Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Azure Queue Storage est un service permettant de stocker et de distribuer un grand nombre de messages. Le Stockage File d’attente est couramment utilisé pour créer un backlog de travail à traiter de manière asynchrone. Il fournit une remise de messages fiable pour les architectures d’application faiblement couplées. La taille d’un message de file d’attente peut atteindre 64 Ko, et une file d’attente peut contenir des millions de messages, jusqu’à la limite totale de capacité d’un compte de stockage.
Lorsque vous utilisez Azure, la fiabilité est une responsabilité partagée. Microsoft fournit une gamme de fonctionnalités pour prendre en charge la résilience et la récupération. Vous êtes responsable de comprendre le fonctionnement de ces fonctionnalités dans tous les services que vous utilisez et de sélectionner les fonctionnalités dont vous avez besoin pour atteindre vos objectifs métier et vos objectifs de temps d’activité.
Cet article explique comment rendre le stockage de files d'attente résilient face à diverses pannes et problèmes potentiels, notamment les défaillances transitoires, les interruptions de zone de disponibilité et les interruptions régionales. Il décrit également comment utiliser des sauvegardes pour récupérer d’autres types de problèmes et met en évidence certaines informations clés sur l’accord de niveau de service pour le stockage de files d’attente (SLA).
Note
Le Stockage File d’attente fait partie de la plateforme Stockage Azure. Certaines des fonctionnalités du Stockage File d’attente sont partagées par de nombreux services de Stockage Azure.
Recommandations de déploiement de production pour la fiabilité
Pour les environnements de production :
Activez le stockage redondant interzone (ZRS) pour les comptes de stockage qui contiennent des ressources de Stockage File d’attente. Le ZRS offre une plus grande disponibilité en répliquant vos données de manière synchrone sur plusieurs zones de disponibilité dans la région principale. Une disponibilité plus élevée permet de protéger vos comptes de stockage contre les défaillances de zone de disponibilité.
Si vous avez besoin d’une résilience aux pannes régionales et que la région principale de votre compte de stockage est jumelée, envisagez d’activer le stockage géo-redondant (GRS). Le GRS réplique les données de manière asynchrone dans la région jumelée. Dans les régions prises en charge, vous pouvez combiner la géo-redondance avec la redondance de zone en utilisant le stockage géoredondant interzone (GZRS).
Pour les exigences de messagerie avancées, envisagez d’utiliser Azure Service Bus. Pour en savoir plus sur les différences entre le Stockage File d’attente et Service Bus, consultez Comparer les files d’attente Stockage Azure et les files d’attente Service Bus.
Vue d’ensemble de l’architecture de fiabilité
Le Stockage File d’attente fonctionne en tant que service de messagerie distribué au sein de l’infrastructure de la plateforme Stockage Azure. Le service fournit une redondance via plusieurs copies de vos données de file d’attente et de message. Le modèle de redondance spécifique dépend de la configuration de votre compte de stockage.
Le stockage localement redondant (LRS) réplique les données de vos comptes de stockage vers une ou plusieurs zones de disponibilité Azure situées dans la région principale de votre choix. Bien qu’il n’existe aucune option permettant de choisir votre zone de disponibilité préférée, Azure peut déplacer ou développer des comptes LRS entre les zones pour améliorer l’équilibrage de charge. Il n’existe aucune garantie que vos données seront réparties entre les zones. Pour plus d’informations sur les zones de disponibilité, consultez Que sont les zones de disponibilité ?.

Le stockage redondant interzone (ZRS), le stockage géo-redondant (GRS) et le stockage géo-redondant interzone (GZRS) offrent des protections supplémentaires. Cet article décrit ces options en détail.
Résilience aux erreurs temporaires
Les erreurs temporaires sont des défaillances courtes et intermittentes dans les composants. Elles se produisent fréquemment dans un environnement distribué comme le cloud, et font partie intégrante des opérations ordinaires. Les erreurs temporaires se corrigent après une courte période de temps. Il est important que vos applications puissent gérer les erreurs temporaires, généralement en réessayant les requêtes affectées.
Toutes les applications hébergées dans le cloud doivent suivre les instructions de gestion des erreurs temporaires Azure lorsqu’elles communiquent avec toutes les API, bases de données et autres composants hébergés dans le cloud. Pour plus d’informations, consultez Recommandations pour la gestion des erreurs temporaires.
Le Stockage File d’attente est couramment utilisé dans les applications, pour les aider à gérer les erreurs temporaires dans d’autres composants. En utilisant la messagerie asynchrone avec un service tel que le Stockage File d’attente, les applications peuvent récupérer d’erreurs temporaires en retraitant les messages ultérieurement. Pour plus d’informations, consultez l’aperçu de la messagerie asynchrone.
Dans le service lui-même, le Stockage File d’attente gère automatiquement les erreurs temporaires à l’aide de plusieurs mécanismes fournis par la plateforme Stockage Azure et les bibliothèques clientes. Le service est conçu pour fournir des fonctionnalités de mise en file d’attente de messages résilientes, même pendant les problèmes d’infrastructure temporaires.
Les bibliothèques clientes de Stockage File d’attente incluent des stratégies de nouvelle tentative intégrées qui gèrent automatiquement les défaillances temporaires courantes telles que les délais d’expiration du réseau, l’indisponibilité temporaire du service (HTTP 503) et les réponses de limitation (HTTP 429). Lorsque votre application rencontre ces conditions temporaires, les bibliothèques clientes réessayent automatiquement les opérations à l’aide de stratégies de backoff exponentiel.
Pour gérer efficacement les erreurs temporaires à l’aide du Stockage File d’attente, vous pouvez effectuer les actions suivantes :
Configurez les délais d’expiration appropriés dans votre client stockage file d’attente pour équilibrer la réactivité avec la résilience aux ralentissements temporaires. Les délais d’expiration par défaut dans les bibliothèques clientes stockage Azure conviennent généralement à la plupart des scénarios.
Implémenter des modèles disjoncteur dans votre application lorsqu’elle traite les messages à partir de files d’attente. Les modèles de circuit disjoncteur empêchent les défaillances en cascade lorsque les services en aval éprouvent des problèmes.
Utiliser des délais d’expiration de visibilité appropriés lorsque votre application reçoit des messages. Les délais d’expiration de visibilité garantissent que les messages deviennent disponibles pour une nouvelle tentative si votre application rencontre des échecs pendant le traitement.
Pour en savoir plus sur l’architecture de stockage Table Azure et sur la conception d’applications résilientes et à grande échelle, consultez la liste de contrôle des performances et de la scalabilité pour le Stockage de files d’attente.
Résilience aux échecs de zone de disponibilité
Les zones de disponibilité sont des groupes physiquement distincts de centres de données au sein d’une région Azure. Lorsqu'une zone tombe en panne, les services peuvent basculer vers l'une des zones restantes.
Le stockage file d’attente Azure est redondant interzone lorsqu’il est déployé avec la configuration ZRS. Contrairement à LRS, ZRS garantit qu’Azure réplique de façon synchrone vos données de file d’attente dans plusieurs zones de disponibilité. ZRS garantit que vos données restent accessibles même si une zone subit une panne. ZRS garantit que vos files d’attente restent accessibles même si une zone de disponibilité entière devient indisponible. Toutes les opérations d’écriture doivent être reconnues sur plusieurs zones avant qu’elles ne soient terminées, ce qui offre des garanties de cohérence forte.
La redondance de zone est activée au niveau du compte de stockage et s’applique à toutes les ressources de stockage file d’attente au sein de ce compte. Vous ne pouvez pas configurer de files d’attente individuelles pour différents niveaux de redondance. Le paramètre s’applique à l’ensemble du compte de stockage. Lorsqu’une zone de disponibilité rencontre une panne, le stockage Azure achemine automatiquement les requêtes vers des zones saines sans nécessiter d’intervention de votre application.

Requirements
- Prise en charge de la région : Vous pouvez déployer des comptes de stockage Azure redondants interzone dans n’importe quelle région prenant en charge les zones de disponibilité.
- Types de comptes de stockage : Vous devez utiliser un compte de stockage v2 standard pour activer ZRS pour le stockage file d’attente. Les comptes de stockage Premium ne prennent pas en charge le Stockage File d’attente.
Cost
Lorsque vous activez le stockage redondant interzone (ZRS), vous êtes facturé à un taux différent de celui du stockage localement redondant (LRS) en raison de la surcharge supplémentaire de réplication et de stockage.
Pour obtenir des informations détaillées sur la tarification, consultez Tarification du stockage File d’attente.
Configurez la prise en charge des zones de disponibilité
Créer un compte de stockage redondant interzone et une file d’attente en effectuant les étapes suivantes.
Créer un compte de stockage et sélectionnez ZRS, GZRS ou stockage géoredondant interzone avec accès en lecture (RA-GZRS) comme option de redondance lors de la création du compte.
Modifier le type de réplication. Pour savoir comment transformer un compte de stockage existant en stockage redondant interzone (ZRS) et connaître les options de configuration et les exigences, consultez Modifier la méthode de réplication d’un compte de stockage.
Désactivez la redondance de zone. Réaffectez les comptes ZRS à une configuration non-zonale, telle que le stockage localement redondant (LRS), à l’aide du même processus de modification de configuration de redondance.
Comportement lorsque toutes les zones sont saines
Cette section décrit ce qu’il faut attendre lorsqu’un compte de stockage de file d’attente est configuré pour la redondance de zone et que toutes les zones de disponibilité sont opérationnelles.
Routage du trafic entre les zones : le Stockage Azure avec stockage redondant interzone (ZRS) distribue automatiquement les requêtes entre les clusters de stockage dans plusieurs zones de disponibilité. La distribution du trafic est transparente pour les applications et ne nécessite aucune configuration côté client.
Réplication des données entre les zones : toutes les opérations d’écriture dans le ZRS sont répliquées de manière synchrone dans toutes les zones de disponibilité au sein de la région. Lorsque vous chargez ou modifiez des données, l’opération n’est pas considérée comme terminée tant que les données n’ont pas été répliquées sur toutes les zones de disponibilité. Cette réplication synchrone garantit une cohérence forte et une perte de données nulle pendant les défaillances de zone.
Comportement lors d’une défaillance de zone
Lorsqu’une zone de disponibilité devient indisponible, le Stockage File d’attente gère automatiquement le processus de basculement en effectuant les actions suivantes.
Détection et réponse : Microsoft détecte automatiquement les défaillances de zone et lance les processus de récupération. Aucune action du client n’est requise pour les comptes de stockage redondant interzone (ZRS).
Si une zone devient indisponible, Azure procède à des mises à jour du réseau, telles que le repointage DNS (Domain Name Service).
- Notification : Microsoft ne vous avertit pas automatiquement lorsqu’une zone est en panne. Toutefois, vous pouvez utiliser Azure Resource Health pour surveiller l’intégrité d’une ressource individuelle, et vous pouvez configurer des alertes Resource Health pour vous avertir des problèmes. Vous pouvez également utiliser Azure Service Health pour comprendre l’intégrité globale du service, y compris les défaillances de zone, et vous pouvez configurer des alertes Service Health pour vous avertir des problèmes.
Demandes actives : les demandes en cours peuvent être supprimées pendant le processus de récupération et doivent être retentées. Les applications doivent implémenter une logique de nouvelle tentative pour gérer ces interruptions temporaires.
Perte de données attendue : Aucune perte de données ne se produit pendant les échecs de zone, car les données sont répliquées de manière synchrone sur plusieurs zones avant la fin des opérations d’écriture.
Temps d’arrêt attendu : Un temps d’arrêt peu important, généralement quelques secondes, peut se produire pendant la récupération automatique, car le trafic est redirigé vers des zones saines. Lorsque vous concevez des applications pour le ZRS, suivez les pratiques de gestion des erreurs temporaires, notamment l’implémentation de stratégies de nouvelle tentative avec temporisation exponentielle.
- Réacheminement du trafic. Si une zone devient indisponible, Azure effectue des mises à jour réseau telles que le repointage DNS (Domain Name System), afin que les demandes soient dirigées vers les zones de disponibilité saines restantes. Le service maintient toutes les fonctionnalités en utilisant les zones restantes sans intervention requise du client.
Récupération de la zone
Lorsque la zone de disponibilité ayant échoué est récupérée, le stockage Azure restaure automatiquement les opérations normales sur toutes les zones de disponibilité. Le service garantit automatiquement la cohérence des données en synchronisant toutes les opérations qui se sont produites pendant la période de panne.
Tester les pannes de zone
Lorsque vous utilisez le stockage redondant interzone (ZRS), le Stockage Azure gère automatiquement la réplication, le routage du trafic et les réponses d’échec de zone. Cette fonctionnalité étant complètement managée, vous n’avez pas besoin de lancer ou de valider les processus de défaillance de zone de disponibilité.
Résilience aux défaillances à l’échelle de la région
Le Stockage Azure, y compris Stockage Blob Azure, Azure Files, Stockage Table Azure et Stockage File d’attente Azure, fournit une gamme de fonctionnalités de géo-redondance et de basculement pour répondre à différentes exigences.
Important
Le stockage géo-redondant (GRS) fonctionne uniquement dans les régions jumelées Azure. Si la région de votre compte de stockage n’est pas jumelée, envisagez d’utiliser les solutions multirégions personnalisées pour la résilience.
Stockage géo-redondant pour les régions jumelées
Le Stockage Azure fournit plusieurs types de GRS dans les régions jumelées. Quel que soit le type de GRS que vous utilisez, les données de la région secondaire sont toujours répliquées à l’aide du stockage localement redondant (LRS). Cette approche offre une protection contre les défaillances matérielles au sein de la région secondaire.
Le GRS prend en charge les basculements planifiés et non planifiés vers la région jumelée Azure en cas de panne dans la région principale. GRS réplique de façon asynchrone les données de la région primaire vers la région jumelée.
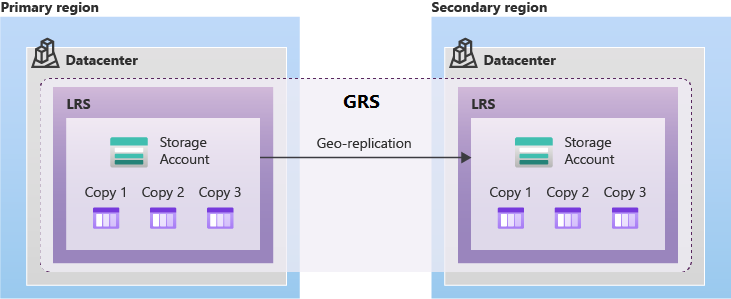
Le stockage géo-redondant interzone (GZRS) réplique les données dans plusieurs zones de disponibilité de la région principale et dans la région jumelée.
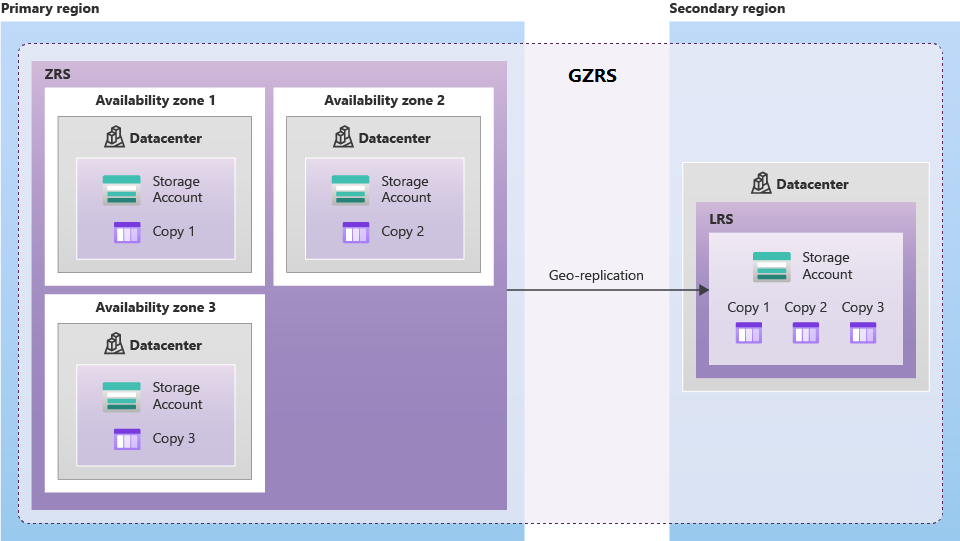


Stockage géo-redondant
- Le stockage géo-redondant avec accès en lecture (RA-GRS) et le stockage géo-redondant interzone avec accès en lecture (RA-GZRS) étendent le stockage géo-redondant (GRS) et le stockage géo-redondant interzone (GZRS), avec l’avantage ajouté de l’accès en lecture au point de terminaison secondaire. Ces options sont idéales pour les applications conçues pour les applications vitales pour l’entreprise à haute disponibilité. Dans le cas peu probable où le point de terminaison principal subit une panne, les applications configurées pour l’accès en lecture à la région secondaire peuvent continuer à fonctionner.
Types de basculement
Le Stockage Azure prend en charge trois types de basculement pour différents scénarios.
Basculement non planifié managé par le client : vous êtes responsable du lancement de la récupération en cas de défaillance du stockage à l’échelle de la région dans votre région principale.
Basculement planifié géré par le client : Vous êtes responsable du lancement de la récupération si une autre partie de votre solution a un échec dans votre région primaire et que vous devez basculer votre solution entière vers une région secondaire. Utilisez un basculement planifié lorsque le stockage reste opérationnel dans la région primaire, mais vous devez basculer l’ensemble de votre solution vers une région secondaire, par exemple pour les exercices de récupération d’urgence conçus pour garantir la conformité et les exigences d’audit.
Basculement managé par Microsoft : dans des circonstances exceptionnelles, Microsoft peut lancer le basculement pour tous les comptes de stockage géo-redondant (GRS) dans une région. Toutefois, le basculement géré par Microsoft est un dernier recours et doit être effectué uniquement après une période de panne prolongée. Vous ne devez pas dépendre du basculement géré par Microsoft.
Les comptes GRS peuvent utiliser l’un de ces types de basculement. Vous n’avez pas besoin de préconfigurer un compte de stockage pour utiliser les types de basculement à l’avance.
Requirements
Prise en charge de la région : Les configurations géoredondantes Azure Storage utilisent les régions jumelées d'Azure pour la réplication de la région secondaire. La région secondaire est automatiquement déterminée en fonction de la sélection de votre région principale et ne peut pas être personnalisée. Pour obtenir la liste complète des régions jumelées Azure, consultez la liste des régions Azure.
Si la région de votre compte de stockage n’est pas jumelée, envisagez d’utiliser les solutions multirégions personnalisées pour la résilience.
- Types de comptes de stockage : Le stockage géoredondant (GRS) et le basculement et le retour arrière initiés par le client sont disponibles dans toutes les régions jumelées Azure qui prennent en charge les comptes de stockage Azure à usage général v2.
Considerations
Lorsque vous implémentez le Stockage File d’attente multi-régions, tenez compte des facteurs importants suivants.
Latence de réplication asynchrone : la réplication des données vers la région secondaire est asynchrone, ce qui signifie qu’il existe un décalage entre le moment où les données sont écrites dans la région principale et lorsqu’elles sont disponibles dans la région secondaire. Ce décalage peut entraîner une perte de données potentielle si une défaillance de région principale se produit avant la réplication des données récentes. La perte de données est mesurée par l’objectif de point de récupération (RPO). Ce décalage de réplication sera probablement inférieur à 15 minutes, mais cette durée est une estimation et n’est pas garantie.
Vous pouvez vérifier la propriété Heure de la dernière synchronisation pour comprendre la quantité de données susceptible d’être perdue si votre compte de stockage subit un basculement non planifié.
Accès à la région secondaire : avec les configurations de stockage géo-redondant (GRS) et de stockage géo-redondant interzone (GZRS), la région secondaire n’est pas accessible pour les lectures tant qu’un basculement n’est pas effectué.
Les configurations de stockage géo-redondant avec accès en lecture (RA-GRS) et de stockage géo-redondant interzone avec accès en lecture (RA-GZRS) fournissent un accès en lecture à la région secondaire pendant les opérations normales, mais en raison de la latence de réplication asynchrone, elles peuvent retourner des données légèrement obsolètes.
- Limitations des fonctionnalités : certaines fonctionnalités du Stockage Azure ne sont pas prises en charge ou présentent des limitations lorsque vous utilisez le stockage géo-redondant (GRS) ou le basculement managé par le client. Passez en revue la compatibilité des fonctionnalités avant d’implémenter la géo-redondance.
Cost
Les configurations de compte de stockage Azure multi-régions entraînent des coûts supplémentaires pour la réplication interrégion et le stockage dans la région secondaire. Le transfert de données entre les régions Azure est facturé en fonction des taux de bande passante interrégion standard.
Pour obtenir des informations détaillées sur la tarification, consultez Tarification du stockage File d’attente.
Configurer la prise en charge multirégion
- Créer un compte de stockage géo-redondant (GRS). Pour créer un compte GRS, consultez Créer un compte de stockage et sélectionnez GRS, stockage géo-redondant avec accès en lecture (RA-GRS), stockage géo-redondant interzone (GZRS) ou stockage géo-redondant interzone avec accès en lecture (RA-GZRS) lors de la création du compte.
Activer la géo-redondance sur un compte de stockage existant. Pour convertir un compte de stockage existant en stockage géoredondant (GRS), consultez Modifier la façon dont un compte de stockage est répliqué.
Warning
Une fois votre compte reconfiguré pour la géo-redondance, il peut s’écouler beaucoup de temps avant que les données existantes de la nouvelle région principale ne soient entièrement copiées dans la nouvelle région secondaire.
Pour éviter une importante perte de données, vérifiez la valeur de la propriété Heure de la dernière synchronisation avant de lancer un basculement non planifié. Pour évaluer la perte de données potentielle, comparez l’heure de la dernière synchronisation à la dernière fois que les données ont été écrites dans la nouvelle région principale.
Désactiver la géoredondance. Convertissez des comptes GRS en configurations à région unique, comme le stockage localement redondant (LRS) ou le stockage redondant interzone (ZRS), en utilisant le même processus de modification de configuration de redondance.
Comportement lorsque toutes les régions sont saines
Cette section décrit ce qu’il faut attendre lorsqu’un compte de stockage est configuré pour la géoredondance et que toutes les régions sont opérationnelles.
Routage du trafic entre les régions : le Stockage Azure utilise une approche active-passive où toutes les opérations d’écriture et la plupart des opérations de lecture sont dirigées vers la région principale.
Pour les configurations de stockage géo-redondant avec accès en lecture (RA-GRS) et de stockage géo-redondant interzone avec accès en lecture (RA-GZRS), les applications peuvent éventuellement lire depuis la région secondaire en accédant au point de terminaison secondaire. Cette approche nécessite une configuration d’application explicite et n’est pas automatique. En outre, en raison du décalage de réplication asynchrone, les données de la région secondaire peuvent être légèrement obsolètes.
Réplication des données entre les régions : les opérations d’écriture sont tout d’abord validées dans la région principale en utilisant les types de redondance configurés suivants :
- Stockage localement redondant (LRS) pour le stockage géo-redondant (GRS) et le RA-GRS
- Stockage redondant interzone (ZRS) pour le stockage géo-redondant interzone (GZRS) et le RA-GZRS
Une fois l’achèvement réussi dans la région principale, les données sont répliquées de manière asynchrone dans la région secondaire où elles sont stockées en utilisant le LRS.
La nature asynchrone de la réplication interrégion signifie qu’il existe généralement un décalage entre le moment où les données sont écrites dans la région principale et lorsqu’elles sont disponibles dans la région secondaire. Vous pouvez surveiller l’heure de réplication en utilisant la propriété Heure de la dernière synchronisation.
Comportement lors d’une défaillance de région
Cette section décrit ce qu’il faut attendre lorsqu’un compte de stockage est configuré pour la géoredondance et qu’il existe une panne dans la région primaire.
Basculement managé par le client (non planifié) : utilisez un basculement non planifié lorsque le stockage dans la région principale n’est pas disponible.
Détection et réponse : Dans le cas peu probable où votre compte de stockage n’est pas disponible dans votre région primaire, vous pouvez envisager de lancer un basculement non planifié géré par le client. Pour prendre cette décision, tenez compte des facteurs suivants :
Indique si Azure Resource Health présente des problèmes d’accès au compte de stockage dans votre région principale
Indique si Microsoft vous conseille d’effectuer un basculement vers une autre région
Warning
Un basculement non planifié peut entraîner une perte de données. Avant de lancer un basculement managé par le client, déterminez si la restauration du service justifie le risque de perte de données.
Notification : Microsoft ne vous avertit pas automatiquement lorsqu’une région est en panne. Toutefois:
Vous pouvez utiliser Azure Resource Health pour surveiller l’intégrité d’une ressource individuelle et configurer des alertes Resource Health pour vous avertir des problèmes.
Vous pouvez utiliser Azure Service Health pour comprendre l’intégrité globale du service, y compris les défaillances de région, et vous pouvez configurer des alertes Service Health pour vous avertir des problèmes.
Demandes actives : Pendant le processus de basculement, les points de terminaison du compte de stockage principal et secondaire deviennent temporairement indisponibles pour les lectures et les écritures. Toutes les demandes actives peuvent être supprimées et les applications clientes doivent réessayer une fois le basculement terminé.
Perte de données attendue : la perte de données est courante lors d’un basculement non planifié en raison du décalage de la réplication asynchrone, ce qui signifie que les écritures récentes peuvent ne pas être répliquées. Vous pouvez vérifier la propriété Heure de la dernière synchronisation pour comprendre la quantité de données susceptible d’être perdue pendant un basculement non planifié. La perte de données attendue est souvent appelée objectif de point de récupération (RPO). Vous pouvez généralement vous attendre à ce que le RPO soit inférieur à 15 minutes, mais cette durée n’est pas garantie.
Temps d’arrêt attendu : Le temps d’arrêt attendu est souvent appelé objectif de temps de récupération (RTO). Le basculement géré par le client s'effectue généralement en moins de 60 minutes, selon la taille et la complexité du compte.
Réacheminement du trafic : Une fois le basculement terminé, Azure met automatiquement à jour les points de terminaison du compte de stockage afin que les applications n’ont pas besoin d’être reconfigurées. Si votre application conserve les entrées DNS (Domain Name System) mises en cache, il peut être nécessaire d’effacer le cache pour vous assurer que l’application envoie le trafic vers la nouvelle région principale.
Configuration après basculement : une fois le basculement non planifié terminé, votre compte de stockage dans la région de destination utilise le niveau de stockage localement redondant (LRS). Si vous avez besoin de le géo-répliquer, vous devez réactiver le stockage géo-redondant (GRS) et attendre que les données soient répliquées dans la nouvelle région secondaire.
Pour plus d’informations sur la façon de lancer un basculement managé par le client, consultez Fonctionnement du basculement managé par le client (non planifié) et Lancer un basculement de compte de stockage.
Basculement managé par le client (planifié) : utilisez un basculement planifié lorsque le stockage reste opérationnel dans la région principale, mais que vous devez basculer toute votre solution vers une région secondaire pour une autre raison. Par exemple, un autre service Azure peut rencontrer un problème et vous devez passer à l’utilisation d’une région secondaire pour toute votre solution. Vous pouvez également utiliser un basculement planifié pour effectuer un exercice de récupération d'urgence (DR) à des fins de conformité et d'audit.
Détection et réponse : vous êtes responsable de la décision de basculer. Vous prenez généralement cette décision si vous devez passer d'une région à l'autre, même si votre compte de stockage fonctionne correctement. Par exemple, vous pouvez déclencher un basculement en cas de panne majeure d’un autre composant d’application que vous ne pouvez pas récupérer dans la région primaire.
Notification : Microsoft ne vous avertit pas automatiquement lorsqu’une région est en panne. Toutefois:
Vous pouvez utiliser Azure Resource Health pour surveiller l’intégrité d’une ressource individuelle et configurer des alertes Resource Health pour vous avertir des problèmes.
Vous pouvez utiliser Azure Service Health pour comprendre l’intégrité globale du service, y compris les défaillances de région, et vous pouvez configurer des alertes Service Health pour vous avertir des problèmes.
Demandes actives : Pendant le processus de basculement, les points de terminaison du compte de stockage principal et secondaire deviennent temporairement indisponibles pour les lectures et les écritures. Toutes les demandes actives peuvent être supprimées et les applications clientes doivent réessayer une fois le basculement terminé.
Perte de données attendue : Aucune perte de données n’est attendue, car le processus de basculement se termine uniquement après la synchronisation de toutes les données, ce qui entraîne un RPO de zéro.
Temps d'indisponibilité prévu : le basculement s'effectue généralement en moins de 60 minutes, ce qui signifie que le RTO prévu est de 60 minutes, en fonction de la taille et de la complexité du compte. Pendant le processus de basculement, les points de terminaison du compte de stockage principal et secondaire deviennent temporairement indisponibles pour les lectures et les écritures.
Réacheminement du trafic : Une fois le basculement terminé, Azure met automatiquement à jour les points de terminaison du compte de stockage afin que les applications n’ont pas besoin d’être reconfigurées. Si votre application conserve les entrées DNS mises en cache, il peut être nécessaire d’effacer le cache pour vous assurer que l’application envoie le trafic vers la nouvelle région principale.
Configuration après basculement : Une fois le basculement planifié terminé, votre compte de stockage dans la région de destination continue d’être géorépliqué et reste au niveau GRS.
Pour plus d’informations sur la façon de lancer un basculement managé par le client, consultez Fonctionnement du basculement managé par le client (planifié) et Lancer un basculement de compte de stockage.
Basculement géré par Microsoft : En cas de sinistre majeur où Microsoft détermine que la région primaire est définitivement irrécupérable, un basculement automatique vers la région secondaire peut être lancé. Microsoft gère l’ensemble du processus et aucune action client n’est requise. La durée qui s’écoule avant le basculement dépend de la gravité de la catastrophe et du temps nécessaire pour évaluer la situation.
Notification : Microsoft ne vous avertit pas automatiquement lorsqu’une région est en panne. Toutefois:
Vous pouvez utiliser Azure Resource Health pour surveiller l’intégrité d’une ressource individuelle et configurer des alertes Resource Health pour vous avertir des problèmes.
Vous pouvez utiliser Azure Service Health pour comprendre l’intégrité globale du service, y compris les défaillances de région, et vous pouvez configurer des alertes Service Health pour vous avertir des problèmes.
Important
Utilisez les options de basculement managé par le client pour développer, tester et implémenter vos plans de récupération d’urgence. Ne comptez pas sur le basculement géré par Microsoft, car il n’est utilisé que dans des situations extrêmes. Un basculement managé par Microsoft est probablement lancé pour une région entière. Il ne peut pas être lancé pour des comptes de stockage, des abonnements ou des clients individuels. Le basculement peut se produire à différents moments pour différents services Azure. Nous vous recommandons d’utiliser le basculement managé par le client.
Récupération de région
Le processus de restauration automatique diffère considérablement entre les scénarios de basculement managés par Microsoft et managés par le client.
Basculement managé par le client (non planifié) : après un basculement non planifié, le compte de stockage est configuré avec un stockage localement redondant (LRS). Pour restaurer automatiquement, vous devez rétablir la relation de stockage géo-redondant (GRS) et attendre que les données soient répliquées.
Basculement managé par le client (planifié) : après un basculement planifié, le compte de stockage reste géo-répliqué. Vous pouvez lancer un autre basculement managé par le client pour effectuer une restauration automatique vers la région principale d’origine. Les mêmes considérations de basculement s’appliquent.
Basculement managé par Microsoft : si Microsoft lance un basculement, il est probable qu’une catastrophe importante s’est produite dans la région principale et que celle-ci ne soit pas récupérable. Toutes les chronologies ou plans de récupération dépendent de l’étendue des efforts liés au sinistre régional et à la reprise d’activité. Vous devez surveiller les communications Azure Service Health pour plus d’informations.
Tester les défaillances régionales
Vous pouvez simuler des défaillances régionales pour tester vos procédures de récupération d’urgence.
Test de basculement planifié : pour les comptes de stockage géo-redondant (GRS), vous pouvez effectuer des opérations de basculement planifiées pendant les fenêtres de maintenance pour tester le processus de basculement et de restauration automatique complet. Le basculement planifié n’implique pas de perte de données, mais un temps d’arrêt pendant le basculement et la restauration automatique.
Test de point de terminaison secondaire : pour les configurations de stockage géo-redondant avec accès en lecture (RA-GRS) et de stockage géo-redondant interzone avec accès en lecture (RA-GZRS), testez régulièrement les opérations de lecture sur le point de terminaison secondaire pour vous assurer que votre application peut lire correctement les données depuis la région secondaire.
Solutions multirégions personnalisées pour la résilience
Les fonctionnalités de basculement inter-régions du Stockage Azure peuvent ne pas convenir pour les raisons suivantes :
Votre compte de stockage se trouve dans une région non appariée.
Vos objectifs de temps d’activité métier ne sont pas satisfaits par le temps de récupération ou la perte de données que les options de basculement intégrées fournissent.
Vous devez basculer vers une région qui n’est pas jumelée à votre région principale.
Il vous faut une configuration active/active entre les régions.
Cette section fournit une vue d’ensemble générale de certaines approches à prendre en compte. Une vue d’ensemble complète des topologies de déploiement multirégion pour stockage Azure est en dehors de l’étendue de cet article.
Note
Pour les exigences multi-régions avancées, envisagez d’utiliser Service Bus à la place, qui inclut la prise en charge des régions non jumelées.
Vous pouvez déployer le Stockage Azure dans plusieurs régions en utilisant des comptes de stockage distincts dans chaque région. Cette approche offre une flexibilité dans la sélection des régions, la possibilité d’utiliser des régions non jumelées et un contrôle plus précis sur la chronologie de la réplication et la cohérence des données. Lorsque vous implémentez plusieurs comptes de stockage dans plusieurs régions, vous devez configurer la réplication des données inter-régions, implémenter l’équilibrage de charge et les stratégies de basculement, et garantir la cohérence des données entre les régions.
Cette approche vous oblige à gérer la distribution des messages, à gérer la synchronisation des données entre les files d’attente des différents comptes de stockage et à implémenter une logique de basculement personnalisée.
Sauvegarde et restauration
Le Stockage File d’attente ne fournit pas de fonctionnalités de sauvegarde traditionnelles, telles que la restauration à un instant dans le passé (PITR). Cela est dû au fait que les files d’attente sont conçues pour le stockage de messages temporaires, au lieu d’une persistance des données à long terme. Les messages sont généralement traités et supprimés des files d’attente pendant les opérations normales de l’application.
Pour les scénarios nécessitant une durabilité des messages au-delà des options de redondance intégrées, envisagez d’implémenter votre propre journalisation ou persistance de messages au niveau de l’application dans un magasin de données permanent, tel que le Stockage Blob ou Azure SQL Database. Cette approche vous permet de conserver l’historique des messages tout en utilisant la file d'attente de stockage pour sa fonction prévue de mise en mémoire tampon temporaire et de coordination du traitement des messages.
Contrat de niveau de service
Le contrat de niveau de service (SLA) pour stockage Azure décrit la disponibilité attendue du service et les conditions qui doivent être remplies pour atteindre cette attente de disponibilité. Le contrat SLA de disponibilité auquel vous êtes éligible dépend du niveau de stockage et du type de réplication que vous utilisez. Pour plus d’informations, consultez Contrats SLA pour les services en ligne.