Modèle d’achat vCore - Azure SQL Database
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Cet article passe en revue le modèle d’achat vCore pour Azure SQL Database.
Vue d’ensemble
Un vCore représente une UC logique et offre la possibilité de choisir entre plusieurs caractéristiques physiques de matériel (par exemple, le nombre de cœurs, la mémoire et la taille de stockage). Le modèle d’achat vCore apporte flexibilité, contrôle et transparence pour la consommation des ressources individuelles. C’est aussi un moyen facile de traduire les exigences des charges de travail locales pour le cloud. Ce modèle optimise le prix et permet de sélectionner les ressources de calcul, de mémoire et de stockage en fonction des besoins de votre charge de travail.
Dans le modèle d’achat vCore, vos coûts dépendent du choix et de l’utilisation de ce qui suit :
- Niveau de service
- Configuration matérielle
- Ressources de calcul (le nombre de vCores et la quantité de mémoire)
- Stockage de base de données réservé
- Stockage de sauvegarde réel
Important
Les ressources de calcul, les E/S, ainsi que le stockage des données et des journaux, sont facturés au niveau de chaque base de données ou au niveau du pool élastique. Le stockage de sauvegarde est facturé au niveau de chaque base de données. Pour plus d’informations sur les tarifs, voir la page des tarifs Azure SQL Database.
Comparer les modèles d’achat de vCore ou DTU
Le modèle d’achat vCore utilisé par Azure SQL Database offre plusieurs avantages par rapport au modèle d’achat DTU :
- limites de calcul, de mémoire, d’E/S et de stockage plus élevées ;
- Choix de la configuration matérielle pour mieux répondre aux besoins de calcul et de mémoire de la charge de travail.
- Remises tarifaires pour Azure Hybrid Benefit (AHB).
- plus grande transparence des informations sur le matériel qui fait tourner les calculs, ce qui facilite la planification des migrations à partir de déploiements locaux.
- La tarification des instances réservées est disponible uniquement pour le modèle d’achat vCore.
- Plus grande granularité de mise à l’échelle avec plusieurs tailles de calcul disponibles.
Consultez les différences entre les modèles d’achat vCore et DTU pour vous aider à choisir.
Compute
Le modèle d’achat vCore a un niveau de calcul provisionné et un niveau de calcul serverless. Dans le niveau du calcul provisionné, le coût de calcul reflète la capacité de calcul totale continuellement provisionnée pour l’application, indépendamment de l’activité de charge de travail. Choisissez l’allocation de ressources la mieux adaptée à vos besoins en vCore et mémoire, puis mettes vos ressources à l’échelle en fonction de votre charge de travail. Dans le niveau de calcul serverless pour Azure SQL Database, les ressources de calcul sont automatiquement mises à l’échelle en fonction de la capacité de la charge de travail et sont facturées selon la quantité de calcul utilisée par seconde.
Pour récapituler :
- Si le niveau de calcul provisionné fournit une quantité spécifique de ressources de calcul qui sont continuellement provisionnées indépendamment de l’activité de la charge de travail, le niveau de calcul serverless met à l’échelle automatiquement les ressources de calcul en fonction de l’activité de la charge de travail.
- Là où le niveau calcul provisionné facture la quantité de calcul provisionnée à un prix fixe par heure, le niveau calcul serverless facture la quantité de calcul utilisée par seconde.
Quel que soit le niveau de calcul, trois réplicas secondaires à haute disponibilité supplémentaires sont automatiquement alloués dans le niveau de service Critique pour l’entreprise pour fournir une résilience élevée aux défaillances et aux basculements rapides. Ces réplicas supplémentaires engendrent un coût environ 2,7 fois supérieur à celui du niveau de service Usage général. De même, le coût plus élevé du stockage par Go dans le niveau de service Critique pour l’entreprise reflète les limites d’E/S plus élevées et la latence plus faible du stockage SSD local.
Dans Hyperscale, les clients contrôlent non seulement le nombre de réplicas de haute disponibilité supplémentaires (de 0 à 4) pour obtenir le niveau de résilience requis par leurs applications, mais aussi les coûts.
Pour plus d’informations sur le calcul dans Azure SQL Database, consultez Ressources de calcul (processeur et mémoire).
Limites des ressources
Pour les limites de ressources vCore, passez en revue les configurations matérielles disponibles, puis passez en revue les limites de ressources pour les éléments suivants :
Stockage des données et des journaux
Les facteurs suivants affectent la quantité de stockage utilisée pour les fichiers de données et les fichiers journaux, et s'appliquent aux niveaux Usage général et Critique pour l'entreprise.
- Chaque taille de calcul accepte une taille de données maximale configurable, qui correspond, par défaut, à 32 Go.
- Quand vous configurez la taille maximale des données, un espace de stockage facturé supplémentaire de 30 % est automatiquement ajouté pour les fichiers journaux.
- Au niveau de service Usage général,
tempdbutilise un disque SSD local et le coût de ce stockage est inclus dans le prix du modèle vCore. - Au niveau de service Critique pour l'entreprise,
tempdbpartage le disque SSD local avec les données et les fichiers journaux, et le coût du stockagetempdbest inclus dans le prix du modèle vCore. - Dans les niveaux Usage général et Critique pour l’entreprise, vous êtes facturé en fonction de la taille de stockage maximale configurée pour une base de données ou un pool élastique.
- Pour SQL Database, vous pouvez sélectionner une taille de données maximale comprise entre 1 Go et la taille de stockage maximale prise en charge, par incréments de 1 Go.
Les considérations suivantes relatives au stockage s’appliquent à Hyperscale :
- La taille de stockage maximale des données est définie sur 128 To et n’est pas configurable.
- Vous êtes facturé uniquement pour le stockage de données alloué, pas pour le stockage de données maximal.
- Le stockage des journaux n’est pas facturé.
tempdbutilise le stockage SSD local et son coût est inclus dans le prix de vCore. Pour surveiller la taille de stockage de données actuellement allouée et utilisée dans SQL Database, utilisez respectivement les métriques Azure Monitor allocated_data_storage et storage.
Pour monitorer la taille de stockage actuellement allouée et utilisée par les données individuelles et les fichiers journaux dans une base de données avec T-SQL, utilisez la vue sys.database_files et la fonction FILEPROPERTY(... , 'SpaceUsed').
Conseil
Dans certaines circonstances, vous devriez peut-être réduire une base de données pour récupérer l’espace inutilisé. Pour plus d’informations, consultez Gérer l’espace des fichiers dans Azure SQL Database.
Stockage de sauvegarde
Le stockage pour les sauvegardes de base de données est alloué afin de prendre en charge les fonctionnalités de récupération jusqu’à une date et heure (PITR) et de conservation à long terme (LTR) de SQL Database. Ce stockage, distinct du stockage des données et des fichiers journaux, est facturé séparément.
- Récupération jusqu’à une date et heure (PITR) : aux niveaux Usage général et Critique pour l’entreprise, les sauvegardes de bases de données individuelles sont automatiquement copiées vers le stockage Azure. La taille de stockage augmente dynamiquement avec chaque nouvelle création de sauvegarde. Le service est utilisé par les sauvegardes complètes, les sauvegardes différentielles et les sauvegardes de fichiers journaux. La consommation du stockage dépend du taux de change de la base de données et de la période de rétention configurée pour les sauvegardes. Vous pouvez configurer une période de conservation distincte pour chaque base de données, allant de 1 à 35 jours pour SQL Database. Une quantité de stockage de sauvegarde égale à la taille maximale des données configurées est fournie sans frais supplémentaires.
- LTR : vous pouvez configurer la conservation à long terme des sauvegardes complètes jusqu’à 10 ans. Si vous configurez une stratégie de rétention à long terme, ces sauvegardes sont stockées automatiquement dans le stockage Blob Azure. Toutefois, vous pouvez contrôler la fréquence à laquelle les sauvegardes sont copiées. Pour répondre aux différentes exigences de conformité, vous pouvez sélectionner plusieurs périodes de conservation pour les sauvegardes hebdomadaires, mensuelles ou annuelles. La configuration choisie détermine la quantité de stockage utilisée pour les sauvegardes de conservation à long terme. Pour plus d’informations, consultez Conservation des sauvegardes à long terme.
Pour le stockage de sauvegarde dans Hyperscale, consultez Sauvegardes automatisées pour les bases de données Hyperscale.
Niveaux de service
Les options de niveau de service du modèle d’achat vCore sont les suivantes : usage général, critique pour l’entreprise et hyperscale. Le niveau de service détermine généralement le type et les performances de stockage, les options de haute disponibilité et de reprise d’activité ainsi que la disponibilité de certaines fonctionnalités comme OLTP en mémoire.
| Cas d’usage | Usage général | Critique pour l’entreprise | Hyperscale |
|---|---|---|---|
| Idéal pour | La plupart des charges de travail d’entreprise. Propose des options de calcul et de stockage équilibrées, évolutives et économiques. | Offre aux applications métier la résilience la plus élevée aux défaillances en utilisant plusieurs réplicas secondaires à haute disponibilité et fournit les meilleures performances d’E/S. | Plus vaste gamme de charges de travail, notamment les charges de travail avec des exigences de stockage et d’échelle lecture hautement évolutives. Offre une plus grande résilience aux défaillances en permettant la configuration de plusieurs réplicas secondaires à haute disponibilité. |
| Taille de calcul | 2 à 128 vCores | 2 à 128 vCores | 2 à 128 vCores |
| Type de stockage | Stockage distant Premium (par instance) | Stockage SSD local ultra-rapide (par instance) | Stockage découplé avec cache disque SSD local (par réplica de calcul) |
| Taille de stockage | 1 Go - 4 To | 1 Go - 4 To | 10 Go – 128 To |
| D’OPÉRATIONS D’E/S PAR SECONDE | 320 IOPS par vCore avec un maximum de 16 000 IOPS | 4 000 IOPS par vCore avec 327 680 IOPS au maximum | 327 680 IOPS avec disque SSD local au maximum L’architecture hyperscale est une architecture à plusieurs niveaux avec une mise en cache sur plusieurs niveaux. L’efficacité des IOPS dépend de la charge de travail. |
| Mémoire/vCore | 5,1 Go | 5,1 Go | 5,1 Go ou 10,2 Go |
| Sauvegardes | Choix d’un stockage de sauvegarde géoredondant, redondant interzone ou localement redondant, conservation des données comprise entre 1 et 35 jours (7 jours par défaut) Conservation à long terme de 10 ans maximum disponible |
Choix d’un stockage de sauvegarde géoredondant, redondant interzone ou localement redondant, conservation des données comprise entre 1 et 35 jours (7 jours par défaut) Conservation à long terme de 10 ans maximum disponible |
Choix entre stockage localement redondant (LRS), redondant interzone (ZRS) et géoredondant (GRS) Conservation de 1 à 35 jours (7 jours par défaut), avec conservation à long terme de 10 ans maximum disponible |
| Disponibilité | Un réplica, réplicas sans échelle lecture, haute disponibilité (HA) redondante interzone |
Trois réplicas,un réplica avec échelle lecture, haute disponibilité (HA) redondante interzone |
haute disponibilité (HA) redondante interzone |
| Tarification/facturation | vCore, stockage réservé et stockage de sauvegarde sont facturés. Les IOPS ne sont pas facturées. |
vCore, stockage réservé et stockage de sauvegarde sont facturés. Les IOPS ne sont pas facturées. |
vCore pour chaque réplica et le stockage utilisé sont facturés. Les IOPS ne sont pas facturées. |
| Modèles de remise | Instances réservées Azure Hybrid Benefit (non disponible avec les abonnements dev/test) Abonnements Entreprise et Dev/Test – Paiement à l’utilisation |
Instances réservées Azure Hybrid Benefit (non disponible avec les abonnements dev/test) Abonnements Entreprise et Dev/Test – Paiement à l’utilisation |
Azure Hybrid Benefit (non disponible avec les abonnements dev/test) 1 Abonnements Entreprise et Dev/Test – Paiement à l’utilisation |
| Tables OLTP en mémoire | Non | Oui | Aucun |
1 La tarification simplifiée pour SQL Database Hyperscale sera bientôt disponible. Pour en savoir plus, reportez-vous au blog de tarification Hyperscale.
Pour des informations plus détaillées, examinez les limites des ressources pour les serveurs logiques, les bases de données individuelles et les bases de données en pool.
Notes
Pour plus d’informations sur le contrat de niveau de service (SLA), consultez Contrat SLA pour Azure SQL Database
Usage général
Le modèle architectural du niveau de service Usage général est basé sur la séparation du calcul et du stockage. Ce modèle architectural s’appuie sur la haute disponibilité et la fiabilité du Stockage Blob Azure qui réplique les fichiers de base de données de façon transparente et qui garantit l’absence de perte de données en cas de panne de l’infrastructure sous-jacente.
L’illustration suivante montre quatre nœuds dans un modèle architectural Standard avec les couches de calcul et de stockage séparées.
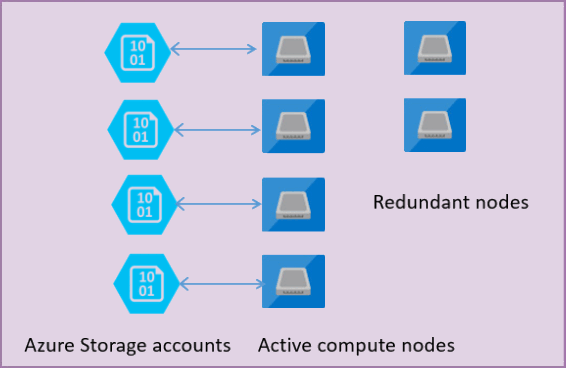
Le modèle architectural correspondant au niveau de service Usage général présente deux couches :
- Couche de calcul sans état qui exécute le processus
sqlservr.exeet ne contient que des données transitoires et données en cache (par exemple : cache du plan, pool de tampons, pool de columnstore). Ce nœud sans état est géré par Azure Service Fabric qui initialise le processus, contrôle l’intégrité du nœud et effectue le basculement vers un autre emplacement si nécessaire. - Une couche de données avec état comprenant les fichiers de base de données (.mdf/.ldf) stockés dans le service Stockage Blob Azure. Le service Stockage Blob Azure garantit qu’aucun enregistrement placé dans un fichier de base de données ne subit de perte de données. Stockage Azure est doté de fonctionnalités intégrées de redondance et de disponibilité des données qui garantissent la préservation des enregistrements d’un fichier journal ou des pages d’un fichier de données, même en cas d’incident du processus.
Dès que le moteur de base de données ou le système d’exploitation est mis à niveau, qu’une partie de l’infrastructure sous-jacente est défaillante ou qu’un problème critique est détecté dans le processus sqlservr.exe, Azure Service Fabric déplace le processus sans état vers un autre nœud de calcul sans état. Afin de réduire le temps de basculement, un ensemble de nœuds de réserve se tient prêt à exécuter le nouveau service de calcul en cas de basculement du nœud principal. Les données dans la couche Stockage Azure ne sont pas affectées, et les fichiers de données/journaux sont attachés à des processus nouvellement initialisés. Ce processus garantit une disponibilité de 99,99 % par défaut et de 99,995 % lorsque la redondance de zone est activée. Il pourrait impacter les performances des lourdes charges de travail en cours d’exécution, et ce en raison des délais de transition et du fait que le nouveau nœud démarre avec un cache à froid.
Quand choisir ce niveau de service ?
Le niveau de service Usage général est le niveau de service par défaut dans Azure SQL Database. Il convient à la plupart des charges de travail génériques. Si vous avez besoin d’un moteur de base de données entièrement managé avec un contrat SLA par défaut et une latence de stockage située entre 5 ms et 10 ms, le niveau Usage général est l’option qu’il vous faut.
Critique pour l’entreprise
Le modèle de niveau de service Critique pour l’entreprise est basé sur un cluster de processus de moteur de base de données. Ce modèle architectural repose sur un quorum de nœuds de moteur de base de données pour minimiser l’impact sur les performances de votre charge de travail, même pendant les activités de maintenance. Les mises à niveau et les correctifs sont appliqués de manière transparente aux système d’exploitation, aux pilotes et au moteur de base de données avec un temps d’arrêt minimal pour les utilisateurs finaux.
Dans le modèle critique pour l’entreprise, le calcul et le stockage sont intégrés sur chaque nœud. La réplication des données entre les processus du moteur de base de données sur chaque nœud d’un cluster à quatre nœuds permet d’atteindre un haut niveau de disponibilité, chaque nœud utilisant un disque SSD attaché localement comme stockage de données. Le diagramme suivant montre comment le niveau de service Business Critical organise un cluster de nœuds de moteur de base de données dans les réplicas de groupe de disponibilité.

Le processus du moteur de base de données et les fichiers .mdf/.ldf sous-jacents sont placés sur le même nœud, et le stockage SSD attaché localement permet à votre charge de travail de bénéficier d’une latence faible. La haute disponibilité est implémentée à l'aide d'une technologie similaire aux groupes de disponibilité AlwaysOn de SQL Server. Chaque base de données est un cluster de nœuds de base de données, avec un réplica principal accessible aux charges de travail clientes et trois réplicas secondaires contenant des copies des données. Le réplica principal pousse constamment les changements vers les réplicas secondaires afin de garantir la disponibilité des données sur les réplicas secondaires en cas de défaillance du réplica principal. Le basculement est géré par Service Fabric et le moteur de base de données : un réplica secondaire devient le réplica principal et un autre réplica secondaire est créé pour garantir un nombre suffisant de nœuds dans le cluster. La charge de travail est automatiquement redirigée vers le nouveau réplica principal.
Par ailleurs, le cluster Critique pour l’entreprise intègre la fonctionnalité Échelle lecture qui fournit un réplica en lecture seule gratuit. Ce dernier permet d’exécuter des requêtes en lecture seule (comme des rapports) qui n’affectent pas les performances de la charge de travail sur votre réplica principal.
Quand choisir ce niveau de service ?
Le niveau de service Critique pour l’entreprise est conçu pour les applications qui exigent des réponses à faible latence du stockage SSD sous-jacent (de 1 à 2 ms en moyenne), une récupération plus rapide en cas de défaillance de l’infrastructure sous-jacente, ou qui ont besoin de décharger des rapports, des données analytiques et des requêtes en lecture seule sur le réplica secondaire accessible en lecture gratuit de la base de données primaire.
Les principales raisons pour lesquelles vous devez choisir le niveau de service Critique pour l’entreprise plutôt que le niveau Usage général sont les suivantes :
- Exigences de faible latence pour les E/S : les charges de travail nécessitant une réponse rapide constante de la couche de stockage (1 à 2 millisecondes en moyenne) doivent utiliser le niveau Critique pour l’entreprise.
- Charge de travail avec requêtes de création de rapports et requêtes analytiques où un seul réplica secondaire en lecture seule gratuit est suffisant.
- Plus grande résilience et récupération plus rapide après les défaillances. En cas de défaillance du système, la base de données sur l’instance principale est désactivée et l’un des réplicas secondaires devient immédiatement la nouvelle base de données primaire en lecture-écriture, prête à traiter les requêtes.
- Protection avancée contre l’altération des données. Étant donné que le niveau Critique pour l’entreprise utilise des réplicas de bases de données en arrière-plan, le service utilise la réparation de page automatique disponible avec la mise en miroir et les groupes de disponibilité pour atténuer l’altération des données. Si un réplica ne peut pas lire une page en raison d’un problème d’intégrité des données, une nouvelle copie de la page est récupérée à partir d’un autre réplica, remplaçant la page illisible sans perte de données ni temps d’arrêt du client. Cette fonctionnalité est disponible dans le niveau Usage général si la base de données a un réplica géosecondaire.
- Disponibilité supérieure - Le niveau Critique pour l’entreprise dans une configuration à plusieurs zones de disponibilité offre une résilience aux défaillances zonales et un SLA avec une disponibilité plus élevée.
- Géo-récupération rapide : lorsque la géo-réplication active, le niveau Critique pour l’entreprise a un objectif de point de récupération garanti de 5 secondes et un objectif de délai de récupération de 30 secondes pour 100 % des heures déployées.
Hyperscale
Le niveau de service Hyperscale convient à tous les types de charges de travail. Son architecture native cloud fournit un calcul et un stockage indépendamment scalables pour prendre en charge la plus vaste gamme d’applications traditionnelles et modernes. Les ressources de calcul et de stockage dans Hyperscale dépassent largement les ressources disponibles dans les niveaux Usage général et Critique pour l’entreprise.
Pour en savoir plus, consultez le niveau de service Hyperscale pour Azure SQL Database.
Quand choisir ce niveau de service ?
Le niveau de service Hyperscale supprime de nombreuses limites pratiques traditionnellement rencontrées dans les bases de données cloud. Là où la plupart des autres bases de données sont limitées par les ressources disponibles dans un seul nœud, les bases de données du niveau de service Hyperscale n’ont pas de limite. Grâce à son architecture de stockage flexible, une base de données Hyperscale évolue selon vos besoins. Seule la capacité de stockage que vous utilisez vous est facturée.
Outre ses fonctionnalités de mise à l’échelle avancées, Hyperscale est un excellent choix pour toutes les charges de travail, pas seulement les bases de données volumineuses. Avec Hyperscale, vous pouvez :
- Obtenir une résilience élevée et une récupération rapide après une défaillance tout en contrôlant les coûts, en choisissant le nombre de réplicas à haute disponibilité (de 0 à 4).
- Améliorer la haute disponibilité en activant la redondance de zone pour le calcul et le stockage.
- Obtenir une faible latence d’E/S (1 à 2 millisecondes en moyenne) pour la partie fréquemment consultée de votre base de données. Pour les bases de données plus petites, cela pourrait s’appliquer à la base de données entière.
- Implémenter une grande variété de scénarios d’échelle lecture avec des réplicas nommés.
- Tirer parti de la mise à l’échelle rapide, sans attendre que les données soient copiées dans le stockage local sur de nouveaux nœuds.
- Profiter d’une sauvegarde de base de données continue sans impact et d’une restauration rapide.
- Prendre en charge les exigences de la continuité de l’activité en utilisant des groupes de basculement et la géoréplication.
Configuration matérielle
Les options de configuration courantes du matériel du modèle vCore sont standard (Gen 5), Fsv2 et série DC. Hyperscale offre également une option pour le matériel de la série Premium et de la série Premium à mémoire optimisée. La configuration matérielle définit les limites de calcul et de mémoire et d’autres caractéristiques qui ont une influence sur les performances de la charge de travail.
Certaines configurations matérielles, comme la série Standard (Gen5), peuvent utiliser plusieurs types de processeur, comme décrit dans Ressources de calcul (processeur et mémoire). Bien qu’une base de données ou un pool élastique donné ait tendance à rester sur du matériel doté du même type de processeur pendant une longue période (généralement pendant plusieurs mois), certains événements peuvent entraîner le déplacement d’une base de données ou d’un pool vers du matériel qui utilise un type de processeur différent.
Une base de données ou un groupe peut être déplacé pour divers scénarios, notamment dans les cas suivants :
- L’objectif du service est modifié
- L’infrastructure actuelle dans un centre de données approche des limites de capacité
- Le matériel actuellement utilisé est mis hors service en raison de sa fin de vie
- La configuration redondante interzone est activée, ce qui permet de changer de matériel en fonction de la capacité disponible.
Pour certaines charges de travail, un déplacement vers un autre type de processeur peut modifier les performances. SQL Database configure le matériel avec l’objectif de fournir des performances de charge de travail prévisibles, même si le type de processeur change, en limitant les changements de performances à une bande étroite. Toutefois, compte tenu du large éventail de charges de travail client dans SQL Database, et à mesure que de nouveaux types de processeurs sont disponibles, des changements de performances plus notables peuvent parfois être constatés lorsqu’une base de données ou un pool sont déplacés vers un autre type de processeur.
Quel que soit le type de processeur utilisé, les limites de ressources pour une base de données ou un pool élastique (comme le nombre de cœurs, la mémoire, les IOPS maximales pour les données, le débit maximal du journal et le nombre maximal de Workers simultanés), restent identiques tant que la base de données reste sur le même objectif de service.
Ressources de calcul (processeur et mémoire)
Le tableau suivant compare les ressources de calcul dans différentes configurations matérielles et différents niveaux de calcul :
| Configuration matérielle | UC | Mémoire |
|---|---|---|
| Série Standard (Gen5) | Calcul provisionné - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platine 8370C (Ice Lake)*, processeurs AMD EPYC 7763v (Milan) - Approvisionnement dans la limite de 128 vCores (hyper-thread) Calcul serverless - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platine 8370C (Ice Lake)*, processeurs AMD EPYC 7763v (Milan) – Effectuer un scale-up automatique dans la limite de 80 vCores (hyper-thread) – Le ratio mémoire/vCore s’adapte dynamiquement à l’utilisation de la mémoire et du processeur selon la demande des charges de travail et peut atteindre 24 Go par vCore. À un moment donné par exemple, une charge de travail pourrait utiliser être facturée pour 240 Go de mémoire et 10 vCores uniquement. |
Calcul provisionné - 5,1 Go par vCore – Provisionnement jusqu’à 625 Go Calcul serverless - Mise à l’échelle automatique dans la limite de 24 Go par vCore - Mise à l’échelle automatique dans la limite de 240 Go |
| Série Fsv2 | - Processeurs Intel® 8168 (Skylake) - Fréquence d’horloge turbo tous cœurs prolongée de 3,4 GHz et fréquence d’horloge turbo monocœur maximale de 3,7 GHz - Approvisionnement dans la limite de 72 vCores (hyper-thread) |
- 1,9 Go par vCore - Provisionnement dans la limite de 136 Go |
| Série DC | - Processeurs Intel® Xeon® E-2288G - Avec Intel Software Guard Extension (Intel SGX) - Approvisionnement dans la limite de 8 vCores (physiques) |
4,5 Go par vCore |
* Dans la vue de gestion dynamique sys.dm_user_db_resource_governance, la génération de matériel pour les bases de données utilisant des processeurs Intel® SP-8160 (Skylake) apparaît comme Gen6, la génération de matériel pour les bases de données utilisant Intel® 8272CL (Cascade Lake) apparaît comme Gen7, et la génération de matériel pour les bases de données utilisant Intel® Xeon® Platine 8370C (Ice Lake) ou AMD® EPYC® 7763v (Milan) apparaît comme Gen8. Pour une taille de calcul et une configuration matérielle données, les limites de ressources sont identiques quel que soit le type de processeur (Intel Broadwell, Skylake, Ice Lake, Cascade Lake ou AMD Milan).
Pour plus d’informations, consultez les limites de ressources pour les bases de données uniques et les pools élastiques.
Pour connaître les ressources et les spécifications de calcul des base de données Hyperscale, consultez Ressources de calcul Hyperscale.
Série Standard (Gen5)
- Le matériel de la série Standard (Gen5) fournit des ressources de calcul et de mémoire équilibrées, et convient à la plupart des charges de travail de base de données.
Le matériel de la série Standard (Gen5) est disponible dans toutes les régions publiques du monde.
Série Premium Hyperscale
- Les options matérielles de la série Premium utilisent les technologies de processeur et de mémoire les plus récentes d’Intel et d’AMD. La série Premium améliore grandement les performances de calcul par rapport au matériel de la série Standard.
- L’option de la série Premium offre des performances processeur plus rapides par rapport à la série Standard et un nombre maximal de vCores plus élevé.
- L'option à mémoire optimisée de la série Premium permet de doubler la quantité de mémoire par rapport à la série Standard.
- La mémoire optimisée des séries Standard et Premium est disponible pour les pools élastiques Hyperscale.
Pour plus d’informations, consultez l’annonce de blog de la série Premium Hyperscale.
Pour connaître les régions disponibles, consultez Disponibilité de la série Premium Hyperscale.
Série Fsv2
- La série Fsv2 est une configuration matérielle optimisée pour le calcul qui assure une faible latence du processeur et une fréquence d’horloge élevée pour les charges de travail les plus exigeantes en ressources de processeur. Comme pour les configurations matérielles de la série Premium Hyperscale, la série Fsv2 utilise les technologies de processeur et de mémoire les plus récentes d’Intel et d’AMD, ce qui permet aux clients de tirer parti du matériel le plus récent tout en utilisant des bases de données et des pools élastiques du niveau de service usage général.
- Selon la charge de travail, la série Fsv2 peut fournir plus de performances de processeur par vCore que d’autres types de matériel. Par exemple, la taille de calcul Fsv2 de 72 vCores peut fournir plus de performances processeur que 80 vCores sur la série Standard (Gen5), à un moindre coût.
- Dans la mesure où Fsv2 fournit moins de mémoire et de
tempdbpar vCore que d’autres matériels, la série standard (Gen5) pourrait mieux fonctionner pour les charges de travail sensibles à ces limites.
La série Fsv2 n’est pas prise en charge dans le niveau Usage général. Pour connaître les régions dans lesquelles la série Fsv2 est disponible, voir Disponibilité de la série Fsv2.
Série DC
- Le matériel de la série DC utilise des processeurs Intel avec la technologie Software Guard Extensions (Intel SGX).
- La série DC est nécessaire pour les charges de travail Always Encrypted avec des enclaves sécurisées qui nécessitent une protection de sécurité plus forte des enclaves matérielles par rapport aux enclaves VBS (sécurité basée sur la virtualisation).
- La série DC est conçue pour les charges de travail qui traitent des données sensibles et exigent des fonctionnalités de traitement des requêtes confidentielles, fournies par Always Encrypted avec enclaves sécurisées.
- Le matériel de la série DC fournit des ressources de calcul et de mémoire équilibrées.
La série DC est prise en charge uniquement pour le calcul provisionné (le mode serverless n’est pas pris en charge) et ne prend pas en charge la redondance de zone. Pour connaître les régions dans lesquelles la série DC est disponible, voir Disponibilité de la série DC.
Types d’offres Azure pris en charge par la série DC
Pour créer des bases de données ou des pools élastiques sur du matériel de série DC, l’abonnement doit être un type d’offre payante, comme le paiement à l’utilisation ou un Accord Entreprise (EA). Pour obtenir la liste complète des types d’offres Azure pris en charge par la série DC, consultez offres actuelles sans limites de dépense.
Sélectionner la configuration matérielle
Vous pouvez sélectionner la configuration matérielle d’une base de données ou d’un pool élastique dans SQL Database au moment de la création. Vous pouvez également modifier la configuration matérielle d’une base de données ou d’un pool élastique existant.
Pour sélectionner une configuration matérielle lors de la création d’une base de données SQL ou d’un pool
Pour plus d’informations, consultez Créer une base de données SQL.
Sous l’onglet Informations de base, sélectionnez le lien Configurer la base de données dans la section Calcul + Stockage, puis le lien Modifier la configuration :

Sélectionnez la configuration matérielle souhaitée :

Pour changer la configuration matérielle d’une base de données SQL ou d’un pool existant
Pour une base de données, sélectionnez le lien Niveau tarifaire sur la page Vue d’ensemble :

Pour un pool, sélectionnez Configurer dans la page Vue d’ensemble.
Suivez les étapes indiquées pour modifier la configuration, puis sélectionnez la configuration matérielle comme dans la procédure précédente.
Disponibilité matérielle
Pour des informations sur la génération précédente de matériels, consultez Disponibilité du matériel de génération précédente.
Série Standard (Gen5)
Le matériel de la série Standard (Gen5) est disponible dans toutes les régions publiques du monde.
Série Premium Hyperscale
Le matériel à mémoire optimisée du niveau de service Hyperscale de série Premium est disponible pour les bases de données uniques et les pools élastiques dans les régions suivantes :
- Australie Est **
- Sud-Australie Est
- Brésil Sud **,*
- Canada Centre **
- Est du Canada
- Asie Est
- Europe septentrionale **
- Europe occidentale **
- France Centre
- Allemagne Centre-Ouest
- Inde Centre
- Sud de l’Inde
- Japon Est **
- OuJapon Est
- Asie Sud-Est **
- Suisse Nord
- Suède Centre **,*
- Royaume-Uni Sud **
- Royaume-Uni Ouest *
- USA Centre **
- USA Est **
- USA Est 2 **
- USA Centre Nord
- USA Centre Sud
- USA Centre-Ouest
- USA Ouest 1
- USA Ouest 2 **
- USA Ouest 3 **
* Le matériel à mémoire optimisée de la série Premium n’est actuellement pas disponible.
** Inclut la prise en charge de la redondance de zone.
Série Fsv2
La série Fsv2 est disponible dans les régions suivantes :
- Centre de l’Australie
- Centre de l’Australie 2
- Australie Est
- Sud-Australie Est
- Brésil Sud
- Centre du Canada
- Asie Est
- Europe septentrionale
- Europe occidentale
- France Centre
- Inde Centre
- Centre de la Corée
- Corée du Sud
- Afrique du Sud Nord
- Asie Sud-Est
- Sud du Royaume-Uni
- Ouest du Royaume-Uni
- USA Est
- USA Ouest 2
Série DC
La série DC est disponible dans les régions suivantes :
- Centre du Canada
- Europe occidentale
- Europe septentrionale
- Asie Sud-Est
- Sud du Royaume-Uni
- USA Ouest
- USA Est
Si vous avez besoin d’une série DC dans une région actuellement non prise en charge, envoyez un demande de support. Sur la page Informations de base, indiquez les informations suivantes :
- Pour Type de problème, sélectionnez Technique.
- Spécifiez l’abonnement souhaité pour le matériel. Sélectionnez Suivant.
- Pour Type de service, sélectionnez SQL Database.
- Pour Ressource, sélectionnez Question générale.
- Pour Résumé, indiquez la disponibilité matérielle et la région souhaitées.
- Pour Type de problème, sélectionnez Sécurité, confidentialité et conformité.
- Pour Sous-type de problème, sélectionnez Always Encrypted.

Générations de matériel précédentes
Gen4
Le matériel Gen4 a été mis hors service et n’est plus disponible pour le provisionnement, le scale-up ni le scale-down. Migrez votre base de données vers un matériel d’une génération prise en charge pour bénéficier de plus grandes possibilités en matière de scalabilité des vCores et du stockage, de performances réseau accélérées, de meilleures performances d’E/S et d’une latence minimale. Passez en revue les options matérielles pour les bases de données uniques et les options matérielles pour les pools élastiques. Pour plus d’informations, consultez La prise en charge a pris fin pour le matériel Gen4 sur Azure SQL Database.