Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Le modèle bulkhead est un type de conception d’application qui est tolérant à l’échec. Dans une architecture en bloc, également appelée architecture basée sur des cellules, les éléments d’une application sont isolés dans des pools afin qu’en cas d’échec, les autres éléments continuent de fonctionner. Le modèle de cloisonnement est nommé après les partitions sectionées (cloisons) de la coque d’un navire. Si la coque d’un navire subit une avarie, seule la section endommagée se remplit d’eau, empêchant ainsi le navire de couler.
Contexte et problème
Une application basée sur le cloud peut inclure plusieurs services, et chaque service a un ou plusieurs consommateurs. Une charge ou une défaillance excessive dans un service affecte tous les consommateurs du service.
En outre, un consommateur peut envoyer des demandes à plusieurs services simultanément et utiliser des ressources pour chaque requête. Lorsque le consommateur envoie une demande à un service mal configuré ou non répond, les ressources utilisées par la demande du client peuvent rester indisponibles pendant une période prolongée. À mesure que les demandes adressées au service continuent, ces ressources peuvent être épuisées. Par exemple, le pool de connexions du client peut être épuisé. À ce stade, les demandes du consommateur adressées à d’autres services sont affectées. Finalement, le consommateur ne peut pas envoyer de demandes à d'autres services, pas seulement au service non réactif d'origine.
L’épuisement des ressources affecte les services qui ont plusieurs consommateurs. De nombreuses demandes d’un client peuvent épuiser les ressources disponibles dans le service. L’épuisement des ressources peut signifier que d’autres consommateurs ne peuvent pas consommer le service, ce qui provoque un effet d’échec en cascade.
Solution
Partitionner des instances de service dans différents groupes en fonction des exigences de charge et de disponibilité du consommateur. Cette conception permet d’isoler les défaillances. Vous pouvez maintenir les fonctionnalités de service pour certains consommateurs, même lors d’une défaillance.
Un consommateur peut également partitionner des ressources pour s’assurer que les ressources utilisées pour appeler un service n’affectent pas les ressources utilisées pour appeler un autre service. Par exemple, un consommateur qui appelle plusieurs services peut être affecté à un pool de connexions pour chaque service. Si un service commence à échouer, il affecte uniquement le pool de connexions affecté pour ce service. Le consommateur peut continuer à utiliser d’autres services.
Ce modèle permet de bénéficier des avantages suivants :
Les consommateurs et les services sont isolés des défaillances en cascade. Un problème qui affecte un consommateur ou un service peut être isolé dans sa propre cloison pour empêcher l’ensemble de la solution d’échouer.
Conserve certaines fonctionnalités si une défaillance de service se produit. D’autres services et fonctionnalités de l’application continuent de fonctionner.
Fournit différents niveaux de qualité de service pour les applications consommatrices. Vous pouvez configurer un pool de consommateurs à priorité élevée pour utiliser des services à priorité élevée.
Le diagramme ci-après illustre des cloisons structurées autour de pools de connexions qui appellent des services individuels. Si le service A échoue ou provoque un problème, le pool de connexions est isolé. Par conséquent, seules les charges de travail qui utilisent le pool de threads attribué au service A sont affectées. Les charges de travail qui utilisent service B et C ne sont pas affectées et peuvent continuer à fonctionner sans interruption.
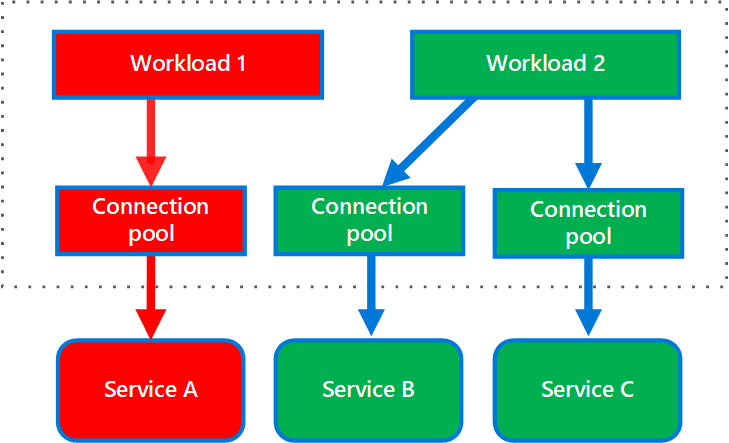
Diagramme montrant deux charges de travail, la charge de travail 1 et la charge de travail 2 et trois services, Service A, Service B et Service C. La charge de travail 1 utilise un pool de connexions affecté au service A. La charge de travail 2 utilise deux pools de connexions. Un pool de connexions est affecté au service B, et l’autre est affecté au service C. Le pool de connexions que la charge de travail 1 utilise est isolé. Les pools de connexions que la charge de travail 2 utilise peuvent continuer à appeler le service B et le service C.
Le diagramme suivant montre plusieurs clients qui appellent un seul service. Chaque client est affecté à une instance de service distincte. Le client 1 effectue trop de requêtes et surcharge son instance. Étant donné que chaque instance de service est isolée des autres, les autres clients peuvent continuer à effectuer des appels.
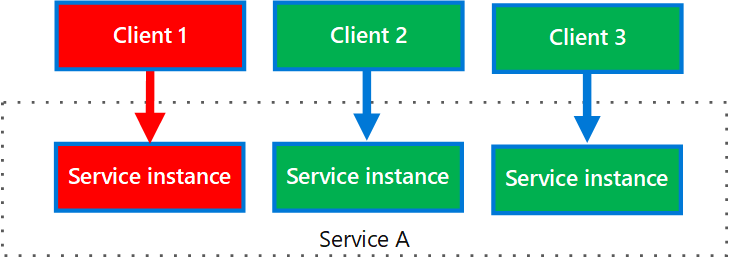
Diagramme montrant trois clients, Client 1, Client 2 et Client 3, et trois instances de service qui forment chacune une partie du service A. Chaque client se connecte à sa propre instance de service. Les instances de service sont isolées. Si le client 1 surcharge son instance, les clients 2 et 3 ne sont pas affectés.
Problèmes et considérations
Tenez compte des points suivants lorsque vous décidez comment implémenter ce modèle :
Définissez des partitions basées sur les exigences métiers et techniques de l’application.
Si vous utilisez une conception basée sur un domaine tactique pour concevoir des microservices, les limites de partition doivent s’aligner sur les contextes délimités.
Lorsque vous partitionnez des services ou des consommateurs en cloisonnements, tenez compte du niveau d’isolation offert par la technologie et de la surcharge en termes de coût, de performances et de facilité de gestion.
Pour fournir une gestion des pannes plus sophistiquée, envisagez de combiner des cloisonnements avec des nouvelles tentatives, un disjoncteur et des modèles de limitation.
Lorsque vous divisez les consommateurs en partitions, envisagez d’utiliser des processus, des pools de threads et des sémaphores. Les projets tels que resilience4j et Polly offrent une infrastructure pour la création de cloisons de consommateurs.
Lorsque vous partitionnez des services en têtes de bloc, envisagez de les déployer dans des machines virtuelles, des conteneurs ou des processus distincts. Les conteneurs offrent un bon niveau d’isolation des ressources pour un coût relativement faible.
Les services qui communiquent à l’aide de messages asynchrones peuvent être isolés via différents ensembles de files d’attente. Chaque file d’attente peut avoir un ensemble dédié d’instances qui traitent des messages sur la file d’attente ou un seul groupe d’instances qui utilisent un algorithme pour retirer de la file d’attente et lancer le traitement.
Déterminez le niveau de granularité des cloisons. Par exemple, si vous souhaitez distribuer des locataires entre des partitions, vous pouvez placer chaque locataire dans une partition distincte ou placer plusieurs locataires dans une seule partition.
Surveillez les performances de chaque partition et le contrat de niveau de service (SLA).
Utilisez des contrôles de plateforme intégrés, tels que les limites de taux de gestion des API Azure, l’isolation de l’unité de requête Azure Cosmos DB et les limites de ressources dans Azure Kubernetes Service (AKS) ou Azure Container Apps. Ne recréez pas ces mécanismes de limitation et d’isolation dans votre code d’application.
Les charges de travail IA et d’inférence nécessitent souvent des cloisonnements stricts en raison de quotas au niveau du déploiement et de limites d’accès concurrentiel, par exemple, l’isolation des déploiements Azure OpenAI par charge de travail ou par locataire.
Quand utiliser ce modèle
Utilisez ce modèle dans les situations suivantes :
- Vous souhaitez isoler les ressources pour des dépendances spécifiques afin qu’une interruption dans un service n’affecte pas l’ensemble de l’application.
- Vous souhaitez isoler les consommateurs critiques des consommateurs standard.
- Vous devez protéger l’application contre les défaillances en cascade.
Ce modèle peut ne pas convenir lorsque :
- L’utilisation moins efficace des ressources peut ne pas être acceptable dans le projet.
- La complexité ajoutée n’est pas nécessaire.
Conception de la charge de travail
Évaluez comment utiliser le modèle Bulkhead dans la conception d’une charge de travail pour répondre aux objectifs et aux principes couverts par les piliers du cadre Azure Well-Architected. Le tableau suivant fournit des conseils sur la façon dont ce modèle prend en charge les objectifs de chaque pilier.
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions de conception de fiabilité aident votre charge de travail à devenir résiliente au dysfonctionnement et à s’assurer qu’elle se rétablit dans un état entièrement opérationnel après une défaillance. | La stratégie d’isolation des défaillances introduite par le biais de la segmentation intentionnelle et complète entre les composants tente de contenir des erreurs dans la cloison qui rencontre le problème, ce qui empêche l’impact sur d’autres cloisons. - RE :02 Flux critiques - RE :07 Autopréservation |
| Les décisions relatives à la conception de la sécurité permettent de garantir la confidentialité, l’intégrité et la disponibilité des données et des systèmes de votre charge de travail. | La segmentation entre les composants permet de limiter les incidents de sécurité au cloisonnement compromis. - SE :04 Segmentation |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes par le biais d’optimisations de la mise à l’échelle, des données et du code. | Chaque cloisonnement peut être évolutif individuellement pour répondre efficacement aux besoins de la tâche qui y est encapsulée. - PE :02 Planification de la capacité - PE :05 Mise à l’échelle et partitionnement |
Si ce modèle introduit des compromis au sein d’un pilier, considérez-les contre les objectifs des autres piliers.
Exemple
Le fichier de configuration Kubernetes ci-après crée un conteneur isolé pour l’exécution d’un seul service, doté de ses propres ressources et limites d’UC et de mémoire.
apiVersion: v1
kind: Pod
metadata:
name: drone-management
spec:
containers:
- name: drone-management-container
image: drone-service
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "1"
Étapes suivantes
- Utilisez des stratégies de limite de débit gestion des API pour contrôler le débit des demandes par client.
- Utilisez des contrôles d’accès concurrentiel Azure Functions pour limiter les exécutions parallèles.
- Définissez les limites de ressources Container Apps pour contrôler l’UC et la mémoire par charge de travail.
- Attribuez le débit RU de Azure Cosmos DB par conteneur pour une isolation prévisible.