Dérive de schéma dans le flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Il y a dérive de schéma quand les métadonnées de vos sources sont fréquemment mises à jour. Des champs, colonnes et types peuvent être ajoutés, supprimés ou modifiés à la volée. Sans gestion de la dérive de schéma, votre flux de données devient vulnérable aux modifications apportées aux sources de données en amont. En cas de modification des colonnes et des champs entrants, les modèles ETL types échouent, car ils sont généralement liés à ces noms de source.
Pour vous protéger contre la dérive de schéma, il est important de disposer d’un outil de flux de données vous permettant, en tant qu’ingénieur de données, de :
- Définir les sources dont les noms de champs, les types de données, les valeurs et les tailles sont modifiables
- Définir des paramètres de transformation qui peuvent fonctionner avec des modèles de données et non avec des champs et des valeurs codés en dur
- Définir des expressions qui comprennent les modèles pour correspondre aux champs entrants, au lieu d’utiliser des champs nommés
Azure Data Factory prend en charge en mode natif des schémas flexibles qui passent d’une exécution à une autre pour que vous puissiez générer une logique de transformation de données générique sans devoir recompiler vos flux de données.
Vous devez prendre une décision relative à l’architecture de votre flux de données pour accepter la dérive de schéma dans celui-ci. Lorsque vous effectuez cette opération, vous pouvez vous protéger contre les modifications de schéma à partir des sources. Toutefois, vous perdez alors la liaison anticipée de vos colonnes et types tout au long de votre flux de données. Azure Data Factory traite les flux d’une dérive de schéma en tant que flux de la liaison tardive. Ainsi, quand vous générez vos transformations, les noms des colonnes dérivées ne sont pas disponibles dans les vues de schéma dans le flux.
Cette vidéo présente quelques-unes des solutions complexes que vous pouvez facilement mettre en place dans les pipelines Azure Data Factory ou Synapse Analytics avec la fonctionnalité de dérive de schéma du flux de données. Dans cet exemple, nous créons des modèles réutilisables basés sur des schémas flexibles de base de données :
Dérive de schéma dans la source
Les colonnes entrant dans votre flux de données à partir de la définition de votre source sont définies comme étant « dérivées » lorsqu’elles ne sont pas présentes dans la projection de votre source. Vous pouvez voir la projection de votre source sous l’onglet Projection dans la transformation de la source. Lorsque vous sélectionnez un jeu de données pour votre source, le service prend automatiquement le schéma du jeu de données et crée une projection à partir de cette définition de schéma du jeu de données.
Dans une transformation de source, la dérive de schéma est définie sous forme de colonnes de lecture qui ne sont pas définies dans votre schéma de jeu de données. Pour autoriser la dérive de schéma, cochez la case Autoriser la dérive de schéma dans la transformation de la source.
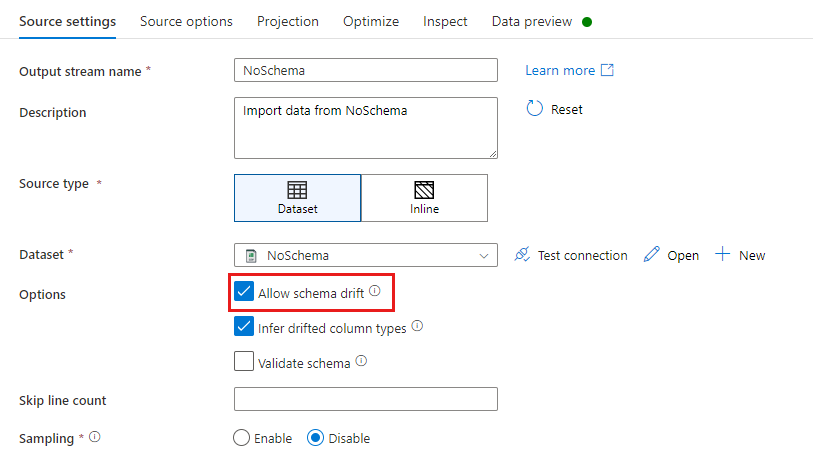
Quand la dérive de schéma est autorisée, tous les champs entrants sont lus à partir de votre source pendant l’exécution et transmis au récepteur via l’ensemble du flux. Par défaut, toutes les colonnes nouvellement détectées (colonnes dérivées) arrivent en tant que type de données chaîne. Si vous souhaitez que votre flux de données déduise automatiquement les types de données des colonnes dérivées, cochez la case Déduire les types des colonnes dérivées dans les paramètres de la source.
Dérive de schéma dans le récepteur
Dans une transformation de récepteur, il y a dérive de schéma quand vous écrivez des colonnes supplémentaires, en plus de ce qui est défini dans le schéma de données du récepteur. Pour autoriser la dérive de schéma, cochez la case Autoriser la dérive de schéma dans la transformation du récepteur.
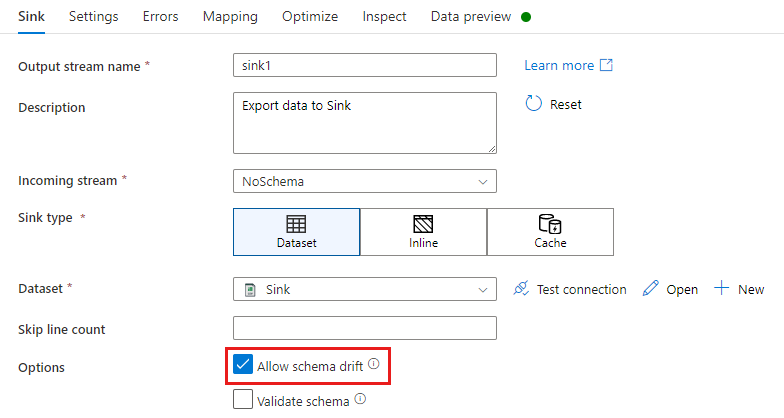
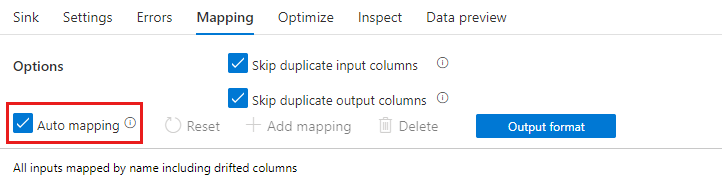
Si la dérive de schéma est autorisée, assurez-vous que le curseur Mappage automatique est activé dans l’onglet Mappage. Quand ce curseur est activé, toutes les colonnes entrantes sont écrites dans votre destination. Dans le cas contraire, vous devez utiliser le mappage basé sur des règles pour écrire des colonnes dérivées.
Transformation de colonnes dérivées
Quand votre flux de données contient des colonnes dérivées, vous pouvez y accéder dans vos transformations à l’aide des méthodes suivantes :
- Utilisez les expressions
byPositionetbyNamepour référencer explicitement une colonne par nom ou numéro de position. - Ajoutez un modèle de colonne dans une colonne dérivée ou une transformation d’agrégation pour mettre en correspondance n’importe quelle combinaison de nom, de flux, de position, d’origine ou de type.
- Ajoutez un mappage basé sur des règles dans une transformation de sélection ou de récepteur pour faire correspondre les colonnes dérivées aux alias de colonnes par le biais d’un modèle.
Pour plus d’informations sur la façon d’implémenter des modèles de colonne, consultez Modèles de colonne de flux de données de mappage.
Action rapide pour mapper des colonnes dérivées
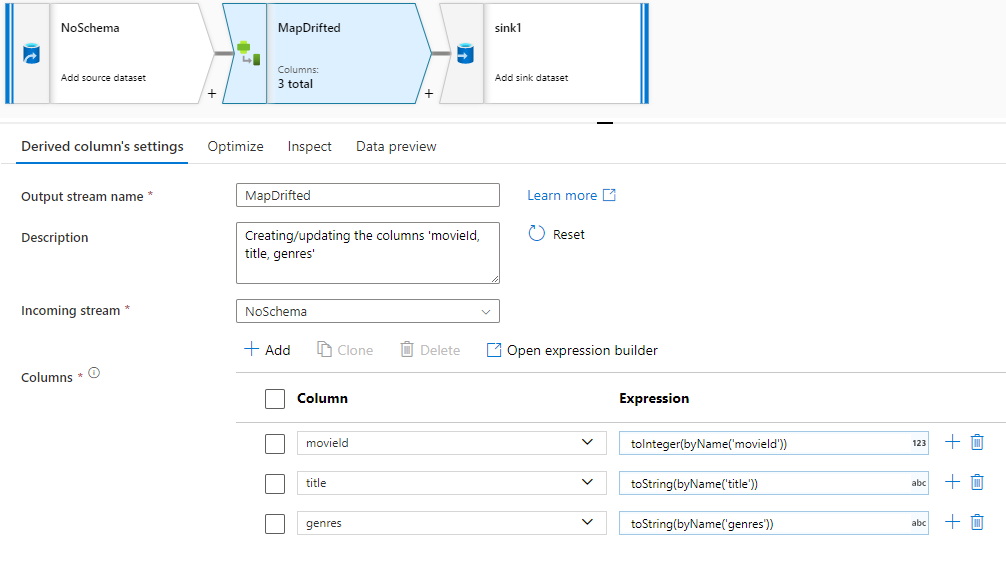
Pour référencer explicitement des colonnes dérivées, vous pouvez générer rapidement des mappages pour ces colonnes à l’aide d’une action rapide d’aperçu des données. Une fois le mode débogage activé, accédez à l’onglet Aperçu des données, puis cliquez sur Actualiser pour obtenir un aperçu des données. Si la fabrique de données détecte l’existence de colonnes dérivées, vous pouvez cliquer sur Mapper les éléments dérivés et générer une colonne dérivée qui vous permet de référencer toutes les colonnes dérivées dans des vues de schéma en aval.
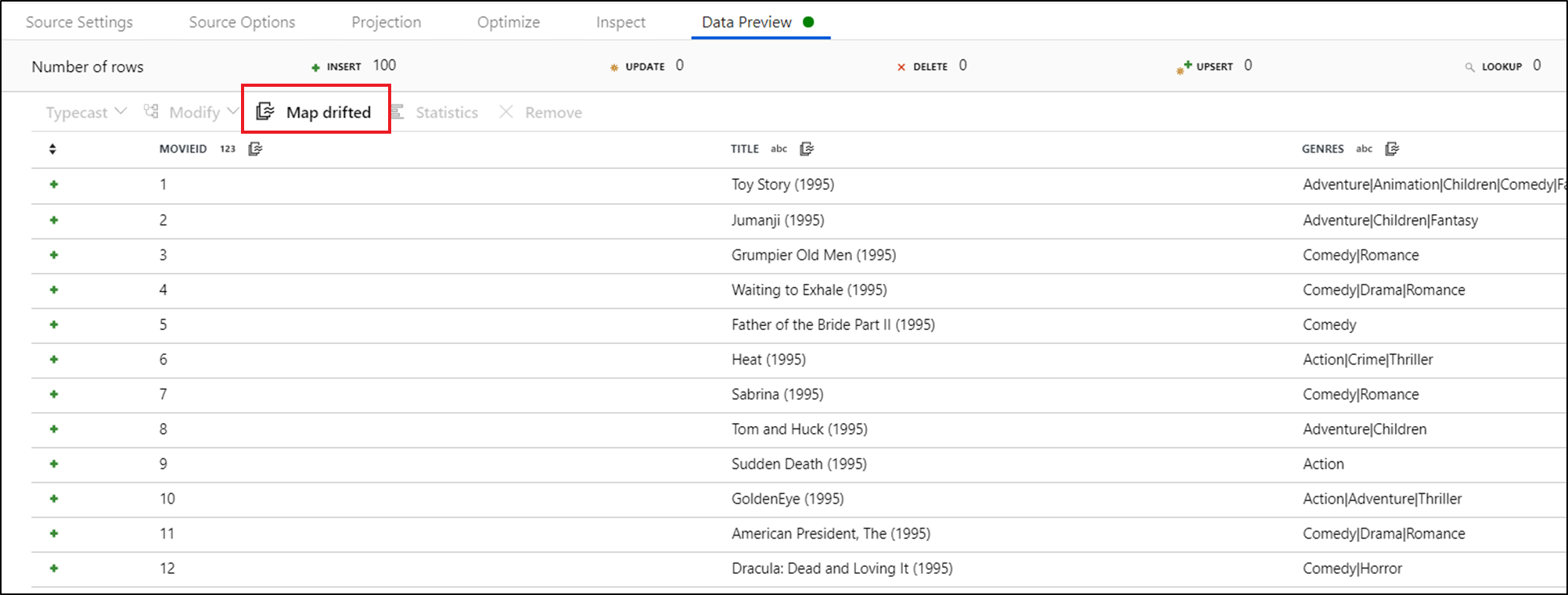
Dans la transformation de colonne dérivée générée, chaque colonne dérivée est mappée au nom et au type de données correspondants détectés. Dans l’aperçu des données ci-dessus, la colonne « movieId » est détectée en tant qu’entier. Une fois que vous avez cliqué sur Mapper les éléments dérivés, movieId est défini dans la colonne dérivée comme toInteger(byName('movieId')) et inclus dans les vues de schéma des transformations en aval.
Contenu connexe
Dans l’article sur le langage d’expression de flux de données, vous trouverez des fonctionnalités supplémentaires pour les modèles de colonnes et la dérive de schéma, notamment « byName » et « byPosition ».
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour