Infrastructure Integration Runtime dans Azure Data Factory
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Le runtime d’intégration (IR) représente l’infrastructure de calcul utilisée par les pipelines Azure Data Factory et Azure Synapse pour fournir les capacités d’intégration de données suivantes dans différents environnements réseau :
- Flux de données : Exécutez un flux de données dans un environnement de calcul Azure géré.
- Déplacement des données : copiez des données entre des magasins de données dans des réseaux publics ou privés (pour des réseaux privés locaux ou virtuels). Les connecteurs intégrés, la conversion de format, le mappage de colonnes, ainsi que les transferts de données performants et évolutifs sont pris en charge par le service.
- Répartition des activités : répartit et analyse les activités de transformation exécutées sur un large éventail de services de calcul, tels qu’Azure Databricks, Azure HDInsight, ML Studio (classique), Azure SQL Database, SQL Server, etc.
- Exécution des packages SSIS : exécute en mode natif les packages SSIS (SQL Server Integration Services) dans un environnement Compute Azure managé.
Dans les pipelines Data Factory et Synapse, une activité définit l’action à effectuer. Un service lié désigne un magasin de données cible ou un service de calcul. Un runtime d’intégration permet de créer une passerelle entre les activités et les services liés. Il est référencé par l’activité ou le service lié, et fournit l’environnement Compute dans lequel l’activité s’exécute directement ou depuis lequel elle est envoyée. Cela permet d’effectuer l’activité dans la région la plus proche possible du magasin de données cible ou du service de calcul pour optimiser les performances tout en vous donnant plus de flexibilité pour répondre aux exigences de sécurité et de conformité.
Il est possible de créer des runtimes d’intégration dans l’interface utilisateur d’Azure Data Factory et d’Azure Synapse directement via le hub de gestion et via les activités, jeux de données ou flux de données qui y font référence.
Types de runtime d’intégration
Data Factory propose trois types de runtime d’intégration (IR). Vous devez choisir le type qui répond le mieux à vos besoins en matière de fonctionnalités d’intégration de données et d’environnement réseau. Les trois types de runtime d’intégration sont les suivants :
- Azure
- Auto-hébergé
- Azure-SSIS
Notes
Les pipelines Synapse ne prennent actuellement en charge que les runtimes d’intégration Azure ou auto-hébergés.
Le tableau suivant décrit les fonctionnalités et l’environnement réseau pour chaque type de runtime d’intégration :
| Type de runtime | Prise en charge du réseau public | Prise en charge de la liaison privée |
|---|---|---|
| Azure | Data Flow Déplacement des données Répartition des activités |
Data Flow Déplacement des données Répartition des activités |
| Auto-hébergé | Déplacement des données Répartition des activités |
Déplacement des données Répartition des activités |
| Azure-SSIS | Exécution de package SSIS | Exécution de package SSIS |
Notes
Les contrôles sortants varient selon le service pour Azure IR. Dans Synapse, les espaces de travail ont des options pour limiter le trafic sortant à partir du réseau virtuel managé lors de l’utilisation d’Azure IR. Dans Data Factory, tous les ports sont ouverts pour les communications sortantes lors de l’utilisation d’Azure IR. Azure-SSIS IR peut être intégré à votre réseau virtuel pour fournir des contrôles sur les communications sortantes.
Runtime d’intégration Azure
Un runtime d'intégration Azure peut :
- Exécuter des flux de données dans Azure
- Exécuter des activités de copie entre les magasins de données cloud
- Distribuez les activités de transformation suivantes dans un réseau public :
- Activité personnalisée .NET
- Activité de fonction Azure
- Activité Databricks Notebook/Jar/Python
- Activité U-SQL Data Lake Analytics
- Activité d’obtention des métadonnées
- Activité Hive HDInsight
- Activité Pig HDInsight
- Activité MapReduce HDInsight
- Activité HDInsight Spark
- Activité de diffusion en continu HDInsight
- Activité de recherche
- Activité d’exécution par lot Machine Learning Studio (classique)
- Activité de ressource de mise à jour Machine Learning Studio (classique)
- Activité de procédure stockée
- Activité de validation
- Activité web
Environnement réseau du runtime d'intégration Azure
L'infrastructure Azure Integration Runtime prend en charge les connexions aux magasins de données et aux services de calcul à l'aide de points de terminaison publiquement accessibles. En activant le réseau virtuel managé, Azure Integration Runtime prend en charge la connexion aux magasins de données à l’aide du service de liaison privée dans un environnement de réseau privé. Dans Synapse, les espaces de travail ont des options pour limiter le trafic sortant à partir du réseau virtuel managé IR. Dans Data Factory, tous les ports sont ouverts pour les communications sortantes. Azure-SSIS IR peut être intégré à votre réseau virtuel pour fournir des contrôles sur les communications sortantes.
Ressources de calcul et mise à l’échelle du runtime d'intégration Azure
Le runtime d’intégration Azure fournit une expérience de calcul entièrement gérée, sans serveur dans Azure. Vous n’avez plus à vous soucier de l’approvisionnement de l’infrastructure, de l’installation du logiciel, des mises à jour correctives ou de la mise à l’échelle des besoins. Par ailleurs, vous payez uniquement pour ce que vous utilisez.
Le runtime d’intégration Azure fournit le calcul natif pour déplacer des données entre les magasins de données cloud de manière sécurisée, fiable et efficace. Vous pouvez définir le nombre d’unités d’intégration des données à utiliser sur l’activité de copie. Ainsi, la taille de calcul du runtime d’intégration Azure est mise à l’échelle sans que vous deviez ajuster la taille du runtime d’intégration Azure.
La répartition des activités est une opération légère pour acheminer l’activité vers le service de calcul cible. Par conséquent, vous n’avez pas besoin de mettre la taille de calcul à l’échelle pour ce scénario.
Pour en savoir plus sur la création et la configuration d’un runtime d’intégration Azure, consultez la rubrique Guide pratique pour créer et configurer Azure Integration Runtime.
Notes
Le runtime d’intégration Azure possède des propriétés liées au runtime Data Flow, définissant l’infrastructure de calcul sous-jacente qui sera utilisée pour exécuter les flux de données.
Runtime d’intégration auto-hébergé
Un runtime d’intégration auto-hébergé peut :
- Exécuter une activité de copie entre des magasins de données cloud et un magasin de données situé sur un réseau privé.
- Répartir les activités de transformation suivantes selon les ressources de calcul dans le réseau local ou Azure :
- Activité de fonction Azure
- Activité personnalisée (s’exécute sur Azure Batch)
- Activité U-SQL Data Lake Analytics
- Activité d’obtention des métadonnées
- Activité Hive HDInsight (BYOC : apportez votre propre certificat)
- Activité Pig HDInsight (BYOC)
- Activité MapReduce HDInsight (BYOC)
- Activité Spark HDInsight (BYOC)
- Activité diffusion en continu HDInsight (BYOC)
- Activité de recherche
- Activité d’exécution par lot Machine Learning Studio (classique)
- Activité de ressource de mise à jour Machine Learning Studio (classique)
- Activité d’exécution des pipelines Machine Learning
- Activité de procédure stockée
- Activité de validation
- Activité web
Remarque
Utilisez le runtime d’intégration auto-hébergé pour prendre en charge les magasins de données qui nécessitent votre propre pilote, comme SAP Hana, MySQL, etc. Pour plus d’informations, consultez Magasins de données pris en charge.
Notes
Java Runtime Environment (JRE) est une dépendance de l’IR auto-hébergé. Vérifiez que vous avez installé JRE sur le même hôte.
Environnement réseau du runtime d'intégration auto-hébergé
Si vous souhaitez intégrer vos données en toute sécurité dans un environnement réseau privé sans visibilité directe depuis l’environnement de cloud public, vous pouvez installer un runtime d’intégration auto-hébergé dans l’environnement local derrière votre pare-feu, ou à l’intérieur d’un réseau privé virtuel. Le runtime d’intégration auto-hébergé établit uniquement des connexions HTTP sortantes pour l’accès à Internet.
Ressources de calcul et mise à l’échelle du runtime d'intégration auto-hébergé
Installez le runtime d’intégration auto-hébergé sur un ordinateur local ou sur une machine virtuelle située à l’intérieur d’un réseau privé. Actuellement, le runtime d’intégration auto-hébergé est pris en charge uniquement sur système d’exploitation Windows.
Pour obtenir un runtime d’intégration hautement disponible et évolutif, vous pouvez effectuer un scale-out du runtime d’intégration auto-hébergé en associant l’instance logique avec plusieurs ordinateurs locaux en mode actif/actif. Consultez l’article sur la Procédure de création et de configuration d’un IR auto-hébergé pour plus d’informations.
Runtime d’intégration Azure SSIS
Pour effectuer une opération lift-and-shift sur la charge de travail SSIS existante, vous pouvez créer un runtime d’intégration Azure SSIS pour exécuter les packages SSIS en mode natif.
Environnement réseau du runtime d'intégration Azure SSIS
Le runtime d’intégration Azure SSIS peut être configuré dans un réseau public ou un réseau privé. L’accès aux données sur site est pris en charge en associant le runtime d’intégration Azure SSIS à un réseau virtuel connecté à votre réseau local.
Ressources de calcul et mise à l’échelle du runtime d’intégration Azure SSIS
Le runtime d’intégration Azure SSIS est un cluster entièrement géré de machines virtuelles Azure qui est chargé d’exécuter vos packages SSIS. Vous pouvez utiliser votre propre base de données SQL Azure ou instance managée SQL pour le catalogue de projets/packages SSIS (SSISDB). Vous pouvez monter en puissance le calcul en spécifiant la taille du nœud et augmenter la taille des instances en spécifiant le nombre de nœuds du cluster. Vous pouvez maîtriser le coût d’exécution de votre runtime d’intégration Azure SSIS en l’arrêtant et en le démarrant comme vous le souhaitez.
Pour plus d’informations, voir Comment créer et configurer un runtime d’intégration Azure-SSIS. Une fois votre runtime d’intégration créé, vous pouvez déployer et gérer vos packages SSIS existants, sans changement ou presque, à l’aide des outils SQL Server Data Tools (SSDT) et SQL Server Management Studio (SSMS), comme si vous utilisez SSIS en local.
Pour plus d’informations sur le runtime Azure-SSIS, voir les articles suivants :
- Didacticiel : deploy SSIS packages to Azure (Déployer des packages SSIS vers Azure). Cet article fournit des instructions détaillées pour créer une instance Azure-SSIS Integration Runtime qui utilise une instance Azure SQL Database pour héberger le catalogue SSIS.
- Procédure : Créer un runtime d’intégration Azure-SSIS. Cet article s’appuie sur le tutoriel et fournit des instructions sur la façon d’utiliser une instance managée SQL et de joindre le runtime d’intégration à un réseau virtuel.
- Monitor an Azure-SSIS IR (Surveiller le runtime d’intégration Azure-SSIS). Cet article explique comment récupérer des informations sur un runtime d’intégration Azure-SSIS ainsi que des descriptions d’état dans les informations renvoyées.
- Manage an Azure-SSIS IR (Gérer un runtime d’intégration Azure-SSIS). Cet article vous explique comment arrêter, démarrer ou supprimer un runtime d’intégration Azure-SSIS. Il vous montre également comment effectuer un scale-out en lui ajoutant des nœuds supplémentaires.
- Joindre un runtime d’intégration Azure-SSIS à un réseau virtuel. Cet article fournit des informations conceptuelles sur la façon d’attacher un runtime d’intégration Azure-SSIS à un réseau virtuel Azure. Il fournit également les étapes permettant d’utiliser le portail Azure pour configurer un réseau virtuel et y joindre un Azure-SSIS Integration Runtime.
Emplacement du runtime d’intégration
Relation entre l’emplacement de la fabrique et l’emplacement du runtime d’intégration
Lorsque vous créez une instance Data Factory ou un espace de travail Synapse, vous devez spécifier son emplacement. Les métadonnées de l’instance sont stockées ici et le déclenchement du pipeline est initié à partir d’ici. Les métadonnées sont stockées uniquement dans la région choisie et ne sont pas stockées dans d’autres régions.
Un pipeline peut toutefois accéder à des magasins de données et à des services de calcul situés dans d’autres régions Azure pour déplacer des données entre des magasins de données ou pour traiter des données à l’aide des services de calcul. Ce comportement se réalise grâce au runtime d’intégration globalement disponible pour garantir la conformité des données et l’efficacité, et réduire les frais de sortie de réseau.
L’emplacement du runtime d’intégration définit l’emplacement de son calcul principal, mais aussi l’emplacement où le déplacement des données, la répartition des activités et l’exécution des packages SSIS sont effectués. L’emplacement du runtime d’intégration peut être différent de l’emplacement de la fabrique de données à laquelle il appartient.
Emplacement du runtime d'intégration Azure
Vous pouvez définir la région spécifique d’un Azure IR, auquel cas l’exécution ou la distribution d’activité se fera dans la région sélectionnée.
Le comportement par défaut est de résoudre automatiquement le runtime d’intégration Azure dans le réseau public. Avec cette option :
Pour l’activité de copie, tout est mis en œuvre pour détecter automatiquement l’emplacement de votre magasin de données récepteur, puis utiliser l’IR dans la même région si disponible ou dans région la plus proche dans la même zone géographique ; sinon, si la région du magasin de données récepteur ne peut pas être détectée, l’IR de la région de l’instance est utilisé à la place.
Par exemple, un espace de travail Data Factory ou Synapse dans la région USA Est,
- Lorsque vous copiez des données vers Azure Blob dans la région USA Ouest, si le blob est détecté dans la région USA Ouest, l’activité de copie est exécutée sur l’IR de cette région ; si la détection de la région échoue, l’activité de copie est exécutée sur l’IR de la région USA Est.
- Lorsque vous copiez des données vers Salesforce et que la région n’est pas détectable, l’activité de copie est exécutée sur l’IR de la région USA Est.
Conseil
Si vos exigences en termes de conformité des données sont strictes et que vous avez besoin de vous assurer que les données restent dans une certaine zone géographique, vous pouvez explicitement créer un runtime d’intégration Azure dans une région donnée et diriger le service lié vers ce runtime d’intégration via la propriété ConnectVia. Par exemple, si vous voulez copier des données depuis Blob dans la région Royaume-Uni Sud vers un espace de travail Azure Synapse dans la région Royaume-Uni Sud et souhaitez vous assurer que les données ne quittent pas le Royaume-Uni, créez un runtime d’intégration dans la région Royaume-Uni Sud et liez les deux services liés à ce runtime.
Pour l’exécution des activités Lookup/GetMetadata/Delete (activités Pipeline), la répartition des activités de transformation (activités External) et les opérations de création (tester la connexion, parcourir la liste des dossiers et des tables, prévisualiser les données), l’IR dans la même région que l’espace de travail Data Factory ou Synapse est utilisé.
Pour Data Flow, c’est l’IR de la région de l’espace de travail Data Factory ou Synapse qui est utilisé.
Conseil
Une meilleure pratique consiste à s’assurer que les flux de données s’exécutent dans la même région que vos magasins de données correspondants, dans la mesure du possible. Vous pouvez y parvenir soit en résolvant automatiquement Azure IR (si l’emplacement du magasin de données est le même que celui de l’espace de travail Data Factory ou Synapse), soit en créant une nouvelle instance Azure IR dans la même région que vos magasins de données, puis en exécutant le flux de données sur celle-ci.
Si vous activez le réseau virtuel managé pour la résolution automatique d’Azure IR, l’IR de la région de l’espace de travail Data Factory ou Synapse est utilisé.
Vous pouvez surveiller l’emplacement de runtime d’intégration utilisé lors de l’exécution de l’activité dans la vue Surveillance de l’activité du pipeline dans Data Factory Studio ou Synapse Studio, ou dans la charge utile Surveillance de l’activité.
Emplacement du runtime d’intégration auto-hébergé
Le runtime d’intégration auto-hébergé est logiquement inscrit auprès de l’espace de travail Data Factory ou Synapse, et il vous revient de fournir le calcul utilisé pour prendre en charge ses fonctionnalités. Par conséquent, il n’existe aucune propriété d’emplacement explicite pour le runtime d’intégration auto-hébergé.
Lorsqu’il est utilisé pour procéder au déplacement des données, le runtime d’intégration auto-hébergé extrait des données de la source et les écrit dans la destination.
Emplacement du runtime d’intégration Azure SSIS
Notes
Les runtimes d’intégration Azure-SSIS ne sont pas actuellement pris en charge dans les pipelines Synapse.
Le choix de l’emplacement pour votre runtime d’intégration Azure SSIS est essentiel pour parvenir à un niveau de performance élevé dans vos flux de travail ETL (extraction, transformation et chargement).
- L’emplacement de votre runtime d’intégration Azure-SSIS ne doit pas nécessairement être identique à l’emplacement de votre fabrique de données, mais il doit être le même que l’emplacement de votre base de données Azure SQL ou instance gérée SQL où se trouve SSISDB. De cette manière, le runtime d’intégration Azure SSIS peut facilement accéder au SSISDB sans être entravé par le trafic entre les différents emplacements.
- Si vous n’avez pas de base de données SQL ou d’instance managée SQL, mais que vous avez des sources/destinations de données locales, vous devez créer une base de données SQL Azure ou une instance managée SQL là où un réseau virtuel est connecté à votre réseau local. De cette façon, vous pouvez créer votre Azure-SSIS Integration Runtime à l’aide de la nouvelle instance managée ou Azure SQL Database, et joindre ce réseau virtuel. Tout se trouve au même emplacement, ce qui réduit les déplacements de données et les coûts associés, tout en optimisant les performances.
- Si l’emplacement de votre base de données SQL Azure ou instance managée SQL existante n’est pas le même que celui d’un réseau virtuel connecté à votre réseau local, créez d’abord votre runtime d’intégration Azure-SSIS en utilisant une base de données SQL Azure ou une instance managée SQL existante et en joignant un autre réseau virtuel situé au même emplacement. Ensuite, configurez un réseau virtuel sur une connexion de réseau virtuel entre les différents emplacements.
Le schéma suivant représente les paramètres d’emplacement de Data Factory et de ses runtimes d’intégration :
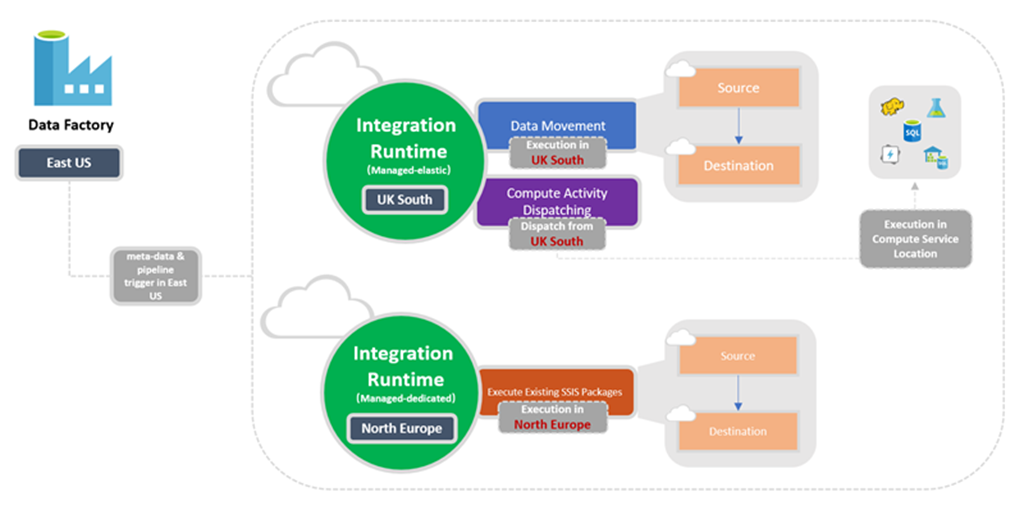
Choix du runtime d’intégration
Si une activité s’associe à plusieurs types de runtime d’intégration, elle se résout en l’un d’entre eux. Le runtime d’intégration auto-hébergé est prioritaire sur le runtime d’intégration Azure dans les instances d’espace de travail Data Factory ou Synapse qui utilisent un réseau virtuel managé. Et ce dernier est prioritaire sur le runtime d’intégration Azure global.
Par exemple, une activité de copie est utilisée pour copier des données de la source vers le récepteur. Le runtime d’intégration Azure global est associé au service lié à la source, et un runtime d’intégration Azure dans le réseau virtuel Azure Data Factory managé est associé au service lié au récepteur. Ainsi, la source et le service lié du récepteur utilisent le runtime d’intégration Azure dans le réseau virtuel Azure Data Factory managé. Mais si un runtime d’intégration auto-hébergé associe le service lié à la source, la source et le service lié du récepteur utilisent le runtime d’intégration auto-hébergé.
Activité de copie
Pour l’activité de copie, les services liés source et récepteur doivent être indiqués pour définir la direction du flux de données. La logique suivante est utilisée pour déterminer l’instance de runtime d’intégration qui effectue la copie :
- Copie entre deux sources de données cloud : lorsque les services liés source et récepteur utilisent tous deux Azure IR, le runtime d’intégration Azure IR régional est utilisé s’il a été spécifié, ou l’emplacement du runtime d’intégration Azure est automatiquement déterminé si l’option de runtime d’intégration à résolution automatique (par défaut) a été choisie comme décrit dans la section Emplacement du runtime d’intégration.
- Copie entre une source de données cloud et une source de données d’un réseau privé : si le service lié source ou récepteur pointe vers un runtime d’intégration auto-hébergé, l’activité de copie est exécutée sur ce runtime d’intégration.
- Copie entre deux sources de données d’un réseau privé : les services liés source et récepteur doivent tous deux pointer vers la même instance du runtime d’intégration. Ce runtime d’intégration est utilisé pour exécuter l’activité de copie.
Activité Lookup/GetMetadata
L’activité Lookup/GetMetadata est exécutée sur le runtime d'intégration associé au service lié de la banque de données.
Activité de transformation externe
Chaque activité de transformation externe qui utilise un moteur de calcul externe a un service de calcul cible lié qui pointe vers un runtime d’intégration. Cette instance du runtime d’intégration détermine l’emplacement à partir duquel l’activité de transformation externe codée manuellement est distribuée.
Activité Data Flow
Les activités Data Flow sont exécutées sur le runtime d’intégration Azure associé à celles-ci. Le calcul Spark utilisé par les flux de données est déterminé par les propriétés du flux de données dans votre Azure Integration Runtime et est entièrement géré par le service.
Runtime d’intégration pour l’intégration continue et la livraison continue
Les runtimes d’intégration ne changent pas souvent et sont similaires dans toutes les phases de CI/CD. Data Factory s’attend à ce que vous ayez le même nom et le même type de runtime d’intégration dans toutes les phases de CI/CD. Si vous voulez partager les runtimes d’intégration dans toutes les phases, envisagez d’utiliser une fabrique dédiée qui contiendra uniquement les runtimes d’intégration partagés. Vous pouvez alors utiliser cette fabrique partagée dans tous vos environnements en tant que type de runtime d’intégration lié.
Contenu connexe
Voir les articles suivants :
- Créer un runtime d’intégration Azure
- Créer un runtime d’intégration auto-hébergé
- Créer un runtime d’intégration Azure-SSIS. Cet article s’appuie sur le tutoriel et fournit des instructions sur la façon d’utiliser une instance managée SQL et de joindre le runtime d’intégration à un réseau virtuel.