Opérations de gestion dans Azure Managed Instance pour Apache Cassandra
Azure Managed Instance pour Apache Cassandra est un service complètement managé pour les clusters Apache Cassandra open source purs. Le service permet également de remplacer des configurations, en fonction des besoins spécifiques de chaque charge de travail, ce qui permet une flexibilité et un contrôle optimaux, le cas échéant. Cet article définit les opérations et les fonctionnalités de gestion fournies par le service. Elle explique également la séparation des responsabilités entre l’équipe de support Azure et les clients lors de la gestion de clusters hybrides.
Compactage
- Il existe différents types de compactage. Nous effectuons actuellement un compactage mineur par réparation (voir Maintenance). Effectue un compactage de l’arborescence Merkle, qui est un type spécial de compactage.
- Selon la stratégie de compactage définie sur la table à l’aide de CQL (par exemple
WITH compaction = { 'class' : 'LeveledCompactionStrategy' }), Cassandra se compacte automatiquement lorsque la table atteint une taille spécifique. Nous vous recommandons de sélectionner soigneusement une stratégie de compactage pour votre charge de travail et de ne pas effectuer de compactages manuels en dehors de la stratégie.
Application de correctifs
Les correctifs au niveau du système d’exploitation sont effectués automatiquement à une cadence de 2 semaines environ.
Les correctifs de niveau logiciel Apache Cassandra sont effectués lorsque des failles de sécurité sont identifiées. La cadence des correctifs peut varier.
Lors de la mise à jour corrective, les machines sont redémarrées dans un rack à la fois. Vous ne devriez pas rencontrer de dégradation au niveau de l’application tant que le paramètre quorum ALL n’est pas utilisé, et que le facteur de réplication est supérieur ou égal à 3.
La version dans Apache Cassandra est au format
X.Y.Z. Vous pouvez contrôler le déploiement des versions majeures (X) et mineures (Y) manuellement via les outils de service. Tandis que les correctifs Cassandra (Z) qui peuvent être nécessaires pour cette combinaison de version majeure/mineure sont effectués automatiquement.
Notes
Le service prend actuellement en charge Cassandra versions 3.11 et 4.0. Les deux versions sont en disponibilité générale. Consultez notre Guide de démarrage rapide Azure CLI (étape 5) pour spécifier la version de Cassandra pendant le déploiement du cluster.
Maintenance
La réparation Nodetool est exécutée automatiquement par le service à l’aide du réparer. Cet outil est exécuté une fois par semaine. Vous souhaiterez peut-être la désactiver si vous utilisez votre propre service pour un déploiement hybride.
La surveillance de l’intégrité des nœuds se compose des éléments suivants :
- Surveillance active de l’appartenance de chaque nœud à l’anneau Cassandra.
- La détection et l’atténuation automatiques des problèmes d’infrastructure telle que les machines virtuelles, le réseau, le stockage, Linux et la prise en charge des défaillances logicielles.
- Surveillance proactive des problèmes d’UC, de disque, de perte de quorum et d’autres problèmes de ressources.
- Affichage automatique des nœuds ayant échoué dans la cas où cela est possible, et affichage manuel des nœuds en réponse aux avertissements générés automatiquement.
Support
Azure Managed Instance pour Apache Cassandra fournit un contrat SLA pour la disponibilité des centres de données dans un cluster managé. Si vous rencontrez des problèmes lors de l’utilisation du service, effectuez unedemande de support dans le portail Azure.
Nos avantages de support sont les suivants :
- Point de contact unique pour les problèmes d’infrastructure Cassandra : il n’est pas nécessaire de déclencher des cas de support avec des équipes IaaS (disque, calcul, mise en réseau) séparément.
- Conseils pro-actifs par e-mail sur les goulots de bouteille de performance, le dimensionnement et d’autres problèmes de contrainte de ressources.
- Prise en charge 24 h/24 et 7 j/7, y compris les incidents générés automatiquement pour les pannes graves.
- Prise en charge des correctifs approuvés par la communauté (voir Mise à jour corrective).
- Prise en charge de l’équipe d’ingénierie Java JDK/JVM interne.
- Prise en charge du système d’exploitation Linux avec la sécurité de la chaîne logistique logicielle.
Important
Nous tenterons d’investiguer et de diagnostiquer tous les problèmes signalés dans la demande de support, puis de les résoudre ou de les atténuer si cela est possible. Notez toutefois que vous avez la responsabilité finale de toute configuration Apache Cassandra susceptible d’entraîner des problèmes de processeur, de disque ou de réseau.
Voici quelques exemples de ces problèmes :
- Opérations de requête inefficaces.
- Débit qui dépasse la capacité.
- Réception des données qui dépassent la capacité de stockage.
- Paramètres de configuration de l’espace de réponse incorrects.
- Stratégie de modèle de données ou de clé de partition médiocre.
Dans le cas où nous examinons un cas de support et découvrons que la cause racine du problème est au niveau de la configuration Apache Cassandra (et non aucun aspect de niveau de plateforme sous-jacent que nous maintenons), nous fournirons toujours des recommandations et des conseils sur la correction ou l’atténuation (dans la mesure du possible), avant de fermer le cas.
Nous vous recommandons d’activer les métriques et/ou de vous familiariser avec l’intégration Azure Monitor afin d’éviter les problèmes courants liés à la configuration ou à l’application dans Apache Cassandra, tels que ceux ci-dessus.
Avertissement
Azure Managed Instance pour Apache Cassandra vous permet également d’exécuter des commandes nodetool et sstable pour l’administration DBA de routine. Voir l’article ici. Certaines de ces commandes peuvent déstabiliser le cluster Cassandra et ne doivent être exécutées qu’avec précaution et après avoir été testées dans des environnements hors production. Dans la mesure du possible, une option --dry-run doit être déployée en premier. Microsoft ne peut proposer aucun Contrat de niveau de service ni support pour les problèmes liés à l’exécution de commandes qui modifient la configuration ou les tables de la base de données par défaut.
Sauvegarde et restauration
Les sauvegardes d’instantanés sont activées par défaut et effectuées toutes les 24 heures. Les sauvegardes sont stockées dans un compte de stockage Blob Azure interne et sont conservées pendant 2 jours (48 heures). Les 2 premières sauvegardes sont gratuites. Les sauvegardes supplémentaires sont facturées, consultez la tarification. Pour modifier l’intervalle de sauvegarde ou la période de rétention, vous pouvez modifier la stratégie dans le portail :

Pour effectuer une restauration à partir d’une sauvegarde existante, effectuez une demande de support dans le portail Azure. Lorsque vous déposez le cas de support, vous devez :
Indiquer l’ID de sauvegarde à partir du portail pour la sauvegarde que vous souhaitez restaurer. Vous la trouverez dans le portail :
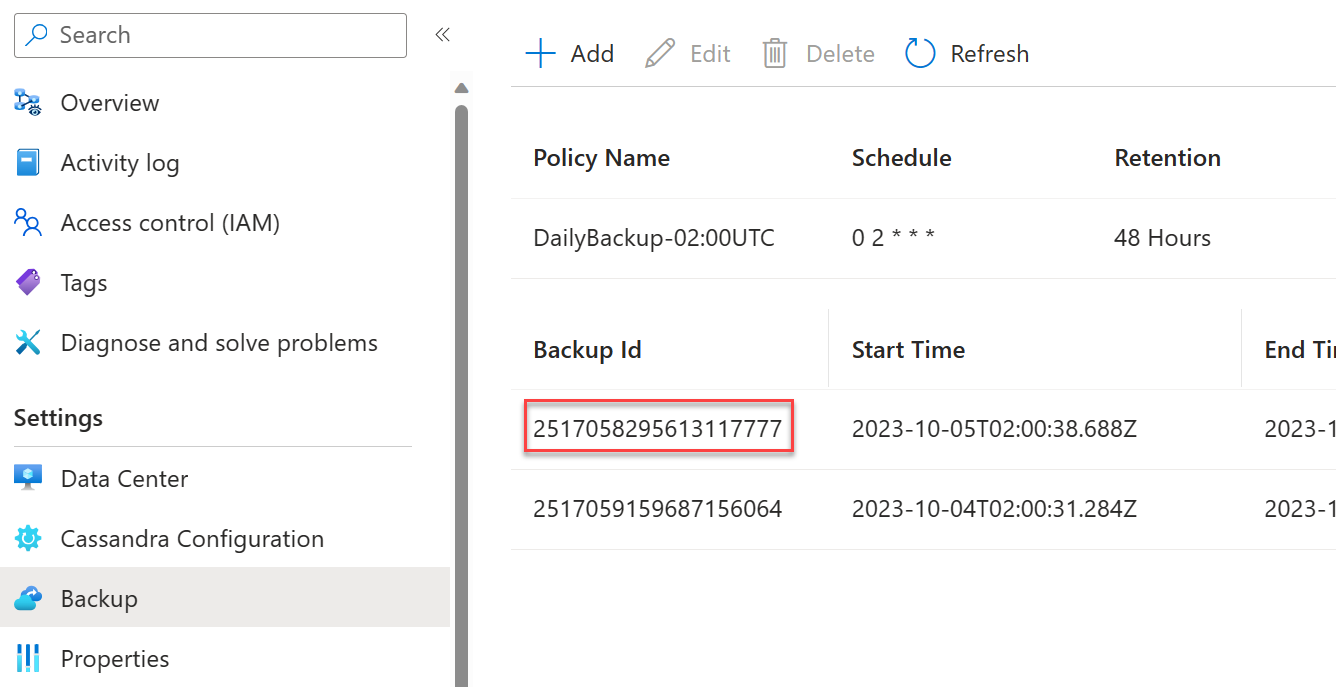
Si la restauration de l’ensemble du cluster n’est pas nécessaire, fournissez l’espace de clés et la table (le cas échéant) qui doivent être restaurés.
Indiquez si vous souhaitez restaurer la sauvegarde dans le cluster existant ou dans un nouveau cluster.
Si vous souhaitez restaurer sur un nouveau cluster, vous devez d’abord créer ce cluster. Vérifiez que le cluster cible correspond au cluster source en termes de nombre de centres de données et que le centre de données correspondant possède le même nombre de nœuds. Vous pouvez également décider de conserver les informations d’identification (nom d’utilisateur/mot de passe) dans le nouveau cluster cible ou d’autoriser la restauration à remplacer le nom d’utilisateur/mot de passe par ce qui a été créé à l’origine.
Vous pouvez également décider s’il faut conserver l’espace de clés
system_authdans le nouveau cluster cible ou autoriser la restauration à le remplacer par les données de la sauvegarde. L’espace de cléssystem_authdans Cassandra contient des données d’autorisation et d’authentification interne, notamment des rôles, des autorisations de rôle et des mots de passe. Notez que notre processus de restauration par défaut remplace l’espace de cléssystem_auth.

Remarque
Le temps nécessaire pour répondre à une demande de restauration à partir de la sauvegarde dépend à la fois de la gravité du cas de support que vous soumettez (et du contrat SLA correspondant pour le temps de réponse) et de la quantité de données à restaurer. Toutefois, nous ne fournissons pas de contrat SLA pour le temps nécessaire à la restauration, car cela dépend substantiellement du volume de données en cours de restauration.
Avertissement
Les sauvegardes sont destinées aux scénarios de suppression accidentelle et ne sont pas géoredondantes. Par conséquent, il n’est pas recommandé de les utiliser comme stratégie de récupération d’urgence (DR) en cas de panne régionale totale. Pour vous protéger en cas de pannes régionales, nous vous recommandons d’effectuer un déploiement multirégion. Consultez le guide de démarrage rapide concernant les déploiements multirégions.
Sécurité
Azure Managed Instance pour Apache Cassandra fournit de nombreux contrôles et fonctionnalités de sécurité explicites intégrés :
- Images de machines virtuelles Linux renforcées avec une chaîne d’approvisionnement contrôlée.
- Surveillance des vulnérabilités courantes & exposition (CVE) au niveau du système d’exploitation.
- La rotation des certificats pour les logiciels Apache Cassandra et Prometheus hébergés sur les machines virtuelles gérées.
- Analyse active des vulnérabilités.
- Analyse antivirus active.
- Pratiques de codage sécurisées.
Pour plus d’informations sur les fonctionnalités de sécurité, consultez notre article ici.
Support hybride
Lorsqu’un cluster hybride est configuré, les opérations de reaper automatisées qui s’exécutent dans le service bénéficient à l’ensemble du cluster. Cela comprend les centres de données qui ne sont pas approvisionnés par le service. En dehors de cela, il vous incombe de gérer votre centre de données local ou hébergé en externe.
Étapes suivantes
Démarrez avec l’un de nos guides de démarrage rapide :
Commentaires
Bientôt disponible : pendant toute l’année 2024, nous allons éliminer progressivement Problèmes GitHub comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, voir : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour