Activité de flux de données dans Azure Data Factory et Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Utilisez l’activité de flux de données pour transformer et déplacer des données par le biais des flux de données de mappage. Si vous débutez avec les flux de données, consultez Vue d’ensemble des flux de données de mappage
Créer une activité de Flow de données avec l’interface utilisateur
Pour utiliser une activité Data Flow dans un pipeline, effectuez les étapes suivantes :
Recherchez Data Flow dans le volet Activités du pipeline, puis faites glisser une activité Data Flow vers le canevas du pipeline.
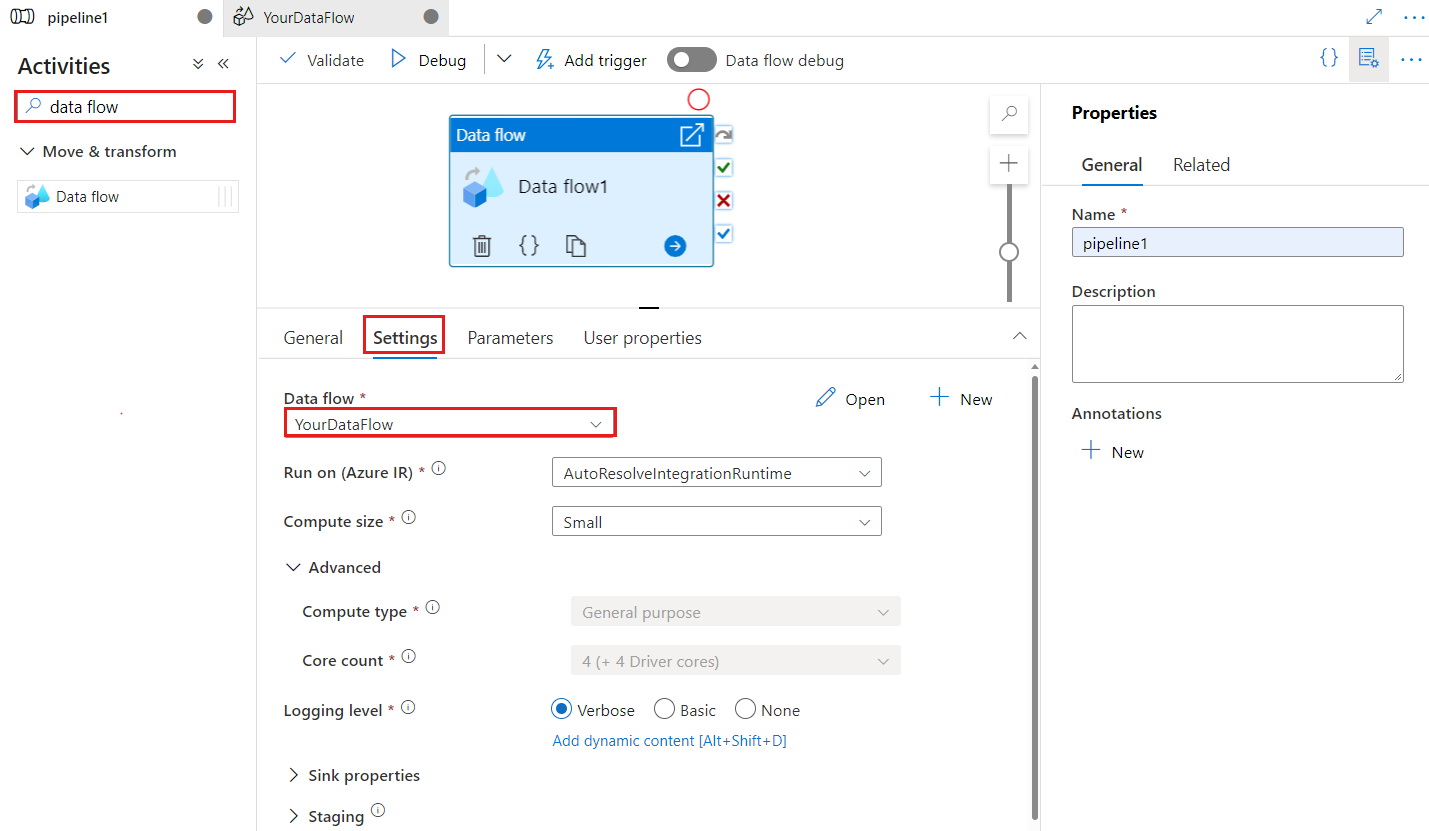
Sélectionnez la nouvelle activité Data Flow sur le canevas si elle ne l’est pas déjà, et son onglet Paramètres pour en modifier les détails.
La clé de point de contrôle est utilisée pour définir le point de contrôle lorsque le flux de données est utilisé pour la capture de données modifiées. Vous pouvez la remplacer. Les activités de flux de données utilisent une valeur GUID comme clé de point de contrôle au lieu de « nom_pipeline + nom_activité » afin de toujours pouvoir continuer à suivre l’état de capture des changements de données du client même en cas d’actions de renommage. Toutes les activités de flux de données existantes utilisent l’ancienne clé de modèle pour des raisons de compatibilité descendante. L’option de clé de point de contrôle après la publication d’une nouvelle activité de flux de données avec la ressource de flux de données activée pour la capture de données modifiées est indiquée ci-dessous.
Sélectionnez un flux de données existant ou créez-en un à l’aide du bouton nouveau. Sélectionnez d’autres options, si nécessaire, pour terminer votre configuration.
Syntaxe
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Propriétés type
| Propriété | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| dataflow | Référence au flux de données en cours d’exécution | DataFlowReference | Oui |
| integrationRuntime | L’environnement de calcul sur lequel le flux de données s’exécute. À défaut de spécification, le runtime d'intégration Azure à résolution automatique est utilisé. | IntegrationRuntimeReference | Non |
| compute.coreCount | Nombre de cœurs utilisés dans le cluster Spark. Ne peut être spécifié que si le runtime d’intégration Azure à résolution automatique est utilisé | 8, 16, 32, 48, 80, 144, 272 | Non |
| compute.computeType | Type de calcul utilisé dans le cluster Spark. Ne peut être spécifié que si le runtime d’intégration Azure à résolution automatique est utilisé | « Général » | Non |
| staging.linkedService | Si vous utilisez une source ou un récepteur Azure Synapse Analytics, spécifiez le compte de stockage utilisé pour la préproduction PolyBase. Si votre Stockage Azure est configuré avec un point de terminaison de service de type réseau virtuel, vous devez utiliser l’authentification par identité managée et activer « Autoriser le service Microsoft approuvé » sur le compte de stockage. Consultez Impact du recours à des points de terminaison de service de type réseau virtuel avec le Stockage Azure. Découvrez également les configurations nécessaires pour le Stockage Blob Azure et Azure Data Lake Storage Gen2. |
LinkedServiceReference | Uniquement si le flux de données lit ou écrit dans Azure Synapse Analytics |
| staging.folderPath | Si vous utilisez une source ou un récepteur Azure Synapse Analytics, chemin du dossier dans le compte de stockage blob utilisé pour la préproduction PolyBase | String | Uniquement si le flux de données lit ou écrit dans Azure Synapse Analytics |
| traceLevel | Définissez le niveau de journalisation de votre exécution d’activité de flux de données | Fine, grossière, aucune | Non |

Dimensionner dynamiquement le calcul du flux de données au moment de l’exécution
Les propriétés Nombre de cœurs et Type de capacité de calcul peuvent être définies de manière dynamique en fonction de la taille de vos données sources entrantes au moment de l’exécution. Utilisez des activités de pipeline telles que Recherche ou Obtention des métadonnées afin de déterminer la taille des données du jeu de données source. Ensuite, utilisez Ajouter du contenu dynamique dans les propriétés de l’activité Flux de données. Vous pouvez choisir de petites, moyennes ou grandes tailles de calcul. Si vous le souhaitez, sélectionnez « Personnalisé » et configurez manuellement les types de calcul et le nombre de cœurs.
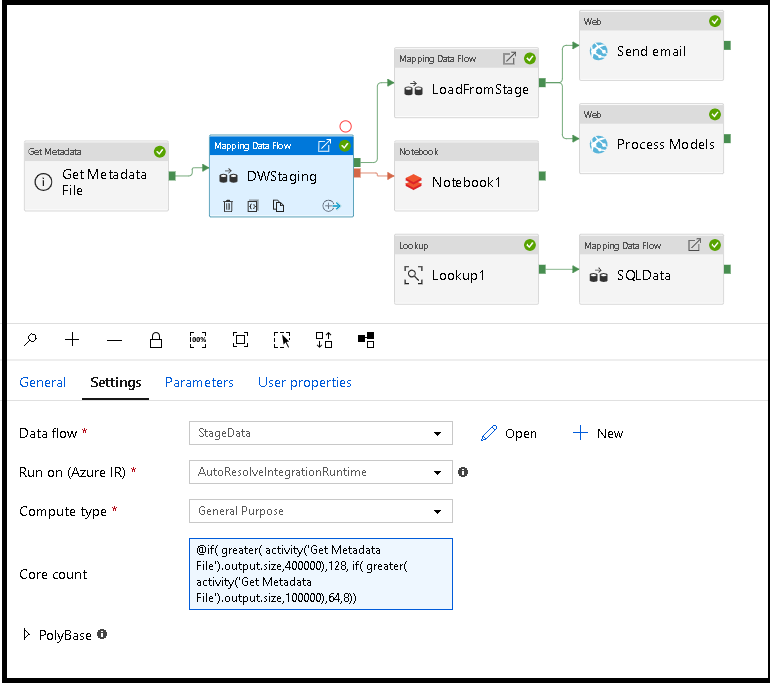
Voici un bref tutoriel vidéo expliquant cette technique
Runtime d’intégration de flux de données
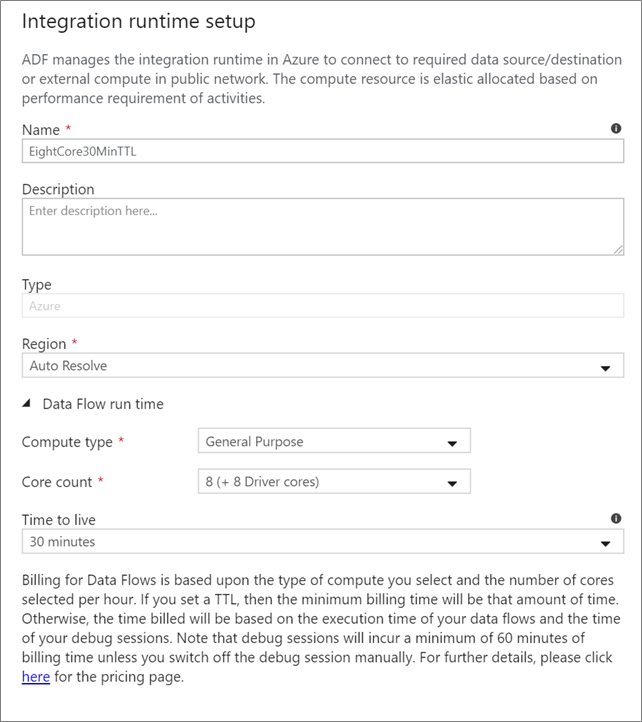
Choisissez le runtime d’intégration à utiliser pour l’exécution de votre activité de flux de données. Par défaut, le service utilise le runtime d’intégration Azure à résolution automatique avec quatre cœurs de worker. Ce runtime d’intégration a un type de calcul à usage général et s’exécute dans la même région que votre instance de service. Pour les pipelines opérationnalisés, il est fortement recommandé de créer vos propres runtimes d’intégration Azure, ce qui vous permet de définir des régions spécifiques, le type de calcul, le nombre de cœurs et de durée de vie de l’exécution de votre activité de flux de données.
Un type de calcul minimal Usage général avec une configuration 8 + 8 (16 cœurs au total) et une durée de vie (TTL) de dix minutes est la recommandation minimale pour la plupart des charges de travail de production. En définissant une courte durée de vie, Azure IR peut gérer un cluster à chaud sans entraîner un temps de démarrage de plusieurs minutes pour un cluster à froid. Pour plus d’informations, consultez Runtime d’intégration Azure.
Important
La sélection du runtime d’intégration dans l’activité de flux de données s’applique uniquement aux exécutions déclenchées de votre pipeline. Le débogage de votre pipeline avec des flux de données s’exécute sur le cluster spécifié dans la session de débogage.
PolyBase
Si vous utilisez Azure Synapse Analytics comme récepteur ou source, vous devez choisir un emplacement de préproduction pour le chargement par lots PolyBase. PolyBase permet d’effectuer des chargements par lots en bloc au lieu de charger les données ligne par ligne. PolyBase réduit considérablement le temps de chargement dans Azure Synapse Analytics.
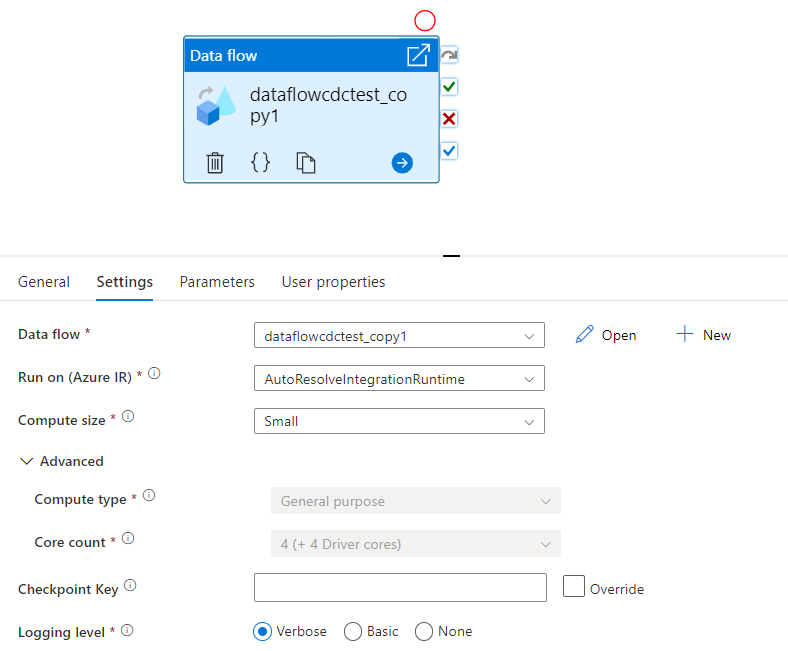
Clé de point de contrôle
Lorsque vous utilisez l’option de capture des modifications pour les sources de flux de données, ADF entretient et gère le point de contrôle automatiquement. La clé de point de contrôle par défaut est un hachage du nom du flux de données et du nom du pipeline. Si vous utilisez un modèle dynamique pour vos tables ou dossiers sources, vous souhaiterez peut-être remplacer ce hachage et définir votre propre valeur de clé de point de contrôle ici.
Niveau de journalisation
Si vous n’avez pas besoin que chaque exécution du pipeline de vos activités de flux de données journalise entièrement tous les journaux de télémétrie détaillés, vous pouvez définir le niveau de journalisation sur « De base » ou « Aucun ». Lors de l’exécution de vos flux de données en mode « Verbose » (par défaut), vous demandez au service de journaliser entièrement l’activité à chaque niveau de partition individuel au cours de la transformation des données. Cela peut être une opération coûteuse. Par conséquent, n’activez l’option Verbose que lorsque la résolution des problèmes peut améliorer les performances globales du pipeline et du flux de données. Le mode « De base » ne consigne que les durées de transformation, tandis que le mode « Aucun » ne fournit qu’un résumé des durées.

Propriétés du récepteur
La fonctionnalité de regroupement dans le flux de données vous permet de configurer l’ordre d’exécution de vos récepteurs et de regrouper les récepteurs ensemble sous le même numéro de groupe. Pour faciliter la gestion des groupes, vous pouvez demander au service d’exécuter des récepteurs, dans le même groupe, en parallèle. Vous pouvez également faire en sorte que le groupe récepteur continue même après que l’un des récepteurs a rencontré une erreur.
Le comportement par défaut des récepteurs de flux de données consiste à exécuter chaque récepteur de manière séquentielle, en série, et à faire échouer le flux de données quand une erreur est détectée dans le récepteur. En outre, tous les récepteurs sont définis par défaut dans le même groupe, sauf si vous accédez aux propriétés du flux de données et définissez des priorités différentes pour les récepteurs.

Première ligne uniquement
Cette option n'est disponible que pour les flux de données dont les récepteurs de cache sont activés pour la « Sortie vers l'activité ». La sortie du flux de données qui est injectée directement dans votre pipeline est limitée à 2 Mo. Le paramètre « Première ligne uniquement » vous permet de limiter la sortie de données du flux de données lorsque vous injectez la sortie de l'activité de flux de données directement dans votre pipeline.
Paramétrage de flux de données
Jeux de données paramétrables
Si votre flux de données utilise des jeux de données paramétrables, définissez les valeurs de paramètre sous l’onglet Paramètres.
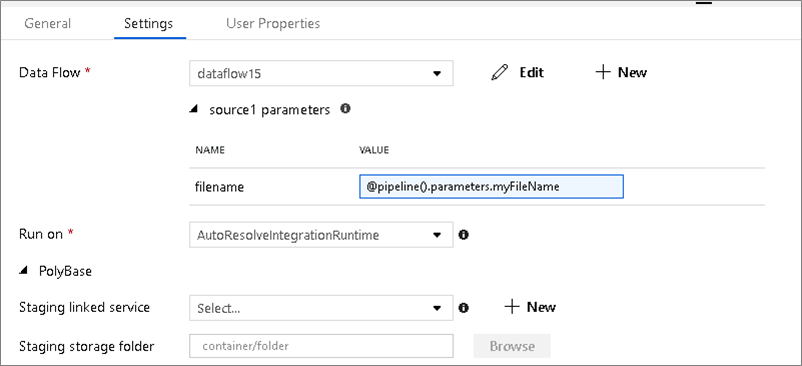
Flux de données paramétrables
Si votre flux de données est paramétré, définissez les valeurs dynamiques des paramètres de flux de données sous l’onglet Paramètres. Vous pouvez utiliser le langage d’expression de pipeline ou le langage d’expression de flux de données pour assigner des valeurs de paramètres dynamiques ou littérales. Pour plus d’informations, consultez Paramètres de flux de données.
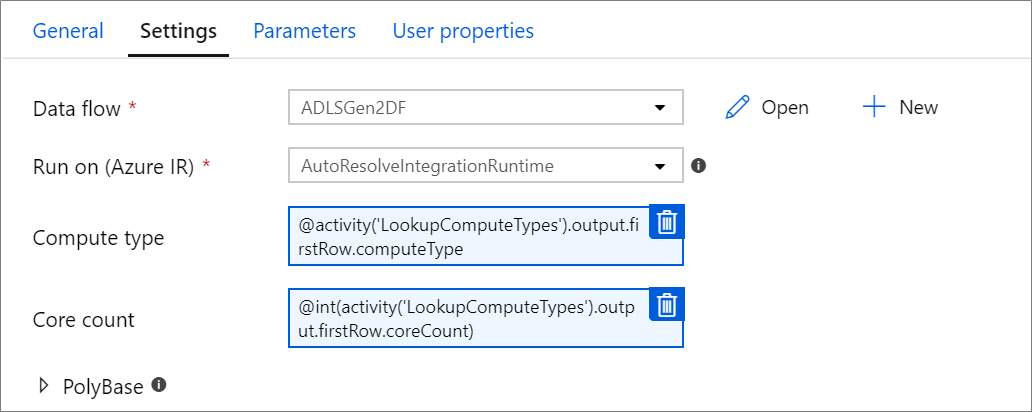
Propriétés de calcul paramétrables.
Vous pouvez paramétriser le nombre de cœurs ou le type de calcul si vous utilisez le runtime d'intégration Azure à résolution automatique et spécifiez des valeurs pour compute.coreCount et compute.computeType.
Débogage de pipeline de l’activité de flux de données
Pour effectuer une exécution de débogage de pipeline à l’aide d’une activité de flux de données, vous devez passer en mode de débogage de flux de données à l’aide du curseur Débogage de flux de données dans la barre supérieure. Le mode débogage vous permet d’exécuter le flux de données sur un cluster Spark actif. Pour plus d’informations, consultez Mode de débogage.

Le pipeline de débogage s’exécute sur le cluster de débogage actif, et non sur l’environnement de runtime d’intégration spécifié dans les paramètres d’activité de flux de données. Vous pouvez choisir l’environnement de calcul de débogage lors du démarrage du mode de débogage.
Supervision de l’activité de flux de données
L’activité de flux de données offre une expérience de supervision spéciale dans laquelle vous pouvez voir des informations relatives au partitionnement, au temps de phase et à la traçabilité des données. Ouvrez le volet de supervision à l’aide de l’icône de lunettes sous Actions. Pour plus d’informations, consultez Supervision des flux de données.
Utiliser des résultats d’activité de flux de données dans une activité postérieure
L’activité de flux de données génère des métriques sur le nombre de lignes écrites dans chaque récepteur et le nombre de lignes lues à partir de chaque source. Ces résultats sont retournés dans la section output du résultat de l’exécution d’activité. Les métriques retournées sont au format du fichier json ci-dessous.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Par exemple, pour obtenir le nombre de lignes écrites dans un récepteur nommé « sink1 » dans une activité nommée « dataflowActivity », utilisez @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Pour obtenir le nombre de lignes lues à partir d’une source nommée « source1 » qui a été utilisée dans ce récepteur, utilisez @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Notes
Si un récepteur n’a aucune ligne écrite, il n’apparaît pas dans les métriques. Son existence peut être vérifiée à l’aide de la fonction contains. Par exemple, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') vérifie si des lignes ont été écrites dans sink1.
Contenu connexe
Consultez des activités de flux de contrôle prises en charge :
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour