Antimodèle de tempête de nouvelles tentatives
Lorsqu’un service est indisponible ou occupé, il peut avoir du mal à récupérer si les clients retentent de se connecter trop souvent. Cela peut même empirer le problème. Dans la mesure où les demandes ne sont généralement valides que pour une période de temps définie, retenter de se connecter indéfiniment ne sert à rien.
Description du problème
Dans le cloud, les services rencontrent parfois des problèmes et deviennent indisponibles pour les clients, ou doivent limiter le débit de leurs clients. Même s’il est tout à fait normal que les clients retentent de se connecter aux services quand la connexion a échoué, il est important qu’ils ne retentent pas trop fréquemment ni trop longtemps. Les nouvelles tentatives dans un laps de temps court n’aboutiront probablement pas, car les services risquent de ne pas avoir récupéré. De plus, les services peuvent être mis sous une plus grande pression quand de nombreuses tentatives de connexion sont effectuées alors qu’ils essaient de récupérer. Les tentatives de connexion répétées peuvent même saturer le service et empirer le problème sous-jacent.
L’exemple suivant illustre un scénario où un client se connecte à une API basée sur un serveur. Si la demande échoue, le client retente immédiatement sans discontinuer. Souvent, ce type de comportement est plus subtil que dans cet exemple, mais le même principe s’applique.
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
Comment corriger le problème
Les applications clientes doivent suivre certaines bonnes pratiques pour éviter de provoquer une tempête de nouvelles tentatives (« retry storm »).
- Limitez le nombre de nouvelles tentatives et ne retentez pas de vous connecter pendant une longue période de temps. Même s’il peut sembler facile d’écrire une boucle
while(true), vous ne voudrez certainement pas réessayer pendant une longue période de temps, car la situation ayant conduit à initier la demande aura probablement changé. Dans la plupart des applications, réessayer de se connecter pendant quelques secondes ou minutes suffit. - Faites une pause entre chaque nouvelle tentative. Si un service n’est pas disponible, retenter immédiatement a peu de chances d’aboutir. Allongez progressivement la durée d’attente entre les tentatives, par exemple à l’aide d’une stratégie de backoff exponentiel.
- Gérez correctement les erreurs. Si le service ne répond pas, déterminez s’il est logique d’abandonner la tentative et de retourner une erreur à l’utilisateur ou à l’appelant de votre composant. Tenez compte de ces scénarios d’échec lors de la conception de votre application.
- Envisagez d’utiliser le modèle Disjoncteur, conçu spécialement pour éviter les tempêtes de nouvelles tentatives.
- Si le serveur fournit un en-tête de réponse
retry-after, veillez à ne pas retenter de vous connecter tant que la durée spécifiée ne s’est pas écoulée. - Utilisez les kits SDK officiels pour communiquer avec les services Azure. Ces kits SDK ont généralement des stratégies de nouvelle tentative intégrées et des protections pour éviter de créer des tempêtes de nouvelles tentatives ou d’y contribuer. Si vous communiquez avec un service qui n’a pas de kit SDK, ou s’il en a un qui ne gère pas correctement la logique de nouvelle tentative, utilisez une bibliothèque comme Polly (pour .NET) ou retry (pour JavaScript) afin de gérer correctement votre logique de nouvelle tentative et éviter d’écrire le code vous-même.
- Si vous exécutez dans un environnement qui le prend en charge, utilisez un maillage de service (ou une autre couche d’abstraction) pour envoyer des appels sortants. En général, ces outils commeDapr prennent en charge les stratégies de nouvelle tentative et suivent automatiquement les bonnes pratiques telles que l’abandon après des tentatives répétées. Cette approche signifie que vous n’avez pas besoin d’écrire de code de nouvelle tentative vous-même.
- Pensez à traiter les demandes par lot et à utiliser le regroupement de demandes, le cas échéant. De nombreux kits SDK gèrent le traitement par lot des demandes et le regroupement de connexions à votre place, ce qui réduit le nombre total de tentatives de connexion sortante effectuées par votre application, même si vous devez quand même veiller à ne pas retenter ces connexions trop fréquemment.
Les services doivent également se protéger contre les tempêtes de nouvelles tentatives.
- Ajoutez une couche de passerelle afin de pouvoir fermer les connexions pendant un incident. Il s’agit d’un exemple de modèle de cloisonnement. Azure fournit de nombreux services de passerelle pour différents types de solutions, notamment Front Door, Application Gatewayet Gestion des API.
- Limitez les demandes au niveau de votre passerelle, ce qui vous permet de ne pas accepter un nombre de demandes qui empêcherait vos composants front-end de continuer à fonctionner.
- Si vous effectuez une limitation, renvoyez un en-tête
retry-afterpour aider les clients à comprendre quand retenter leurs connexions.
Considérations
- Les clients doivent prendre en compte le type d’erreur retourné. Certains types d’erreur n’indiquent pas l’échec du service, mais indiquent plutôt que le client a envoyé une demande non valide. Par exemple, si une application cliente reçoit une réponse d’erreur
400 Bad Request, toute nouvelle tentative de la même demande ne sera probablement pas utile, car le serveur vous dit que votre demande n’est pas valide. - Les clients doivent prendre en compte la durée qu’il est logique d’observer avant de retenter les connexions. Cette durée nécessaire avant une nouvelle tentative sera définie par les besoins de votre entreprise et vous déterminerez si vous pouvez raisonnablement retourner une erreur à l’utilisateur ou à l’appelant. Dans la plupart des applications, réessayer de se connecter pendant quelques secondes ou minutes suffit.
Comment détecter le problème
Du point de vue du client, les symptômes de ce problème peuvent inclure des temps de réponse ou de traitement très longs, ainsi qu’une télémétrie qui indique des nouvelles tentatives de connexion répétées.
Du point de vue du service, les symptômes de ce problème peuvent inclure un grand nombre de demandes d’un client dans un laps de temps court, ou un grand nombre de demandes d’un seul client lors d’une récupération suite à des pannes. Les symptômes peuvent également inclure des difficultés lors de la récupération du service, ou des défaillances en cascade du service immédiatement après la correction d’une erreur.
Exemple de diagnostic
Les sections suivantes illustrent une approche de détection d’une tempête de nouvelles tentatives potentielle, à la fois côté client et côté service.
Identification de la télémétrie du client
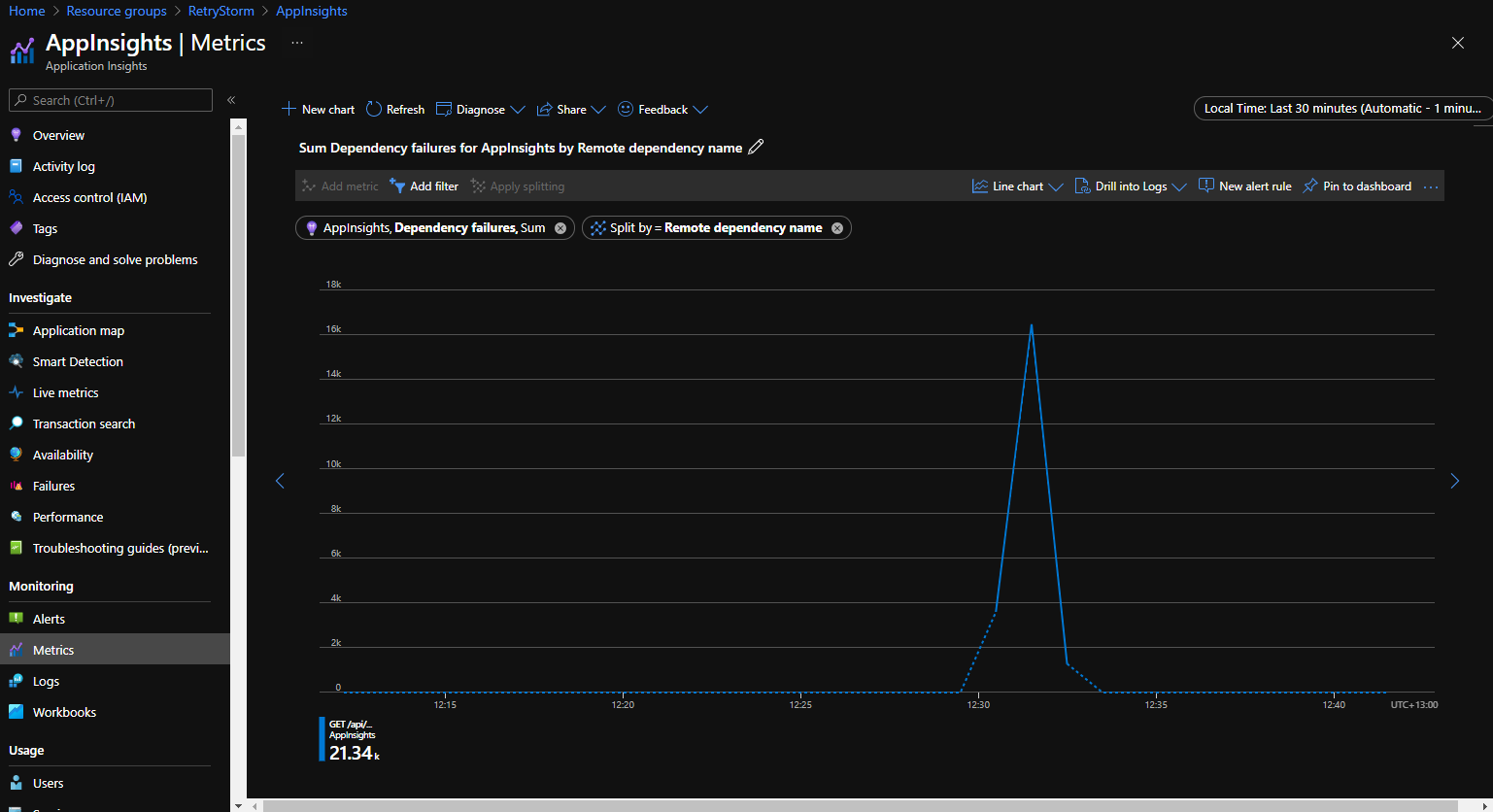
Azure application Insights enregistre la télémétrie des applications et met les données à disposition pour les interroger et les visualiser. Les connexions sortantes sont suivies en tant que dépendances, et les informations les concernant sont accessibles et peuvent être représentées sous forme graphique pour identifier quand un client effectue un grand nombre de demandes sortantes au même service.
Le graphique suivant a été extrait de l’onglet Métriques du portail Application Insights et montre la métrique Échecs de dépendance classés par Nom de dépendance distante. Cela illustre un scénario où un grand nombre (plus de 21 000) de tentatives de connexion à une dépendance ont échoué dans un laps de temps court.
Identification des la télémétrie du serveur
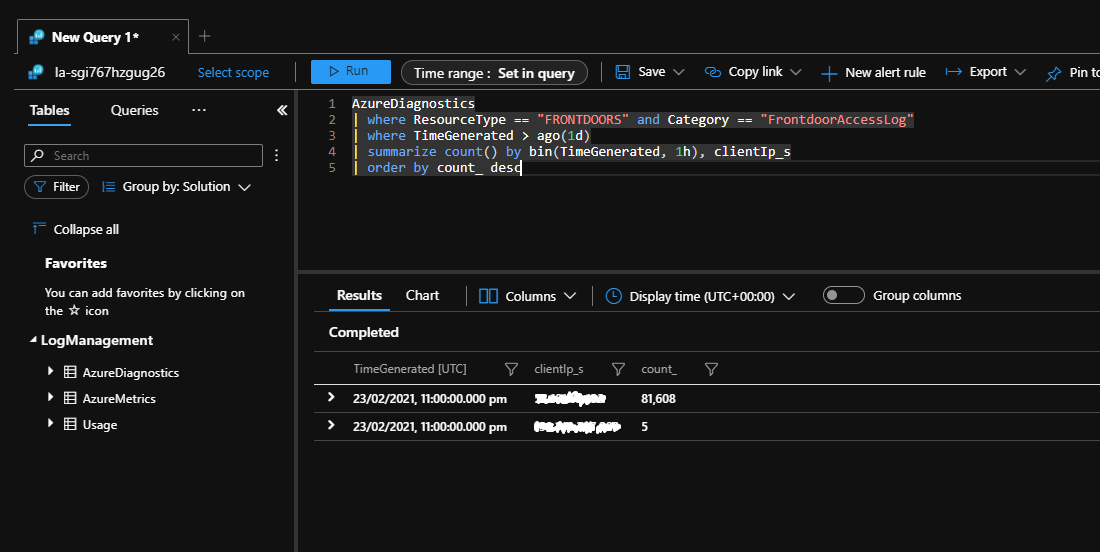
Les applications serveur peuvent être capables de détecter un grand nombre de connexions venant d’un seul client. Dans l’exemple suivant, Azure Front Door fait office de passerelle pour une application et a été configuré pour journaliser toutes les demandes dans un espace de travail Log Analytics.
La requête Kusto suivante peut être exécutée sur Log Analytics. Elle identifie les adresses IP du client qui ont envoyé un grand nombre de demandes à l’application le dernier jour.
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
L’exécution de cette requête lors d’une tempête de nouvelles tentatives montre un grand nombre de tentatives de connexion à partir d’une seule adresse IP.
Ressources associées
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour