Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment configurer un cluster Pacemaker de base sur Red Hat Enterprise Server (RHEL). Les instructions couvrent à la fois RHEL 7, RHEL 8 et RHEL 9.
Conditions préalables
Lisez les articles et les notes SAP suivantes :
Lisez la documentation sur la haute disponibilité (HA) RHEL
- Configuration et gestion des clusters de haute disponibilité.
- Stratégies de prise en charge pour les clusters haute disponibilité RHEL – sbd et fence_sbd.
- Stratégies de prise en charge pour les clusters haute disponibilité RHEL – fence_azure_arm.
- Limitations connues de la surveillance émulée par logiciel.
- Exploration des composants de la haute disponibilité de Red Hat Enterprise Linux – sbd et fence_sbd.
- Guide de conception pour les clusters à haute disponibilité RHEL – Considérations relatives à sbd
- Considérations relatives à l’adoption de RHEL 8 – Haute disponibilité et clusters
Documentation RHEL spécifique à Azure
Documentation RHEL pour les offres SAP
- Stratégies de prise en charge pour les clusters à haute disponibilité RHEL – Gestion de SAP S/4HANA dans un cluster.
- Configuration de SAP S/4HANA ASCS/ERS avec Standalone Enqueue Server 2 (ENSA2) dans Pacemaker.
- Configuration d’une réplication du système SAP HANA dans un cluster Pacemaker.
- Solution de haute disponibilité Red Hat Enterprise Linux pour le Scale-out SAP HANA et la réplication de système.
Vue d’ensemble
Important
Les clusters Pacemaker qui s’étendent sur plusieurs réseaux virtuels/sous-réseaux ne sont pas couverts par les stratégies du Support Standard.
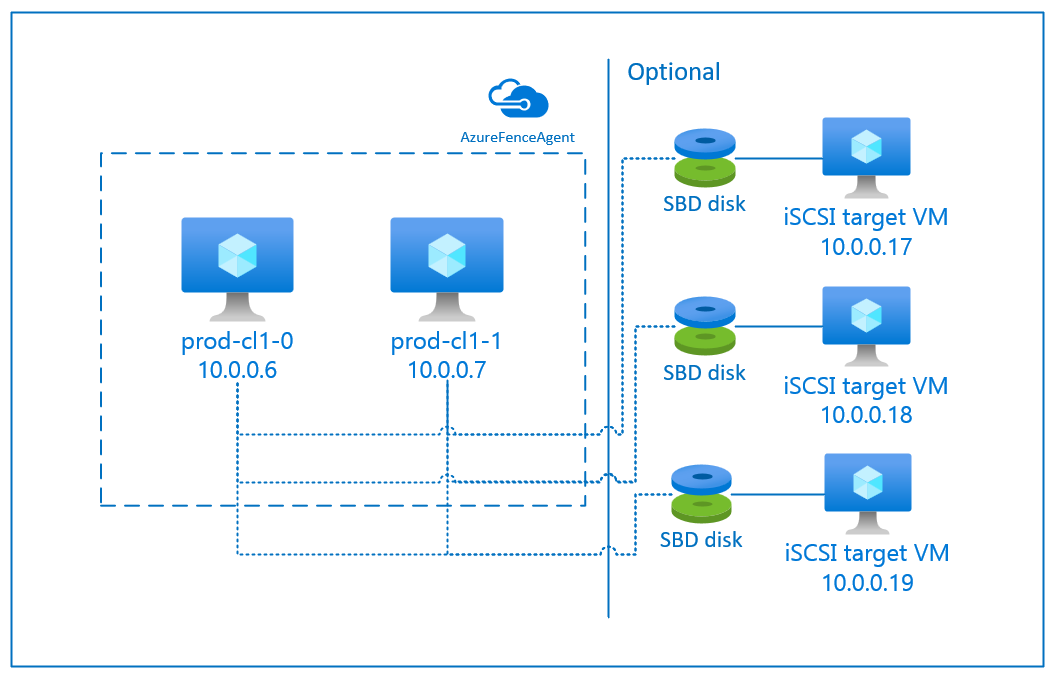
Il existe deux options disponibles sur Azure pour configurer l’isolation dans un cluster Pacemaker pour RHEL : l’agent d’isolation Azure qui redémarre un nœud défaillant via les API Azure ou vous pouvez utiliser un appareil SBD.
Important
Dans Azure, un cluster de haute disponibilité RHEL (Red Hat Enterprise Linux) avec un fencing basé sur le stockage (fence_sbd) utilise un chien de garde émulé par logiciel. Il est important de passer en revue Limitations connues du chien de garde émulé par logiciel et Stratégies de prise en charge pour les clusters haute disponibilité RHEL – sbd et fence_sbd lorsque vous sélectionnez SBD comme mécanisme de clôture.
Utilisation d’un appareil SBD
Remarque
Le mécanisme d’isolation avec SBD est pris en charge sur RHEL 8.8 et versions ultérieures, ainsi que sur RHEL 9.0 et versions ultérieures.
Vous pouvez configurer l’appareil SBD de deux manières :
SBD avec Serveur cible iSCSI
Le dispositif SBD nécessite au moins une machine virtuelle supplémentaire qui agit en tant que serveur cible iSCSI (interface Internet SCSI de système de calcul) et fournit un appareil SBD. Ces serveurs cibles iSCSI peuvent toutefois être partagés avec d’autres clusters Pacemaker. Le recours à un appareil SBD présente l’avantage que, si vous utilisez déjà des appareils SBD en local, ils ne vous obligent pas à modifier la façon dont vous exploitez le cluster Pacemaker.
Vous pouvez utiliser jusqu'à trois appareils SBD dans un cluster Pacemaker pour permettre qu'un appareil SBD devienne indisponible (par exemple, lors de la mise à jour corrective du serveur cible iSCSI). Si vous souhaitez utiliser plusieurs appareils SBD par Pacemaker, veillez à déployer plusieurs serveurs cibles iSCSI et à connecter un SBD à partir de chaque serveur cible iSCSI. Nous vous recommandons d’utiliser un ou trois appareils SBD. Pacemaker ne peut pas isoler automatiquement un nœud de cluster si deux appareils SBD uniquement sont configurés et que l’un d’eux n’est pas disponible. Si vous souhaitez pouvoir procéder à une isolation lorsqu’un serveur cible iSCSI est inactif, vous devez utiliser trois appareils SBD, et donc trois serveurs cibles iSCSI. Il s’agit de la configuration la plus résiliente avec des appareils SBD.
Important
Lorsque vous planifiez pour déployer et configurer des nœuds de cluster Pacemaker Linux et des appareils SBD, n’autorisez pas le routage entre vos machines virtuelles et celles qui hébergent les appareils SBD à passer par d’autres appareils, par exemple une appliance virtuelle réseau (NVA).
Les événements de maintenance et d’autres problèmes liés à l’appliance réseau virtuelle NVA peuvent avoir un impact négatif sur la stabilité et la fiabilité de la configuration générale du cluster. Pour obtenir plus d’informations, consultez les Règles de routage définies par l’utilisateur.
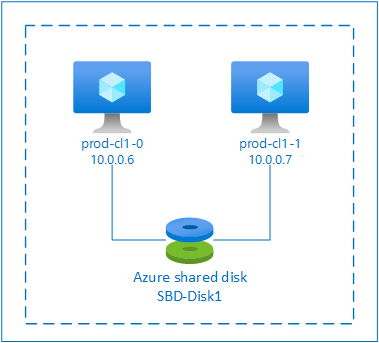
SBD avec disque partagé Azure
Pour configurer un appareil SBD, vous devez attacher au moins un disque partagé Azure à toutes les machines virtuelles qui font partie du cluster Pacemaker. L’avantage d’un appareil SBD utilisant un disque partagé Azure est que vous n’avez pas besoin de déployer et de configurer de machines virtuelles supplémentaires.
Voici quelques considérations importantes sur les appareils SBD à prendre en compte lors de la configuration de l’utilisation d’un disque partagé Azure :
- Un disque partagé Azure avec SSD Premium est pris en charge en tant qu’appareil SBD.
- Les appareils SBD qui utilisent un disque partagé Azure sont pris en charge sur RHEL 8.8 et versions ultérieures.
- Les appareils SBD qui utilisent un disque partagé Azure Premium sont pris en charge sur le stockage localement redondant (LRS) et le stockage redondant interzone (ZRS).
- Selon le type de votre déploiement, choisissez le stockage redondant approprié pour un disque partagé Azure comme appareil SBD.
- Un appareil SBD utilisant le stockage LRS pour un disque partagé Azure Premium (skuName – Premium_LRS) n’est pris en charge qu’avec un déploiement régional tel qu’un groupe à haute disponibilité.
- Un appareil SBD utilisant le stockage ZRS pour un disque partagé Azure Premium (skuName – Premium_ZRS) est recommandé avec un déploiement zonal tel qu’une zone de disponibilité ou un groupe identique avec FD=1.
- Un ZRS pour disque géré est actuellement disponible dans les régions répertoriées dans le document sur la disponibilité régionale.
- Le disque partagé Azure utilisé pour les appareils SBD n’a pas besoin d’être de grande taille. La valeur maxShares détermine combien de nœuds de cluster peuvent utiliser le disque partagé. Par exemple, vous pouvez choisir les tailles de disque P1 et P2 pour votre appareil SBD sur un cluster à deux nœuds, par exemple un scale-up SAP ASCS/ERS ou SAP HANA.
- Pour un scale-out HANA avec une réplication système HANA (HSR) et Pacemaker, vous pouvez utiliser un disque partagé Azure pour des appareils SBD dans des clusters contenant jusqu’à cinq nœuds par site de réplication en raison de la limite actuelle de maxShares.
- Nous vous déconseillons d’attacher un appareil SBD de disque partagé Azure sur plusieurs clusters Pacemaker.
- Si vous utilisez plusieurs appareils SBD de disque partagé Azure, vérifiez le nombre maximal de disques de données pouvant être attachés à la machine virtuelle.
- Pour plus d’informations sur les limitations des disques partagés Azure, lisez attentivement la section « Limitations » de la documentation Disque partagé Azure.
Utilisation d’un agent d’isolation Azure
Vous pouvez configurer l’isolation à l’aide d’un agent d’isolation Azure. L’agent d’isolation Azure nécessite des identités managées pour les machines virtuelles de cluster, ou un principal de service ou une identité système managée (MSI) qui gère le redémarrage de nœuds défaillants via des API Azure. L'agent de barrière Azure n'impose pas le déploiement de machines virtuelles supplémentaires.
Appareil SBD avec un serveur cible iSCSI
Pour utiliser un appareil SBD qui a recours à un serveur cible iSCSI pour l’isolation, suivez les instructions des sections suivantes.
Configuration du serveur cible iSCSI
Vous devez tout d’abord créer les machines virtuelles cibles iSCSI. Vous pouvez partager des serveurs cibles iSCSI avec plusieurs clusters Pacemaker.
Déployez des machines virtuelles s’exécutant sur une version de système d’exploitation RHEL prise en charge et connectez-vous-y via SSH. Les machines virtuelles ne doivent pas nécessairement être de grande taille. Les tailles de machines virtuelles telles que Standard_E2s_v3 et Standard_D2s_v3 sont suffisantes. Veillez à utiliser le Stockage Premium pour le disque de système d’exploitation.
Il n’est pas nécessaire d’utiliser RHEL pour SAP avec HA et les services de mise à jour, ou une image du système d'exploitation RHEL pour applications SAP pour le serveur cible iSCSI. Vous pouvez utiliser une image de système d’exploitation RHEL standard à la place. Toutefois, n’oubliez pas que le cycle de vie de prise en charge varie entre les différentes versions de produit de systèmes d’exploitation.
Exécutez les commandes suivantes sur toutes les machines virtuelles de cible iSCSI.
Mettez à jour RHEL.
sudo yum -y updateRemarque
Vous pouvez être amené à redémarrer le nœud après la mise à niveau ou la mise à jour du système d’exploitation.
Installez le package cible iSCSI.
sudo yum install targetcliDémarrez et configurez la cible pour commencer à l’heure de démarrage.
sudo systemctl start target sudo systemctl enable targetOuvrir le port
3260dans le pare-feusudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Création d’un appareil iSCSI sur le serveur cible iSCSI
Pour créer les disques iSCSI pour vos clusters SAP, exécutez les commandes suivantes sur toutes les machines virtuelles cibles iSCSI. L’exemple illustre la création d’appareils SBD pour plusieurs clusters, ce qui démontre l’utilisation d’un seul serveur cible iSCSI pour de nombreux clusters. L’appareil SBD est configuré sur le disque de système d’exploitation. Veillez donc à disposer d’un espace suffisant.
- ascsnw1 : représente le cluster ASCS/ERS de NW1.
- dbhn1 : représente le cluster de base de données de HN1.
- sap-cl1 and sap-cl2 : noms d’hôte des nœuds de cluster NW1 ASCS/ERS.
- hn1-db-0 et hn1-db-1 : noms d’hôte des nœuds de cluster de base de données.
Dans les instructions suivantes, modifiez la commande par vos SID et noms d’hôte spécifiques, le cas échéant.
Créez le dossier racine de tous les appareils SBD.
sudo mkdir /sbdCréez le dispositif SBD pour les serveurs ASCS/ERS du système NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Créez le dispositif SBD du cluster de base de données du système HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Enregistrez la configuration targetcli.
sudo targetcli saveconfigVérifiez que tout a été correctement configuré
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Configuration de l’appareil SBD du serveur cible iSCSI
[A] : s’applique à tous les nœuds. [1] : s’applique uniquement au nœud 1. [2] : s’applique uniquement au nœud 2.
Sur les nœuds de cluster, connectez et découvrez l’appareil iSCSI créé dans la section précédente. Exécutez les commandes suivantes sur les nœuds du nouveau cluster que vous souhaitez créer.
[A] Installez ou mettez à jour les utilitaires d’initiateur iSCSI sur tous les nœuds de cluster.
sudo yum install -y iscsi-initiator-utils[A] Installez le cluster et les packages SBD sur tous les nœuds de cluster.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Activez le service iSCSI.
sudo systemctl enable iscsid iscsi[1] Modifiez le nom de l’initiateur sur le premier nœud du cluster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Modifiez le nom de l’initiateur sur le deuxième nœud du cluster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Redémarrez le service iSCSI pour appliquer les modifications.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Connectez les appareils iSCSI. Dans l’exemple suivant, 10.0.0.17 est l’adresse IP du serveur cible iSCSI, et 3260 le port par défaut. Le nom de cible
iqn.2006-04.ascsnw1.local:ascsnw1est répertorié lorsque vous exécutez la première commandeiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Si vous utilisez plusieurs appareils SBD, connectez-vous également au deuxième serveur cible iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Si vous utilisez plusieurs appareils SBD, connectez-vous également au troisième serveur cible iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Vérifiez que les appareils iSCSI sont disponibles et notez le nom d’appareil. Dans l’exemple suivant, trois appareils iSCSI sont découverts en connectant le nœud aux trois serveurs cibles iSCSI.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Récupérez l’ID des appareils iSCSI.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgLa commande liste trois ID de périphérique pour chaque appareil SBD. Nous vous recommandons d’utiliser l'ID qui commence par scsi-3. Dans l’exemple précédent, les ID sont les suivants :
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Créez l’appareil SBD.
Utilisez l’ID d’appareil des appareils iSCSI pour créer de nouveaux appareils SBD sur le premier nœud de cluster.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createCréez également le deuxième et le troisième appareil SBD si vous souhaitez en utiliser plusieurs.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Adaptez la configuration SBD
Ouvrez le fichier de configuration SBD.
sudo vi /etc/sysconfig/sbdModifiez la propriété de l’appareil SBD, activez l’intégration de Pacemaker et modifiez le mode de démarrage de SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Exécutez la commande suivante pour charger le module
softdog.modprobe softdog[A] Exécutez la commande suivante pour veiller à ce que
softdogsoit automatiquement chargé après un redémarrage de nœud.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] La valeur du délai d’expiration du service SBD est définie sur 90 s par défaut. Toutefois, si la valeur de
SBD_DELAY_STARTest définie suryes, le service SBD retarde son démarrage jusqu’au délai d’expiration demsgwait. Par conséquent, la valeur de délai d’expiration du service SBD doit dépasser le délai d’expiration demsgwaitquandSBD_DELAY_STARTest activé.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Appareil SBD avec un disque partagé Azure
Cette section s’applique uniquement si vous souhaitez utiliser un appareil SBD avec un disque partagé Azure.
Configurer un disque partagé Azure avec PowerShell
Pour créer et attacher un disque partagé Azure avec PowerShell, exécutez l’instruction suivante. Si vous souhaitez déployer des ressources avec Azure CLI ou le Portail Azure, vous pouvez également consulter Déploiement d’un disque ZRS.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Configuration de l’appareil SBD du disque partagé Azure
[A] Installez le cluster et les packages SBD sur tous les nœuds de cluster.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Assurez-vous que le disque attaché est disponible.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Récupérez l’ID d’appareil du disque partagé attaché.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaL’ID d’appareil de liste de commande pour le disque partagé attaché. Nous vous recommandons d’utiliser l'ID qui commence par scsi-3. Dans cet exemple, l’ID est /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Créer l’appareil SBD
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Adaptez la configuration SBD
Ouvrez le fichier de configuration SBD.
sudo vi /etc/sysconfig/sbdModifiez la propriété de l’appareil SBD, activez l’intégration du Pacemaker et modifiez le mode de démarrage de SBD
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Exécutez la commande suivante pour charger le module
softdog.modprobe softdog[A] Exécutez la commande suivante pour veiller à ce que
softdogsoit automatiquement chargé après un redémarrage de nœud.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] La valeur du délai d’expiration du service SBD est définie sur 90 secondes par défaut. Toutefois, si la valeur de
SBD_DELAY_STARTest définie suryes, le service SBD retarde son démarrage jusqu’au délai d’expiration demsgwait. Par conséquent, la valeur de délai d’expiration du service SBD doit dépasser le délai d’expiration demsgwaitquandSBD_DELAY_STARTest activé.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Configuration d’agent d’isolation Azure
L’appareil d’isolation utilise une identité managée pour les ressources Azure ou un principal de service à autoriser sur Azure. Selon la méthode de gestion des identités, suivez les procédures appropriées –
Configurer la gestion des identités
Utilisez une identité managée ou un principal de service.
Pour créer une identité managée (MSI), créez une identité managée affectée par le système pour chaque machine virtuelle du cluster. Si une identité managée affectée par le système existe déjà, elle sera alors utilisée. N’utilisez pas d’identités managées attribuées par l’utilisateur avec Pacemaker pour l’instant. Un appareil d’isolation, basé sur l’identité managée, est pris en charge sur RHEL 7.9 et RHEL 8.x/RHEL 9.x.
Créer un rôle personnalisé pour l’agent d’isolation
Par défaut, ni l’identité managée ni le principal de service ne disposent des autorisations nécessaires pour accéder à vos ressources Azure. Vous devez accorder à l’identité managée ou au principal de service les autorisations appropriées pour démarrer et arrêter (mettre hors tension) toutes les machines virtuelles du cluster. Si vous n’avez pas encore créé le rôle personnalisé, utilisez pour cela PowerShell ou Azure CLI.
Utilisez le contenu suivant pour le fichier d’entrée. Vous devez adapter le contenu à vos abonnements, c’est-à-dire remplacer
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxetyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyypar vos ID d’abonnement. Si vous n’avez qu’un seul abonnement, supprimez la deuxième entrée dansAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Attribuer le rôle personnalisé
Utilisez une identité managée ou un principal de service.
Attribuez le rôle personnalisé
Linux Fence Agent Rolecréé dans la dernière section de chaque identité managée des machines virtuelles du cluster. Chaque identité managée affectée par le système de machine virtuelle a besoin du rôle attribué pour la ressource de chaque machine virtuelle du cluster. Pour plus d’informations, consultez Attribuer à une identité managée un accès à une ressource à l’aide du Portail Azure. Vérifiez que l’attribution de rôle d’identité managée de chaque machine virtuelle contient toutes les machines virtuelles du cluster.Important
Soyez conscient que le processus d'attribution et de suppression de l'autorisation avec des identités gérées peut être retardé jusqu'à ce qu'il soit effectif.
Installation du cluster
Les différences dans les commandes ou la configuration entre RHEL 7 et RHEL 8/RHLEL 9 sont marquées dans le document.
[A] Installez le module complémentaire RHEL HA.
sudo yum install -y pcs pacemaker nmap-ncat[A] Sur RHEL 9x, installez les agents de ressources pour le déploiement cloud.
sudo yum install -y resource-agents-cloud[A] Installez le package fence-agents si vous utilisez un appareil d’isolation basé sur un agent d’isolation Azure.
sudo yum install -y fence-agents-azure-armImportant
Nous recommandons les versions suivantes de l’agent d’isolation Azure (ou une version ultérieure) aux clients qui souhaitent utiliser les identités managées pour les ressources Azure à la place des noms de principaux de service pour l’agent d’isolation :
- RHEL 8.4 : fence-agents-4.2.1-54.el8.
- RHEL 8.2 : fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1 : fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9 : fence-agents-4.2.1-41.el7_9.4.
Important
Sur RHEL 9, nous vous recommandons les versions de package suivantes (ou versions ultérieures) pour éviter les problèmes liés à l’agent d’isolation Azure :
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Vérifiez la version de l’agent de clôture Azure. Si nécessaire, mettez-le à jour vers la version minimale requise ou ultérieure.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armImportant
Si vous devez mettre à jour l’agent d’isolation Azure et que vous utilisez un rôle personnalisé, mettez à jour ce dernier en y ajoutant l’action powerOff. Pour plus d’informations, consultez Créer un rôle personnalisé pour l’agent de clôture.
[A] Configurer la résolution du nom d’hôte.
Vous pouvez utiliser un serveur DNS ou modifier le fichier
/etc/hostssur tous les nœuds. Cet exemple vous explique comment utiliser le fichier/etc/hosts. Remplacez l’adresse IP et le nom d’hôte dans les commandes suivantes.Important
Si vous utilisez des noms d’hôte dans la configuration du cluster, il est absolument essentiel que vous disposiez d’une résolution fiable du nom d’hôte. Si les noms ne sont pas disponibles, les communications de cluster échouent, ce qui peut entraîner des retards de basculement de cluster.
L’avantage d’utiliser
/etc/hostsréside dans le fait que votre cluster devient indépendant du DNS, ce qui peut aussi représenter un point de défaillance unique.sudo vi /etc/hostsInsérez les lignes suivantes dans
/etc/hosts. Changez l’adresse IP et le nom d’hôte en fonction de votre environnement.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Changez le mot de passe
haclusterpour utiliser le même mot de passe.sudo passwd hacluster[A] Ajoutez des règles de pare-feu pour Pacemaker.
Ajoutez les règles de pare-feu suivantes à toutes les communications de cluster entre les nœuds de cluster.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Activez les services de cluster de base.
Exécutez les commandes suivantes pour activer le service Pacemaker et le démarrer.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Créez un cluster Pacemaker.
Exécutez les commandes suivantes pour authentifier les nœuds et créer le cluster. Définissez le jeton sur 30000 pour permettre la maintenance tout en préservant la mémoire. Pour plus d’informations, consultez cet article pour Linux.
Si vous créez un cluster sur RHEL 7.x, utilisez les commandes suivantes :
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allSi vous créez un cluster sur RHEL 8.x/RHEL 9.x, utilisez les commandes suivantes :
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allVérifiez l’état du cluster en exécutant la commande suivante :
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Définissez les votes attendus.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Conseil
Si vous créez un cluster à plusieurs nœuds (c’est-à-dire, un cluster comportant plus de deux nœuds), ne définissez pas la valeur 2 aux votes.
[1] Autorisez les actions d’isolation simultanées.
sudo pcs property set concurrent-fencing=true
Créer un dispositif de clôture sur le cluster Pacemaker
Conseil
- Pour éviter les courses d’isolation au sein d’un cluster Pacemaker à deux nœuds, vous pouvez configurer une propriété de cluster
priority-fencing-delay. Cette propriété introduit un délai supplémentaire dans un délimiteur de nœud qui a une priorité de ressource totale supérieure lorsqu’un scénario split-brain se produit. Pour plus d’informations, consultez Pacemaker peut-il clôturer le nœud de cluster avec le moins de ressources en cours d’exécution ?. - La propriété
priority-fencing-delays’applique à Pacemaker version 2.0.4-6.el8 ou ultérieure et sur un cluster à deux nœuds. Si vous configurez la propriété de clusterpriority-fencing-delay, il n’est pas nécessaire de définir la propriétépcmk_delay_max. En revanche, si la version de Pacemaker est antérieure à 2.0.4-6.el8, vous devez définir la propriétépcmk_delay_max. - Pour obtenir des instructions sur la définition de la propriété de cluster
priority-fencing-delay, consultez la documentation respective sur la haute disponibilité avec Scale-up pour SAP ASCS/ERS et SAP HANA.
Selon le mécanisme d’isolation sélectionné, suivez uniquement une section pour découvrir les instructions pertinentes : SBD en tant qu’appareil d’isolation ou Agent d’isolation Azure en tant qu’appareil d’isolation.
SBD en tant qu’appareil d’isolation
[A] Activez un service SBD
sudo systemctl enable sbd[1] Pour l’appareil SBD configuré en utilisant des serveurs cibles iSCSI ou un disque partagé Azure, exécutez les commandes suivantes.
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Redémarrez le cluster
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allRemarque
Si vous rencontrez l’erreur suivante lors du démarrage du cluster Pacemaker, vous pouvez ignorer le message. Vous pouvez également démarrer le cluster via la commande
pcs cluster start --all --request-timeout 140.Erreur : nous ne pouvons pas démarrer tous les nœuds node1/node2 : il est impossible d’effectuer la connexion à node1/node2, vérifiez si pcsd s’y exécute ou essayez de définir un délai d’expiration supérieur avec l’option
--request-timeout(l’opération a expiré après 60 000 millisecondes avec 0 octet reçu)
Agent d’isolation Azure en tant qu’appareil d’isolation
[1] Une fois que vous avez attribué des rôles aux deux nœuds de cluster, vous pouvez configurer les appareils d’isolation dans le cluster.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Exécutez la commande appropriée selon que vous utilisez une identité managée ou un principal de service pour l’agent d’isolation Azure.
Remarque
Quand vous utilisez le cloud Azure Government, vous devez spécifier l’option
cloud=au moment de la configuration de l’agent d’isolation. Par exemple,cloud=usgovpour le cloud Azure US Government. Pour plus d’informations sur la prise en charge de RedHat sur le cloud Azure Government, consultez Politiques de support des clusters à haute disponibilité RHEL - Machines virtuelles Microsoft Azure en tant que membres du cluster.Conseil
L’option
pcmk_host_mapest requise dans la commande uniquement si les noms d’hôte RHEL et les noms de machines virtuelles Azure ne sont pas identiques. Spécifiez le mappage au format nom-d-hôte:nom-machine-virtuelle. Pour plus d’informations, consultez Quel format dois-je utiliser pour spécifier les mappages de nœuds pour les dispositifs de protection dans pcmk_host_map ?.Pour RHEL 7.x, utilisez la commande suivante pour configurer l’appareil de délimitation :
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600Pour RHEL 8.x/9.x, utilisez la commande suivante pour configurer l’appareil d’isolation :
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
Si vous utilisez un appareil d’isolation, en fonction de la configuration du principal de service, lisez Passer de SPN à MSI pour les clusters Pacemaker à l’aide de l’isolation Azure et découvrez comment effectuer la conversion en configuration d’identité managée.
Les opérations de monitoring et d’isolation sont désérialisées. Par conséquent, si un événement d’isolation se produit en même temps qu’une opération de monitoring longue, il n’y a aucun délai pour le basculement du cluster. En effet, l’opération de monitoring est déjà en cours d’exécution.
Conseil
L'agent de clôture Azure nécessite une connectivité sortante aux points de terminaison publics. Pour plus d’informations et pour découvrir les solutions potentielles, consultez Connectivité de point de terminaison public pour les machines virtuelles avec ILB Standard.
Configuration de Pacemaker pour les événements planifiés Azure
Azure propose des événements planifiés. Les événements planifiés sont fournis via le service de métadonnées et permettent à l’application de se préparer à ces événements.
L’agent de ressources azure-events-az surveille les événements Azure planifiés. Si des événements sont détectés et que l’agent de ressources détermine qu’un autre nœud de cluster est disponible, il définit l'attribut d’intégrité au niveau du nœud #health-azure sur -1000000.
Lorsque cet attribut d’intégrité de cluster spécial est défini pour un nœud, le nœud est considéré comme non sain par le cluster et toutes les ressources sont migrées loin du nœud affecté. La contrainte d’emplacement garantit que les ressources dont le nom commence par « health- » sont exclues, car l’agent doit fonctionner dans cet état défectueux. Une fois que le nœud de cluster affecté est libre d’exécuter des ressources de cluster, l’événement planifié peut exécuter son action, telle que le redémarrage, sans risque d’exécuter des ressources.
L’attribut #heath-azure est réinitialisé à 0 au démarrage de pacemaker, une fois que tous les événements ont été traités, marquant ainsi le nœud comme sain à nouveau.
[A] Vérifiez que le package de l’agent
azure-events-azest déjà installé et à jour.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudExigences minimales pour la version :
- RHEL 8.4 :
resource-agents-4.1.1-90.13 - RHEL 8.6 :
resource-agents-4.9.0-16.9 - RHEL 8.8 :
resource-agents-4.9.0-40.1 - RHEL 9.0 :
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 et versions ultérieures :
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4 :
[1] Configurez les ressources dans Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Définissez la stratégie et la contrainte du nœud de santé du cluster Pacemaker.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Important
Ne définissez aucune autre ressource dans le cluster en commençant par
health-en plus des ressources décrites dans les étapes suivantes.[1] Définissez la valeur initiale des attributs de cluster. Exécutez pour chaque nœud de cluster et pour les environnements de Scale-out, y compris la machine virtuelle de Pacemaker majoritaire.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configurez les ressources dans Pacemaker. Assurez-vous que les ressources commencent par
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ meta failure-timeout=120s \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=trueDésactivez le mode maintenance du cluster Pacemaker.
sudo pcs property set maintenance-mode=falseEffacez les erreurs lors de l’activation et vérifiez que les ressources
health-azure-eventsont démarré correctement sur tous les nœuds de cluster.sudo pcs resource cleanupLa première exécution d'une requête pour des événements programmés peut prendre jusqu'à deux minutes. Les tests Pacemaker avec des événements planifiés peuvent utiliser des actions de redémarrage ou de redéploiement pour les machines virtuelles du cluster. Pour plus d’informations, consultez Événements planifiés.
Configuration d’isolation facultative
Conseil
Cette section s’applique uniquement si vous voulez configurer un appareil d’isolation spécial fence_kdump.
Si vous avez besoin de collecter des informations de diagnostic au sein de la machine virtuelle, il peut être utile de configurer un autre appareil d’isolation en fonction de l’agent d’isolationfence_kdump. L’agent fence_kdump peut détecter qu’un nœud est entré dans la récupération sur incident kdump et peut autoriser le service de récupération sur incident à se terminer, avant d’appeler d’autres méthodes d’isolation. Notez que fence_kdump ne remplace pas les mécanismes d’isolation traditionnels, tels que l’agent d’isolation Azure ou SBD lorsque vous utilisez des machines virtuelles Azure.
Important
Sachez que si fence_kdump est configuré en tant qu’appareil d’isolation de premier niveau, il entraîne des retards dans les opérations d’isolation et, respectivement, dans le basculement des ressources d’application.
Si une image mémoire après incident est correctement détectée, l’isolation sera retardée jusqu’à ce que le service de récupération sur incident se termine. Si le nœud défaillant est inaccessible ou s’il ne répond pas, l’isolation est retardée pour une durée déterminée, selon le nombre d’itérations configuré et le délai d’expiration fence_kdump. Pour plus d’informations, consultez Comment configurer fence_kdump dans un cluster Pacemaker Red Hat ?.
Il peut être nécessaire d’adapter le délai d’expiration de fence_kdump proposé à l’environnement spécifique.
Nous vous recommandons de configurer l’isolation fence_kdump uniquement quand cela est nécessaire pour collecter les diagnostics au sein de la machine virtuelle, et toujours en combinaison avec les méthodes d’isolation classiques, comme l’agent d’isolation Azure ou SBD.
Les articles issus des bases de connaissances Red Hat suivants contiennent des informations importantes sur la configuration de l’isolation fence_kdump :
- Consultez Comment configurer fence_kdump dans un cluster Pacemaker Red Hat ?.
- Consultez Guide pratique pour configurer/gérer les niveaux d’isolation dans un cluster RHEL avec Pacemaker.
- Consultez fence_kdump échoue avec « délai d’expiration après X secondes » dans un cluster à haute disponibilité RHEL 6 ou 7 avec kexec-tools antérieurs à 2.0.14.
- Pour plus d’informations sur la modification du délai d’expiration par défaut, consultez Comment configurer kdump pour une utilisation avec le module complémentaire à haute disponibilité RHEL 6, 7, 8 ?.
- Pour plus d’informations sur la réduction du délai de basculement lorsque vous utilisez
fence_kdump, consultez Puis-je réduire le délai attendu de basculement lors de l’ajout de la configuration fence_kdump ?.
Exécutez les étapes facultatives suivantes pour ajouter fence_kdump en tant que configuration d’isolation de premier niveau, en plus de la configuration de l’agent d’isolation Azure.
[A] Vérifiez que
kdumpest actif et configuré.systemctl is-active kdump # Expected result # active[A] Installez l’agent de clôture
fence_kdump.yum install fence-agents-kdump[1] Créez un appareil d’isolation
fence_kdumpdans le cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configurez les niveaux d’isolation pour que le mécanisme d’isolation
fence_kdumpsoit engagé en premier.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Autorisez les ports requis pour
fence_kdumpvia le pare-feu.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Effectuez la configuration
fence_kdump_nodesdans/etc/kdump.confafin d’éviter l’échec defence_kdumpen raison d'un délai d’attente pour certaines versionskexec-tools. Pour obtenir plus d’informations, consultez fence_kdump expire lorsque fence_kdump_nodes n’est pas spécifié avec kexec-tools version 2.0.15 ou ultérieure et fence_kdump échoue avec « délai d’expiration après X secondes » dans un cluster à haute disponibilité RHEL 6 ou 7 avec des versions de kexec-tools antérieures à 2.0.14. L’exemple de configuration pour un cluster à deux nœuds est présenté ici. Une fois vos modifications apportées dans/etc/kdump.conf, l’image kdump doit être régénérée. Pour régénérer, redémarrez le servicekdump.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Veillez à ce que le fichier d’images
initramfscontienne les fichiersfence_kdumpethosts. Pour plus d’informations, consultez Comment configurer fence_kdump dans un cluster Pacemaker Red Hat ?.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendTestez la configuration en bloquant un nœud. Pour plus d’informations, consultez Comment configurer fence_kdump dans un cluster Pacemaker Red Hat ?.
Important
Si le cluster est déjà utilisé en mode productif, planifiez le test en conséquence, car le blocage d’un nœud a un impact sur l’application.
echo c > /proc/sysrq-trigger
Étapes suivantes
- Consultez Planification et implémentation de machines virtuelles Azure pour SAP.
- Consultez Déploiement de machines virtuelles Azure pour SAP.
- Consultez Déploiement SGBD de machines virtuelles Azure pour SAP.
- Pour savoir comment établir une HA et planifier la récupération d’urgence de SAP HANA sur des machines virtuelles Azure, consultez Haute disponibilité de SAP HANA sur des machines virtuelles Azure.