Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le 📦 package Microsoft.Extensions.DataIngestion fournit des blocs de construction .NET fondamentaux pour l’ingestion de données. Cela permet aux développeurs de lire, de traiter et de préparer des documents pour les flux de travail d'IA et d'apprentissage automatique, en particulier les scénarios de génération augmentée par récupération (RAG).
Avec ces blocs de construction, vous pouvez créer des pipelines d’ingestion de données robustes, flexibles et intelligents adaptés aux besoins de votre application :
- Représentation unifiée du document : Représentez n’importe quel type de fichier (par exemple, PDF, Image ou Microsoft Word) dans un format cohérent qui fonctionne bien avec les modèles de langage volumineux.
- Ingestion de données flexibles : Lisez des documents à partir des services cloud et des sources locales à l’aide de plusieurs lecteurs intégrés, ce qui facilite l’apport de données à partir de l’endroit où elle réside.
- Améliorations intégrées de l’IA : Enrichissez automatiquement le contenu avec des résumés, une analyse des sentiments, une extraction de mots clés et une classification, en préparant vos données pour les flux de travail intelligents.
- Stratégies de segmentation personnalisables : Fractionnez des documents en blocs à l’aide d’approches basées sur des jetons, basées sur des sections ou sémantiques, afin de pouvoir optimiser vos besoins de récupération et d’analyse.
- Stockage prêt pour la production : Stockez les blocs traités dans les bases de données vectorielles populaires et les magasins de documents, avec prise en charge de la génération d'embeddings, rendant ainsi vos pipelines adaptés aux scénarios réels.
- Composition du pipeline de bout en bout : Chaînez des lecteurs, des processeurs, des segmenteurs et des enregistreurs avec l’API IngestionPipeline<T>, ce qui réduit la répétition de code et facilite la création, la personnalisation et l’extension de flux de travail complets.
- Performances et scalabilité : Conçus pour le traitement évolutif des données, ces composants peuvent gérer efficacement de grands volumes de données, ce qui les rend adaptés aux applications de niveau entreprise.
Tous ces composants sont ouverts et extensibles par conception. Vous pouvez ajouter une logique personnalisée et de nouveaux connecteurs et étendre le système pour prendre en charge les scénarios IA émergents. En standardisant la façon dont les documents sont représentés, traités et stockés, les développeurs .NET peuvent créer des pipelines de données fiables, évolutifs et gérables sans « réinventer la roue » pour chaque projet.
Construit sur des bases stables
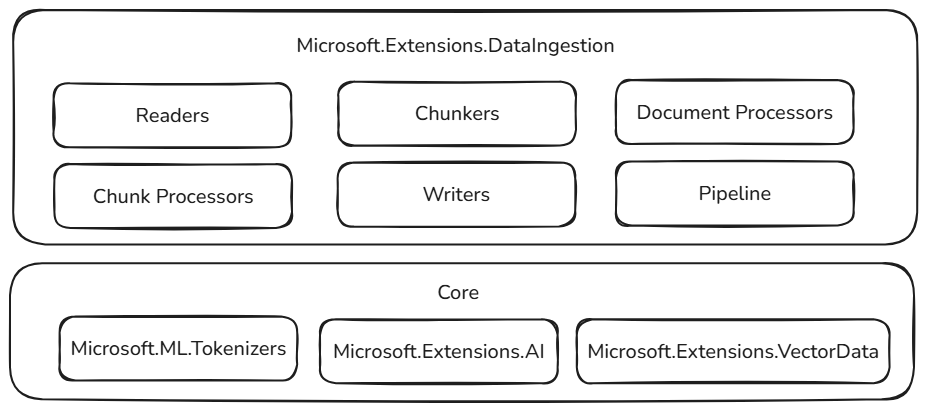
Ces blocs de construction d’ingestion de données sont basés sur des composants éprouvés et extensibles dans l’écosystème .NET, ce qui garantit la fiabilité, l’interopérabilité et l’intégration transparente aux flux de travail IA existants :
- Microsoft.ML.Tokenizers : Les tokenizers fournissent la base de la segmentation de documents basés sur des jetons. Cela permet un fractionnement précis du contenu, qui est essentiel pour la préparation des données pour les modèles de langage volumineux et l’optimisation des stratégies de récupération.
- Microsoft.Extensions.AI : Cet ensemble de bibliothèques alimente les transformations d’enrichissement à l’aide de modèles de langage volumineux. Il permet des fonctionnalités telles que la synthèse, l’analyse des sentiments, l’extraction de mots clés et la génération d’incorporation, ce qui facilite l’amélioration de vos données avec des insights intelligents.
- Microsoft.Extensions.VectorData : Cet ensemble de bibliothèques offre une interface cohérente pour stocker des blocs traités dans un large éventail de magasins vectoriels, notamment Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch, etc. Cela garantit que vos pipelines de données sont prêts pour la mise en production et peuvent être mis à l’échelle sur différents backends de stockage.
En plus des modèles et outils familiers, ces abstractions s’appuient sur des composants déjà extensibles. La fonctionnalité de plug-in et l’interopérabilité sont primordiales, de sorte que le reste de l’écosystème d’IA .NET augmente, les fonctionnalités des composants d’ingestion de données augmentent également. Cette approche permet aux développeurs d’intégrer facilement de nouveaux fournisseurs, enrichissements et options de stockage, en conservant leurs pipelines prêts à l’avenir et adaptables aux scénarios d’IA en évolution.
Voir aussi
Collaborer avec nous sur GitHub
La source de ce contenu se trouve sur GitHub, où vous pouvez également créer et examiner les problèmes et les demandes de tirage. Pour plus d’informations, consultez notre guide du contributeur.