Présentation de SQL Data Sync pour Azure
S’applique à : ![]() Azure SQL Database
Azure SQL Database
Important
SQL Data Sync sera mis hors service le 30 septembre 2027. Envisagez de migrer vers d’autres solutions de réplication/synchronisation de données.
SQL Data Sync est un service basé sur Azure SQL Database qui vous permet de synchroniser les données choisies de manière bidirectionnelle sur plusieurs bases de données, à la fois locales et dans le cloud.
Azure SQL Data Sync ne prend pas en charge Azure SQL Managed Instance ou Azure Synapse Analytics.
Vue d’ensemble
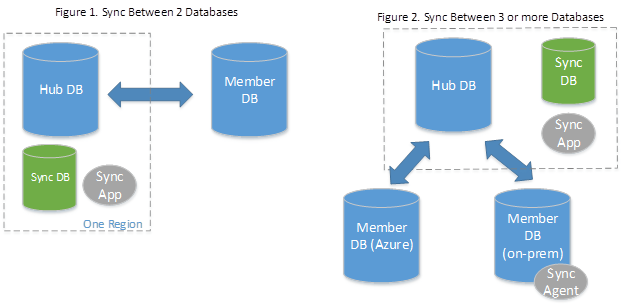
SQL Data Sync est basé sur le concept d’un groupe de synchronisation. Un groupe de synchronisation est un groupe de bases de données que vous souhaitez synchroniser.
Data Sync utilise une topologie hub and spoke pour synchroniser les données. Vous définissez l’une des bases de données du groupe de synchronisation en tant que base de données Hub. Le reste des bases de données sont des bases de données membres. La synchronisation se produit uniquement entre le hub et des membres individuels.
- Le base de données Hub doit être une base de données Azure SQL Database.
- Les bases de données membres peuvent être des bases de données dans Azure SQL Database ou dans des instances de SQL Server.
- La base de données de métadonnées de synchronisation contient les métadonnées et le journal de Data Sync. La base de données de métadonnées de synchronisation doit être une base de données Azure SQL Database située dans la même région que la base de données Hub. La base de données de métadonnées de synchronisation est créée par le client et lui appartient. Vous ne pouvez avoir qu’une seule base de données de métadonnées de synchronisation par région et par abonnement. La base de données de métadonnées de synchronisation ne peut pas être supprimée ni renommée tant que des groupes de synchronisation ou des agents de synchronisation existent. Microsoft recommande de créer une nouvelle base de données vide, à utiliser comme base de données de métadonnées de synchronisation. SQL Data Sync crée les tables dans cette base de données et exécute une charge de travail fréquente.
Notes
Si vous utilisez une base de données locale comme base de données membre, vous devez installer et configurer un agent de synchronisation local.
Un groupe de synchronisation dispose des propriétés suivantes :
- Le schéma de synchronisation décrit quelles sont les données en cours de synchronisation.
- Le sens de synchronisation peut être bidirectionnel ou peut circuler dans une seule direction. Autrement dit, le sens de synchronisation peut être Hub vers membre, Membre vers hub, ou les deux.
- L’intervalle de synchronisation correspond à la fréquence à laquelle la synchronisation se produit.
- La stratégie de résolution de conflit est une stratégie au niveau groupe, qui peut être Priorité au hub ou Priorité au membre.
Quand l’utiliser
Data Sync est utile dans les cas où les données doivent être tenues à jour entre plusieurs bases de données dans Azure SQL Database ou SQL Server. Voici les principaux cas d’usage pour Data Sync :
- Synchronisation de données hybride : avec Data Sync, vous pouvez assurer la synchronisation des données entre vos bases de données dans SQL Server et Azure SQL Database pour activer des applications hybrides. Cette fonctionnalité peut intéresser les clients qui veulent passer au cloud et souhaitent placer une partie de leurs applications dans Azure.
- Applications distribuées : dans de nombreux cas, il est recommandé de séparer les différentes charges de travail entre plusieurs bases de données. Par exemple, si vous possédez une base de données de production de grande taille, mais que vous devez également exécuter un rapport ou une charge de travail analytique de ces données, il est utile de disposer d’une seconde base de données pour cette charge de travail supplémentaire. Cette approche réduit l’impact sur les performances de votre charge de travail de production. Vous pouvez utiliser Data Sync afin de maintenir la synchronisation de ces deux bases de données.
- Applications distribuées globalement : de nombreuses entreprises sont présentes dans plusieurs régions et même dans plusieurs pays/régions. Afin de réduire la latence du réseau, il est préférable de conserver vos données dans une région proche. Avec Data Sync, vous pouvez facilement synchroniser des bases de données dans différentes régions partout dans le monde.
Data Sync n’est pas la solution préconisée pour les scénarios suivants :
| Scénario | Certaines solutions recommandées |
|---|---|
| Récupération d’urgence | Sauvegardes automatisées dans Azure SQL Database |
| Mise à l’échelle en lecture | Utiliser des réplicas en lecture seule pour décharger des charges de travail de requêtes en lecture seule |
| ETL (OLTP vers OLAP) | Azure Data Factory ou SQL Server Integration Services |
| Migration de SQL Server vers Azure SQL Database. Toutefois, SQL Data Sync peut être utilisé une fois la migration terminée afin de garantir la synchronisation de la source et de la cible. | Azure Database Migration Service |
Fonctionnement
- Suivi des modifications de données : Data Sync effectue le suivi des modifications en utilisant des déclencheurs d’insertion, de mise à jour et de suppression. Les modifications sont enregistrées dans une table latérale dans la base de données utilisateur. BULK INSERT n’active aucun déclencheur par défaut. Si FIRE_TRIGGERS n’est pas spécifié, aucun déclencheur d’insertion ne s’exécute. Ajoutez l’option FIRE_TRIGGERS afin que Data Sync puisse suivre ces insertions.
- Synchronisation des données : SQL Data Sync est conçu dans un modèle de Hub and Spoke. Le hub se synchronise avec chaque membre individuellement. Les modifications depuis le hub sont téléchargées vers le membre, puis les modifications à partir du membre sont chargées vers le hub.
- Résolution des conflits : Data Sync fournit deux options pour la résolution de conflit, Priorité au hub ou Priorité au membre.
- Si vous sélectionnez Priorité au hub, les modifications dans le hub remplacent toujours les modifications dans le membre.
- Si vous sélectionnez Priorité au membre, les modifications dans le membre remplacent toujours les modifications dans le hub. S’il existe plusieurs membres, la valeur finale dépend du membre qui se synchronise en premier.
Comparaison avec la réplication transactionnelle
| Synchronisation des données | Réplication transactionnelle | |
|---|---|---|
| Avantages | - Support actif/actif - Synchronisation bidirectionnelle entre la base de données Azure SQL et locale |
- Latence réduite - Cohérence transactionnelle - Réutilisation de la topologie existante après la migration \- Prise en charge d’Azure SQL Managed Instance |
| Inconvénients | - Pas de cohérence transactionnelle - Impact plus important sur les performances |
- Impossible de publier à partir de la base de données Azure SQL - Coût de maintenance élevé |
Liaison privée pour Azure SQL Data Sync
Notes
Le SQL Data Sync privé est différent d’Azure Private Link.
La nouvelle fonctionnalité de liaison privée vous permet de choisir un point de terminaison privé géré par le service pour établir une connexion sécurisée entre le service de synchronisation et vos bases de données membres/Hub pendant le processus de synchronisation des données. Un point de terminaison privé géré par le service est une adresse IP privée au sein d’un réseau virtuel et d’un sous-réseau spécifiques. Dans Azure SQL Data Sync, le point de terminaison privé géré par le service est créé par Microsoft et est utilisé exclusivement par le service Synchronisation des données pour une opération de synchronisation donnée.
Avant de configurer la liaison privée, lisez les conditions générales de la fonctionnalité.

Remarque
Vous devez approuver manuellement le point de terminaison privé géré par le service dans la page Connexions de point de terminaison privé du portail Azure pendant le déploiement du groupe de synchronisation ou à l’aide de PowerShell.
Bien démarrer
Configurer Data Sync dans le portail Azure
- Tutoriel : configurer SQL Data Sync entre des bases de données d’Azure SQL Database et SQL Server
- Data Sync Agent - Data Sync Agent pour SQL Data Sync
Configurer Data Sync avec PowerShell
- Utiliser PowerShell pour synchroniser des données entre plusieurs bases de données dans Azure SQL Database
- Utiliser PowerShell pour synchroniser des données entre SQL Database et SQL Server
Configurer la synchronisation des données avec l’API REST
Consultez les bonnes pratiques pour Data Sync
Un problème est survenu ?
Cohérence et performances
Cohérence éventuelle
Étant donné que Data Sync est basé sur le déclencheur, la cohérence transactionnelle n’est pas garantie. Microsoft garantit que toutes les modifications sont effectuées par la suite et que Data Sync n’entraîne pas de perte de données.
Impact sur les performances
Data Sync utilise des déclencheurs d’insertion, de mise à jour et de suppression pour effectuer le suivi des modifications. Cela crée des tables latérales dans la base de données utilisateur pour le suivi des modifications. Ces activités de suivi des modifications ont un impact sur votre charge de travail de base de données. Évaluez votre niveau de service et effectuez une mise à niveau si nécessaire.
Le provisionnement et le déprovisionnement lors de la création, la mise à jour et la suppression du groupe de synchronisation pourraient également avoir un impact sur les performances de la base de données.
Conditions requises et limitations :
Conditions générales
- Chaque table doit avoir une clé primaire. Ne modifiez pas la valeur de la clé primaire dans une ligne. Si vous avez à le faire, supprimez la ligne et recréez-la avec la nouvelle valeur de clé primaire.
Important
Le changement de la valeur d’une clé primaire existante entraîne le comportement incorrect suivant :
- Les données entre le hub et le membre risquent d’être perdues même si la synchronisation ne signale aucun problème.
- La synchronisation peut échouer, car la table de suivi contient une ligne qui n’existe pas dans la source en raison du changement de la clé primaire.
Le niveau d’isolement d’instantané doit être activé pour le hub et les membres de synchronisation. Pour plus d’informations, consultez Isolement de capture instantanée dans SQL Server.
Pour utiliser la liaison privée Data Sync, les bases de données Hub et celles de membre doivent être hébergées dans Azure (même région ou régions différentes), dans le même type de cloud (par exemple, les deux dans le cloud public ou dans le cloud gouvernemental). En outre, pour utiliser une liaison privée, les fournisseurs de ressources
Microsoft.Networkdoivent être inscrits pour les abonnements qui hébergent les serveurs hub et membres. Enfin, vous devez approuver manuellement la liaison privée pour Azure SQL Data Sync pendant la configuration de la synchronisation, dans la section « Connexions des point de terminaison privés » du portail Azure ou via PowerShell. Pour plus d’informations sur la manière d’approuver la liaison privée, consultez Tutoriel : Configurer SQL Data Sync entre des bases de données dans Azure SQL Database et SQL Server. Une fois que vous avez approuvé le point de terminaison privé géré par le service, toutes les communications entre le service de synchronisation et les bases de données membres/Hub se font par le biais de la liaison privée. Les groupes de synchronisation existants peuvent être mis à jour pour que cette fonctionnalité soit activée.
Limitations générales
- Une table ne peut pas avoir une colonne d’identité qui n’est pas la clé primaire.
- Une clé primaire ne peut pas avoir les types de données suivants : sql_variant, binary, varbinary, image et xml.
- Si vous utilisez les types de données suivants comme clé primaire, n’oubliez pas que la précision n’est prise en charge qu’à la seconde près : time, datetime, datetime2 et datetimeoffset.
- Les noms des objets (bases de données, tables et colonnes) ne peuvent pas contenir les caractères imprimables suivants : point (
.), crochet gauche ([) ou crochet droit (]). - Un nom de table ne peut pas contenir les caractères imprimables :
! " # $ % ' ( ) * + -ou espace. - L’authentification Microsoft Entra (anciennement Azure Active Directory) n’est pas prise en charge.
- S’il existe des tables avec le même nom mais un schéma différent (par exemple,
dbo.customersetsales.customers), une seule des tables peut être ajoutée à la synchronisation. - Les colonnes avec des type de données définis par l’utilisateur ne sont pas prises en charge.
- Le déplacement de serveurs entre différents abonnements n’est pas pris en charge.
- Si deux clés primaires ne sont pas différentes dans le cas (par exemple,
Fooetfoo), la synchronisation des données ne prend pas en charge ce scénario. - La troncation des tables n’est pas une opération prise en charge par la synchronisation des données (les modifications ne sont pas suivies).
- L’utilisation d’une base de données Azure SQL Hyperscale en tant que base de données de hub ou de métadonnées de synchronisation n’est pas prise en charge. Toutefois, une base de données Hyperscale peut être une base de données membre dans une topologie de synchronisation des données.
- Les tables à mémoire optimisée ne sont pas prises en charge.
- Les modifications de schéma ne sont pas répliquées automatiquement. Une solution personnalisée peut être créée pour automatiser la réplication des modifications de schéma.
- Data Sync ne prend en charge que les deux propriétés d’index suivantes : Unique, En cluster/Non cluster. Les autres propriétés d’index, comme
IGNORE_DUP_KEY, le prédicat de filtreWHERE, ne sont pas pris en charge et l’index de destination est provisionné sans ces propriétés, même si ces propriétés sont définies pour l’index source. - Une base de données de tâches élastiques Azur ne peut pas être utilisée en tant que base de données de métadonnées de synchronisation de données SQL, et inversement.
- SQL Data Sync n'est pas pris en charge pour les bases de données de registre.
Types de données non pris en charge
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection (prise en charge de XML)
- Cursor, RowVersion, Timestamp, Hierarchyid
Types de colonne non pris en charge
Data Sync ne peut pas synchroniser des colonnes en lecture seule ou générées par le système. Par exemple :
- Colonnes calculées
- Colonnes générées par le système pour les tables temporelles.
Limitations des dimensions de la base de données et du service
| Dimensions | Limite | Solution de contournement |
|---|---|---|
| Nombre maximal de groupes de synchronisation auquel peut appartenir une base de données. | 5 | |
| Nombre maximal de points de terminaison dans un seul groupe de synchronisation | 30 | |
| Nombre maximal de points de terminaison locaux dans un seul groupe de synchronisation. | 5 | Créer plusieurs groupes de synchronisation |
| Noms de la base de données, de la table, du schéma et des colonnes | 50 caractères par nom | |
| Tables dans un groupe de synchronisation | 500 | Créer plusieurs groupes de synchronisation |
| Colonnes d’une table dans un groupe de synchronisation | 1 000 | |
| Taille de ligne de données sur une table | 24 Mo |
Remarque
Il pourrait y avoir jusqu’à 30 points de terminaison dans un même groupe de synchronisation s’il n’existe qu’un seul groupe de synchronisation. S’il existe plus d’un groupe de synchronisation, le nombre total de points de terminaison dans tous les groupes de synchronisation ne peut pas dépasser 30. Si une base de données appartient à plusieurs groupes de synchronisation, elle est comptée comme plusieurs points de terminaison, et non pas un seul.
Configuration requise pour le réseau
Notes
Si vous utilisez une liaison privée Sync, cette configuration requise du réseau ne s’applique pas.
Quand le groupe de synchronisation est établi, le service Data Sync doit se connecter à la base de données Hub. Lors de l’établissement du groupe de synchronisation, le serveur SQL Azure doit avoir la configuration suivante dans ses paramètres Firewalls and virtual networks :
- Le paramètre Refuser l’accès au réseau public doit être désactivé.
- Le paramètre Autoriser les services et les ressources Azure à accéder à ce serveur doit avoir la valeur Oui, ou vous devez créer des règles IP pour les adresses IP utilisées par le service Data Sync.
Une fois le groupe de synchronisation créé et provisionné, vous pouvez désactiver ces paramètres. L’agent de synchronisation se connecte directement à la base de données Hub et vous pouvez utiliser les règles IP de pare-feu du serveur ou des points de terminaison privés pour permettre à l’agent d’accéder au serveur hub.
Remarque
Si vous modifiez les paramètres de schéma du groupe de synchronisation, vous devez autoriser le service Data Sync à accéder à nouveau au serveur afin que la base de données Hub puisse être reprovisionnée.
Résidence des données dans une région
Si vous synchronisez des données dans la même région, SQL Data Sync ne stocke/traite pas les données client en dehors de la région dans laquelle l’instance de service est déployée. Si vous synchronisez des données entre différentes régions, SQL Data Sync réplique les données client dans les régions appairées.
FAQ sur SQL Data Sync
Combien coûte le service de synchronisation des données SQL Data Sync ?
Aucun frais n’est facturé pour le service SQL Data Sync en lui-même. Toutefois, les frais de transfert de données pour le déplacement des données vers et depuis votre instance SQL Database vous seront facturés. Pour plus d'informations, consultez Frais de transfert de données.
Quelles régions prennent en charge la synchronisation des données ?
SQL Data Sync est disponible dans toutes les régions.
Un compte SQL Database est-il requis ?
Oui. Vous devez avoir un compte SQL Database pour héberger la base de données Hub.
Puis-je utiliser la synchronisation des données pour effectuer une synchronisation entre les bases de données SQL Server uniquement ?
Pas directement. Vous pouvez toutefois effectuer une synchronisation entre les bases de données SQL Server de façon indirecte, en créant une base de données Hub dans Azure, puis en ajoutant les bases de données locales au groupe de synchronisation.
Puis-je utiliser la synchronisation de données pour synchroniser des bases de données dans base de données Azure SQL qui appartiennent à différents abonnements ?
Oui. Vous pouvez configurer la synchronisation entre des bases de données qui appartiennent à des groupes de ressources détenus par des abonnements différents, même si les abonnements appartiennent à des abonnés différents.
- Si les abonnements appartiennent au même abonné et que vous disposez d’autorisations pour tous les abonnements, vous pouvez configurer le groupe de synchronisation dans le Portail Azure.
- Sinon, vous devez utiliser PowerShell pour ajouter les membres de synchronisation.
Puis-je configurer la synchronisation des données pour synchroniser des bases de données SQL Database qui appartiennent à différents clouds (comme le cloud public Azure et Azure exploité par 21Vianet) ?
Oui. Vous pouvez synchroniser des bases de données qui appartiennent à des clouds différents. Vous devez utiliser PowerShell pour ajouter les membres de synchronisation appartenant à différents abonnements.
Puis-je utiliser Data Sync pour envoyer des données de ma base de données de production vers une base de données vide, et ensuite les synchroniser ?
Oui. Créez manuellement le schéma dans la nouvelle base de données en créant le script à partir de la base de données d’origine. Après avoir créé le schéma, ajoutez les tables à un groupe de synchronisation pour copier les données et les garder synchronisées.
Dois-je utiliser SQL Data Sync pour sauvegarder et restaurer mes bases de données ?
Il est déconseillé d’utiliser SQL Data Sync pour créer une sauvegarde de vos données. Vous ne pouvez pas sauvegarder et restaurer à un point précis dans le temps car les synchronisations de SQL Data Sync ne sont pas affectées à des versions. Par ailleurs, SQL Data Sync ne sauvegarde pas d’autres objets SQL, notamment les procédures stockées, et n’effectue pas rapidement l’équivalent d’une opération de restauration.
Pour une technique de sauvegarde recommandée, voir Copier une copie cohérente au niveau transactionnel d’une base de données dans Azure SQL Database.
Data Sync peut-il synchroniser des tables et colonnes chiffrées ?
- Si une base de données utilise Always Encrypted, vous ne pouvez synchroniser que les tables et colonnes qui sont pas chiffrées. Vous ne pouvez pas synchroniser les colonnes chiffrées, car Data Sync ne peut pas déchiffrer les données.
- Si une colonne utilise le chiffrement Column-Level Encryption (CLE), vous pouvez synchroniser la colonne tant que la taille de ligne est inférieure à la taille maximale de 24 Mo. Data Sync traite la colonne chiffrée par clé (CLE) comme des données binaires normales. Pour déchiffrer les données d’autres membres de synchronisation, vous devez avoir le même certificat.
Le classement est-il pris en charge dans SQL Data Sync ?
Oui. SQL Data Sync prend en charge la configuration des paramètres de classement dans les scénarios suivants :
- Si les tables du schéma de synchronisation sélectionné ne sont pas encore dans votre Hub ou dans les bases de données membres, lorsque vous déployez le groupe de synchronisation, le service crée automatiquement les tables et colonnes correspondantes avec les paramètres de classement sélectionnés dans les bases de données de destination vides.
- Si les tables à synchroniser existent déjà dans votre Hub ou vos bases de données membres, SQL Data Sync requiert que les colonnes clés primaires aient le même classement dans le Hub que dans les bases de données membres pour déployer avec succès le groupe de synchronisation. Il n’existe aucune restriction de classement sur les colonnes autres que les colonnes clés primaires.
La fédération est-elle prise en charge dans SQL Data Sync ?
La base de données racine de fédération peut être utilisée sans limitation dans SQL Data Sync. Vous ne pouvez pas ajouter de point de terminaison de base de données fédérée à la version actuelle de SQL Data Sync.
Puis-je utiliser SQL Data Sync pour synchroniser des données exportées à partir de Dynamics 365 à l’aide de la fonctionnalité BYOD (apportez votre propre base de données) ?
La fonctionnalité Dynamics 365 apportez votre propre base de données permet aux administrateurs d’exporter des entités de données depuis l’application dans leur propre base de données Microsoft Azure SQL. La synchronisation des données peut être utilisée pour synchroniser ces données dans d’autres bases de données si les données sont exportées à l’aide de l’envoi (push) incrémentiel (l’envoi intégral n’est pas pris en charge) et si l’activation des déclencheurs dans la base de données cible est définie sur Oui.
Comment créer la synchronisation des données dans le groupe de basculement pour prendre en charge la récupération d’urgence ?
- Pour garantir que les opérations de synchronisation des données dans la région de basculement correspondent à la région primaire, après le basculement, vous devez recréer manuellement le groupe de synchronisation dans la région de basculement avec les mêmes paramètres que la région primaire.
Contenu connexe
Mettre à jour le schéma d’une base de données synchronisée
Vous devez mettre à jour le schéma d’une base de données dans un groupe de synchronisation ? Les modifications de schéma ne sont pas répliquées automatiquement. Pour des solutions à ce problème, consultez les articles suivants :
- Automatiser la réplication des modifications de schéma avec SQL Data Sync dans Azure
- Utiliser PowerShell pour mettre à jour le schéma de synchronisation dans un groupe de synchronisation existant
Superviser et dépanner
SQL Data Sync s’exécute-t-il comme prévu ? Pour surveiller l’activité et résoudre les problèmes, consultez les articles suivants :
- Superviser SQL Data Sync avec des journaux Azure Monitor
- Résoudre les problèmes liés à Azure SQL Data Sync
En savoir plus sur Azure SQL Database
Pour plus d’informations sur Azure SQL Database, consultez les articles suivants :