Surveiller l’intégrité de vos sauvegardes à l’aide des métriques de sauvegarde Azure (version préliminaire)
Sauvegarde Azure fournit un ensemble de métriques intégrées via Azure Monitor qui vous permettent de surveiller l’intégrité de vos sauvegardes. Elle vous permet également de configurer des règles d’alerte qui se déclenchent lorsque les métriques dépassent les seuils définis.
Sauvegarde Azure offre les principales fonctionnalités suivantes :
- Possibilité d’afficher les métriques prêtes à l’emploi liées à la sauvegarde et à la restauration de l’intégrité de vos éléments de sauvegarde, ainsi que les tendances associées.
- Possibilité d’écrire des règles d’alerte personnalisées sur ces métriques pour surveiller efficacement l’intégrité de vos éléments de sauvegarde.
- Possibilité d’acheminer les alertes de métriques déclenchées vers différents canaux de notification pris en charge par Azure Monitor, tels que la messagerie, ITSM, webhook, les applications logiques, etc.
En savoir plus sur les métriques Azure Monitor.
Scénarios pris en charge
Prend en charge les métriques intégrées pour les types de charges de travail suivants :
- machine virtuelle Azure, bases de données SQL dans une machine virtuelle Azure
- Bases de données SAP HANA dans une machine virtuelle Azure
- Azure Files
- Blobs Azure.
Les métriques pour le type de charge de travail d’instance HANA ne sont pas prises en charge actuellement.
Les métriques peuvent être consultées pour tous les coffres Recovery Services de chaque région et abonnement à la fois. L’affichage des métriques pour une plus grande étendue dans le portail Azure n’est pas pris en charge actuellement. Les mêmes limites s’appliquent également à la configuration des règles d’alerte de métrique.
Métriques intégrées prises en charge
Actuellement, Sauvegarde Azure prend en charge les métriques suivantes :
Événements d’intégrité de la sauvegarde : la valeur de cette métrique représente le nombre d’événements d’intégrité liés à l’intégrité des tâches de sauvegarde, qui ont été déclenchées pour le coffre dans un délai spécifique. Lorsqu’une tâche de sauvegarde se termine, le service Sauvegarde Azure crée un événement d’intégrité de sauvegarde. En fonction de l’état d’une tâche (par exemple, réussite ou échec), les dimensions associées à l’événement varient.
Événements d’intégrité de la restauration : la valeur de cette métrique représente le nombre d’événements d’intégrité liés à l’intégrité des tâches de sauvegarde, qui ont été déclenchées pour le coffre dans un délai spécifique. Lorsqu’une tâche de restauration est terminée, le service Sauvegarde Azure crée un événement d’intégrité de restauration. En fonction de l’état d’une tâche (par exemple, réussite ou échec), les dimensions associées à l’événement varient.
Notes
Nous prenons en charge les événements d’intégrité de restauration uniquement pour la charge de travail des objets BLOB Azure, car les sauvegardes sont continues, et il n’y a aucune notion de tâches de sauvegarde ici.
Par défaut, les nombres sont exposés au niveau du coffre. Pour afficher le nombre d’éléments de sauvegarde et d’état de tâche particuliers, vous pouvez filtrer les métriques sur l’une des dimensions prises en charge.
Le tableau suivant répertorie les dimensions prises en charge par les métriques Événements d’intégrité de sauvegarde et Événements d’intégrité de restauration :
| Nom de la dimension | Description |
|---|---|
| ID de la source de données | ID unique de la source de données associée à la tâche.
Pour la sauvegarde de base de données SQL AG, le champ ID de source de données est vide, car il n’y a aucune source de données (machine virtuelle) dans de tels scénarios. Pour afficher les métriques d’une base de données particulière au sein d’un groupe de disponibilité, utilisez le champ ID de l'instance de sauvegarde. |
| Type de source de données | Type de la source de données associée à la tâche. Voici les types de sources de données pris en charge :
|
| ID d’instance de sauvegarde | L’ID ARM de l’instance de sauvegarde associée à la tâche. Par exemple : /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/testRG/providers/Microsoft.RecoveryServices/vaults/testVault/backupFabrics/Azure/protectionContainers/IaasVMContainer;iaasvmcontainerv2;testRG;testVM/protectedItems/VM;iaasvmcontainerv2;testRG;testVM |
| Nom de l’instance de sauvegarde | Nom convivial de l’instance de sauvegarde pour faciliter la lisibilité. Son format est le suivant : {protectedContainerName};{backupItemFriendlyName}. Par exemple : testStorageAccount;testFileShare |
| État d’intégrité | Représente l’intégrité de l’élément de sauvegarde une fois la tâche terminée. Il peut prendre l’une des valeurs suivantes : Sain, Temporaire, Non sain, Non sain persistant, Détérioré temporaire, Détérioré persistant.
|
Scénarios de monitoring
Afficher les métriques dans le portail Azure
Pour afficher les métriques dans le portail Azure, suivez les étapes ci-dessous :
Accédez au Centre de sauvegarde dans le portail Azure et cliquez sur Métriques dans le menu.
Sélectionnez un coffre ou un groupe de coffres dont vous souhaitez afficher les métriques.
Actuellement, la portée maximale pour laquelle vous pouvez afficher les métriques est : Tous les coffres Recovery Services dans un abonnement et une région particuliers. Par exemple, tous les coffres Recovery Services dans la région USA Est dansTestSubscription1.
Sélectionnez une métrique pour afficher les événements d’intégrité de sauvegarde ou les événements d’intégrité de restauration.
Cela génère le rendu d’un graphique qui indique le nombre d’événements d’intégrité pour le ou les coffres. Vous pouvez ajuster l’intervalle de temps et la granularité de l’agrégation à l’aide des filtres situés en haut de l’écran.
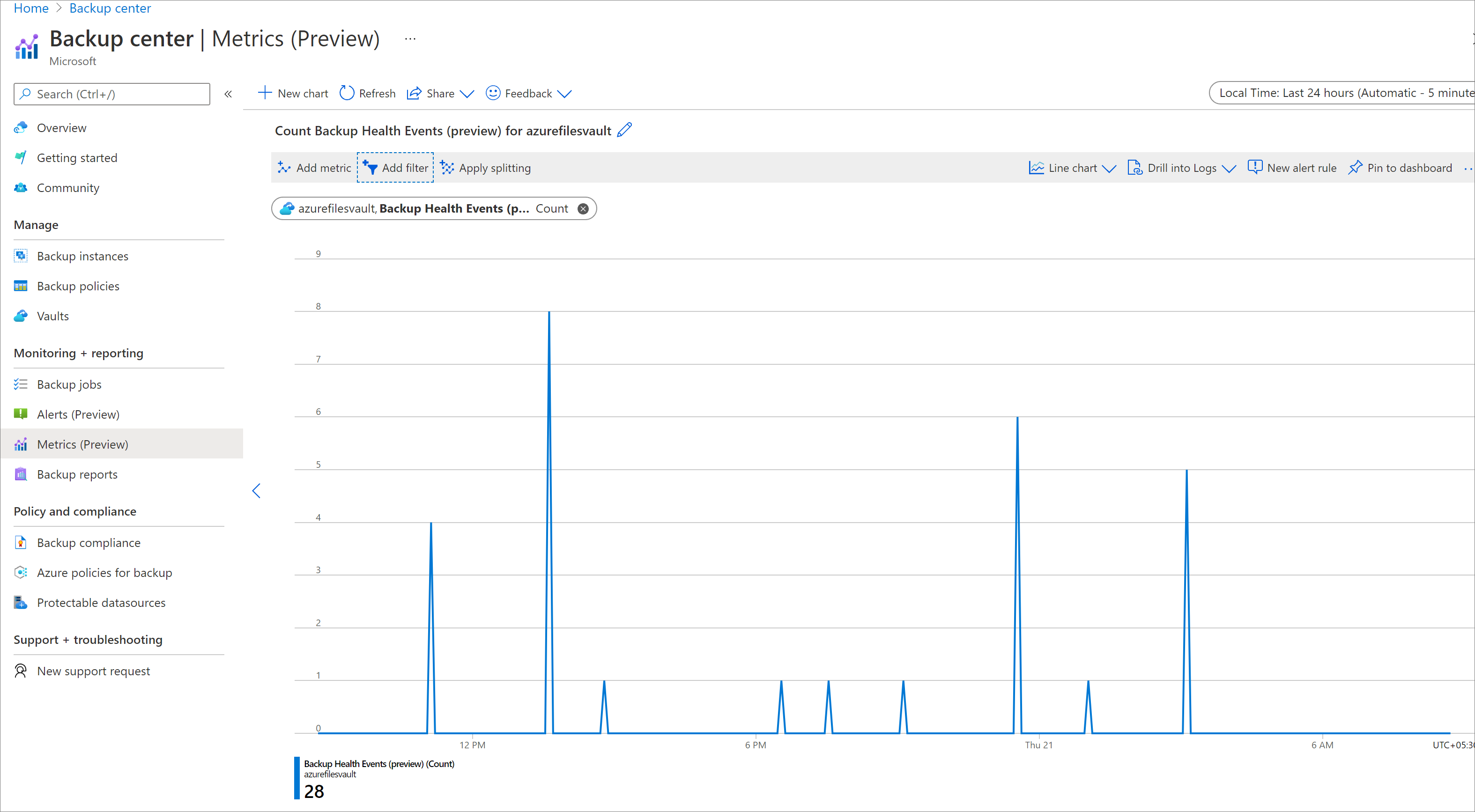
Pour filtrer les métriques selon différentes dimensions, cliquez sur le bouton Ajouter un filtre et sélectionnez les valeurs de dimension appropriées.
- Par exemple, si vous souhaitez afficher le nombre d’événements d’intégrité uniquement pour les sauvegardes de machines virtuelles Azure, ajoutez un filtre
Datasource Type = Microsoft.Compute/virtualMachines. - Pour afficher les événements d’intégrité d’une source de données ou d’une instance de sauvegarde particulière au sein du coffre, utilisez les filtres ID de source de données/ID d’instance de sauvegarde.
- Pour afficher les événements d’intégrité uniquement pour les échecs de sauvegarde, utilisez un filtre sur HealthStatus, en sélectionnant les valeurs correspondant à un état d’intégrité non sain ou détérioré.
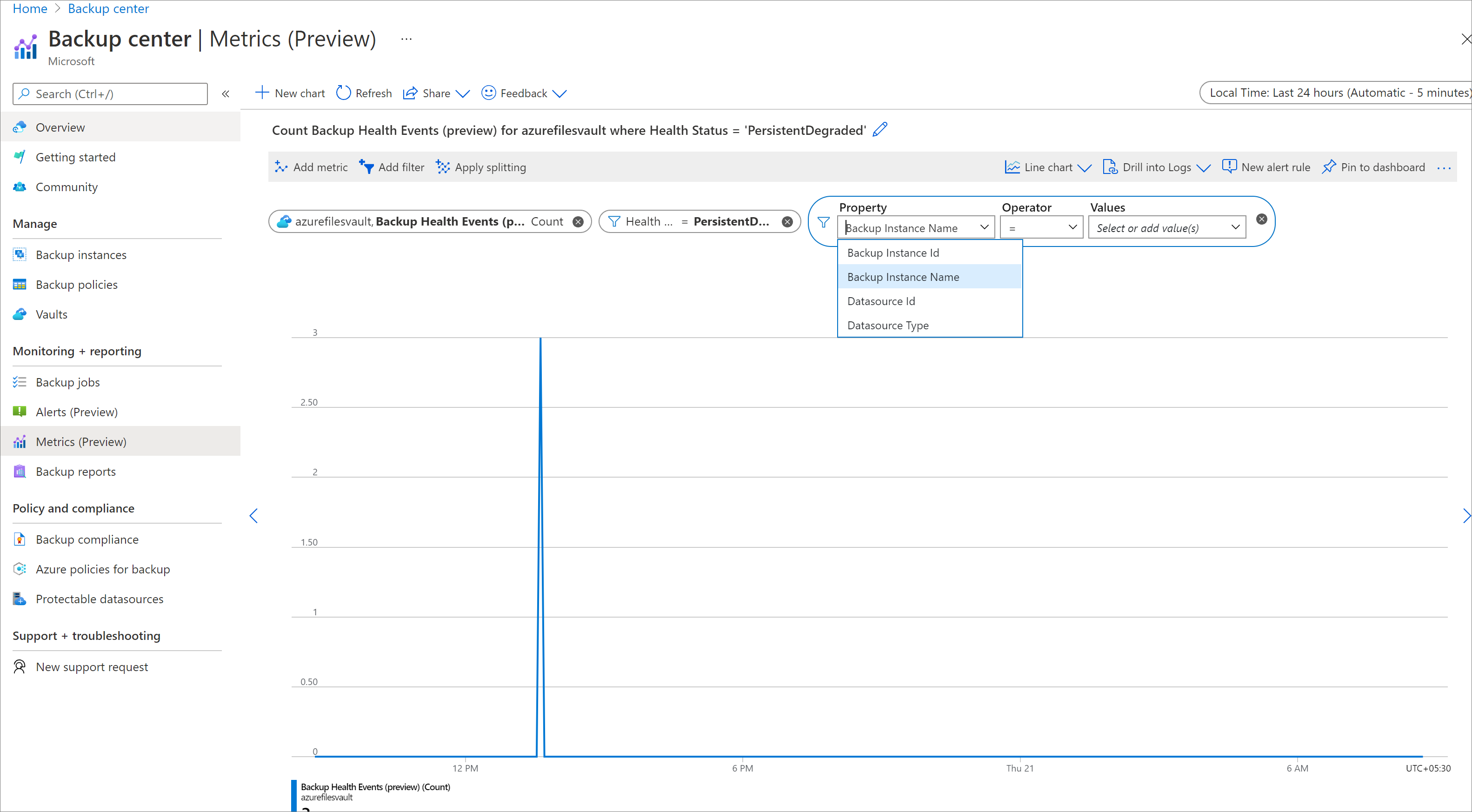
- Par exemple, si vous souhaitez afficher le nombre d’événements d’intégrité uniquement pour les sauvegardes de machines virtuelles Azure, ajoutez un filtre



Configurer des alertes et des notifications sur vos métriques
Pour configurer des alertes et des notifications sur vos métriques, procédez comme suit :
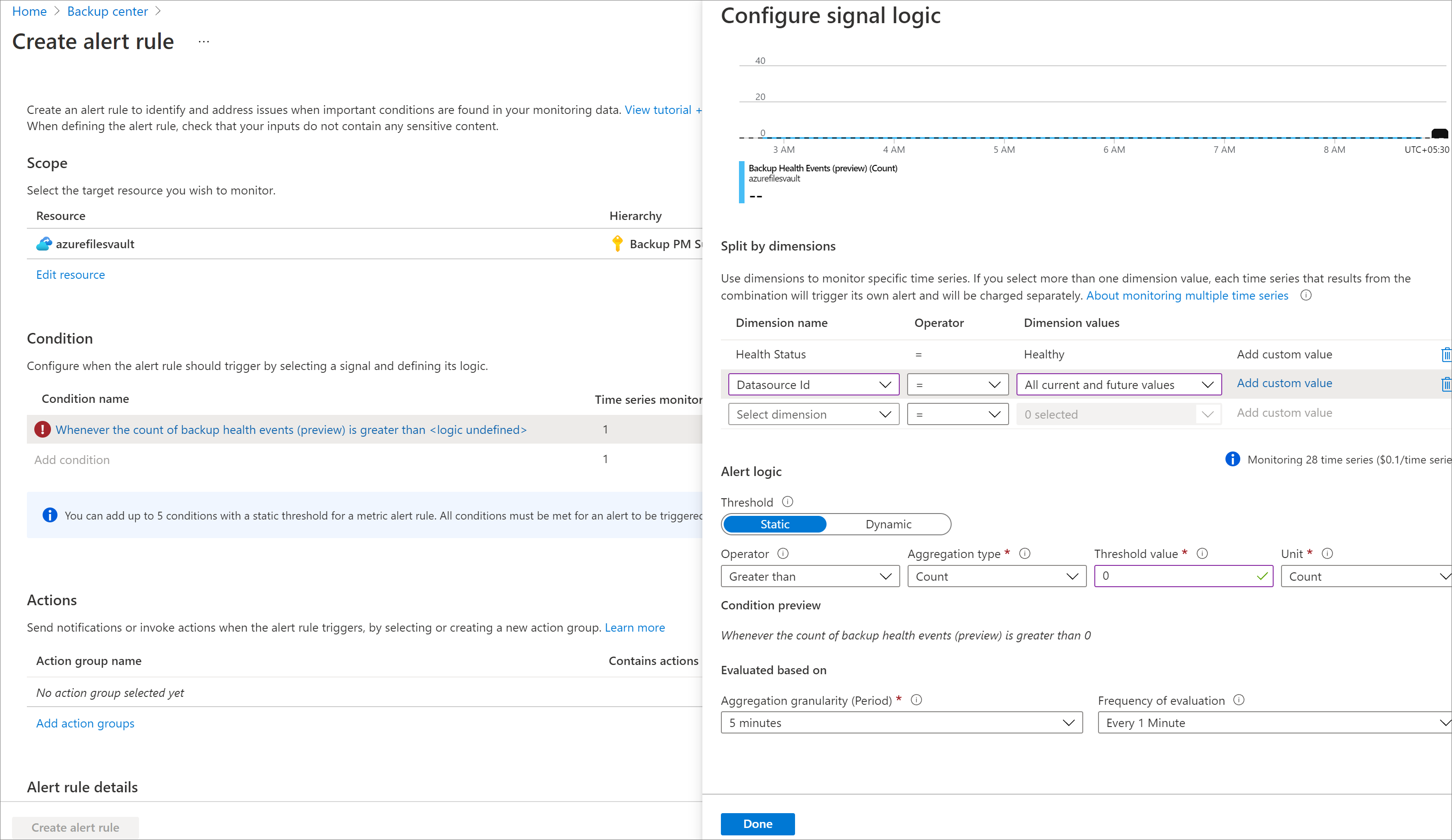
Cliquez sur Nouvelle règle d’alerte en haut des graphiques de métriques.
Sélectionnez l’étendue pour laquelle vous souhaitez créer des alertes.
Les limites d’étendue sont les mêmes que celles décrites dans la section Afficher les métriques.Sélectionnez la condition sur laquelle l’alerte doit être déclenchée.
Par défaut, certains champs sont préremplis en fonction des sélections effectuées dans le graphique des métriques. Vous pouvez modifier les paramètres selon vos besoins. Pour générer des alertes individuelles pour chaque source de donnée dans le coffre, utilisez la sélection dimensions de la règle d’alertes de métriques. Voici quelques scénarios :Déclenchement d’alertes en cas d’échec de tâches de sauvegarde pour chaque source de source :
Règle d’alerte : déclencher une alerte si des événements d’intégrité de sauvegarde > 0 au cours des dernières 24 heures pour :
- Dimensions ["HealthStatus"] = "Non sain persistent/Non sain temporaire"
- Dimensions ["DatasourceId"] = "Toutes les valeurs actuelles et futures"
Déclenchement d’alertes si toutes les sauvegardes du coffre ont réussi pour la journée :
Règle d’alerte : déclencher une alerte si des événements d’intégrité de sauvegarde < 1 au cours des dernières 24 heures pour :
- Dimensions ["HealthStatus"] = "Non sain persistent/Non sain temporaire / Déterioré persistent/Déterioré temporaire"
Remarque
Si vous sélectionnez davantage de dimensions dans le cadre de la condition de règle d’alerte, le coût augmente (ce qui est proportionnel au nombre de combinaisons uniques de valeurs de dimension possibles). La sélection d’un plus grand nombre de dimensions vous permet d’obtenir davantage de contexte sur une alerte déclenchée.
Pour configurer des notifications pour ces alertes à l’aide de groupes d’actions, configurez un groupe d’actions dans le cadre de la règle d’alerte ou créez une règle d’action distincte.
Nous prenons en charge différents canaux de notification, tels que le courrier électronique, ITSM, webhook, application logique, SMS. En savoir plus sur les groupes d’actions.
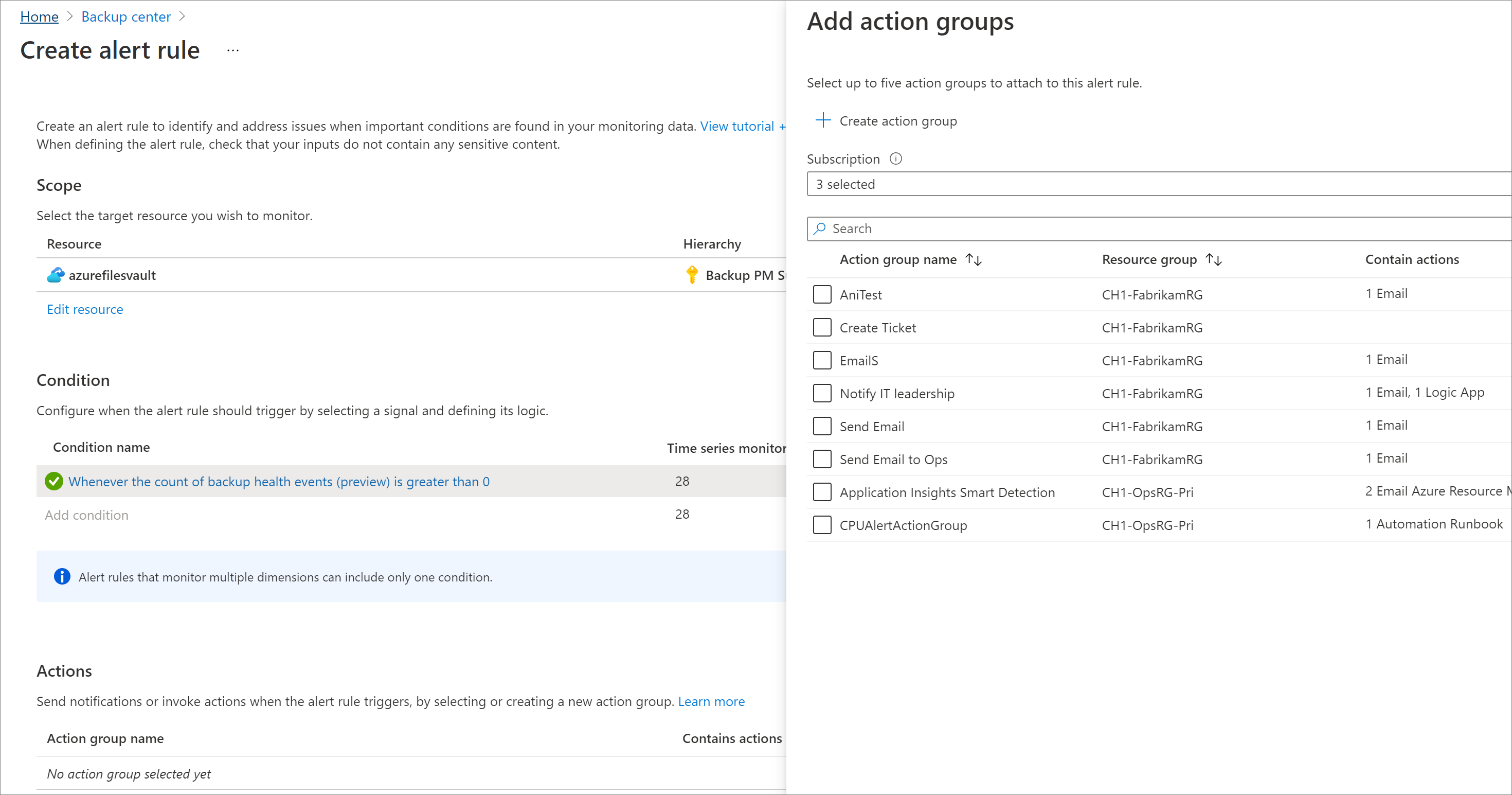
Configurer le comportement de résolution automatique : vous pouvez configurer des alertes de métriques comme sans état ou avec état en fonction des besoins.
- Pour générer une alerte à chaque échec de la tâche, quelle que soit la cause de l’échec, en raison de la même cause sous-jacente (comportement sans état), désélectionnez l’option Résoudre automatiquement les alertes dans la règle d’alerte.
- Sinon, pour configurer les alertes avec état, activez la même case à cocher. Par conséquent, lorsqu’une alerte de métrique est déclenchée sur l’étendue, un autre échec ne crée pas de nouvelle alerte de métrique. L’alerte est résolue automatiquement si la condition de génération d’alerte prend la valeur false pour trois cycles d’évaluation successifs. De nouvelles alertes sont générées si la condition prend à nouveau la valeur true.


En savoir plus sur le comportement avec état et sans état des alertes de métriques Azure Monitor.

Gestion des alertes
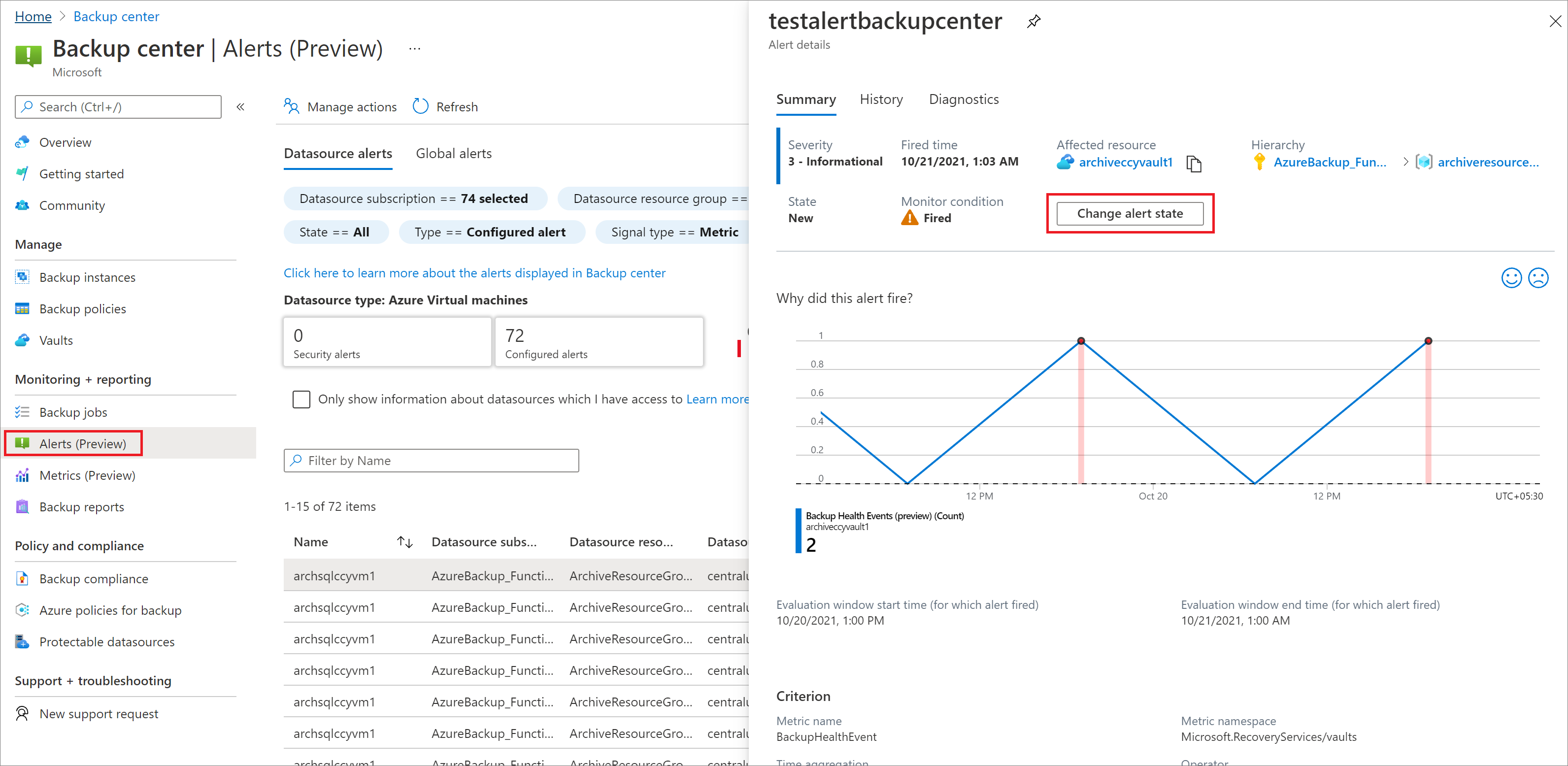
Pour afficher les alertes de métriques déclenchées, procédez comme suit :
Accédez àCentre de sauvegarde>Alertes.
Filtrage pour Type de signal = Métrique et Type d’alerte = Configuré.
Cliquez sur une alerte pour afficher plus de détails sur l’alerte et modifier son état.

Remarque
L’alerte comporte deux champs : Condition de surveillance (déclenchée/résolue) et État de l’alerte (nouveau/acquitter (ack)/fermé) .
- État de l’alerte : Vous pouvez modifier ce champ (comme indiqué dans la capture d’écran ci-dessous).
- Condition du surveillance : vous ne pouvez pas modifier ce champ. Ce champ est plus utilisé dans les scénarios où le service lui-même résout l’alerte. Par exemple, le comportement de résolution automatique dans les alertes de métriques utilise le champ Condition de surveillance pour résoudre une alerte.
Alertes de source de source et alertes globales
En fonction de la configuration des règles d’alerte, l’alerte déclenchée s’affiche sous la section Alertes de source de données ou Alertes globales du centre de sauvegarde :
- Si l’alerte déclenchée est associée à une dimension d’ID de source de données, l’alerte déclenchée s’affiche sous Alertes de source de données.
- Si aucune dimension d’ID de source de données n’est associée à l’alerte, l’alerte déclenchée s’affiche sous Alertes globales, car aucune information ne reliant l’alerte à une source de données spécifique n’est présente.
En savoir plus sur la source de données et les alertes globales ici
Notes
Actuellement, en cas d’alertes de restauration d’objets BLOB, les alertes s’affichent sous les alertes datasource uniquement si vous sélectionnez à la fois les dimensions- datasourceId et datasourceType lors de la création de la règle d’alerte. Si aucune dimension n’est sélectionnée, les alertes s’affichent sous les alertes globales.
Accès aux métriques par programmation
Vous pouvez utiliser les différents clients programmatiques, tels que PowerShell, l’interface CLI ou l’API REST, pour accéder à la fonctionnalité de métriques. Consultez Documentation sur l’API REST Azure Monitor pour plus de détails.
Exemples de scénarios d’alerte
Déclencher une seule alerte si toutes les sauvegardes déclenchées d’un coffre ont réussi au cours des dernières 24 heures
Règle d’alerte : déclencher une alerte si des événements d’intégrité de sauvegarde < 1 au cours des dernières 24 heures pour :
Dimensions["HealthStatus"] != "Healthy"
Déclencher une alerte après chaque travail de sauvegarde ayant échoué
Règle d’alerte : déclencher une alerte si des événements d’intégrité de sauvegarde > 0 au cours des 5 dernières minutes pour :
- Dimensions["HealthStatus"]!= "Healthy"
- Dimensions["DatasourceId"]= "Toutes les valeurs actuelles et futures"
Déclencher une alerte en cas d’échecs de sauvegarde consécutifs pour le même élément au cours des dernières 24 heures
Règle d’alerte : déclencher une alerte si des événements d’intégrité de sauvegarde > 1 au cours des dernières 24 heures pour :
- Dimensions["HealthStatus"]!= "Healthy"
- Dimensions["DatasourceId"]= "Toutes les valeurs actuelles et futures"
Déclencher une alerte si aucune tâche de sauvegarde n’a été exécutée pour un élément au cours des dernières 24 heures
Règle d’alerte : déclencher une alerte si des événements d’intégrité de sauvegarde < 1 au cours des dernières 24 heures pour :
Dimensions["DatasourceId"]= "Toutes les valeurs actuelles et futures"