Qu’est-ce que le magasin analytique Azure Cosmos DB ?
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Le magasin analytique Azure Cosmos DB est un magasin de colonnes totalement isolé qui permet d’effectuer des traitements analytiques à grande échelle sur les données opérationnelles de votre base de données Azure Cosmos DB sans incidence sur vos charges de travail transactionnelles.
Le magasin transactionnel Azure Cosmos DB est indépendant des schémas et il vous permet d’itérer sur vos applications transactionnelles sans avoir à vous soucier de la gestion des schémas ou des index. À l’inverse, le magasin analytique Azure Cosmos DB est schématisé pour optimiser les performances des requêtes analytiques. Cet article décrit en détail le stockage analytique.
Défis liés à l’analytique à grande échelle des données opérationnelles
Les données opérationnelles multi-modèles dans un conteneur de Azure Cosmos DB sont stockées en interne dans un « magasin transactionnel » basé sur des lignes indexées. Le format du magasin de lignes est conçu pour permettre des requêtes opérationnelles ainsi que des lectures et des écritures transactionnelles rapides avec des temps de réponse de l’ordre de la milliseconde. Si votre jeu de données devient volumineux, les requêtes analytiques complexes peuvent être coûteuses en termes de débit approvisionné sur les données stockées dans ce format. Une consommation élevée de débit approvisionné a également un impact sur les performances des charges de travail transactionnelles utilisées par vos applications et services en temps réel.
Traditionnellement, pour analyser de grandes quantités de données, les données opérationnelles sont extraites du magasin transactionnel de Azure Cosmos DB et stockées dans une couche de données distincte. Par exemple, les données sont stockées dans un entrepôt de données ou un lac de données dans un format approprié. Ces données sont ensuite utilisées pour l’analytique à grande échelle et analysées à l’aide du moteur de calcul, comme les clusters Apache Spark. La séparation des données analytiques et opérationnelles entraîne des retards pour les analystes qui souhaitent utiliser les données les plus récentes.
Les pipelines ETL deviennent également complexes lors du traitement des mises à jour des données opérationnelles par rapport au traitement des données opérationnelles nouvellement reçues.
Magasin analytique orienté colonne
Le magasin analytique Azure Cosmos DB traite les défis de complexité et de latence qui se produisent avec les pipelines ETL traditionnels. Le magasin analytique Azure Cosmos DB peut automatiquement synchroniser vos données opérationnelles dans un magasin en colonnes séparé. Le format du magasin de colonnes est approprié pour les requêtes analytiques à grande échelle qui sont exécutées de manière optimisée, ce qui permet d’améliorer la latence de ces requêtes.
À l’aide d’Azure Synapse Link, vous pouvez désormais créer des solutions HTAP non ETL en établissant une liaison directe avec le magasin analytique Azure Cosmos DB à partir d’Azure Synapse Analytics. Elle vous permet d’exécuter des analyses à grande échelle en temps quasi réel sur vos données opérationnelles.
Fonctionnalités du magasin analytique
Lorsque vous activez le magasin analytique sur un conteneur Azure Cosmos DB, un nouveau magasin de colonnes est créé en interne en fonction des données opérationnelles de votre conteneur. Ce magasin de colonnes est conservé séparément du magasin transactionnel orienté lignes pour ce conteneur, dans un compte de stockage entièrement géré par Azure Cosmos DB, dans un abonnement interne. Les clients n’ont pas besoin de consacrer du temps à l’administration du stockage. Les insertions, les mises à jour et les suppressions apportées à vos données opérationnelles sont automatiquement synchronisées avec le magasin analytique. Vous n’avez pas besoin du flux de modification ni de la procédure ETL pour synchroniser les données.
Magasin de colonnes pour les charges de travail analytiques sur les données opérationnelles
Les charges de travail analytiques impliquent généralement des agrégations et des analyses séquentielles de champs sélectionnés. En stockant les données dans un ordre colonne-principal, le magasin analytique permet de sérialiser un groupe de valeurs pour chaque champ. Ce format réduit le nombre d’IOPS nécessaires pour analyser ou calculer des statistiques sur des champs spécifiques. Il améliore considérablement les temps de réponse des requêtes pour les analyses sur de grands jeux de données.
Par exemple, si vos tables opérationnelles sont au format suivant :
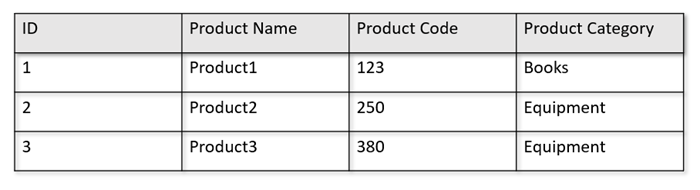
Le magasin de lignes conserve les données ci-dessus dans un format sérialisé par ligne sur le disque. Ce format permet des lectures, des écritures et des requêtes opérationnelles plus rapides, faisant suite une demande de retour d’informations sur un produit spécifique, par exemple. Toutefois, au fur et à mesure que la taille du jeu de données augmente, l’exécution de requêtes analytiques complexes sur les données peut s’avérer plus coûteuse. Par exemple, si vous souhaitez obtenir « les tendances des ventes d’un produit de la catégorie « Équipement » dans différentes unités commerciales et sur différents mois », vous devrez lancer une requête complexe. Les analyses de grande envergure sur ce jeu de données peuvent être coûteuses en termes de débit approvisionné et avoir également un impact sur les performances des charges de travail transactionnelles qui alimentent vos applications et services en temps réel.
Le magasin analytique, qui est un magasin de colonnes, est mieux adapté à ce type de requêtes car il sérialise ensemble des champs de données similaires et réduit le nombre d’IOPS sur le disque.
L’image suivante représente le magasin de lignes transactionnelles et le magasin de colonnes analytiques dans Azure Cosmos DB :
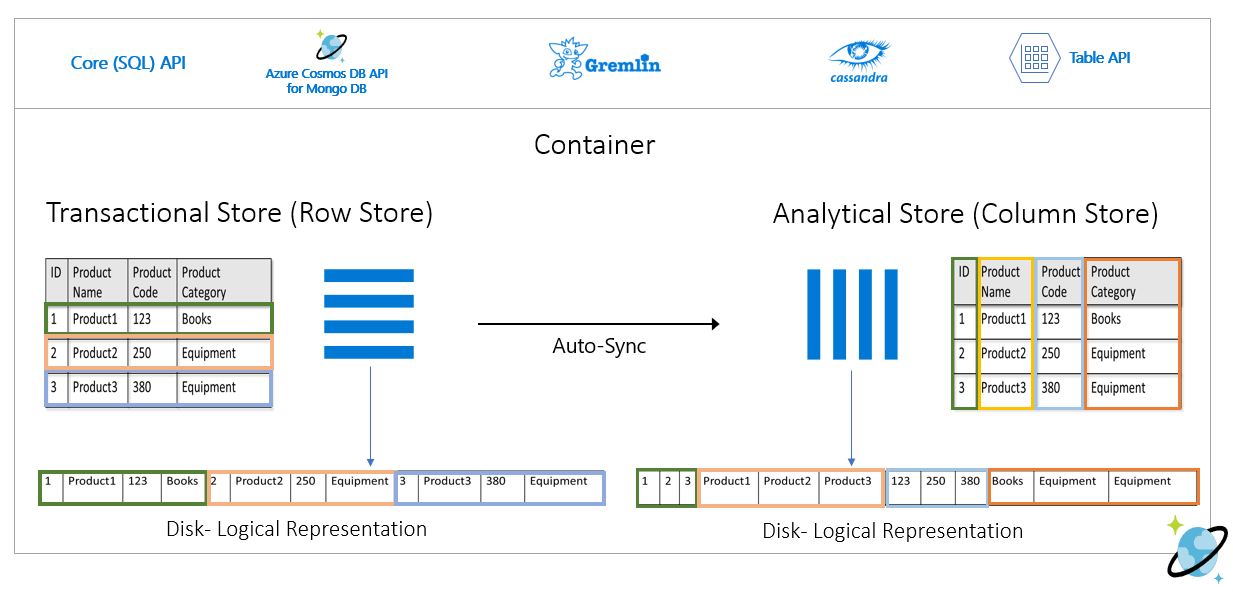
Performances découplées pour les charges de travail analytiques
Les requêtes analytiques n’ont aucune incidence sur les performances de vos charges de travail transactionnelles, car le magasin analytique est distinct du magasin transactionnel. Le magasin analytique n’impose pas d’allouer des unités de requête (RU, Request Unit) distinctes.
Synchronisation automatique
La synchronisation automatique fait référence à la fonctionnalité complètement managée d’Azure Cosmos DB où les insertions, les mises à jour, les suppressions de données opérationnelles sont automatiquement synchronisées à partir du magasin transactionnel vers le magasin analytique en temps quasi-réel en temps quasi-réel. La latence de synchronisation automatique est généralement en moins de 2 minutes. Dans le cas d’une base de données de débit partagé avec un grand nombre de conteneurs, la latence de la synchronisation automatique des conteneurs individuels peut être supérieure et prendre jusqu’à 5 minutes.
À la fin de chaque exécution du processus de synchronisation automatique, vos données transactionnelles seront immédiatement disponibles pour les runtimes Azure Synapse Analytics :
Les pools Spark d’Azure Synapse Analytics peuvent lire toutes les données, y compris les mises à jour les plus récentes, par le biais de tables Spark, qui sont mises à jour automatiquement, ou via la commande
spark.read, qui lit toujours le dernier état des données.Les pools SQL serverless d’Azure Synapse Analytics peuvent lire toutes les données, y compris les mises à jour les plus récentes, par le biais de vues, qui sont mises à jour automatiquement, ou via les commandes
SELECTetOPENROWSET, qui lisent toujours l’état le plus récent des données.
Notes
Vos données transactionnelles seront synchronisées au magasin analytique, même si la durée de vie (TTL) transactionnelle est inférieure à deux minutes.
Notes
Notez que si vous supprimez votre conteneur, le magasin analytique est également supprimé.
Extensibilité et élasticité
En utilisant le partitionnement horizontal, le magasin transactionnel Azure Cosmos DB peut mettre à l’échelle de manière élastique le stockage et le débit sans temps d’arrêt. Le partitionnement horizontal dans le magasin transactionnel est évolutif et élastique lors de la synchronisation automatique afin de garantir la synchronisation des données avec le magasin analytique quasiment en temps réel. La synchronisation des données se produit quel que soit le débit de trafic transactionnel (1 000, 1 million d’opérations/s, etc.). Elle n’a pas d’impact sur le débit approvisionné dans le magasin transactionnel.
Gérer automatiquement les mises à jour de schéma
Le magasin transactionnel Azure Cosmos DB est indépendant des schémas et il vous permet d’itérer sur vos applications transactionnelles sans avoir à vous soucier de la gestion des schémas ou des index. À l’inverse, le magasin analytique Azure Cosmos DB est schématisé pour optimiser les performances des requêtes analytiques. Grâce à la capacité de synchronisation automatique, Azure Cosmos DB gère l’inférence du schéma sur les dernières mises à jour du magasin transactionnel. Il gère aussi la représentation du schéma dans le magasin analytique, qui comprend la gestion des types de données imbriqués.
À mesure que votre schéma évolue et que de nouvelles propriétés sont ajoutées au fil du temps, le magasin analytique présente automatiquement un schéma uni dans tous les schémas historiques du magasin transactionnel.
Notes
Dans le contexte du magasin analytique, nous considérons les structures suivantes comme des propriétés :
- « Éléments » ou « paires chaîne-valeur séparées par le signe
:» JSON. - Objets JSON, délimités par les signes
{et}. - Tableaux JSON, délimités par les signes
[et].
Contraintes de schéma
Les contraintes suivantes s’appliquent aux données opérationnelles dans Azure Cosmos DB lorsque vous activez le magasin analytique pour inférer et représenter automatiquement le schéma correctement :
Vous pouvez spécifier au maximum 1 000 propriétés sur tous les niveaux imbriqués dans le schéma de document et une profondeur d’imbrication maximale de 127.
- Seules les 1 000 premières propriétés sont représentées dans le magasin analytique.
- Seuls les 127 premiers niveaux imbriqués sont représentés dans le magasin analytique.
- Le premier niveau d’un document JSON est son niveau racine
/. - Les propriétés du premier niveau du document sont représentées sous forme de colonnes.
Exemples de scénarios :
- Si le premier niveau de votre document comporte 2 000 propriétés, le processus de synchronisation représente les 1 000 premières d’entre elles.
- Si vos documents présentent cinq niveaux dont chacun comporte 200 propriétés, toutes les propriétés sont représentées.
- Si vos documents ont 10 niveaux disposant chacun de 400 propriétés, le processus de synchronisation représentera entièrement les deux premiers niveaux et seulement la moitié du troisième niveau.
Le document hypothétique ci-dessous contient quatre propriétés et trois niveaux.
- Les niveaux sont
root,myArrayet la structure imbriquée dansmyArray. - Les propriétés sont
id,myArray,myArray.nested1etmyArray.nested2. - La représentation du magasin analytique compte deux colonnes,
idetmyArray. Vous pouvez utiliser les fonctions Spark ou T-SQL pour exposer également les structures imbriquées en tant que colonnes.
- Les niveaux sont
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Le magasin analytique ne respecte pas la casse, à la différence des documents JSON (et des collections et conteneurs Azure Cosmos DB) qui la respectent du point de vue de l’unicité.
- Dans le même document : les noms de propriétés du même niveau doivent être uniques en cas de comparaison ne respectant pas la casse. Par exemple, le document JSON suivant contient « Name » et « name » dans le même niveau. Bien qu’il s’agisse d’un document JSON valide, il ne respecte pas la contrainte d’unicité. Il n’est donc pas pleinement représenté dans le magasin analytique. Dans cet exemple, « Name » et « name » sont identiques en cas de comparaison ne respectant pas la casse. Seul
"Name": "fred"sera représenté dans le magasin analytique, car il s’agit de la première occurrence. Et"name": "john"ne sera pas représentés du tout.
{"id": 1, "Name": "fred", "name": "john"}- Dans des documents différents : les propriétés dans le même niveau et portant le même nom, mais présentant des casses différentes, sont représentées dans la même colonne, en utilisant le format de nom de la première occurrence. Par exemple, les documents JSON suivants ont
"Name"et"name"dans le même niveau. Étant donné que le premier format de document est"Name", celiui-ci sera utilisé pour représenter le nom de la propriété dans le magasin analytique. En d’autres termes, le nom de colonne dans le magasin analytique sera"Name"."fred"et"john"sont représentés dans la colonne"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- Dans le même document : les noms de propriétés du même niveau doivent être uniques en cas de comparaison ne respectant pas la casse. Par exemple, le document JSON suivant contient « Name » et « name » dans le même niveau. Bien qu’il s’agisse d’un document JSON valide, il ne respecte pas la contrainte d’unicité. Il n’est donc pas pleinement représenté dans le magasin analytique. Dans cet exemple, « Name » et « name » sont identiques en cas de comparaison ne respectant pas la casse. Seul
Le premier document de la collection définit le schéma initial du magasin analytique.
- Les documents contenant plus de propriétés que le schéma initial génèrent de nouvelles colonnes dans le magasin analytique.
- Les colonnes ne peuvent pas être supprimées.
- La suppression de tous les documents d’une collection ne réinitialise pas le schéma du magasin analytique.
- Il n’existe pas de contrôle de version de schéma. C’est la dernière version inférée du magasin transactionnel qui apparaît dans le magasin analytique.
Actuellement, Azure Synapse Spark ne peut pas lire les propriétés qui contiennent des caractères spéciaux dans leurs noms (indiqués ci-dessous). Azure Synapse SQL serverless n’est pas affecté.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Notes
Les espaces blancs sont également répertoriés dans le message d’erreur Spark renvoyé lorsque vous atteignez cette limite. Mais nous avons ajouté un traitement spécial des espaces blancs. Consultez plus de détails dans les articles ci-dessous.
- Si vous avez des noms de propriétés qui utilisent les caractères répertoriés ci-dessus, les alternatives sont les suivantes :
- Modifiez votre modèle de données à l’avance pour éviter ces caractères.
- Étant donné que nous ne prenons pas en charge la réinitialisation de schéma, vous pouvez modifier votre application pour ajouter une propriété redondante portant un nom similaire, en évitant ces caractères.
- Utilisez le flux de modification pour créer une vue matérialisée de votre conteneur sans ces caractères dans les noms de propriétés.
- Utilisez l’option Spark
dropColumnpour ignorer les colonnes affectées et charger toutes les autres colonne dans un dataFrame. La syntaxe est :
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark prend désormais en charge les propriétés incluant des espaces blancs dans leurs noms. Pour ce faire, vous devez utiliser l’option Spark
allowWhiteSpaceInFieldNamespour charger les colonnes affectées dans un DataFrame, en conservant le nom d’origine. La syntaxe est :
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Les types de données BSON suivants ne sont pas pris en charge et ne sont pas représentés dans le magasin analytique :
- Decimal128
- Expression régulière
- Pointeur de base de données
- JavaScript
- Symbole
- MinKey/MaxKey
Lorsque vous utilisez des chaînes DateHeure qui suivent la norme ISO 8601 UTC, attendez-vous au comportement suivant :
- Les pools Spark dans Azure Synapse représenteront ces colonnes comme
string. - Les pools serverless SQL dans Azure Synapse représenteront ces colonnes comme
varchar(8000).
- Les pools Spark dans Azure Synapse représenteront ces colonnes comme
Les propriétés avec des types
UNIQUEIDENTIFIER (guid)sont représentées commestringdans le magasin analytique et doivent être converties enVARCHARdans SQL ou enstringdans Spark pour une visualisation correcte.Les pools serverless SQL dans Azure Synapse prennent en charge des ensembles de résultats contenant jusqu’à 1000 colonnes, et l’exposition de colonnes imbriquées est également comptabilisée dans cette limite. Il est recommandé de prendre en compte ces informations dans votre architecture et la modélisation de vos données transactionnelles.
Si vous renommez une propriété, dans un ou plusieurs documents, elle sera considérée comme une nouvelle colonne. Si vous exécutez le même changement de nom dans tous les documents de la collection, toutes les données sont migrées vers la nouvelle colonne et l’ancienne colonne est représentée par des valeurs
NULL.
Représentation du schéma
Il existe deux méthodes de représentation de schéma dans le magasin analytique, valides pour tous les conteneurs du compte de base de données. Ces modes présentent des compromis entre la simplicité de l’expérience de requête, et la simplicité d’une représentation en colonnes pour les schémas polymorphes :
- Représentation de schéma bien définie, option par défaut pour l’API pour les comptes NoSQL et Gremlin.
- Représentation du schéma de fidélité totale, option par défaut de l'API pour les comptes MongoDB.
Représentation de schéma bien définie
La représentation de schéma bien définie crée une représentation tabulaire simple des données indépendantes du schéma dans le magasin transactionnel. La représentation de schéma bien définie prend en compte les considérations suivantes :
- Le premier document définit le schéma de base, et les propriétés doivent toujours avoir le même type dans tous les documents. Les exceptions sont les suivantes :
- De
NULLà n’importe quel autre type de données. La première occurrence non Null définit le type de données de la colonne. Tout document ne suivant pas le premier type de données non Null n’est pas représenté dans le magasin analytique. - De
floatàintegerTous les documents sont représentés dans le magasin analytique. - De
integeràfloatTous les documents sont représentés dans le magasin analytique. Toutefois, pour lire ces données avec des pools serverless Azure Synapse SQL, vous devez utiliser une clause WITH pour convertir la colonne envarchar. Il est possible, après cette conversion initiale, de la reconvertir en nombre. Vérifiez l’exemple ci-dessous, où la valeur initiale num était entière, et la deuxième flottante.
- De
SELECT CAST (num as float) as num
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = '<your-connection',
OBJECT = 'IntToFloat',
SERVER_CREDENTIAL = 'your-credential'
)
WITH (num varchar(100)) AS [IntToFloat]
Les propriétés qui ne suivent pas le type de données de schéma de base ne sont pas représentées dans le magasin analytique. Par exemple, considérez les documents ci-dessous : le premier a défini le schéma de base du magasin analytique. Le deuxième document, dans lequel
idest"2", n’a pas de schéma bien défini, car la propriété"code"est une chaîne alors que, dans le premier document, la propriété"code"est un nombre. Dans ce cas, le magasin analytique inscrit le type de données"code"en tant que type de donnéesintegerpour toute la durée de vie du conteneur. Le deuxième document reste inclus dans un magasin analytique, mais pas sa propriété"code".{"id": "1", "code":123}{"id": "2", "code": "123"}
Notes
La condition ci-dessus ne s’applique pas aux propriétés NULL. Par exemple, {"a":123} and {"a":NULL} est encore bien défini.
Notes
La condition ci-dessus ne change pas si vous mettez à jour "code" du document "1" sur une chaîne dans votre magasin transactionnel. Dans le magasin analytique,"code" sera conservé comme integer étant donné que la réinitialisation du schéma n’est pas prise en charge pour le moment.
- Les types de tableau doivent contenir un type répété unique. Par exemple,
{"a": ["str",12]}n’est pas un schéma bien défini, car le tableau contient un mélange des types entier et chaîne.
Notes
Si le magasin analytique Azure Cosmos DB suit la représentation de schéma bien définie et que la spécification ci-dessus n’est pas respectée par certains éléments, ceux-ci ne sont pas inclus dans le magasin analytique.
Un comportement différent est attendu en ce qui concerne les différents types dans un schéma bien défini :
- Les pools Spark dans Azure Synapse représenteront ces valeurs comme
undefined. - Les pools serverless SQL dans Azure Synapse représenteront ces valeurs comme
NULL.
- Les pools Spark dans Azure Synapse représenteront ces valeurs comme
Un comportement différent est attendu en ce qui concerne les valeurs
NULLexplicites :- Les pools Spark dans Azure Synapse lire ces valeurs comme
0(zéro) et dèsundefinedque la colonne a une valeur non null. - Les pools SQL serverless dans Azure Synapse liront ces valeurs comme
NULL.
- Les pools Spark dans Azure Synapse lire ces valeurs comme
Un comportement différent est attendu en ce qui concerne les colonnes manquantes :
- Les pools Spark dans Azure Synapse représenteront ces colonnes comme
undefined. - Les pools serverless SQL dans Azure Synapse représenteront ces colonnes comme
NULL.
- Les pools Spark dans Azure Synapse représenteront ces colonnes comme
Solutions de contournement pour les problématiques de la représentation
Il est possible qu’un ancien document, avec un schéma incorrect, ait été utilisé pour créer le schéma de base du magasin analytique de votre conteneur. Sur la base de toutes les règles présentées ci-dessus, vous pouvez recevoir NULL pour certaines propriétés quand vous interrogez votre magasin analytique avec Azure Synapse Link. La suppression ou la mise à jour des documents problématiques n’est pas utile, car la réinitialisation du schéma de base n’est pas actuellement prise en charge. Voici les solutions possibles :
- Pour migrer les données vers un nouveau conteneur, vérifiez que tous les documents ont le schéma correct.
- Abandonner la propriété avec le mauvais schéma et en ajouter une nouvelle, avec un autre nom, qui dispose du bon schéma dans tous les documents. Exemple : vous avez des milliards de documents dans le conteneur Orders où la propriété status est une chaîne. Cependant, la propriété status du premier document de ce conteneur est définie avec un entier. Ainsi, un document aura une propriété status correctement représentée et tous les autres documents auront la valeur
NULLpour cette propriété. Vous pouvez ajouter la propriété status2 à tous les documents et commencer à l’utiliser au lieu de la propriété d’origine.
Représentation de schéma avec une fidélité optimale
La représentation du schéma de fidélité optimale est conçue pour gérer l’intégralité des schémas polymorphes dans les données opérationnelles indépendantes du schéma. Dans cette représentation de schéma, aucun élément n’est supprimé du magasin analytique, même si les contraintes de schéma bien définies (qui ne sont pas des champs de type de données mixtes ou des tableaux de types de données mixtes) ne sont pas respectées.
Pour cela, les propriétés du nœud terminal des données opérationnelles sont traduites dans le magasin analytique sous forme de paires key-value JSON, où le type de données est key et le contenu de la propriété est value. Cette représentation d’objet JSON autorise les requêtes sans ambiguïté, et vous pouvez analyser individuellement chaque type de données.
En d’autres termes, dans la représentation de schéma de fidélité complète, chaque type de données de chaque propriété de chaque document génère une paire key-value dans un objet JSON pour cette propriété. Chaque élément compte pour l’une des 1 000 propriétés de la limite maximale.
Prenons l’exemple de document suivant dans le magasin transactionnel :
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
L’objet imbriqué address est une propriété au niveau racine du document, représenté sous forme de colonne. Chaque propriété de nœud terminal dans l’objet address est représentée sous la forme d’un objet JSON : {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Contrairement à la représentation de schéma bien définie, la méthode de la fidélité optimale autorise une variation dans les types de données. Si le document suivant dans cette collection de l’exemple ci-dessus a streetNo comme chaîne, il est représenté dans le magasin analytique sous la forme "streetNo":{"string":15850}. Dans la méthode de schéma bien définie, il ne serait pas représenté.
Carte des types de données pour un schéma de fidélité optimale
Voici une carte des types de données MongoDB et de leurs représentations dans le magasin analytique dans une représentation de schéma de fidélité complète. La carte ci-dessous n'est pas valide pour les comptes d'API NoSQL.
| Type de données d’origine | Suffixe | Exemple |
|---|---|---|
| Double | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| Binary | ".binary" | 0 |
| Booléen | ".bool" | Vrai |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| Timestamp | ".timestamp" | Timestamp(0, 0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Document | ".object" | {"a": "a"} |
Un comportement différent est attendu en ce qui concerne les valeurs
NULLexplicites :- Les pools Spark dans Azure Synapse liront ces valeurs comme
0(zéro). - Les pools SQL serverless dans Azure Synapse liront ces valeurs comme
NULL.
- Les pools Spark dans Azure Synapse liront ces valeurs comme
Un comportement différent est attendu en ce qui concerne les colonnes manquantes :
- Les pools Spark dans Azure Synapse représenteront ces colonnes comme
undefined. - Les pools serverless SQL dans Azure Synapse représenteront ces colonnes comme
NULL.
- Les pools Spark dans Azure Synapse représenteront ces colonnes comme
Attendez-vous à un comportement différent en ce qui concerne les valeurs
timestamp:- Les pools Spark dans Azure Synapse liront ces valeurs comme
TimestampType,DateType, ouFloat. Cela dépend de la plage et de la manière dont l'horodatage a été généré. - Les pools SQL Serverless dans Azure Synapse liront ces valeurs comme
DATETIME2, allant de0001-01-01à9999-12-31. Les valeurs au-delà de cette plage ne sont pas prises en charge et entraînent un échec d’exécution pour vos requêtes. Si c’est votre cas, vous pouvez :- Supprimez la colonne de la requête. Pour conserver la représentation, vous pouvez créer une nouvelle propriété mettant en miroir cette colonne, mais dans la plage prise en charge, et l’utiliser dans vos requêtes.
- Utilisez la capture de données modifiées à partir d’un magasin analytique, sans frais d’unités de requête, pour transformer et charger les données dans un nouveau format, dans l’un des récepteurs pris en charge.
- Les pools Spark dans Azure Synapse liront ces valeurs comme
Utilisation du schéma de fidélité optimale avec Spark
Spark gère chaque type de données en tant que colonne lors du chargement dans un DataFrame. Prenons l’exemple d’une collection avec les documents ci-dessous.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Alors que le premier document a rating comme nombre et timestamp au format UTC, le deuxième document a rating et timestamp en tant que chaînes. En supposant que cette collection a été chargée dans DataFrame sans aucune transformation de données, la sortie de df.printSchema() est :
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
Dans une représentation de schéma bien définie, rating et timestamp du deuxième document ne sont pas représentés. Dans un schéma de fidélité optimale, vous pouvez utiliser les exemples suivants pour accéder individuellement à chaque valeur de chaque type de données.
Dans l’exemple ci-dessous, nous pouvons utiliser PySpark pour exécuter une agrégation :
df.groupBy(df.item.string).sum().show()
Dans l’exemple ci-dessous, nous pouvons utiliser PySQL pour exécuter une autre agrégation :
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Utilisation du schéma de fidélité optimale avec SQL
En considérant les mêmes documents que ceux de l’exemple Spark ci-dessus, les clients peuvent utiliser l’exemple de syntaxe suivant :
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
À partir de la requête ci-dessus, les clients peuvent implémenter des transformations à l’aide de cast, convert ou toute autre fonction T-SQL pour manipuler vos données. Les clients peuvent également masquer des structures de types de données complexes à l’aide de vues.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Utilisation du champ MongoDB _id
Le champ MongoDB _id est fondamental pour chaque collection dans MongoDB et possède à l’origine une représentation hexadécimale. Comme vous pouvez le voir dans le tableau ci-dessus, le schéma de fidélité optimale conserve ses caractéristiques, créant un défi pour sa visualisation dans Azure Synapse Analytics. Pour une visualisation correcte, vous devez convertir le type de données _id comme suit :
Utilisation du champ MongoDB _id dans Spark
L’exemple ci-dessous fonctionne sur les versions 2.x et 3.x de Spark :
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Utilisation du champ MongoDB _id dans SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET('CosmosDB',
'Your-account;Database=your-database;Key=your-key',
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Schéma de fidélité complet pour l'API pour les comptes NoSQL ou Gremlin
Il est possible d'utiliser le schéma de fidélité complet pour API pour les comptes NoSQL, au lieu de l'option par défaut, en définissant le type de schéma lors de l'activation de Synapse Link sur un compte Azure Cosmos DB pour la première fois. Voici les considérations relatives à la modification du type de représentation de schéma par défaut :
- Actuellement, si vous activez Synapse Link dans votre compte d'API NoSQL à l'aide du portail Azure, il sera activé en tant que schéma bien défini.
- Actuellement, si vous souhaitez utiliser un schéma de fidélité totale avec des comptes d’API NoSQL ou Gremlin, vous devez le définir au niveau du compte dans la même cli ou la même commande PowerShell qui activera Synapse Link au niveau du compte.
- Actuellement, Azure Cosmos DB for MongoDB n’est pas compatible avec cette possibilité de changer la représentation du schéma. Tous les comptes MongoDB auront toujours le type de représentation de schéma de fidélité optimale.
- La carte des types de données du schéma Full Fidelity mentionnée ci-dessus n'est pas valide pour les comptes d'API NoSQL qui utilisent des types de données JSON. Par exemple, les valeurs
floatetintegersont représentées commenumdans le magasin analytique. - Il n’est pas possible de réinitialiser le type de représentation du schéma d’une précision bien définie à une fidélité optimale ou inversement.
- Actuellement, le schéma des conteneurs dans le magasin analytique est défini lors de la création du conteneur, même si Synapse Link n’a pas été activé dans le compte de base de données.
- Les conteneurs ou les graphiques créés avant Synapse Link a été activé avec un schéma de fidélité totale au niveau du compte auront un schéma bien défini.
- Les conteneurs ou les graphiques créés après l’activation de Synapse Link avec un schéma de fidélité totale au niveau du compte auront un schéma de fidélité totale.
Le type de représentation du schéma doit être choisi en même temps que l’activation de Synapse Link sur le compte, à l’aide d’Azure CLI ou de PowerShell.
Avec Azure CLI :
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Notes
Dans la commande ci-dessus, remplacez create par update pour les comptes existants.
Avec PowerShell :
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Notes
Dans la commande ci-dessus, remplacez New-AzCosmosDBAccount par Update-AzCosmosDBAccount pour les comptes existants.
Durée de vie (TTL) analytique
La durée de vie analytique indique la durée pendant laquelle les données doivent être conservées dans le magasin analytique, pour un conteneur.
Le magasin analytique est activé lorsque la durée de vie analytique est définie sur une valeur autre que NULL et 0. Dans ce cas, les insertions, les mises à jour et les suppressions apportées aux données opérationnelles sont automatiquement synchronisées du magasin transactionnel vers le magasin analytique, quelle que soit la configuration de la durée de vie transactionnelle. La conservation de ces données transactionnelles dans le magasin analytique peut être contrôlée au niveau du conteneur par la propriété AnalyticalStoreTimeToLiveInSeconds.
Voici les configurations possibles de la durée de vie analytique :
Si la valeur est définie sur
0ouNULL: le magasin analytique est désactivé. Aucune donnée n’est répliquée du magasin transactionnel vers le magasin analytique.Si la valeur est définie sur
-1: le magasin analytique conserve toutes les données d’historique, indépendamment de la conservation des données dans le magasin transactionnel. Ce paramètre indique que le magasin analytique a une conservation infinie de vos données opérationnellesSi la valeur est définie sur un nombre entier positif
n: les éléments expirent du magasin analytiquensecondes après leur heure de dernière modification dans le magasin transactionnel. Ce paramètre peut être utilisé si vous souhaitez conserver vos données opérationnelles pendant une période limitée dans le magasin analytique, indépendamment de la conservation des données dans le magasin transactionnel.
Éléments à prendre en considération :
- Le magasin analytique peut, après avoir été activé avec une valeur de durée de vie analytique, être mis à jour avec une autre valeur valide.
- Si la durée de vie transactionnelle peut être définie au niveau du conteneur ou de l’élément, la durée de vie analytique, elle, ne peut actuellement être définie qu’au niveau du conteneur.
- Vous pouvez allonger la conservation de vos données opérationnelles dans le magasin analytique en définissant une durée de vie analytique supérieure ou égale à la durée de vie transactionnelle au niveau du conteneur.
- Vous pouvez mettre le magasin analytique en miroir par rapport au magasin transactionnel en définissant une durée de vie analytique égale à la durée de vie transactionnelle.
- Si la durée de vie analytique est supérieure à la durée de vie transactionnelle, les données existeront à un moment donné uniquement dans le magasin analytique. Toutes les données sont en lecture seule.
- Actuellement, nous ne supprimons aucune donnée du magasin analytique. Si vous définissez votre durée de vie analytique sur un entier positif, les données ne seront pas incluses dans vos requêtes et vous ne serez pas facturé pour celles-ci. Cependant, si vous redéfinissez la durée de vie analytique sur
-1, toutes les données apparaîtront à nouveau et vous commencerez à être facturé pour tout le volume de données.
Comment activer le magasin analytique sur un conteneur :
Sur le Portail Azure, l’option de durée de vie analytique est définie sur la valeur par défaut (-1) lorsqu’elle est activée. Vous pouvez modifier cette valeur en « n » secondes en accédant aux paramètres du conteneur sous Explorateur de données.
Dans le kit SDK Azure Management, les kits SDK Azure Cosmos DB, PowerShell et Azure CLI, vous pouvez activer l’option de durée de vie analytique en lui donnant la valeur -1 ou « n » secondes.
Pour plus d’informations, consultez Guide pratique pour configurer la durée de vie analytique d’un conteneur.
Analytique économique des données historiques
La hiérarchisation des données fait référence à la séparation des données entre les infrastructures de stockage optimisées pour différents scénarios. Cela améliore les performances globales et la rentabilité de la pile de données de bout en bout. Avec le magasin analytique, Azure Cosmos DB prend désormais en charge la hiérarchisation automatique des données du magasin transactionnel vers le magasin analytique avec différentes dispositions de données. Le magasin analytique optimisé en termes de coût de stockage par rapport au magasin transactionnel vous permet de conserver des échéances plus longues pour l’analyse historique des données opérationnelles.
Après avoir activé le magasin analytique, vous pouvez, selon les besoins de conservation des données des charges de travail transactionnelles, configurer la propriété transactional TTL de façon que les enregistrements soient automatiquement supprimés du magasin transactionnel au bout d’un certain temps. De même, la propriété analytical TTL vous permet de gérer le cycle de vie des données conservées dans le magasin analytique indépendamment du magasin transactionnel. En activant le magasin analytique et en configurant les propriétés TTL analytiques, vous pouvez hiérarchiser et définir de manière transparente la période de conservation des données pour les deux magasins.
Notes
Lorsque analytical TTL est supérieur à transactional TTL, votre conteneur va contenir des données qui existent uniquement dans le magasin analytique. Ces données sont lues uniquement et actuellement nous ne prenons pas en charge le niveau TTL de document dans le magasin analytique. Si vos données de conteneur peuvent avoir besoin d’une mise à jour ou d’une suppression à un moment donné à l’avenir, n’utilisez pas analytical TTL supérieur à transactional TTL. Cette fonctionnalité est recommandée pour les données qui n’auront pas besoin de mises à jour ou de suppressions à l’avenir.
Notes
Si votre scénario ne demande pas de suppressions physiques, vous pouvez adopter une approche de suppression/mise à jour logique. Insérez dans le magasin transactionnel une autre version du même document qui existe uniquement dans le magasin analytique, mais nécessite une suppression/mise à jour logique. Peut-être avec un indicateur indiquant qu’il s’agit d’une suppression ou d’une mise à jour d’un document expiré. Les deux versions du même document coexistent dans le magasin analytique, et votre application ne doit prendre en compte que la dernière.
Résilience
Le magasin analytique s’appuie sur Stockage Azure et offre la protection suivante contre les défaillances physiques :
- Par défaut, les comptes de bases de données Azure Cosmos DB allouent un magasin analytique aux comptes de stockage localement redondant (LRS). Le stockage localement redondant offre une durabilité des objets d’au moins 99,999999999 % (11 « neuf ») sur une année donnée.
- Si une région géographique du compte de bases de données est configurée pour la redondance interzone, elle est allouée dans des comptes de stockage redondant interzone (ZRS). Les clients doivent activer Zones de disponibilité sur une région de leur compte de bases de données Azure Cosmos DB pour que les données analytiques de cette région soient stockées dans ZRS. Le stockage ZRS offre une durabilité des ressources de stockage d’au moins 99,9999999999 % (12 neuf) sur une année donnée.
Pour plus d’informations sur la durabilité de Stockage Azure, cliquez ici.
Sauvegarde
Bien que le magasin analytique dispose d’une protection intégrée contre les défaillances physiques, la sauvegarde peut être nécessaire pour les suppressions accidentelles ou les mises à jour dans le magasin transactionnel. Dans ces cas, vous pouvez restaurer un conteneur et utiliser le conteneur restauré pour remplir les données dans le conteneur d’origine ou reconstruire entièrement le magasin analytique si nécessaire.
Notes
Actuellement, le magasin analytique n’est pas sauvegardé, il ne peut donc pas être restauré. Votre stratégie de sauvegarde ne peut pas être planifiée en s’appuyant dessus.
Synapse Link et le magasin analytique par conséquent ont un niveau de compatibilité différent avec les modes de sauvegarde Azure Cosmos DB :
- Le mode de sauvegarde périodique est entièrement compatible avec Synapse Link et ces deux fonctionnalités peuvent être utilisées dans le même compte de base de données.
- Actuellement, le mode de sauvegarde continue et Synapse Link ne sont pas pris en charge dans le même compte de bases de données. Les clients doivent choisir l’une de ces deux fonctionnalités et cette décision ne peut pas être modifiée.
Stratégies de sauvegarde
Il existe deux politiques de sauvegarde possibles et pour comprendre comment les utiliser, les détails suivants sur les sauvegardes Azure Cosmos DB sont très importants :
- Le conteneur d’origine est restauré sans magasin analytique dans les deux modes de sauvegarde.
- Azure Cosmos DB ne prend pas en charge le remplacement des conteneurs à partir d’une restauration.
Voyons maintenant comment utiliser des sauvegardes et des restaurations du point de vue du magasin analytique.
Restauration d’un conteneur avec TTTL >= ATTL
Quand transactional TTL est supérieur ou égale à analytical TTL, toutes les données du magasin analytique existent toujours dans le magasin transactionnel. En cas de restauration, vous avez deux situations possibles :
- Pour utiliser le conteneur restauré comme remplacement du conteneur d’origine. Pour reconstruire le magasin analytique, activez simplement Synapse Link au niveau du compte et au niveau du conteneur.
- Pour utiliser le conteneur restauré comme source de données pour remplir ou mettre à jour les données dans le conteneur d’origine. Dans ce cas, le magasin analytique reflète automatiquement les opérations de données.
Restauration d’un conteneur avec TTTL < ATTL
Quand transactional TTL est inférieur à analytical TTL, certaines données existent uniquement dans le magasin analytique et ne seront pas dans le conteneur restauré. Là encore, vous avez deux situations possibles :
- Pour utiliser le conteneur restauré comme remplacement du conteneur d’origine. Dans ce cas, lorsque vous activez Synapse Link au niveau du conteneur, seules les données qui étaient dans le magasin transactionnel seront incluses dans le nouveau magasin analytique. Toutefois, notez que le magasin analytique du conteneur d’origine reste disponible pour les requêtes tant que le conteneur d’origine existe. Vous souhaiterez peut-être modifier votre application pour interroger les deux.
- Pour utiliser le conteneur restauré comme source de données pour remplir ou mettre à jour les données dans le conteneur d’origine :
- Le magasin analytique reflète automatiquement les opérations de données pour les données qui se trouve dans le magasin transactionnel.
- Si vous réinscrire des données précédemment supprimées du magasin transactionnel en raison de
transactional TTL, ces données sont dupliquées dans le magasin analytique.
Exemple :
- La durée de vie transactionnelle du conteneur
OnlineOrdersest d’un mois, et sa durée de vie analytique d’un an. - Lorsque vous le restaurez sur
OnlineOrdersNewet que vous activez le magasin analytique pour le reconstruire, le magasin transactionnel et le magasin analytique ne comportent tous deux qu’un mois de données. - Le conteneur d’origine,
OnlineOrders, n’est pas supprimé. Son magasin analytique est toujours disponible. - Les nouvelles données ne sont ingérées que dans
OnlineOrdersNew. - Les requêtes analytiques effectuent une opération UNION ALL sur les magasins analytiques alors que les données d’origine sont toujours pertinentes.
Si vous voulez supprimer le conteneur d’origine sans perdre les données de son magasin analytique, vous pouvez conserver ce dernier dans un autre service de données Azure. Synapse Analytics permet d’effectuer des jointures entre des données stockées à différents emplacements. Par exemple, une requête Synapse Analytics joint les données du magasin analytique à des tables externes situées dans le Stockage Blob Azure, Azure Data Lake Storage, etc.
Il est important de noter que les données du magasin analytique suivent un schéma différent de celui du magasin transactionnel. Bien que vous puissiez générer des instantanés des données de votre magasin analytique et les exporter dans n’importe quel service de données Azure sans frais en unités de requête, nous ne pouvons pas garantir l’utilisation de cet instantané pour alimenter le magasin transactionnel. Ce processus n’est pas pris en charge.
Diffusion mondiale
Si vous avez un compte Azure Cosmos DB distribué globalement, une fois que vous avez activé le magasin analytique pour un conteneur, il est disponible dans toutes les régions de ce compte. Toutes les modifications apportées aux données opérationnelles sont répliquées globalement dans toutes les régions. Vous pouvez effectuer des recherches analytiques efficaces sur la copie régionale la plus proche de vos données dans Azure Cosmos DB.
Partitionnement
Le partitionnement du magasin analytique est complètement indépendant du partitionnement du magasin transactionnel. Par défaut, les données du magasin analytique ne sont pas partitionnées. Si vos requêtes analytiques ont des filtres fréquemment utilisés, vous avez la possibilité d’opérer un partitionnement sur la base de ces champs pour améliorer les performances des requêtes. Pour plus d’informations, consultez Présentation du partitionnement personnalisé et Comment configurer un partitionnement personnalisé.
Sécurité
L’authentification auprès du magasin analytique est la même qu’auprès du magasin transactionnel pour une base de données particulière. Vous pouvez utiliser des clés primaires, secondaires ou en lecture seule pour l’authentification. Vous pouvez tirer parti du service lié dans Synapse Studio pour empêcher le collage des clés Azure Cosmos DB dans les notebooks Spark. Pour Azure Synapse SQL serverless, vous pouvez utiliser les informations d’identification SQL pour empêcher également le collage des clés Azure Cosmos DB dans les notebooks SQL. L’accès à ces services liés ou à ces informations d’identification est ouvert à toute personne ayant accès à l’espace de travail. Notez que la clé Azure Cosmos DB en lecture seule peut également être utilisée.
Isolement réseau à l’aide de points de terminaison privés : vous pouvez contrôler indépendamment l’accès réseau aux données dans le magasin transactionnel et le magasin analytique. L’isolement réseau s’effectue à l’aide de points de terminaison privés managés distincts pour chaque magasin, au sein de réseaux virtuels managés dans les espaces de travail Azure Synapse. Pour plus d’informations, consultez l’article Configurer des points de terminaison privés pour le magasin analytique.
Chiffrement des données au repos : le chiffrement de votre magasin analytique est activé par défaut.
Chiffrement des données avec des clés managées par le client : vous pouvez chiffrer les données du magasin transactionnel et du magasin analytique de manière fluide en utilisant les mêmes clés managées par le client, de manière automatique et transparente. Azure Synapse Link prend uniquement en charge la configuration des clés gérées par le client en utilisant l’identité managée de votre compte Azure Cosmos DB. Vous devez configurer l’identité managée de votre compte dans votre stratégie d’accès Azure Key Vault avant d’activer Azure Synapse Link sur votre compte. Pour en savoir plus, consultez l’article Configurer des clés gérées par le client en utilisant les identités managées des comptes Azure Cosmos DB.
Notes
Si vous modifiez votre compte de base de données de Premier tiers à Identité affectée par le système ou l’utilisateur, tout en activant Azure Synapse Link dans votre compte de base de données, vous ne pouvez pas revenir à l’identité Premier tiers, car vous ne pouvez pas désactiver Synapse Link de votre compte de base de données.
Support de plusieurs runtimes Azure Synapse Analytics
Le magasin analytique est optimisé pour fournir une extensibilité, une élasticité et des performances pour les charges de travail analytiques sans aucune dépendance des runtimes de calcul. La technologie de stockage est auto-gérée pour optimiser vos charges de travail analytiques sans effort manuel.
En découplant le système de stockage analytique du système de calcul analytique, les données du magasin analytique Azure Cosmos DB peuvent être interrogées simultanément à partir des différents runtimes analytiques pris en charge par Azure Synapse Analytics. À l’heure actuelle, Azure Synapse Analytics prend en charge Apache Spark et le pool SQL serverless avec le magasin analytique Azure Cosmos DB.
Notes
Vous pouvez uniquement lire à partir du magasin analytique à l’aide des runtimes d’Azure Synapse Analytics. L’inverse est également vrai : les runtimes d’Azure Synapse Analytics peuvent uniquement lire à partir du magasin analytique. Seul le processus de synchronisation automatique peut modifier des données dans le magasin analytique. Vous pouvez réécrire des données dans le magasin transactionnel de Azure Cosmos DB à l’aide du pool Spark d’Azure Synapse Analytics, en utilisant le Kit de développement logiciel (SDK) OLTP Azure Cosmos DB intégré.
Tarifs
Le magasin analytique suit un modèle tarifaire basé sur la consommation selon lequel sont facturés les éléments suivants :
Stockage : volume des données conservées dans le magasin analytique chaque mois, y compris les données historiques définies par la durée de vie analytique.
Opérations d’écriture analytique : synchronisation complètement managée des mises à jour des données opérationnelles vers le magasin analytique à partir du magasin transactionnel (synchronisation automatique)
Opérations de lecture analytique : opérations de lecture effectuées sur le magasin analytique à partir des runtimes du pool Azure Synapse Analytics Spark et du pool SQL serverless.
La tarification du magasin analytique est distincte du modèle de tarification du magasin de transactions. Il n’existe pas de concept d’unités de requête approvisionnées dans le magasin analytique. Pour plus d’informations sur le modèle de tarification du magasin analytique, consultez la page de tarification Azure Cosmos DB.
Les données dans le magasin d’analytiques sont accessibles uniquement via Azure Synapse Link, qui s’effectue dans les runtimes Azure Synapse Analytics : les pools Apache Spark Azure Synapse et les pools SQL serverless Azure Synapse. Consultez la page de tarification d’Azure Synapse Analytics pour obtenir des informations complètes sur le modèle de tarification pour accéder aux données dans le magasin analytique.
Afin d’obtenir une estimation précise des coûts d’activation du magasin d’analytique sur un conteneur Azure Cosmos DB, du point de vue du magasin analytique, vous pouvez utiliser l’outil de planification Azure Cosmos DB Capacity et obtenir une estimation des coûts de votre magasin analytique et des opérations d’écriture.
Les estimations des opérations de lecture du magasin analytique ne sont pas incluses dans le module de calcul du coût de Azure Cosmos DB, car elles varient selon votre charge de travail analytique. Une estimation globale indique cependant que l’analyse de 1 To de données dans le magasin analytique entraîne généralement 130 000 opérations de lecture analytique et se traduit par un coût de 0,065 USD. Par exemple, si vous utilisez des pools SQL serverless Azure Synapse pour effectuer cette analyse de 1 To, cela coûtera 5 USD, d’après la page de tarification d’Azure Synapse Analytics. Le coût total final de cette analyse de 1 To sera de 5,065 USD.
Bien que l’estimation ci-dessus soit destinée à l’analyse de 1 To de données dans le magasin analytique, l’application de filtres réduit le volume de données analysées et détermine le nombre exact d’opérations de lecture analytique en fonction du modèle de tarification de la consommation. Une preuve de concept relative à la charge de travail analytique produirait une estimation plus fine des opérations de lecture analytique. Cette estimation n’inclut pas le coût d’Azure Synapse Analytics.
Étapes suivantes
Pour en savoir plus, consultez les documents suivants :