Le traitement du langage naturel (NLP, Natural Language Processing) a de nombreuses utilisations : l’analyse des sentiments, la détection de thèmes, la détection de la langue, l’extraction d’expressions clés et la classification des documents.
Plus précisément, vous pouvez utiliser NLP pour :
- Classifier des documents. Par exemple, vous pouvez étiqueter des documents comme sensibles ou indésirables.
- Effectuer un traitement ou des recherches ultérieurs. Vous pouvez utiliser la sortie NLP à ces fins.
- Résumer un texte en identifiant les entités présentes dans le document.
- Étiqueter des documents avec des mots clés. Pour les mots clés, NLP peut utiliser des entités identifiées.
- Effectuer une recherche et une récupération basées sur le contenu. L’étiquetage rend cette fonctionnalité possible.
- Résumer les thèmes importants d’un document. NLP peut combiner des entités identifiées en thèmes.
- Catégoriser des documents pour la navigation. Pour cela, NLP utilise les thèmes détectés.
- Énumérer les documents qui se rapportent à un thème sélectionné. Pour cela, NLP utilise les thèmes détectés.
- Attribuer un score à un texte pour les sentiments. En utilisant cette fonctionnalité, vous pouvez évaluer le ton positif ou négatif d’un document.
Apache®, Apache Spark et le logo représentant une flamme sont soit des marques déposées, soit des marques commerciales d’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Cas d’usage potentiels
Les scénarios métier qui peuvent tirer parti du NLP personnalisé sont les suivants :
- Intelligence documentaire pour les documents manuscrits ou créés par des machines dans les secteurs de la finance, de la santé, de la distribution, de l’administration et d’autres.
- Tâches NLP indépendantes du secteur pour le traitement du texte, telles que la reconnaissance d’entités nommées, la classification, le résumé et l’extraction de relations. Ces tâches automatisent le processus de récupération, d’identification et d’analyse des informations des documents, comme le texte et les données non structurées. Les modèles de stratification des risques, la classification d’ontologie et les résumés de ventes sont des exemples de ces tâches.
- Récupération des informations et création de graphes de connaissances pour la recherche sémantique. Cette fonctionnalité permet de créer des graphiques de connaissances médicales qui sont utiles pour la découverte de médicaments et les essais cliniques.
- Traduction de texte pour les systèmes d’IA conversationnelle dans les applications orientées client dans les secteurs de la distribution, de la finance, du tourisme et d’autres.
Apache Spark en tant que framework NLP personnalisé
Apache Spark est un framework de traitement parallèle qui prend en charge le traitement en mémoire pour améliorer les performances des applications d’analytique du Big Data. Azure Synapse Analytics, Azure HDInsight et Azure Databricks offrent un accès à Spark et tirent parti de sa puissance de traitement.
Pour les charges de travail NLP personnalisées, le traitement du langage naturel Spark sert de framework efficace pour le traitement d’une grande quantité de textes. Cette bibliothèque NLP open source contient des bibliothèques Python, Java et Scala qui offrent toutes les fonctionnalités des bibliothèques NLP traditionnelles, comme spaCy, NLTK, Stanford CoreNLP et Open NLP. Spark NLP offre aussi des fonctionnalités comme la vérification orthographique, l’analyse des sentiments et la classification de documents. Spark NLP améliore les efforts précédents en fournissant une justesse, une vitesse et une scalabilité de pointe.
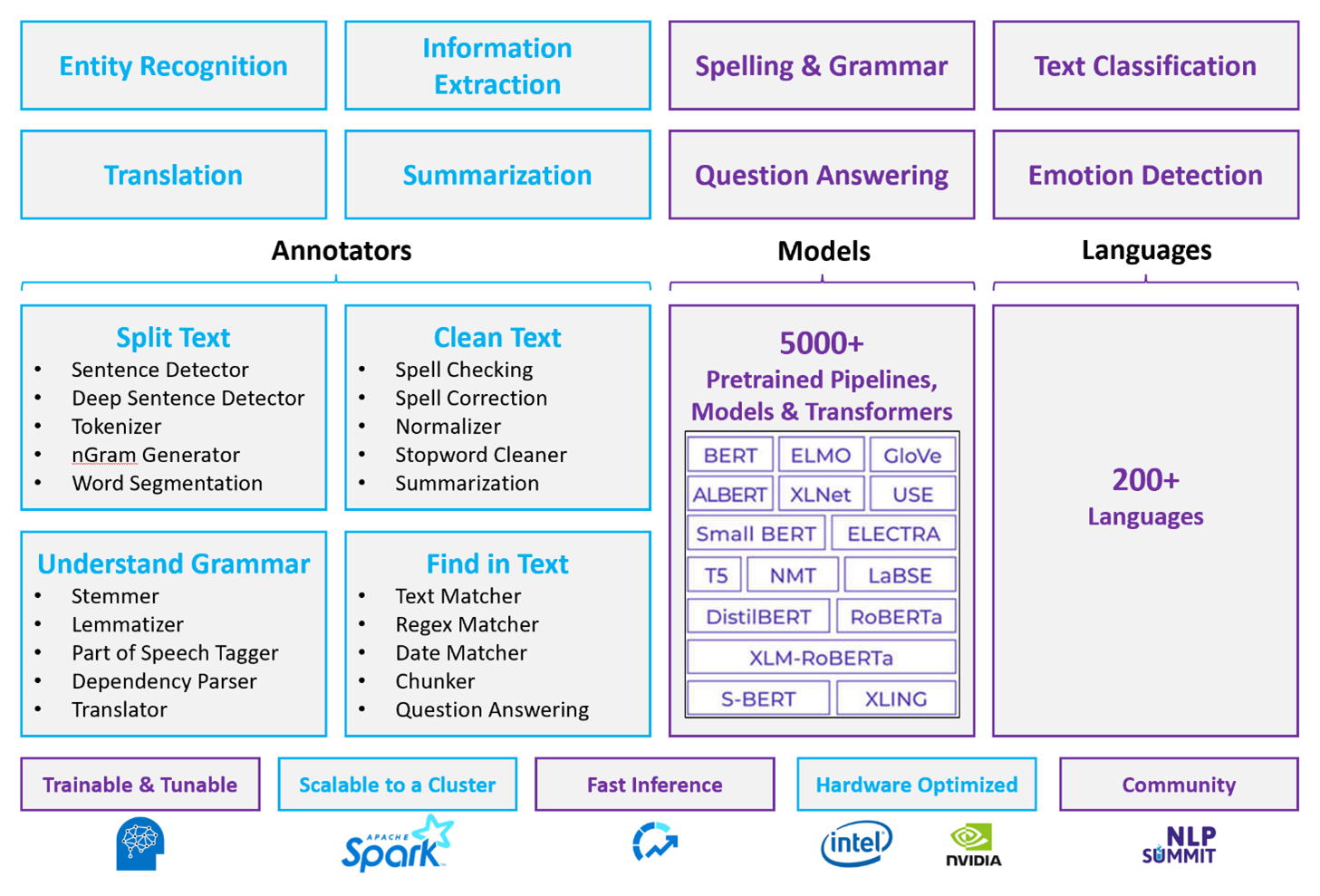
Les points de référence publics récents montrent que Spark NLP est 38 et 80 fois plus rapide que spaCy, avec une justesse comparable pour l’entraînement de modèles personnalisés. Spark NLP est la seule bibliothèque open source qui peut utiliser un cluster Spark distribué. Spark NLP est une extension native de Spark ML qui fonctionne directement sur des dataframes. Par conséquent, les accélérations sur un cluster entraînent un autre ordre de grandeur du gain en performances. Comme chaque pipeline Spark NLP est un pipeline Spark ML, Spark NLP est adapté pour la création de pipelines NLP et de machine learning unifiés, comme la classification de documents, la prédiction des risques et les pipelines de recommandation.
Outre d’excellentes performances, Spark NLP offre également une justesse de pointe pour un nombre croissant de tâches NLP. L’équipe Spark NLP s’informe régulièrement des articles universitaires pertinents les plus récents et implémente des modèles de pointe. Au cours des deux à trois dernières années, les modèles les plus performants ont utilisé le deep learning. La bibliothèque est fournie avec des modèles de deep learning prédéfinis pour la reconnaissance d’entités nommées, la classification de documents, la détection des sentiments et des émotions, et la détection des phrases. La bibliothèque comprend aussi des dizaines de modèles de langage préentraînés qui incluent la prise en charge des incorporations de mots, de segments, de phrases et de documents.
La bibliothèque a des builds optimisées pour les processeurs, les GPU et les dernières puces Intel Xeon. Vous pouvez mettre à l’échelle les processus d’entraînement et d’inférence pour tirer parti des clusters Spark. Ces processus peuvent s’exécuter en production dans toutes les plateformes d’analytique courantes.
Défis
- Le traitement d’une collection de documents de texte de forme libre nécessite une quantité importante de ressources de capacité de calcul. Le traitement est également gourmand en temps. Ces processus impliquent souvent un déploiement de capacités de calcul GPU.
- Sans un format de document standardisé, il peut être difficile d’obtenir des résultats cohérents et précis quand vous utilisez le traitement de texte de forme libre pour extraire des faits spécifiques d’un document. Par exemple, considérez une représentation textuelle d’une facture : il peut être difficile de créer un processus capable d’extraire correctement la date et le numéro de la facture quand les factures proviennent de plusieurs fournisseurs.
Critères de sélection principaux
Dans Azure, des services Spark comme Azure Databricks, Azure Synapse Analytics et Azure HDInsight fournissent des fonctionnalités NLP quand vous les utilisez avec Spark NLP. Azure Cognitive Services est une autre option pour les fonctionnalités NLP. Pour décider du service à utiliser, posez-vous les questions suivantes :
Voulez-vous utiliser des modèles prédéfinis ou pré-entraînés ? Si oui, envisagez d’utiliser les API offertes par Azure Cognitive Services. Vous pouvez aussi télécharger le modèle de votre choix via Spark NLP.
Devez-vous effectuer l’apprentissage de modèles personnalisés avec une grande quantité de données de texte ? Si oui, envisagez d’utiliser Azure Databricks, Azure Synapse Analytics ou Azure HDInsight avec Spark NLP.
Avez-vous besoin de fonctionnalités NLP de bas niveau comme la création de jetons, la recherche de radical, la lemmatisation et TF/IDF (term frequency/inverse document frequency) ? Si oui, envisagez d’utiliser Azure Databricks, Azure Synapse Analytics ou Azure HDInsight avec Spark NLP. Vous pouvez aussi utiliser une bibliothèque de logiciels open source dans l’outil de traitement de votre choix.
Avez-vous besoin de fonctionnalités NLP simples, de haut niveau comme l’identification d’entité et d’intention, la détection de la rubrique, la vérification orthographique ou l’analyse des sentiments ? Si oui, envisagez d’utiliser les API offertes par Cognitive Services. Vous pouvez aussi télécharger le modèle de votre choix via Spark NLP.
Matrice des fonctionnalités
Les tableaux suivants récapitulent les principales différences entre les fonctionnalités des services NLP.
Fonctionnalités générales
| Fonctionnalité | Service Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) avec Spark NLP | Azure Cognitive Services |
|---|---|---|
| Fournit des modèles préformés en tant que service | Oui | Oui |
| API REST | Oui | Oui |
| Programmabilité | Python, Scala | Pour connaître les langues prises en charge, consultez Ressources supplémentaires |
| Prend en charge le traitement des jeux de données Big Data et des grands documents | Oui | Non |
Fonctionnalités NLP de bas niveau
| Fonctionnalité des annotateurs | Service Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) avec Spark NLP | Azure Cognitive Services |
|---|---|---|
| Détecteur de phrases | Oui | Non |
| Détecteur de phrases approfondi | Oui | Oui |
| Générateur de jetons | Oui | Oui |
| Générateur N-gram | Oui | Non |
| Segmentation des mots | Oui | Oui |
| Générateur de formes dérivées | Oui | Non |
| Générateur de lemmatisation | Oui | Non |
| Balisage morphosyntaxique | Oui | Non |
| Analyseur de dépendances | Oui | Non |
| Traduction | Oui | Non |
| Nettoyeur de mots vides | Oui | Non |
| Correction orthographique | Oui | Non |
| Normaliseur | Oui | Oui |
| Correspondance de texte | Oui | Non |
| TF/IDF | Oui | Non |
| Correspondance d’expression régulière | Yes | Incorporé dans LUIS (Language Understanding Service). Non pris en charge dans CLU (Conversational Language Understanding, Compréhension du langage courant), qui remplace LUIS. |
| Correspondance de date | Yes | Possible dans LUIS et CLU via la reconnaissance DateTime |
| Segmenteur | Oui | Non |
Fonctionnalités NLP de haut niveau
| Fonctionnalité | Service Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) avec Spark NLP | Azure Cognitive Services |
|---|---|---|
| Vérification orthographique | Oui | Non |
| Résumé | Oui | Oui |
| Réponses aux questions | Oui | Oui |
| Détection de sentiments | Oui | Oui |
| Détection d’émotions | Yes | Prend en charge l’exploration des opinions |
| Classification de jetons | Yes | Oui, via des modèles personnalisés |
| Classification de texte | Oui | Oui, via des modèles personnalisés |
| Représentation de texte | Oui | Non |
| NER | Oui | Oui : l’analytique de texte fournit un ensemble de NER et les modèles personnalisés sont dans la reconnaissance d’entités |
| Reconnaissance d’entités | Yes | Oui, via des modèles personnalisés |
| Détection de la langue | Oui | Oui |
| Prend en charge des langues en plus de l’anglais | Oui, prend en charge plus de 200 langues | Oui, prend en charge plus de 97 langues |
Configurer Spark NLP dans Azure
Pour installer Spark NLP, utilisez le code suivant, mais remplacez <version> par le numéro de la version la plus récente. Pour plus d’informations, consultez la documentation de Spark NLP.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Développer des pipelines NLP
Pour l’ordre d’exécution d’un pipeline NLP, Spark NLP suit le même concept de développement que les modèles de machine learning Spark ML traditionnels. Mais Spark NLP applique des techniques NLP.
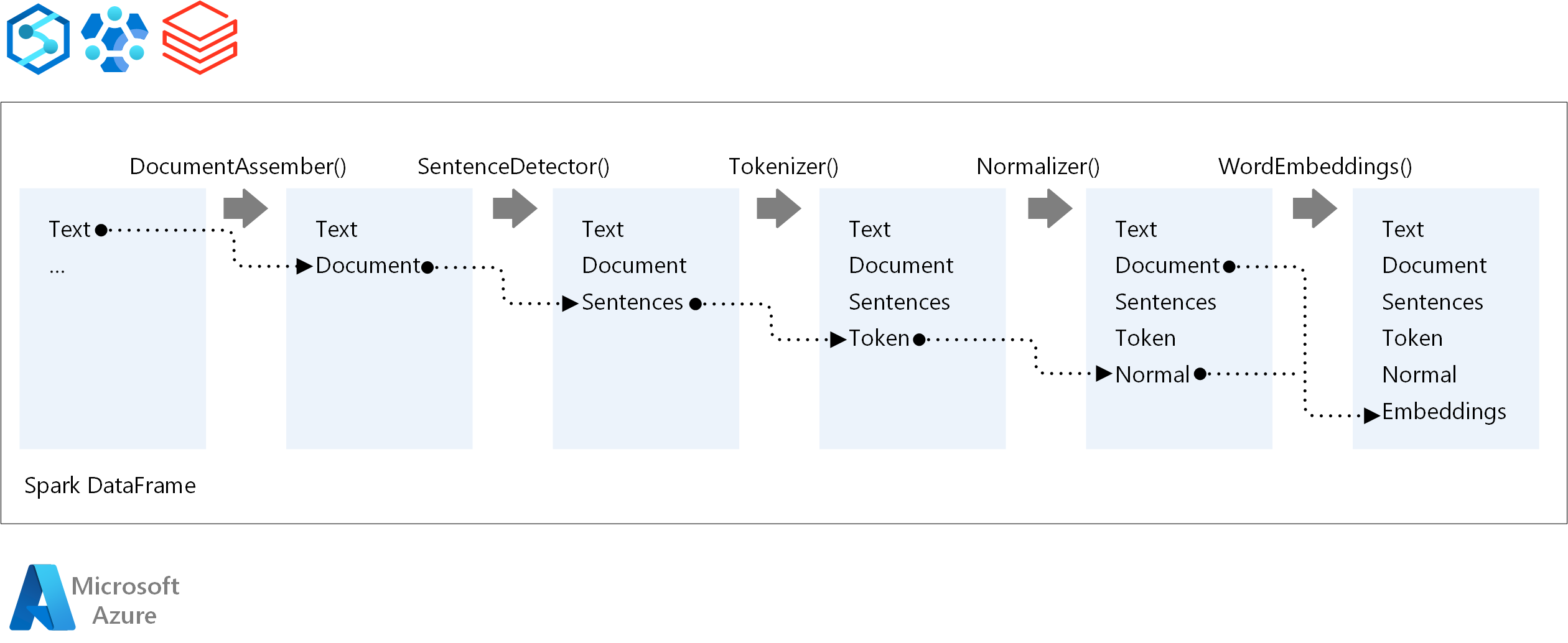
Les principaux composants d’un pipeline Spark NLP sont les suivants :
DocumentAssembler : un transformateur qui prépare les données en les changeant en un format que Spark NLP peut traiter. Cette étape est le point d’entrée de chaque pipeline Spark NLP. DocumentAssembler peut lire une colonne
Stringou unArray[String]. Vous pouvez utilisersetCleanupModepour prétraiter le texte. Par défaut, ce mode est désactivé.SentenceDetector : un annotateur qui détecte les limites des phrases en utilisant l’approche spécifiée. Cet annotateur peut retourner chaque phrase extraite dans un
Array. Il peut aussi retourner chaque phrase dans une ligne différente, si vous définissezexplodeSentencessur true.Générateur de jetons : un annotateur qui sépare le texte brut en jetons (ou unités) comme des mots, des nombres et des symboles, et retourne les jetons dans une structure
TokenizedSentence. Cette classe n’est pas personnalisée. Si vous personnalisez un générateur de jetons, laRuleFactoryinterne utilise la configuration d’entrée pour configurer les règles de création de jetons. Le générateur de jetons utilise des standards ouverts pour identifier les jetons. Si les paramètres par défaut ne répondent pas à vos besoins, vous pouvez ajouter des règles pour personnaliser le générateur de jetons.Normaliseur : un annotateur qui nettoie les jetons. Le normaliseur nécessite des radicaux. Le normaliseur utilise des expressions régulières et un dictionnaire pour transformer du texte et supprimer les caractères inutiles.
WordEmbeddings : annotateurs de recherche qui mappent des jetons à des vecteurs. Vous pouvez utiliser
setStoragePathpour spécifier un dictionnaire de recherche de jetons personnalisé pour les incorporations. Chaque ligne de votre dictionnaire doit contenir un jeton et sa représentation vectorielle, séparés par des espaces. Si un jeton n’est pas trouvé dans le dictionnaire, le résultat est un vecteur zéro de la même dimension.
Spark NLP utilise des pipelines Spark MLlib, qui sont pris en charge nativement par MLflow. MLflow est une plateforme open source pour le cycle de vie du Machine Learning. Ses composants sont les suivants :
- Suivi Mlflow : enregistre les expériences et fournit un moyen d’interroger les résultats.
- Projets MLflow : permet d’exécuter du code de science des données sur n’importe quelle plateforme.
- Modèles MLflow : déploie des modèles sur différents environnements.
- Registre de modèles : gère les modèles que vous stockez dans un référentiel central.
MLflow est intégré dans Azure Databricks. Vous pouvez installer MLflow dans n’importe quel autre environnement Spark pour suivre et gérer vos expériences. Vous pouvez aussi utiliser Registre de modèles MLflow afin de rendre des modèles disponibles en production.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Moritz Steller | Architecte de solution cloud senior
- Zoiner Tejada | CEO et Architecte
Étapes suivantes
Documentation de Spark NLP :
Composants Azure :
Ressources Learn :
Ressources associées
- Traitement du langage naturel personnalisé à grande échelle
- Choisir une technologie Cognitive Services Microsoft
- Comparer les produits et technologies de Machine Learning de Microsoft
- MLflow et Azure Machine Learning
- Enrichissement par IA avec traitement des images et du langage naturel dans la Recherche cognitive Azure
- Analyser les flux d’actualités avec l’analytique en quasi-temps réel à l’aide du traitement des images et du langage naturel
- Suggérer des étiquettes de contenu avec NLP à l’aide du deep learning