Qu’est-ce que le service de reconnaissance vocale ?
Le service Speech fournit des capacités de reconnaissance vocale et de synthèse vocale avec une ressource Speech. Vous pouvez transcrire la parole en texte avec une grande précision, produire des voix de synthèse vocale à la tonalité naturelle, traduire du contenu audio parlé et utiliser la reconnaissance de l’orateur pendant les conversations.

Créez des voix personnalisées, ajoutez des mots spécifiques à votre vocabulaire de base ou créez vos propres modèles. Exécutez Speech n’importe où, dans le cloud ou en périphérie dans des conteneurs. Vous pouvez aisément activer vos applications, outils et appareils pour les services Speech avec l’interface CLI Speech, le SDK Speech et les API REST.
Speech est disponible dans diverses langues, régions et gammes de prix.
Scénarios de reconnaissance vocale
Voici quelques scénarios courants de reconnaissance vocale :
- Sous-titrage : découvrez comment synchroniser les sous-titres avec le contenu audio en entrée, appliquer des filtres de vulgarité, obtenir des résultats partiels, appliquer des personnalisations et identifier les langues parlées pour les scénarios multilingues.
- Création de contenu audio : vous pouvez utiliser des voix neuronales pour rendre les interactions avec les chatbots et les assistants vocaux plus naturelles et plus agréables, pour convertir des textes numériques comme les livres électroniques en livres audio et pour améliorer les systèmes de navigation embarqués.
- Centre d’appels : transcrivez les appels en temps réel ou traitez les appels par lots, supprimez les informations d’identification personnelle et extrayez des insights comme le sentiment pour faciliter votre cas d’usage de centre d’appels.
- Apprentissage de la langue : fournir des commentaires d’évaluation de la prononciation aux apprenants de langue, prendre en charge la transcription en temps réel pour les conversations d’apprentissage à distance, et lire à voix haute des supports d’enseignement avec des voix neuronales.
- Assistants vocaux : Créez des interfaces conversationnelles naturelles et humaines pour leurs applications et leurs expériences. La fonctionnalité d’assistant vocal permet une interaction rapide et fiable entre un appareil et une implémentation d’assistant.
Microsoft utilise Speech pour de nombreux scénarios, tels que le sous-titrage dans Teams, la dictée dans Office 365 et Lire à haute voix dans le navigateur Microsoft Edge.
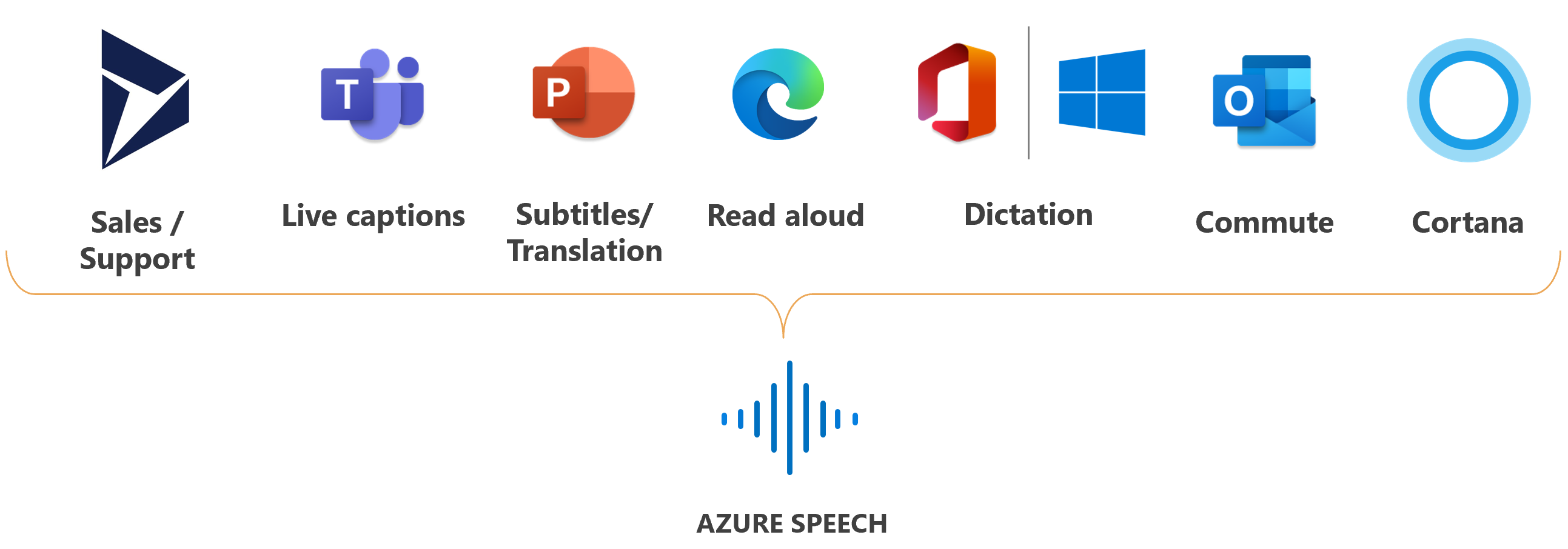
Fonctionnalités vocales
Ces sections résument les fonctionnalités de Speech et proposent des liens pour plus d’informations.
Reconnaissance vocale
Utilisez la reconnaissance vocale pour transcrire l’audio en texte, en temps réel ou de manière asynchrone avec la transcription par lots.
Conseil
Vous pouvez essayer la reconnaissance vocale en temps réel dans Speech Studio sans vous inscrire ni écrire de code.
Convertissez du contenu audio en texte à partir de diverses sources, notamment les microphones, les fichiers audio et le stockage d’objets blob. Utilisez la diarisation de l’orateur pour déterminer qui a dit quoi et quand. Obtenez des transcriptions lisibles avec mise en forme et ponctuation automatiques.
Le modèle de base peut s’avérer insuffisant si l’audio contient des bruits ambiants ou de nombreux jargons spécifiques à un secteur ou à un domaine d’activité. Dans ce cas, vous pouvez créer et entraîner des modèles vocaux personnalisés avec des données acoustiques, linguistiques et de prononciation. Les modèles vocaux personnalisés sont privés et peuvent offrir un avantage concurrentiel.
Reconnaissance vocale en temps réel
Avec la reconnaissance vocale en temps réel, l’audio est transcrit comme étant reconnu à partir d’un microphone ou d’un fichier. Utilisez la reconnaissance vocale en temps réel pour les applications qui doivent transcrire de l’audio en temps réel, par exemple :
- Transcriptions, légendes ou sous-titres pour les réunions en direct
- Diarisation
- Évaluation de la prononciation
- Les agents du centre d’appels vous assistent
- Dictation
- Agents vocaux
API de transcription rapide (préversion)
L’API de transcription rapide permet de transcrire des fichiers audio avec des résultats renvoyés de manière synchronisé et beaucoup plus rapide que l’audio en temps réel. Utilisez la transcription rapide dans les scénarios où vous avez besoin de la transcription d’un enregistrement audio le plus rapidement possible avec une latence prévisible, par exemple :
- Transcription audio ou vidéo rapide, sous-titres et modification.
- Traduction vidéo
Remarque
L’API de transcription rapide est disponible uniquement via l’API REST de reconnaissance vocale version 2024-05-15-preview.
Pour bien démarrer avec la transcription rapide, consultez utiliser l’API de transcription rapide (préversion).
Transcription Batch
La transcription par lots est utilisée pour la transcription d’importants volumes de données audio stockées. Vous pouvez pointer vers des fichiers audio à l’aide d’un URI de signature d’accès partagé (SAP) et recevoir les résultats de la transcription de manière asynchrone. Utilisez la transcription par lots pour les applications qui doivent transcrire de l’audio en grande quantité, par exemple :
- Transcriptions, sous-titres ou légendes pour les sons préenregistrés
- Analyse post-appel du centre de contacts
- Diarisation
Synthèse vocale
Avec la synthèse vocale, vous pouvez convertir un texte en une synthèse vocale semblable à celle d’un être humain. Utilisez des voix neurales, qui sont des voix humaines alimentées par des réseaux neuronaux profonds. Utilisez le langage SSML (Speech Synthesis Markup Language) pour ajuster la tonalité, la prononciation, le débit de parole, le volume et bien plus encore.
- Voix neuronale prédéfinie : voix prêtes à l’emploi très naturelles. Passez en revue les exemples de voix neuronales prédéfinies dans la Galerie de voix et déterminez celle qui répond le mieux à vos besoins métier.
- Voix neuronale personnalisée : Outre les voix neuronales prédéfinies, vous pouvez également créer une voix neuronale personnalisée, reconnaissable et propre à votre marque ou à votre produit. Les voix neuronales personnalisées sont privées et peuvent offrir un avantage concurrentiel. Passez en revue les exemples de voix neuronales personnalisées ici.
Traduction vocale
La traduction vocale permet à vos applications, outils et appareils d’effectuer de la traduction multilingue en temps réel de la parole. Utilisez cette fonctionnalité pour la traduction de voix en voix et de voix en texte.
Identification de la langue
L’identification de la langue sert à identifier les langues parlées dans du contenu audio par comparaison à la liste des langues prises en charge. Utilisez l’identification de langue seule, ou avec la reconnaissance vocale ou la traduction vocale.
Reconnaissance de l’orateur
La reconnaissance de l’orateur fournit des algorithmes qui vérifient et identifient les orateurs d’après leurs caractéristiques vocales uniques. Le service Reconnaissance de l’orateur est utilisé pour répondre à la question « qui parle ? ».
Évaluation de la prononciation
L’évaluation de la prononciation évalue la prononciation de la parole et fournit des indications aux orateurs sur la précision et la maîtrise du discours. Grâce à l’évaluation de la prononciation, les élèves qui apprennent des langues peuvent pratiquer, obtenir des commentaires instantanés et améliorer leur prononciation pour pouvoir parler et se présenter en toute confiance.
Reconnaissance de l’intention
Reconnaissance de l’intention : utilisez la reconnaissance vocale avec la compréhension du langage courant pour déduire les intentions de l’utilisateur à partir des transcriptions et agir sur des commandes vocales.
Livraison et présence
Vous pouvez déployer les fonctionnalités Azure AI Speech dans le cloud ou localement.
Avec des conteneurs, vous pouvez rapprocher le service de vos données pour favoriser la conformité, la sécurité ou pour d’autres raisons opérationnelles.
Le déploiement du service Speech dans les clouds souverains est possible pour certains organismes publics et leurs partenaires. Par exemple, le cloud Azure Government est disponible pour les organismes publics américains et leurs partenaires. Microsoft Azure géré par le cloud 21Vianet est accessible aux organisations ayant une présence commerciale en Chine. Pour plus d’informations, consultez Clouds souverains.
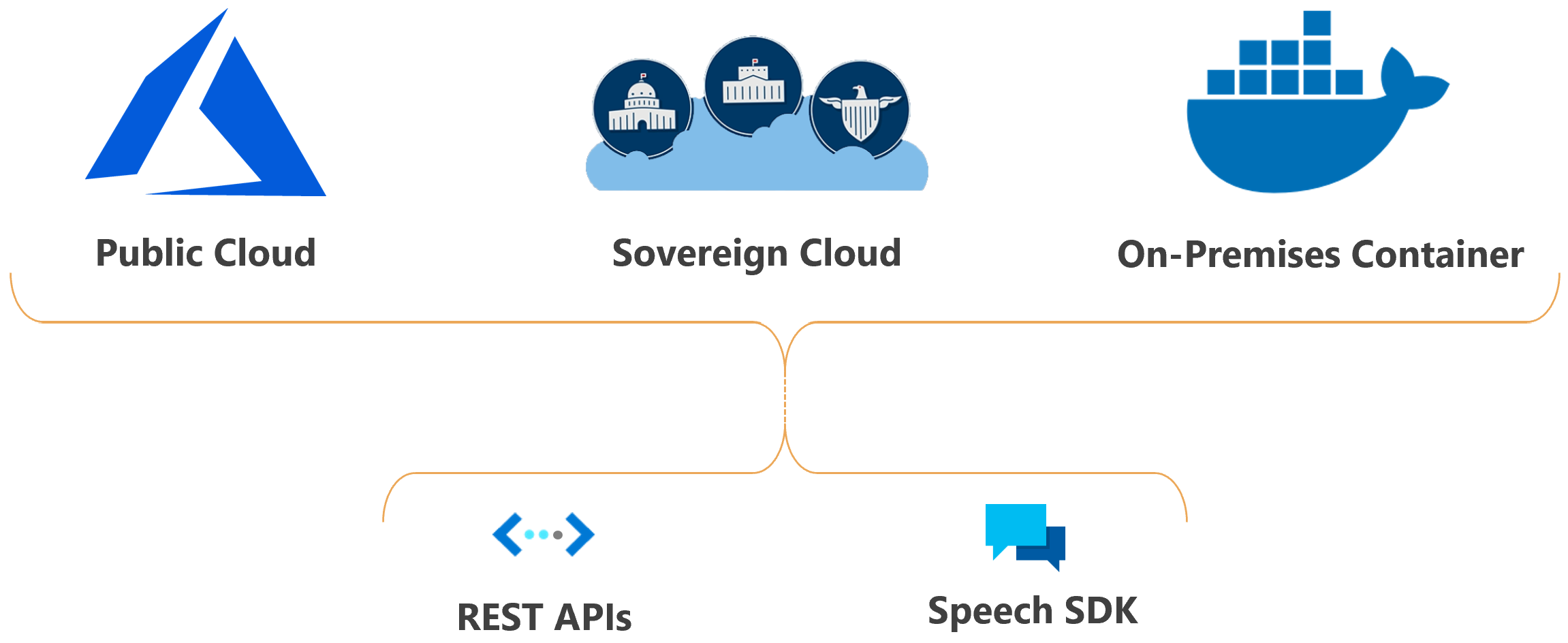
Utiliser Speech dans votre application
Speech Studio est un ensemble d’outils basés sur une interface utilisateur permettant de créer et d’intégrer des fonctionnalités du service Azure AI Speech dans vos applications. Vous créez des projets dans Speech Studio à l’aide d’une approche sans code, puis vous référencez les ressources que vous créez dans vos applications à l’aide du SDK Speech, de l’interface CLI Speech ou d’API REST.
L’interface CLI Speech est un outil en ligne de commande qui vous permet d’utiliser le service Speech sans avoir à écrire du code. La plupart des fonctionnalités fournies dans le SDK Speech sont disponibles dans l’interface CLI Speech, et certaines fonctionnalités avancées et personnalisations sont simplifiées dans l’interface CLI Speech.
Le kit SDK Speech expose les nombreuses capacités du service Speech dont vous pouvez vous servir pour développer des applications intégrant la reconnaissance vocale. Le kit de développement logiciel (SDK) Speech est disponible dans de nombreux langages de programmation et sur toutes les plateformes.
Dans certains cas, vous ne pouvez pas ou ne devez pas utiliser le kit SDK Speech. Dans ce cas, vous pouvez utiliser des API REST pour accéder au service Speech. Par exemple, vous pouvez utiliser des API REST pour la transcription par lots et des API REST pour la reconnaissance de l’orateur.
Prendre en main
Nous proposons des guides de démarrage rapide pour de nombreux langages de programmation très répandus. Chaque guide de démarrage rapide est conçu pour vous montrer des modèles de conception de base et vous permettre d’exécuter du code en moins de 10 minutes. Consultez la liste suivante pour connaître le guide de démarrage rapide de chaque fonctionnalité :
- Guide de démarrage rapide sur la reconnaissance vocale
- Démarrage rapide de la synthèse vocale
- Guide de démarrage rapide sur la traduction vocale
Exemples de code
Un exemple de code pour le service Speech est disponible sur GitHub. Ces exemples couvrent des scénarios courants tels que la lecture du signal audio d’un fichier ou d’un flux, la reconnaissance continue et ponctuelle, et l’utilisation de modèles personnalisés. Pour voir les exemples SDK et REST, suivez ces liens :
- Exemples de reconnaissance vocale, de synthèse vocale et de traduction vocale (SDK)
- Exemples de transcription par lot (REST)
- Exemples de synthèse vocale (REST)
- Exemples d’assistant vocal (Kit de développement logiciel [SDK])
IA responsable
Un système d’IA englobe non seulement la technologie, mais aussi ses utilisateurs, les personnes concernées et l’environnement dans lequel il est déployé. Lisez les notes de transparence pour en savoir plus sur l’utilisation et le déploiement d’une IA responsable dans vos systèmes.
Reconnaissance vocale
- Note de transparence et cas d’usage
- Caractéristiques et limitations
- Intégration et utilisation responsable
- Données, confidentialité et sécurité
Évaluation de la prononciation
Voix neuronale personnalisée
- Note de transparence et cas d’usage
- Caractéristiques et limitations
- Accès limité
- Déploiement responsable de la reconnaissance vocale synthétique
- Divulgation d’un talent vocal
- Guide de conception de la divulgation
- Modèles de conception de divulgation
- Code de conduite
- Données, confidentialité et sécurité
Reconnaissance de l’orateur
- Note de transparence et cas d’usage
- Caractéristiques et limitations
- Accès limité
- Recommandations générales
- Données, confidentialité et sécurité