Utiliser Azure Data Factory pour migrer des données d'un cluster Hadoop local vers le service Stockage Azure
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Factory fournit un mécanisme performant, robuste et économique pour migrer des données à grande échelle d'un système HDFS local vers le service Stockage Blob Azure ou Azure Data Lake Storage Gen2.
Data Factory propose deux approches de base pour la migration de données d'un système HDFS local vers Azure. Vous pouvez sélectionner l'approche en fonction de votre scénario.
- Mode Data Factory DistCp (recommandé) : dans Data Factory, vous pouvez utiliser le mode DistCp (copie distribuée) pour copier des fichiers tels quels sur le service Stockage Blob Azure (copie intermédiaire comprise) ou Azure Data Lake Store Gen2. Utilisez Data Factory intégré avec DistCp pour tirer parti d'un puissant cluster existant et obtenir le meilleur débit de copie. Vous bénéficiez également d'une planification flexible et d'une expérience de surveillance unifiée à partir de Data Factory. Selon la configuration de Data Factory, l'activité de copie construit automatiquement une commande DistCp, envoie les données à votre cluster Hadoop, puis surveille l'état de la copie. Nous recommandons le mode DistCp de Data Factory pour la migration de données d'un cluster Hadoop local vers Azure.
- Mode Runtime d’intégration native de Data Factory : DistCp ne s’applique pas à tous les scénarios. Par exemple, dans un environnement de Réseaux virtuels Azure, l'outil DistCp ne prend pas en charge le peering privé Azure ExpressRoute avec un point de terminaison de réseau virtuel Stockage Azure. En outre, dans certains cas, il est préférable de ne pas utiliser votre cluster Hadoop existant comme moteur pour la migration des données afin de ne pas surcharger votre cluster, car cela pourrait nuire aux performances des travaux ETL existants. Utilisez plutôt la fonctionnalité native du runtime d'intégration de Data Factory comme moteur pour copier les données du système HDFS local vers Azure.
Cet article fournit les informations suivantes sur les deux approches :
- Performances
- Résilience de copie
- Sécurité du réseau
- Architecture de solution de haut niveau
- Meilleures pratiques en matière d’implémentation
Performances
En mode DistCp de Data Factory, le débit est le même que si vous utilisiez l'outil DistCp indépendamment. Le mode DistCp de Data Factory optimise la capacité de votre cluster Hadoop existant. Vous pouvez utiliser DistCp pour une copie volumineuse inter ou intra-cluster.
DistCp utilise MapReduce pour sa distribution, pour la gestion et la récupération des erreurs, et pour la génération de rapports. Il développe une liste de fichiers et de répertoires en entrée pour le mappage des tâches. Chaque tâche copie une partition de fichiers spécifiée dans la liste source. Vous pouvez utiliser Data Factory intégré avec DistCp pour créer des pipelines afin d'exploiter pleinement la bande passante de votre réseau, ainsi que les IOPS et la bande passante de stockage dans le but d'optimiser le débit de déplacement des données de votre environnement.
Le mode Runtime d'intégration native de Data Factory permet également le parallélisme à différents niveaux. Vous pouvez utiliser le parallélisme pour exploiter pleinement votre bande passante réseau, ainsi que les IOPS et la bande passante de stockage afin d'optimiser le débit de déplacement des données :
- Une seule activité de copie peut tirer parti de plusieurs ressources de calcul évolutives. Avec un runtime d’intégration auto-hébergé, vous pouvez effectuer un scale-up manuel de la machine ou un scale-out vers plusieurs machines (jusqu’à quatre nœuds). Une activité de copie unique partitionne son ensemble de fichiers sur tous les nœuds.
- Une activité de copie unique lit et écrit dans le magasin de données à l'aide de plusieurs conversations.
- Le flux de contrôle Data Factory peut démarrer plusieurs activités de copie en parallèle. Par exemple, vous pouvez utiliser une boucle ForEach.
Pour plus d'informations, consultez le Guide de performance des activités de copie.
Résilience
En mode DistCp de Data Factory, vous pouvez utiliser différents paramètres de ligne de commande DistCp (par exemple, -i pour ignorer les échecs, ou -update pour écrire des données lorsque le fichier source et le fichier de destination sont de taille différente) afin d'atteindre différents niveaux de résilience.
En mode Runtime d'intégration native de Data Factory, lors de l'exécution d'une activité de copie unique, Data Factory dispose d'un mécanisme de nouvelle tentative intégré. Il peut gérer un certain niveau d'échecs passagers dans les magasins de données ou dans le réseau sous-jacent.
Lors d'une copie binaire d'un système HDFS local vers le service Stockage Blob et d'un système HDFS local vers Data Lake Store Gen2, Data Factory crée automatiquement des points de contrôle à grande échelle. Si l’exécution d’une activité de copie échoue ou expire, lors d’une nouvelle tentative (vérifiez que le nombre de nouvelles tentatives est > 1), la copie reprend à partir du dernier point d’échec au lieu de commencer depuis le début.
Sécurité du réseau
Par défaut, Data Factory transfère les données du système HDFS local vers le service Stockage Blob ou Azure Data Lake Storage Gen2 à l'aide d'une connexion chiffrée via le protocole HTTPS. Le protocole HTTPS assure le chiffrement des données en transit et empêche les écoutes clandestines et les attaques de l’intercepteur.
Si vous ne souhaitez pas que les données soient transférées sur l'Internet public, pour plus de sécurité, vous pouvez également les transférer sur un lien de peering privé via ExpressRoute.
Architecture de solution
Cette image illustre une migration de données via l'Internet public :
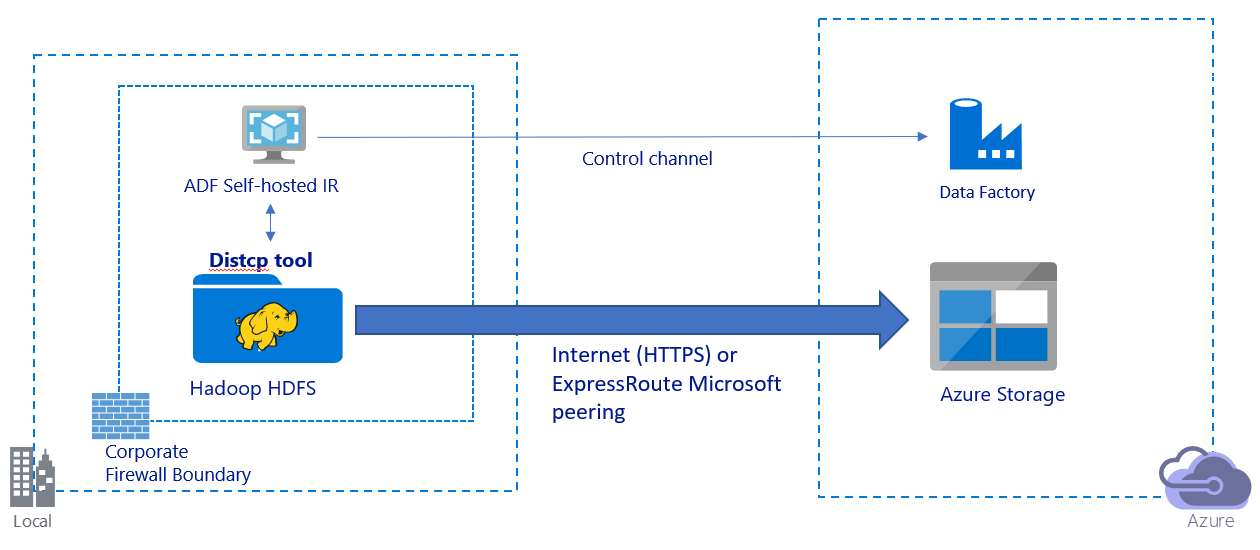
- Dans cette architecture, les données sont transférées en toute sécurité à l'aide du protocole HTTPS via l'Internet public.
- Dans un environnement de réseau public, nous vous recommandons d'utiliser le mode DistCp de Data Factory. Vous pouvez tirer parti d'un puissant cluster existant pour obtenir le meilleur débit de copie. Vous bénéficiez également d'une planification flexible et d'une expérience de surveillance unifiée à partir de Data Factory.
- Pour cette architecture, vous devez installer le runtime d'intégration auto-hébergé de Data Factory sur un ordinateur Windows derrière un pare-feu d'entreprise pour soumettre la commande DistCp à votre cluster Hadoop et surveiller l'état de la copie. Comme l'ordinateur n'est pas le moteur qui va déplacer les données (à des fins de contrôle uniquement), la capacité de la machine n'a aucun impact sur le débit du déplacement des données.
- Les paramètres existants de la commande DistCp sont pris en charge.
Cette image illustre une migration de données via un lien privé :
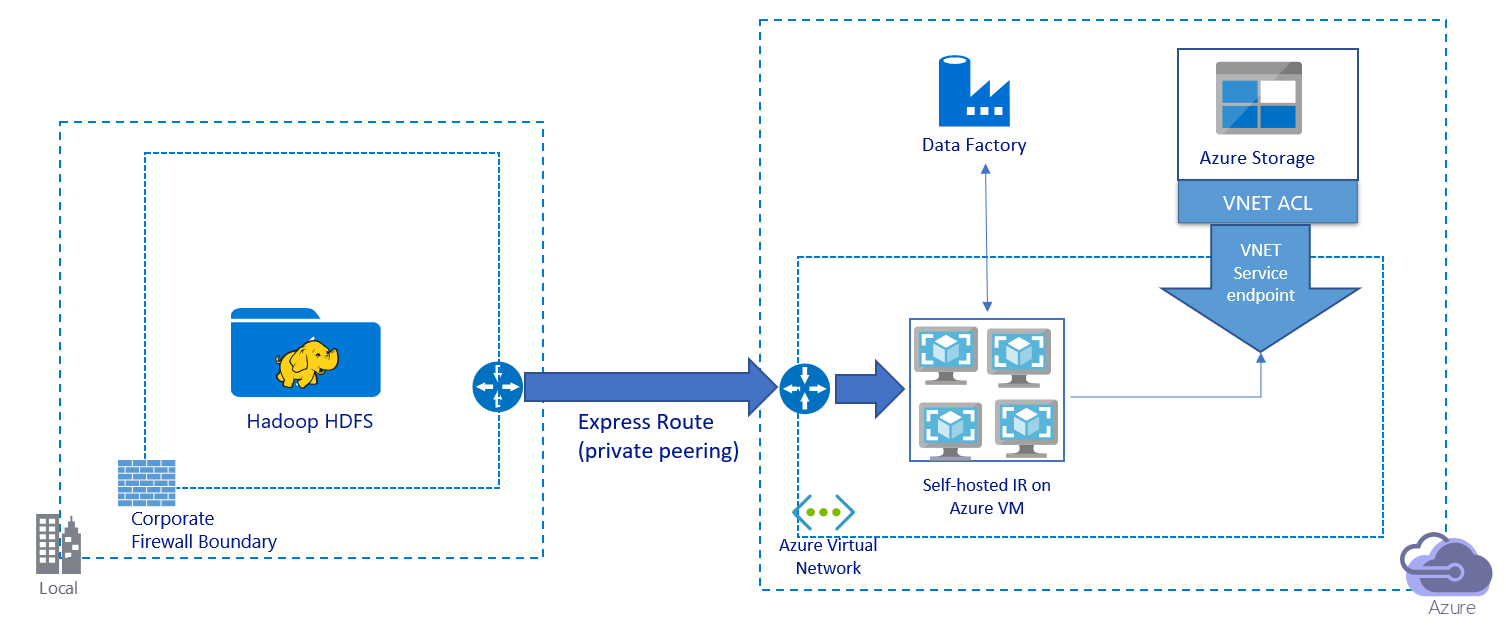
- Dans cette architecture, les données sont migrées sur un lien de peering privé via Azure ExpressRoute. Les données ne transitent jamais par l'Internet public.
- L'outil DistCp ne prend pas en charge le peering privé ExpressRoute avec un point de terminaison de réseau virtuel Stockage Azure. Nous vous recommandons d'utiliser la fonctionnalité native de Data Factory via le runtime d'intégration pour migrer les données.
- Pour cette architecture, vous devez installer le runtime d'intégration auto-hébergé de Data Factory sur une machine virtuelle Windows de votre réseau virtuel Azure. Vous pouvez procéder à une montée en puissance manuelle de vos machines virtuelles ou à une montée en charge sur plusieurs machines virtuelles pour utiliser pleinement votre réseau ainsi que vos IOPS ou votre bande passante de stockage.
- La configuration de démarrage recommandée pour chaque machine virtuelle Azure (avec le runtime d'intégration auto-hébergé de Data Factory installé) est Standard_D32s_v3 avec 32 processeurs virtuels et 128 Go de mémoire. Vous pouvez surveiller l'utilisation de l'UC et de la mémoire de la machine virtuelle pendant la migration des données afin de déterminer si vous devez monter en puissance pour améliorer les performances de la machine virtuelle ou descendre en puissance pour réduire les coûts.
- Vous pouvez également monter en charge en associant jusqu'à quatre nœuds de machine virtuelle à un seul runtime d'intégration auto-hébergé. Une seule tâche de copie exécutée sur un runtime d'intégration auto-hébergé partitionne automatiquement le jeu de fichiers et tire parti de tous les nœuds de machine virtuelle pour copier les fichiers en parallèle. Pour une haute disponibilité, nous vous recommandons de commencer avec deux nœuds de machine virtuelle afin d'éviter un scénario de point de défaillance unique pendant la migration des données.
- Lorsque vous utilisez cette architecture, la migration initiale des données d'instantané et la migration des données delta sont à votre disposition.
Meilleures pratiques en matière d’implémentation
Nous vous recommandons de suivre ces meilleures pratiques lors de l'implémentation de votre migration de données.
Authentification et gestion des informations d’identification
- Pour vous authentifier auprès de HDFS, vous pouvez utiliser Windows (Kerberos) ou Anonymous.
- Différents types d'authentification sont pris en charge pour la connexion au service Stockage Blob Azure. Nous vous recommandons vivement d'utiliser des identités managées pour les ressources Azure. Basées sur une identité Data Factory automatiquement managée dans Microsoft Entra ID, les identités managées vous permettent de configurer des pipelines sans fournir d'informations d'identification dans la définition du service lié. Vous pouvez également vous authentifier auprès du service Stockage Blob à l'aide du principal de service, d'une signature d'accès partagé ou d'une clé de compte de stockage.
- Différents types d'authentification sont également pris en charge pour la connexion à Azure Data Lake Storage Gen2. Nous vous recommandons vivement d'utiliser des identités managées pour les ressources Azure, mais vous pouvez aussi utiliser un principal de service ou une clé de compte de stockage.
- Lorsque vous n'utilisez pas d'identités managées pour les ressources Azure, nous vous recommandons vivement de stocker les informations d'identification dans Azure Key Vault pour faciliter la gestion centralisée et la rotation des clés sans modifier les services liés Azure Data Factory. Cette bonne pratique s'applique également à l'intégration/livraison continue (CI/CD).
Migration initiale des données d’instantané
En mode DistCp de Data Factory, vous pouvez créer une activité de copie pour soumettre la commande DistCp et utiliser différents paramètres pour contrôler le comportement initial de migration des données.
En mode Runtime d'intégration native de Data Factory, nous vous recommandons d'avoir recours à une partition de données, en particulier lorsque vous migrez plus de 10 To de données. Pour partitionner les données, utilisez les noms de dossier du système HDFS. Chaque travail de copie Data Factory peut ensuite copier une partition de dossiers à la fois. Vous pouvez exécuter plusieurs tâches de copie Data Factory simultanément pour un meilleur débit.
Si l'un des travaux de copie échoue en raison d'un problème temporaire de réseau ou de magasin de données, vous pouvez réexécuter ce travail afin de recharger la partition correspondante à partir du système HDFS. Les autres travaux de copie qui chargent d'autres partitions ne sont pas affectés.
Migration des données Delta
En mode DistCp de Data Factory, vous pouvez utiliser le paramètre de ligne de commande DistCp -update, afin d'écrire des données lorsque le fichier source et le fichier de destination sont de taille différente, pour la migration des données delta.
En mode d'intégration native de Data Factory, le moyen le plus efficace d'identifier les fichiers nouveaux ou modifiés à partir du système HDFS consiste à utiliser une convention d'affectation de noms partitionnée. Lorsque les données de votre système HDFS ont été partitionnées avec des informations de tranche temporelle dans le nom du fichier ou du dossier (par exemple, /aaaa/mm/jj/fichier.csv ), votre pipeline peut facilement identifier les fichiers et dossiers à copier de façon incrémentielle.
Sinon, si les données de votre système HDFS ne sont pas partitionnées, Data Factory peut identifier les fichiers nouveaux ou modifiés à l'aide de leur valeur LastModifiedDate. Data Factory analyse tous les fichiers du système HDFS et ne copie que les fichiers nouveaux et mis à jour dont l'horodatage correspondant à la dernière modification est supérieur à une valeur définie.
En présence d'un grand nombre de fichiers dans le système HDFS, l'analyse initiale des fichiers peut prendre beaucoup de temps, quel que soit le nombre de fichiers correspondant à la condition de filtre. Dans ce scénario, nous vous recommandons de commencer par partitionner les données avec la même partition que celle utilisée pour la migration initiale des instantanés. L'analyse des fichiers peut ensuite être effectuée en parallèle.
Estimation du prix
Considérez le pipeline suivant pour la migration de données du système HDFS vers le service Stockage Blob Azure :
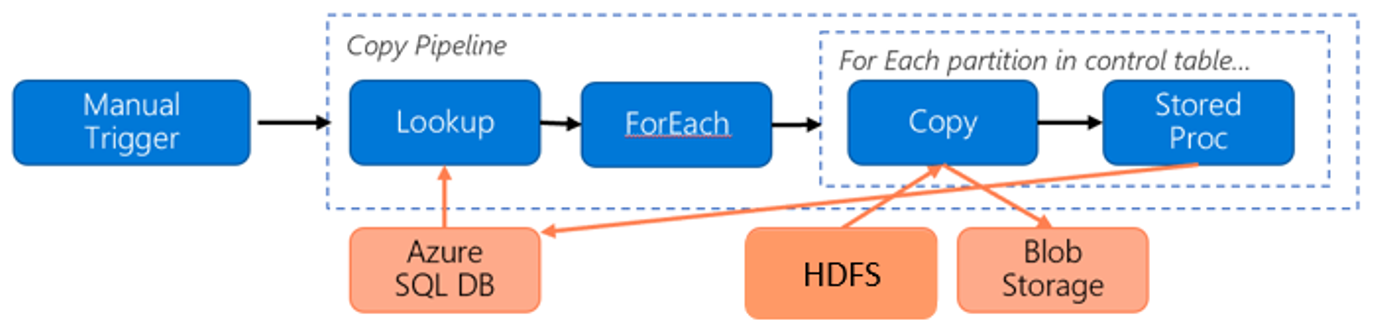
Basons-nous sur les informations suivantes :
- Le volume total de données est de 1 Po.
- Vous migrez des données à l'aide du mode Runtime d'intégration native de Data Factory.
- 1 Po est divisé en 1 000 partitions et chaque copie déplace une partition.
- Chaque activité de copie est configurée avec un runtime d'intégration auto-hébergé associé à quatre machines et atteignant un débit de 500 Mbits/s.
- L'accès concurrentiel ForEach est défini sur 4 et le débit agrégé est de 2 Gbits/s.
- Au total, la migration prend 146 heures.
Voici le prix estimé en fonction de nos hypothèses :
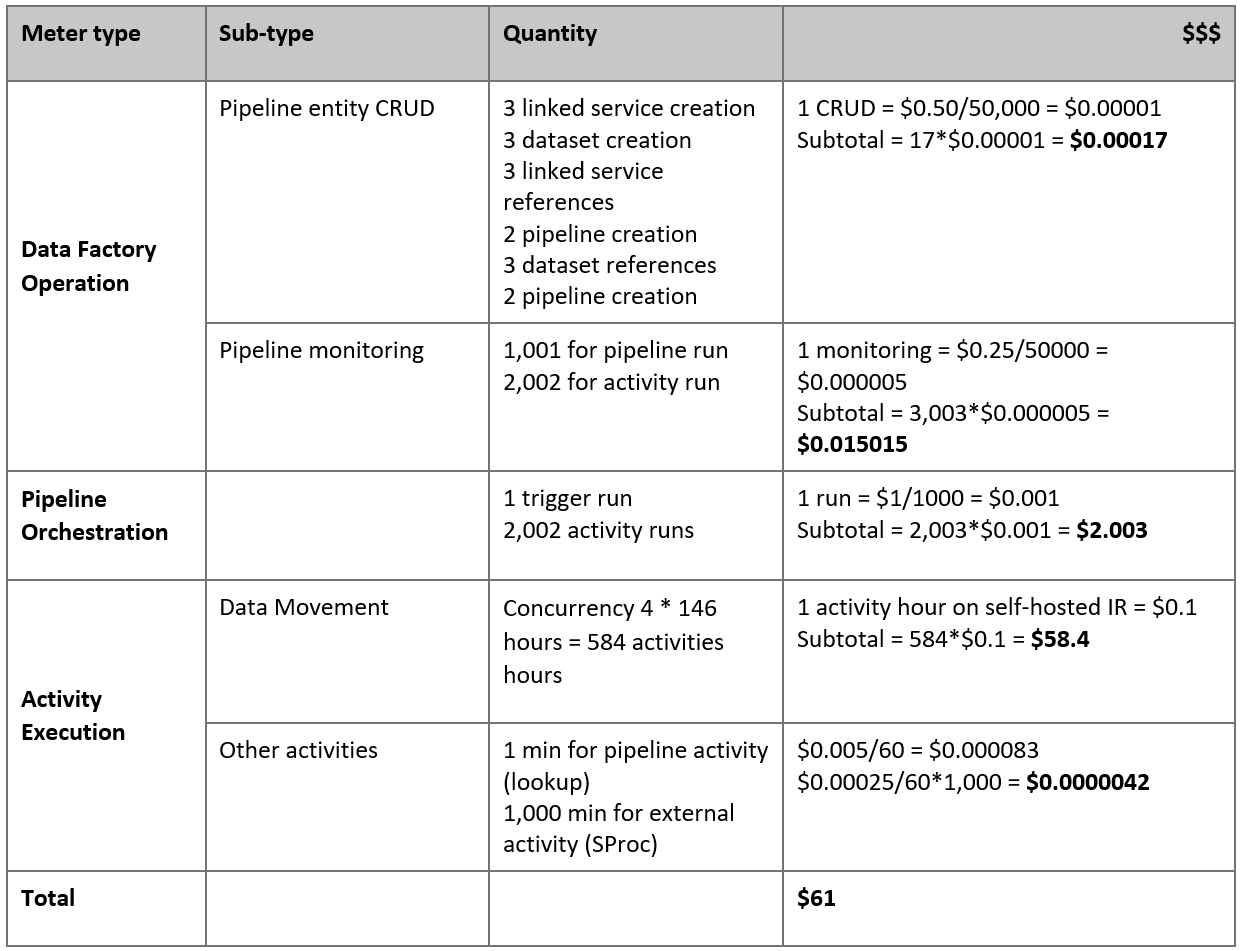
Remarque
Il s’agit d’un exemple de tarification hypothétique. Vos tarifs réels dépendent du débit réel dans votre environnement. Le prix d'une machine virtuelle Azure Windows (avec le runtime d'intégration auto-hébergé installé) n'est pas inclus.
Références supplémentaires
- Connecteur HDFS
- Connecteur de stockage Blob Azure
- Connecteur Azure Data Lake Storage Gen2
- Guide sur les performances et le réglage de l’activité de copie
- Créer et configurer un runtime d’intégration auto-hébergé
- Haute disponibilité et extensibilité du runtime d'intégration auto-hébergé
- Considérations relatives à la sécurité des déplacements de données
- Stocker les informations d’identification dans Azure Key Vault
- Copier un fichier de façon incrémentielle en fonction d'un nom de fichier partitionné
- Copier les fichiers nouveaux et modifiés basés sur LastModifiedDate
- Page des tarifs de Data Factory
Contenu connexe
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour