire la latence d’accès aux données. Si les utilisateurs sont répartis dans différents pays ou régions, il n’est pas toujours possible de stocker la totalité des données de l’application dans un même magasin de données.
Une mise à l’échelle verticale, via l’ajout de capacité de disque, de puissance de traitement, de mémoire et de connexions réseau, peuvent différer les effets de certaines de ces limitations. Mais il ne s’agit là que d’une solution temporaire. Une application cloud commerciale capable de prendre en charge un grand nombre d’utilisateurs et de gros volumes de données doit permettre une mise à l’échelle presque infinie. Une mise à l’échelle verticale n’est donc pas nécessairement la meilleure solution.
Solution
Divisez le magasin de données en partitions horizontales ou en partitions de base de données. Chaque partition a le même schéma, mais conserve son propre sous-ensemble de données. Une partition est un magasin de données à part entière (il peut contenir les données de nombreuses entités de types différents), exécuté sur un serveur agissant comme un nœud de stockage.
Ce modèle permet de bénéficier des avantages suivants :
Vous pouvez faire évoluer le système en ajoutant des partitions exécutées sur des nœuds de stockage supplémentaires.
Un système peut utiliser du matériel prêt à l’emploi au lieu d’ordinateurs spécialisés et coûteux pour chaque nœud de stockage.
Vous pouvez réduire les conflits et améliorer les performances en équilibrant la charge de travail entre les partitions.
Dans le cloud, les partitions peuvent se trouver physiquement à proximité des utilisateurs qui accéderont aux données.
Lors de la division d’un magasin de données en partitions, décidez quelles données doivent être placées dans chaque partition. En général, une partition contient des éléments compris dans une plage déterminée par un ou plusieurs attributs des données. Ces attributs forment la clé de partition. La clé de partition doit être statique. Elle ne doit pas reposer sur des données variables.
Le partitionnement organise physiquement les données. Lorsqu’une application stocke et récupère des données, la logique de partitionnement dirige l’application vers la partition appropriée. Cette logique de partitionnement peut être implémentée comme partie intégrante du code d’accès aux données dans l’application, ou elle peut être implémentée par le système de stockage de données si elle prend en charge le partitionnement en toute transparence.
L’abstraction de l’emplacement physique des données dans la logique de partitionnement permet un niveau élevé de contrôle sur les données contenues dans des partitions spécifiques. Elle permet également de migrer les données entre les partitions sans réviser la logique métier d’une application, si les données présentes dans les partitions doivent être redistribuées ultérieurement (par exemple, si les partitions deviennent déséquilibrées). En contrepartie, l’accès aux données suppose une surcharge supplémentaire pour déterminer l’emplacement de chaque élément de données récupéré.
Pour garantir l’extensibilité et des performances optimales, il est important fractionner les données d’une manière appropriée pour les types de requêtes que l’application exécute. Dans de nombreux cas, il est peu probable que le schéma de partitionnement corresponde exactement aux besoins de chaque requête. Par exemple, dans un système multi-locataires, une application pourrait avoir besoin de récupérer les données des locataires en utilisant l’ID du locataire, mais elle pourrait aussi avoir besoin de rechercher ces données sur la base d’un autre attribut tel que le nom ou l’emplacement du locataire. Pour gérer ces situations, mettez en œuvre une stratégie de partitionnement avec une clé de partition qui prend en charge les requêtes les plus courantes.
Si les requêtes récupèrent régulièrement les données à l’aide d’une combinaison de valeurs d’attributs, vous pouvez probablement définir une clé de partition composite en associant des attributs. Vous pouvez également utiliser un modèle tel qu’une table d’index pour permettre une recherche rapide des données en fonction des attributs qui ne sont pas couverts par la clé de partition.
Stratégies de partitionnement
Trois stratégies sont couramment utilisées lors de la sélection de la clé de partition et au moment de décider comment distribuer les données dans les partitions. Notez qu’il ne doit pas nécessairement y avoir une correspondance exacte entre les partitions et les serveurs qui les hébergent, un même serveur pouvant héberger plusieurs partitions. Les stratégies sont les suivantes :
Stratégie de recherche. Dans cette stratégie, la logique de partitionnement implémente un mappage qui achemine une requête de données vers la partition qui contient ces données à l’aide de la clé de partition. Dans une application multi-locataires, toutes les données d’un locataire pourraient être stockées ensemble dans un fragment en utilisant l’ID du locataire comme clé de fragmentation. Plusieurs locataires peuvent partager la même partition, mais les données d’un locataire spécifique ne sont pas réparties sur plusieurs partitions. L’image illustre le partitionnement des données de locataire en fonction des ID de locataire.
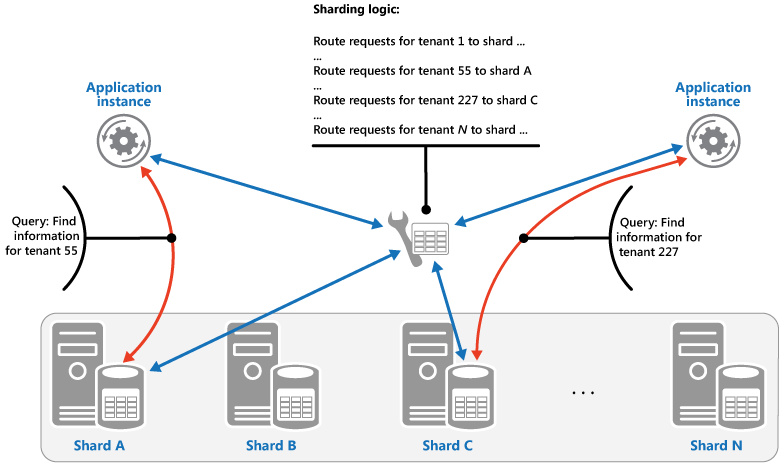
Le mappage entre la valeur de la clé de partition et le stockage physique où existent les données peut reposer sur des partitions physiques où chaque valeur de clé de partition est mappée à une partition physique. Une autre technique plus souple de rééquilibrage des partitions est le partitionnement virtuel, où les valeurs des clés de partition sont mappées au même nombre de partitions virtuelles, qui sont à leur tour mappées à moins de partitions physiques. Dans cette approche, une application localise les données à l’aide d’une valeur de clé de partition qui fait référence à une partition virtuelle, et le système mappe de façon transparente les partitions virtuelles aux partitions physiques. Le mappage entre une partition virtuelle et une partition physique peut changer sans nécessiter la modification du code d’application afin d’utiliser un autre ensemble de valeurs de clés de partition.
Stratégie de plage. Cette stratégie regroupe les éléments associés dans la même partition et les trie par clé de partition, celles-ci étant séquentielles. Elle est utile pour les applications qui récupèrent fréquemment des ensembles d’éléments à l’aide de requêtes de plage (des requêtes qui renvoient un ensemble d’éléments de données pour une clé de partition comprise dans une certaine plage). Par exemple, si une application doit régulièrement rechercher toutes les commandes passées au cours d’un mois spécifique, ces données peuvent être récupérées plus rapidement si toutes les commandes d’un mois sont stockées par date et heure dans la même partition. Si les commandes ont été stockées dans des partitions différentes, elles doivent être extraites individuellement via un grand nombre de requêtes ponctuelles (des requêtes qui renvoient un seul élément de données). L’image suivante illustre le stockage d’ensembles de données séquentiels (plages) dans la partition.
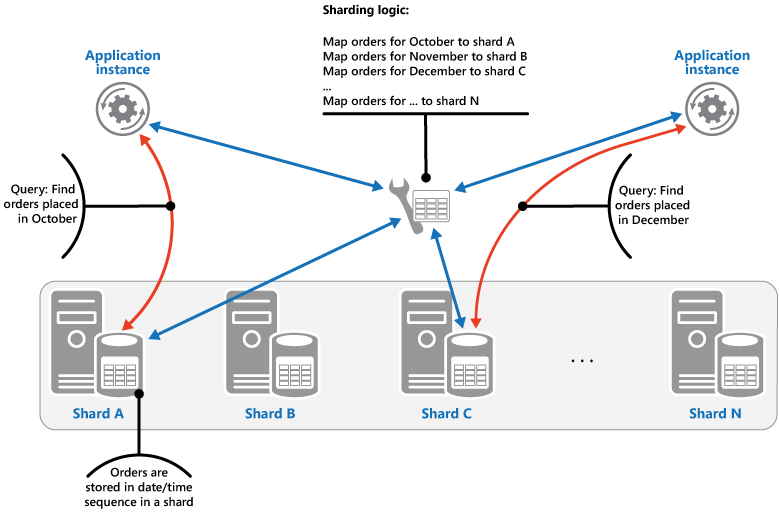
Dans cet exemple, la clé de partition est une clé composite contenant le mois de la commande en tant qu’élément le plus significatif, suivi du jour et de l’heure de la commande. Les données relatives aux commandes sont naturellement triées lorsque des commandes sont créées et ajoutées à une partition. Certains magasins de données prennent en charge les clés de partition en deux parties contenant un élément clé de partition qui identifie la partition et une clé de ligne qui identifie de façon unique un élément dans la partition. Les données sont généralement conservées selon l’ordre de clé de ligne dans la partition. Les éléments soumis à des requêtes de plage et qui doivent être regroupés peuvent utiliser une clé de partition qui a la même valeur pour la clé de partition, mais une valeur unique pour la clé de ligne.
Stratégie de hachage. L’objectif de cette stratégie est de réduire le risque de zones réactives (partitions qui reçoivent une charge disproportionnée). Elle distribue les données dans les partitions d’une façon qui permet d’obtenir un équilibre entre la taille de chaque partition et la charge moyenne que rencontre chaque partition. La logique de partitionnement traite la partition dans laquelle stocker un élément en fonction du hachage d’un ou plusieurs attributs des données. La fonction de hachage choisie doit distribuer les données uniformément parmi les partitions, éventuellement en introduisant un élément aléatoire dans le calcul. L’image suivante illustre le partitionnement des données de locataire en fonction du hachage des ID de locataire.
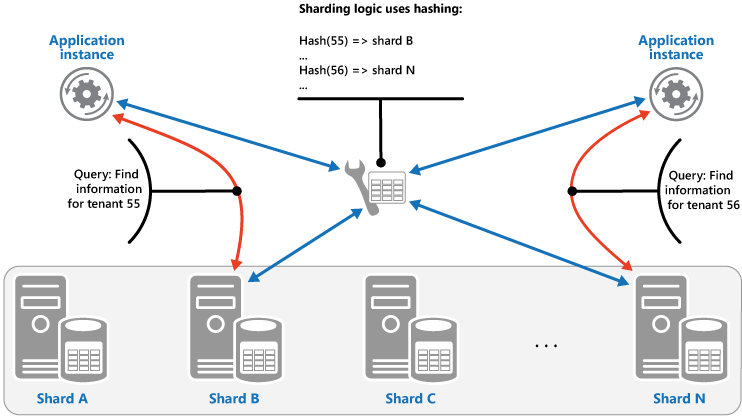
Pour comprendre l’avantage de la stratégie de hachage par rapport aux autres stratégies de fragmentation, considérez comment une application multi-locataires qui inscrit de nouveaux locataires de manière séquentielle pourrait assigner les locataires aux fragments dans le magasin de données. Avec la stratégie de plage, les données des locataires 1 à n sont stockées dans la partition A, les données des locataires n+1 à m sont stockées dans la partition B, et ainsi de suite. Si les derniers locataires enregistrés sont également les plus actifs, la majorité de l’activité des données survient dans un petit nombre de partitions, ce qui peut entraîner des zones réactives. En revanche, la stratégie de hachage alloue des locataires à des partitions en fonction d’un hachage de leur ID de locataire. Cela signifie que des locataires séquentiels sont plus susceptibles d’être alloués à des partitions différentes, ce qui distribue la charge entre celles-ci. L’illustration précédente montre ceci pour les locataires 55 et 56.
Les trois stratégies de partitionnement ont les avantages et les considérations suivantes :
Recherche. Cette stratégie offre davantage de contrôle sur la façon dont les partitions sont configurées et utilisées. Les partitions virtuelles permettent de réduire l’impact lors du rééquilibrage des données, car de nouvelles partitions physiques peuvent être ajoutées pour répartir la charge de travail. Le mappage entre une partition virtuelle et les partitions physiques qui implémentent cette partition peut être modifié sans influer sur le code d’application qui utilise une clé de partition pour stocker et récupérer des données. La recherche des emplacements de partition peut imposer une surcharge supplémentaire.
Plage. Cette stratégie est facile à implémenter et fonctionne bien avec les requêtes de plage, car elles peuvent souvent extraire plusieurs éléments de données d’une même partition en une seule opération. Cette stratégie facilite la gestion des données. Par exemple, si des utilisateurs de la même région se trouvent dans la même partition, les mises à jour peuvent être planifiées dans chaque fuseau horaire selon le modèle local de charge et de demande. Toutefois, cette stratégie ne fournit pas un équilibrage optimal entre les partitions. Le rééquilibrage des partitions est difficile et peut ne pas résoudre le problème de charge inégale si la majorité de l’activité concerne des clés de partition adjacentes.
Hachage. Cette stratégie offre plus de chances pour une meilleure distribution de la charge et des données. Le routage des requêtes peut être effectué directement à l’aide de la fonction de hachage. Il n’est pas nécessaire de maintenir un mappage. Notez que le calcul du hachage peut imposer une surcharge supplémentaire. En outre, il est difficile de rééquilibrer les partitions.
Les systèmes de partitionnement les plus courants implémentent l’une des approches décrites ci-dessus, mais vous devez également envisager les exigences métier de vos applications et leurs modèles d’utilisation des données. Par exemple, dans une application multi-locataires :
Vous pouvez partitionner les données en fonction de la charge de travail. Vous pouvez séparer les données des locataires hautement volatiles dans des partitions distinctes. Cela peut améliorer la vitesse d’accès aux données pour les autres locataires.
Vous pouvez partitionner les données en fonction de l’emplacement des locataires. Vous pouvez mettre hors connexion les données des locataires dans une région géographique spécifique à des fins de sauvegarde et de maintenance pendant les heures creuses dans cette région, tandis que les données des locataires dans d’autres régions de données restent en ligne et accessibles pendant leurs heures de travail.
Les locataires à haute valeur pourraient se voir attribuer leurs propres fragments privés, performants et peu chargés, tandis que les locataires à valeur moindre pourraient être amenés à partager des fragments plus densément peuplés et occupés.
Les données pour les locataires nécessitant un niveau élevé d’isolation et de confidentialité peuvent être stockées sur un serveur complètement séparé.
Opérations de déplacement de données et de mise à l’échelle
Chacune des stratégies de partitionnement implique des fonctionnalités différentes et des niveaux de complexité distincts pour la gestion du scale-in, du scale-out, du déplacement des données et la maintenance de l’état.
La stratégie de recherche permet d’effectuer les opérations de déplacement des données et de mise à l’échelle au niveau de l’utilisateur, que ce soit en ligne ou hors connexion. La technique consiste à suspendre certaines ou toutes les activités des utilisateurs (par exemple, pendant les périodes creuses), déplacer les données vers la nouvelle partition virtuelle ou partition physique, modifier les mappages, invalider ou actualiser les caches qui contiennent ces données, puis autoriser la reprise des activités des utilisateurs. Ce type d’opération peut souvent être géré de manière centralisée. La stratégie de recherche nécessite un état hautement compatible avec le cache et les réplicas.
La stratégie de plage impose certaines restrictions sur les opérations de déplacement de données et de mise à l’échelle, qui doivent généralement être effectuées lorsqu’une partie ou la totalité du magasin de données est hors connexion, car elles impliquent un fractionnement et une fusion des données entre les partitions. Le déplacement des données pour rééquilibrer les partitions ne résout pas forcément le problème de la charge inégale si la majorité de l’activité concerne des clés de partition adjacentes ou des identificateurs de données qui se trouvent dans la même plage. La stratégie de plage peut également nécessiter la maintenance d’un état pour mapper des plages avec les partitions physiques.
La stratégie de hachage rend les opérations de déplacement de données et de mise à l’échelle plus complexe, car les clés de partition sont des hachages des identificateurs de données ou des clés de partition. Le nouvel emplacement de chaque partition doit être déterminé à partir de la fonction de hachage, ou la fonction modifiée pour fournir les mappages corrects. Toutefois, la stratégie de hachage ne requiert pas la maintenance de l’état.
Problèmes et considérations
Prenez en compte les points suivants lorsque vous choisissez comment implémenter ce modèle :
Le partitionnement de base de données est complémentaire d’autres formes de partitionnement, telles que le partitionnement vertical et le partitionnement fonctionnel. Par exemple, une même partition peut contenir des entités qui ont été partitionnées verticalement, et une partition fonctionnelle peut être implémentée sous la forme de plusieurs partitions. Pour plus d’informations sur le partitionnement, voir Conseils sur le partitionnement des données.
Veillez à l’équilibre des partitions afin qu’elles gèrent un volume similaire d’E/S. Au fur et à mesure que des données sont insérées et supprimées, il est nécessaire de régulièrement rééquilibrer les partitions pour garantir une distribution uniforme et réduire les risques de zones réactives. Le rééquilibrage peut s’avérer une opération coûteuse. Pour réduire la nécessité de rééquilibrage, planifiez la croissance en vous assurant que chaque partition contient suffisamment d’espace libre pour gérer le volume attendu de modifications. Vous devez également développer des stratégies et des scripts pour rééquilibrer rapidement les partitions si cela s’avère nécessaire.
Utilisez des données stables pour la clé de partition. Si la clé de partition est modifiée, l’élément de données correspondant doit peut-être changer de partition, augmentant ainsi la quantité de travail effectué par les opérations de mise à jour. Pour cette raison, évitez de baser la clé de partition sur des informations potentiellement volatiles. Au lieu de cela, recherchez des attributs fixes ou qui forment naturellement une clé.
Assurez-vous que les clés de partition sont uniques. Par exemple, évitez d’utiliser les champs incrémentés automatiquement comme clé de partition. Dans certains systèmes, les champs incrémentés automatiquement ne peuvent pas être coordonnés entre les partitions. Des éléments de partitions différentes risquent alors de se retrouver avec la même clé de partition.
Les valeurs incrémentées automatiquement dans d’autres champs (même si elles ne sont pas des clés de partition) peuvent également entraîner des problèmes. Par exemple, si vous utilisez des champs incrémentés automatiquement pour générer des ID uniques, deux éléments distincts situés dans des partitions différentes risquent d’avoir le même ID.
Il n’est pas toujours possible de créer une clé de partition qui répond aux besoins de chaque requête possible sur les données. Partitionnez les données pour prendre en charge les requêtes les plus fréquentes et, si nécessaire, créez des tables d’index secondaires pour prendre en charge les requêtes qui récupèrent des données à l’aide de critères basés sur des attributs qui ne font pas partie de la clé de partition. Pour plus d'informations, voir le modèle de table d’index.
Les requêtes qui accèdent à une seule partition sont plus efficaces que celles qui récupèrent des données de plusieurs partitions. Par conséquent, évitez d’implémenter un système de partitionnement où les applications exécutent de nombreuses requêtes qui joignent les données contenues dans des partitions différentes. N’oubliez pas qu’une même partition peut contenir les données de plusieurs types d’entités. Envisagez la dénormalisation de vos données pour conserver les entités associées qui sont fréquemment interrogées ensemble (par exemple, les détails des clients et des commandes qu’ils ont passées) dans la même partition pour réduire le nombre de lectures effectuées par une application.
Si une entité dans une partition fait référence à une entité stockée dans une autre partition, incluez la clé de partition de la deuxième entité dans le schéma de la première entité. Cela permet d’améliorer les performances des requêtes qui font référence à des données liées dans les partitions.
Si une application doit effectuer des requêtes qui récupèrent des données dans plusieurs partitions, il est possible extraire ces données à l’aide de tâches parallèles. Par exemple, il peut s’agir de requêtes de distribution ramifiée, où les données de plusieurs partitions sont récupérées en parallèle, puis regroupées en un résultat unique. Toutefois, cette approche ajoute inévitablement une certaine complexité à la logique d’accès aux données d’une solution.
Pour de nombreuses applications, la création d’un plus grand nombre de petites partitions peut s’avérer plus efficace que d’avoir un petit nombre de grandes partitions, car elles offrent plus d’opportunités pour l’équilibrage de charge. Cela peut également être utile si vous envisagez de migrer des partitions d’un emplacement physique vers un autre. Une petite partition est plus rapide à déplacer qu’une grande partition.
Assurez-vous que les ressources disponibles pour chaque nœud de stockage de partition sont suffisantes pour gérer les exigences d’extensibilité en termes de débit et de taille des données. Pour plus d’informations, consultez la section « Concevoir des partitions évolutives » dans le guide sur le partitionnement de données.
Envisagez de répliquer les données de référence pour toutes les partitions. Si une opération qui récupère des données à partir d’une partition fait également référence à des données statiques ou lentes dans la même requête, ajoutez ces données à la partition. L’application peut ensuite récupérer facilement toutes les données pour la requête, sans avoir à effectuer un aller-retour supplémentaire vers un magasin de données distinct.
Si les données de référence sont stockées dans plusieurs modifications de partitions, le système doit synchroniser ces modifications sur toutes les partitions. Le système peut rencontrer une certaine incohérence pendant cette synchronisation. Si vous faites cela, vous devez vous assurer que vos applications sont en mesure de gérer cette situation.
Il peut être difficile de maintenir l’intégrité référentielle et la cohérence entre les partitions. Vous devez donc limiter les opérations qui influent sur les données de plusieurs partitions. Si une application doit modifier des données dans plusieurs partitions, évaluez si une cohérence totale des données est nécessaire. Une approche courante alternative dans le cloud consiste à mettre en œuvre une cohérence finale. Les données de chaque partition sont mises à jour séparément, et la logique d’application doit garantir que le succès de toutes les mises à jour, ainsi que la gestion des incohérences qui peuvent survenir lors de l’interrogation des données pendant l’exécution d’une opération éventuellement cohérente. Pour en savoir plus sur l’implémentation de cohérence éventuelle, voir Manuel d’introduction à la cohérence des données.
La configuration et la gestion d’un grand nombre de partitions peuvent se révéler complexes. Les tâches telles que la surveillance, la sauvegarde, la vérification de la cohérence et la journalisation/l’audit doivent être effectuées sur plusieurs partitions et serveurs, éventuellement situés à plusieurs emplacements. Ces tâches sont susceptibles d’être implémentées à l’aide de scripts ou autres solutions d’automatisation, mais sans pour autant éliminer entièrement les besoins d’administration supplémentaires.
Les partitions peuvent être géolocalisées, afin de rapprocher les données qu’elles contiennent des instances d’une application qui les utilisent. Cette approche peut améliorer considérablement les performances, mais elle nécessite une attention particulière pour les tâches qui doivent accéder à plusieurs partitions à différents emplacements.
Quand utiliser ce modèle
Utilisez ce modèle quand un magasin de données est susceptible d’avoir besoin de plus de ressources disponibles pour un nœud de stockage unique, ou pour améliorer les performances en réduisant les conflits dans un magasin de données.
Notes
Le principal objectif du partitionnement est d’améliorer les performances et l’extensibilité d’un système, mais il peut au passage améliorer la disponibilité selon la répartition des données dans les partitions. Un échec dans une partition n’empêche pas nécessairement une application d’accéder aux données contenues dans les autres partitions. Un opérateur peut exécuter une maintenance ou une récupération sur une ou plusieurs partitions sans rendre inaccessible la totalité des données d’une application. Pour plus d’informations, consultez les recommandations en matière de partitionnement de données.
Conception de la charge de travail
Un architecte devrait évaluer comment le modèle de Partitionnement peut être utilisé dans la conception de sa charge de travail pour répondre aux objectifs et principes couverts par les piliers de Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Étant donné que les données ou le traitement sont isolés au niveau de la partition, un dysfonctionnement dans une partition reste limité à celle-ci. - RE :06Partitionnement des données - RE :07 Auto-conservation |
| L’optimisation des coûts est axée sur le maintien et l’amélioration du retour sur investissement de votre charge de travail. | Un système qui met en œuvre la fragmentation bénéficie souvent de l’utilisation de plusieurs instances de ressources de calcul ou de stockage moins coûteuses plutôt que d’une seule ressource plus coûteuse. Dans de nombreux cas, cette configuration peut vous faire économiser de l’argent. - CO :07 Coûts composants |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes grâce à des optimisations de la mise à l’échelle, des données, du code. | Lorsque vous utilisez la fragmentation dans votre stratégie de mise à l’échelle, les données ou le traitement sont isolés à une partition, donc ils ne concurrencent pour les ressources qu’avec d’autres requêtes qui sont dirigées vers cette partition. Vous pouvez également utiliser le partitionnement pour optimiser en fonction de la géographie. - PE :05 Mise à l’échelle et partitionnement - PE :08 Performance des données |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Prenons l'exemple d'un site web qui propose des informations détaillées sur les livres publiés dans le monde entier. Le nombre de livres pouvant être catalogués dans cette charge de travail et les modèles typiques d'interrogation/d'utilisation ne permettent pas d'envisager l'utilisation d'une seule base de données relationnelle pour stocker les informations relatives aux livres. L'architecte de charge de travail décide de partitionner les données sur plusieurs instances de base de données, en utilisant le numéro international normalisé du livre (ISBN) statique comme clé de partition. Plus précisément, il utilise le chiffre de vérification (0 - 10) de l’ISBN, ce qui permet d'obtenir 11 unités logiques possibles et d'équilibrer équitablement les données dans chaque partition. Pour commencer, il décide de colocaliser les 11 partitions logiques dans trois bases de données physiques. Il utilise l’approche de partitionnement de recherche et stocke les informations de correspondance clé-serveur dans une base de données de carte de partitions.
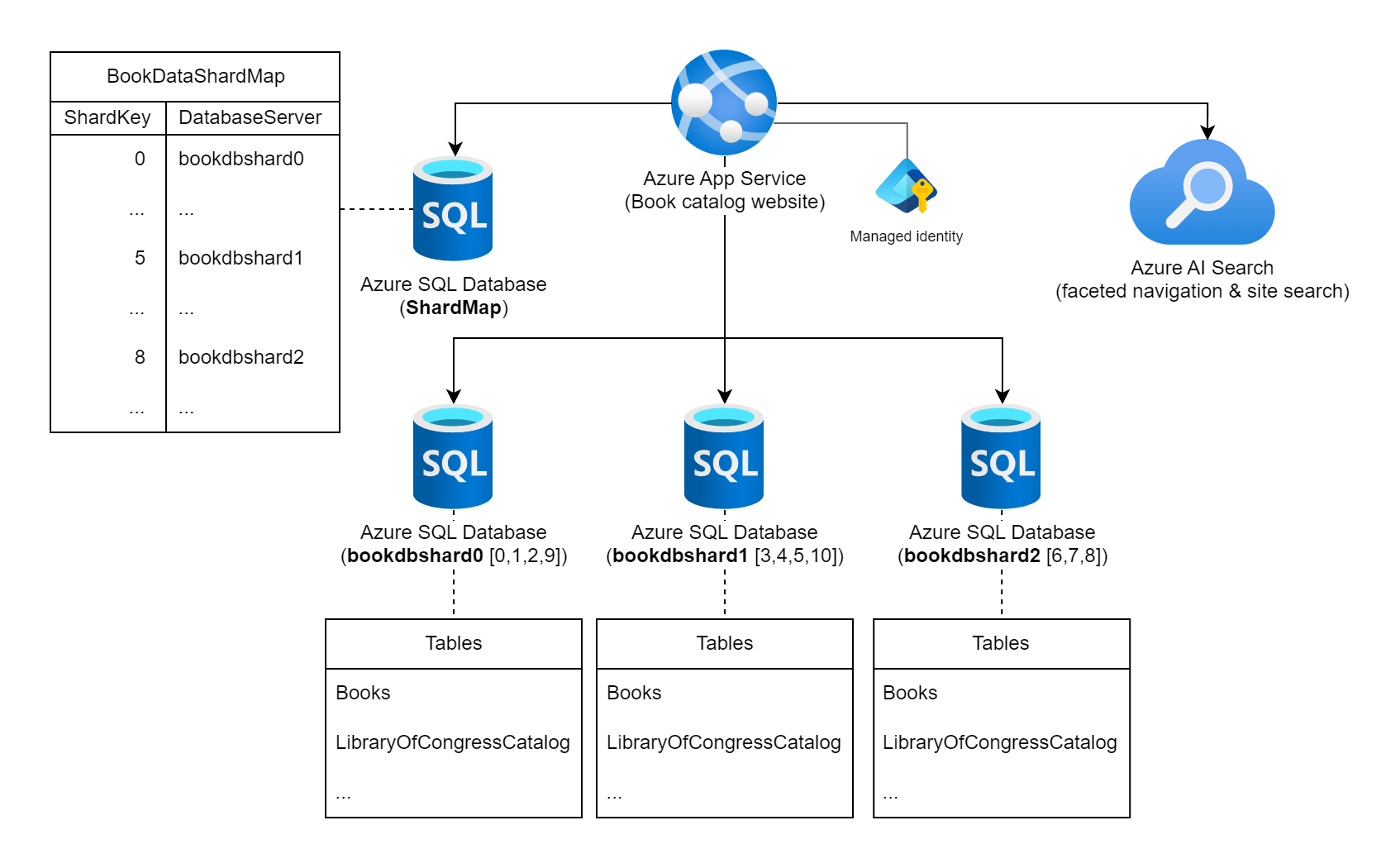
Diagramme montrant un service Azure App Service intitulé « Site web du catalogue de livres » connecté à plusieurs instances Azure SQL Database et à une instance Recherche Azure AI. L'une des bases de données se nomme ShardMap et comporte une table d'exemple qui reflète une partie de la table de cartes de partition présentée plus loin dans ce document. Il existe également trois instances de base de données de partition répertoriées : bookdbshard0, bookdbshard1 et bookdbshard2. Chacune de ces bases de données contient un exemple de liste de tables. Les trois exemples sont identiques, répertoriant les tables de « Books » et « LibraryOfCongressCatalog », ainsi qu'un indicateur de tables supplémentaires. L'icône Recherche Azure AI indique une utilisation pour la navigation à facettes et la recherche de site. L’identité managée est associée à Azure App Service.
Carte de partitions de recherche
La base de données de carte de partitions contient la table et les données de carte de partitions suivantes.
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Exemple de code de site web - accès à une seule partition
Le site web ne connaît pas le nombre de bases de données de partition physique (trois dans cet exemple) ni la logique qui mappe une clé de partition à une instance de base de données, mais le site web sait que le chiffre de vérification de l’ISBN d’un livre doit être utilisé comme clé de partition. Le site web dispose d’un accès en lecture seule à la base de données de carte de partitions et d'un accès en lecture-écriture à toutes les bases de données de partition. Dans cet exemple, le site web utilise l’identité managée système d’Azure App Service qui héberge le site web pour l’autorisation de conserver les secrets hors des chaîne de connexion.
Le site web est configuré avec les chaîne de connexion suivantes, soit dans un fichier appsettings.json, comme dans cet exemple, soit via les paramètres d’application App Service.
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
Une fois les informations de connexion à la base de données de carte de partitions disponibles, un exemple de requête de mise à jour exécutée par le site web vers le pool de partitions de la charge de travail ressemblerait au code suivant.
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
Dans l’exemple de code précédent, si book.Isbn était remplacé par 978-8-1130-1024-6, alors isbnCheckDigit deviendrait 6. L’appel à OpenShardConnectionForKeyAsync(6) serait généralement implémenté avec une approche cache-aside. Il interroge la base de données de carte de partitions identifiée par la chaîne de connexion ShardMapDb s’il ne dispose pas d’informations de partition mises en cache pour la clé de partition 6. La valeur bookdbshard2, provenant du cache de l'application ou de la base de données de partitions, remplace SHARD dans la chaîne de connexion BookDbFragment. Une connexion groupée est (ré)établie pour bookdbshard2.database.windows.net, ouverte et retournée au code appelant. Le code met ensuite à jour l’enregistrement existant sur cette instance de base de données.
Exemple de code de site web - accès à plusieurs partitions
Dans les rares cas où le site web a besoin d'une requête directe interpartition, l'application exécute une requête de distribution ramifiée parallèle sur toutes les partitions.
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
En guise d’alternative aux requêtes interpartitions de cette charge de travail, vous pouvez utiliser un index géré en externe dans Recherche Azure AI, par exemple pour la recherche de site ou les fonctionnalités de navigation à facettes.
Ajout d’instances de partition
L’équipe responsable des charges de travail est consciente que si le catalogue de données ou son utilisation simultanée venait à augmenter de manière significative, plus de trois instances de base de données pourraient être nécessaires. Elle ne prévoit pas d'ajouter dynamiquement des serveurs de base de données et assumera les temps d'arrêt de la charge de travail si une nouvelle partition doit être mise en ligne. L’ajout d’une nouvelle instance de partition en ligne nécessite le déplacement de données de partitions existantes vers la nouvelle partition, ainsi qu’une mise à jour de la table de carte de partitions. Cette approche relativement statique permet à la charge de travail de mettre en cache en toute confiance le mappage de la base de données des clés de partition dans le code du site web.
Dans cet exemple, la logique de la clé de répartition a une limite supérieure stricte de 11 partitions physiques au maximum. Si l’équipe responsable de la charge de travail effectue des tests d’estimation de la charge et détermine que plus de 11 instances de bases de données seront finalement nécessaires, une modification invasive de la logique de la clé de partition devra être apportée. Cette opération implique une planification minutieuse des modifications du code et de la migration des données vers la nouvelle logique de clé.
Fonctionnalité SDK
Au lieu d’écrire du code personnalisé pour la gestion des partitions et le routage des requêtes vers des instances Azure SQL Database, utilisez la bibliothèque cliente de base de données élastique. Cette bibliothèque prend en charge la gestion des cartes de partitions, le routage des requêtes dépendant des données et les requêtes interpartitions dans C# et Java.
Étapes suivantes
Les recommandations suivantes peuvent aussi s’avérer utiles pendant l’implémentation de ce modèle :
- Data Consistency Primer (Manuel d’introduction à la cohérence des données). Il peut être nécessaire de maintenir la cohérence des données réparties dans les différentes partitions. Résume les problèmes se rapportant au maintien de la cohérence des données distribuées, et décrit les avantages et les compromis des différents modèles de cohérence.
- Conseils sur le partitionnement des données. Le partitionnement d’un magasin de données peut entraîner d’autres problèmes. Décrit ces problèmes liés au partitionnement des magasins de données dans le cloud pour améliorer l’extensibilité, réduire les conflits et optimiser les performances.
Ressources associées
Les modèles suivants peuvent également être pertinents lors de l’implémentation de ce modèle :
- Modèle de table d’index. Parfois, il n’est pas possible de prendre entièrement en charge les requêtes uniquement par le biais de la conception de la clé de partition. Permet à une application de récupérer rapidement des données à partir d’un vaste magasin de données en spécifiant une clé autre que la clé de partition.
- Modèle de vue matérialisée. Pour maintenir les performances de certaines opérations de requête, il est utile de créer des vues matérialisées qui agrègent et synthétisent les données, surtout si ces données reposent sur les informations distribuées dans plusieurs partitions. Décrit comment générer et remplir ces vues.