Transformation de modification de ligne dans le flux de données de mappage
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
Utiliser la transformation de Alter Row pour définir des stratégies insert, delete, update et upsert sur les lignes. Vous pouvez ajouter des conditions de type un-à-plusieurs en tant qu’expressions. Ces conditions doivent être spécifiées par ordre de priorité, car chaque ligne est marquée avec la stratégie liée à la première expression correspondante. Chacune de ces conditions peut entraîner l'insertion, la mise à jour, la suppression ou l'upsert d'une ligne (ou de plusieurs lignes). Alter Row peut produire des actions DDL et DML sur votre base de données.

Les transformations Alter Row ne fonctionnent que sur les récepteurs de base de données, REST ou Azure Cosmos DB de votre flux de données. Les actions que vous affectez aux lignes (insertion, mise à jour, suppression ou upsert) n’ont pas lieu au cours des sessions de débogage. Pour activer les stratégies de modification de ligne sur vos tables de base de données, exécutez une activité Exécuter un flux de données dans un pipeline.
Remarque
Une transformation de modification de ligne (Alter Row) n’est pas nécessaire pour les flux de données de capture des changements de données qui utilisent des sources CDC natives comme SQL Server ou SAP. Dans ces cas, ADF détecte automatiquement le marqueur de ligne de sorte que les stratégies Alter Row sont inutiles.
Spécifier une stratégie de ligne par défaut
Créez une transformation Alter Row et spécifiez une stratégie de ligne associée à la condition true(). Chaque ligne qui ne correspond à aucune des expressions définies précédemment est marquée pour la stratégie de ligne spécifiée. Par défaut, chaque ligne qui ne correspond à aucune expression conditionnelle est marquée pour Insert.

Notes
Pour associer une stratégie à toutes les lignes, vous pouvez créer une condition pour cette stratégie et spécifier la condition comme true().
Afficher les stratégies dans l’aperçu des données
Utilisez le mode de débogage pour afficher les résultats de vos stratégies de modification de ligne dans le volet d’aperçu des données. Un aperçu des données d’une transformation de modification de ligne ne génère pas d’actions DDL ni DML sur votre cible.

Une icône pour chaque stratégie de modification de ligne indique si une action d’insertion, de mise à jour, d’upsert ou de suppression se produit. L’en-tête supérieur indique le nombre de lignes que chaque stratégie affecte dans l’aperçu.
Autoriser les stratégies de modification de ligne dans le récepteur
Pour que les stratégies de modification de ligne fonctionnent, le flux de données doit écrire dans une base de données ou un récepteur Azure Cosmos DB. Dans l’onglet Paramètres de votre récepteur, activez les stratégies de modification de ligne autorisées pour ce récepteur.
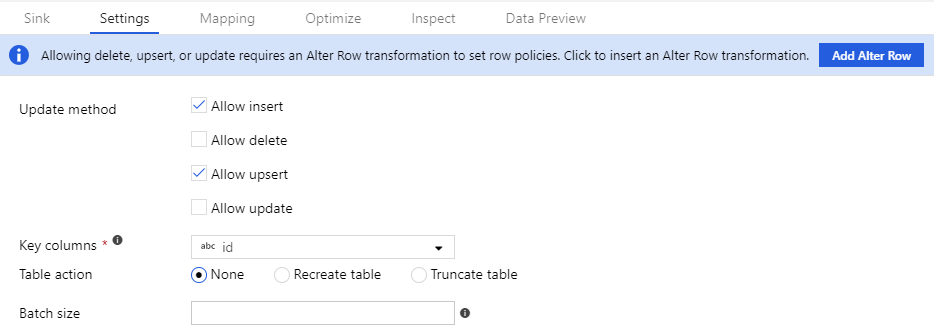
Le comportement par défaut est d’autoriser uniquement les insertions. Pour autoriser les mises à jour, les opérations upsert ou les suppressions, cochez la case dans le récepteur correspondant à cette condition. Si les mises à jour, les opérations upsert ou les suppressions sont activées, vous devez spécifier les colonnes clés du récepteur sur lesquelles effectuer la correspondance.
Notes
Si vos insertions, mises à jour ou opérations upsert modifient le schéma de la table cible du récepteur, le flux de données échoue. Pour modifier le schéma cible dans votre base de données, choisissez Recréer la table en tant qu’action de table. Cela supprime et recrée votre table selon la nouvelle définition de schéma.
La transformation du récepteur requiert une clé unique ou une série de clés pour l’identification de ligne unique dans votre base de données cible. Pour les récepteurs SQL, définissez les clés sous l’onglet Paramètres du récepteur. Pour Azure Cosmos DB, définissez la clé de partition dans les paramètres et définissez également le champ système Azure Cosmos DB « ID » dans votre mappage de récepteur. Pour Azure Cosmos DB, il est obligatoire d’inclure la colonne système « ID » pour les mises à jour, les upserts et les suppressions.
Fusionne et fait un upsert avec Azure SQL Database et Azure Synapse
Les Data Flows prennent en charge les fusions par rapport au pool de base de données Azure SQL Database et Azure Synapse (base de données de l’entrepôt de données) avec l’option upsert.
Toutefois, vous pouvez rencontrer des scénarios dans lesquels votre schéma de base de données cible utilisait la propriété d’identité des colonnes clés. Le service vous oblige à identifier les clés que vous utilisez pour faire correspondre les valeurs de ligne des mises à jour et des upserts. Toutefois, si la propriété d’identité est définie pour la colonne cible et que vous utilisez la stratégie upsert, la base de données cible ne vous autorise pas à écrire dans la colonne. Vous pouvez également rencontrer des erreurs lorsque vous essayez d’utiliser une opération upsert par rapport à la colonne de distribution d’une table distribuée.
Voici comment résoudre ce problème :
Accédez aux paramètres de transformation du récepteur et définissez « Ignorer l’écriture des colonnes clés ». Cela indique au service de ne pas écrire la colonne que vous avez sélectionnée comme valeur de clé pour votre mappage.
Si cette colonne clé n’est pas la colonne qui est à l’origine du problème pour les colonnes d’identité, vous pouvez utiliser l’option SQL de prétraitement de transformation du récepteur :
SET IDENTITY_INSERT tbl_content ON. Ensuite, désactivez-la à l’aide de la propriété SQL postérieure au traitement :SET IDENTITY_INSERT tbl_content OFF.Pour le cas d’identité et le cas de colonne de distribution, vous pouvez passer de la logique de l’opération upsert à l’utilisation d’une condition de mise à jour distincte et d’une condition d’insertion distincte à l’aide d’une transformation de fractionnement conditionnel. De cette façon, vous pouvez définir le mappage sur le chemin d’accès de la mise à jour pour ignorer le mappage de la colonne clé.
Script de flux de données
Syntaxe
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
Exemple
L’exemple ci-dessous est une transformation de modification de ligne nommée CleanData qui prend un flux entrant SpecifyUpsertConditions et crée trois conditions de modification de ligne. Dans la transformation précédente, une colonne nommée alterRowCondition est calculée pour déterminer si une ligne est ou n’est pas insérée, mise à jour ou supprimée dans la base de données. Si la valeur de la colonne a une valeur de chaîne qui correspond à la règle de modification de ligne, cette stratégie lui est affectée.
Dans l’IU, cette transformation se présente comme dans l’image ci-dessous :
Le script de flux de données pour cette transformation se trouve dans l’extrait de code ci-dessous :
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
Contenu connexe
Une fois la transformation Alter Row effectuée, vous souhaiterez peut-être transférer vos données vers un magasin de données de destination.