Azure Cosmos DB : Cas d’usage d’analytique No-ETL
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Azure Cosmos DB fournit différentes options d’analytique pour l’analytique sans ETL, en quasi-temps réel sur les données opérationnelles. Vous pouvez activer l’analytique sur vos données Azure Cosmos DB à l’aide des options suivantes :
- Mise en miroir d’Azure Cosmos DB dans Microsoft Fabric
- Azure Synapse Link pour Azure Cosmos DB
Pour en savoir plus sur ces options, consultez « Analytique et BI sur vos données Azure Cosmos DB. »
Important
La mise en miroir d’Azure Cosmos DB dans Microsoft Fabric est désormais disponible en préversion pour l’API NoSql. Cette fonctionnalité fournit toutes les fonctionnalités d’Azure Synapse Link avec de meilleures performances analytiques, la possibilité d’unifier votre patrimoine de données avec Fabric OneLake et d’ouvrir l’accès à vos données dans OneLake avec le format Delta Parquet. Si vous envisagez d’utiliser Azure Synapse Link, nous vous recommandons d’essayer la mise en miroir pour évaluer la compatibilité globale avec votre organisation. Pour commencer à mettre en miroir, cliquez sur ici.
L’analytique en quasi-temps réel sans ETL peut ouvrir différentes possibilités pour vos entreprises. Voici trois exemples de scénarios :
- Analyse de chaîne logistique, prévisions et rapports
- Personnalisation en temps réel
- Maintenance prédictive, détection d’anomalies dans les scénarios IoT
Analyse de chaîne logistique, prévisions et rapports
Les études montrent que l’incorporation d’analyse de Big Data dans les opérations logistiques débouchent sur une amélioration des délais de livraison et de l’efficacité de la chaîne logistique.
Les fabricants s’intègrent aux technologies cloud natives pour sortir des contraintes héritées des anciens systèmes ERP (planification des ressources d’entreprise) et SCM (gestion de la chaîne logistique). Alors que les chaînes logistiques génèrent de plus en plus de volumes de données opérationnelles (commande, expédition, données de transaction), les fabricants ont besoin d’une base de données opérationnelle. Cette base de données opérationnelle doit être mise à l’échelle pour gérer les volumes de données, ainsi qu’une plateforme analytique pour atteindre un niveau d’intelligence contextuelle en temps réel afin de garder un temps d’avance.
L’architecture suivante montre la puissance de l’utilisation d’Azure Cosmos DB comme base de données opérationnelle native dans le cloud dans l’analytique de la chaîne d’approvisionnement :
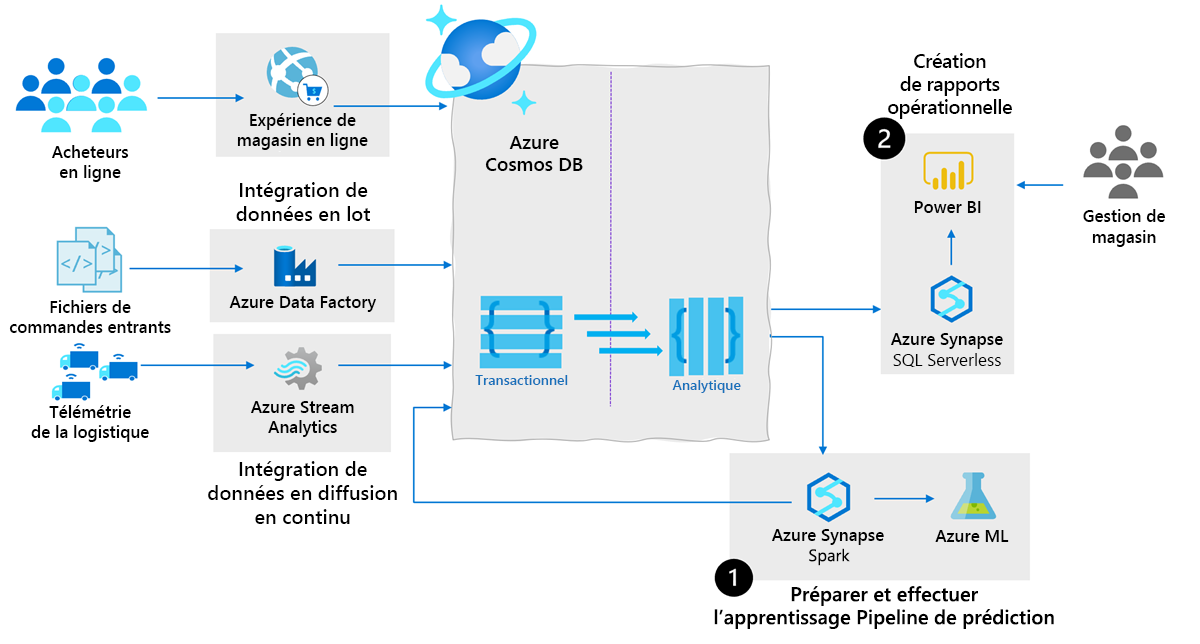
En fonction de l’architecture précédente, vous pouvez obtenir les cas d’usage suivants :
- Préparer et effectuer l’apprentissage d’un pipeline prédictif : générez des insights sur les données opérationnelles dans la chaîne logistique en utilisant des traductions Machine Learning. De cette façon, vous pouvez réduire les frais d’inventaire et d’exploitation et réduire les délais de livraison de la commande au client.
La mise en miroir et Synapse Link vous permettent d’analyser les données opérationnelles modifiées dans Azure Cosmos DB sans processus ETL manuels. Ces offres vous permettent de réduire les coûts supplémentaires, la latence et la complexité opérationnelle. Ils permettent aux ingénieurs données et aux scientifiques des données de créer des pipelines prédictifs robustes :
Interrogez des données opérationnelles à partir d’Azure Cosmos DB à l’aide de l’intégration native avec des pools Apache Spark dans Microsoft Fabric ou Azure Synapse Analytics. Vous pouvez interroger les données d’un bloc-notes interactif ou des tâches à distance planifiées sans ingénierie de données complexe.
Créez des modèles Machine Learning (ML) avec des algorithmes Spark ML et l’intégration d’Azure Machine Learning (AML) dans Microsoft Fabric ou Azure Synapse Analytics.
Réécrivez les résultats après l’inférence de modèle dans Azure Cosmos DB pour un scoring en quasi temps réel.
Rapports opérationnels : Les équipes responsables des chaînes logistiques ont besoin de rapports flexibles et personnalisés sur des données opérationnelles précises et en temps réel. Ces rapports sont nécessaires pour bénéficier d’une vue instantanée de l’efficacité, de la rentabilité et de la productivité de la chaîne logistique. Elle permet aux analystes de données et aux autres parties prenantes de réévaluer constamment l’activité et d’identifier les points à ajuster pour réduire les frais d’exploitation.
La mise en miroir et Synapse Link pour Azure Cosmos DB activent des scénarios décisionnels enrichis (BI)/reporting :
Interrogez des données opérationnelles à partir d’Azure Cosmos DB à l’aide de l’intégration native avec une expressivité complète du langage T-SQL.
Modélisez et publiez automatiquement des tableaux de bord BI sur Azure Cosmos DB via Power BI intégré dans Microsoft Fabric ou Azure Synapse Analytics.
Voici quelques conseils pour l’intégration de données pour les données par lot et les données en flux dans Azure Cosmos DB :
Orchestration et intégration de données par lot : les chaînes logistiques devenant de plus en plus complexes, les plateformes de données de chaîne logistique doivent intégrer de nombreux formats et sources de données. Microsoft Fabric et Azure Synapse sont intégrés avec le même moteur d’intégration de données et les mêmes expériences qu’Azure Data Factory. Cette intégration permet aux ingénieurs des données de créer des pipelines de données enrichis sans autre moteur d’orchestration :
Déplacez les données de plus de 85 sources de données prises en charge vers Azure Cosmos DB avec Azure Data Factory.
Écrivez des pipelines ETL sans code pour Azure Cosmos DB, y compris des mappages relationnels de hiérarchies et des mappages entre hiérarchies avec des flux de données de mappage.
Intégration et traitement des données de diffuser en continu : avec la croissance de l’IoT industriel (capteurs de suivi des ressources « de la production à la mise en vente », flottes logistiques connectées, etc.), il existe une explosion des données en temps réel générées de façon continue et qui doivent être intégrées aux données classiques plus lentes afin de générer des insights. Azure Stream Analytics est un service recommandé pour les flux ETL et le traitement sur Azure dans un large éventail de scénarios. Azure Stream Analytics prend en charge Azure Cosmos DB en tant que récepteur de données natif.
Personnalisation en temps réel
Les commerçants doivent désormais créer des solutions de commerce électronique sécurisées et évolutives qui répondent aux besoins des clients et des entreprises. Ces solutions de commerce électronique doivent attirer les clients avec des produits et des offres personnalisés, traiter les transactions de façon rapide et sécurisée, et se concentrer sur le traitement et le service clientèle. Azure Cosmos DB avec la dernière version de Synapse Link pour Azure Cosmos DB permet aux détaillants de générer des recommandations personnalisées pour les clients en temps réel. Ils utilisent des paramètres de cohérence ajustables à faible latence pour obtenir des insights immédiats, comme présenté dans l’architecture suivante :
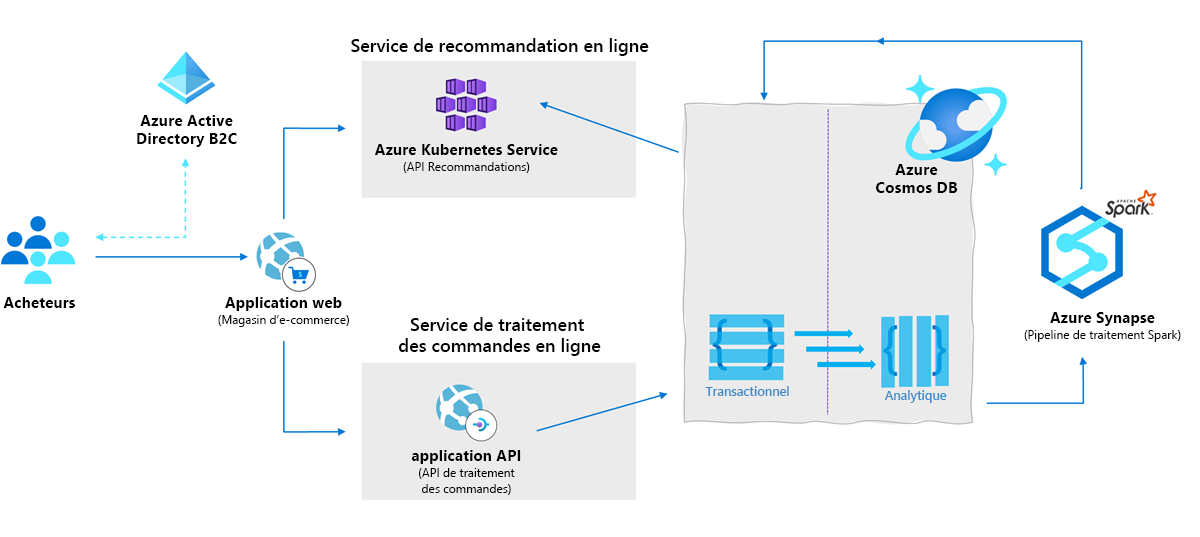
- Préparer et entraîner le pipeline prédictif : Vous pouvez générer des insights sur les données opérationnelles sur vos unités commerciales ou segments de clients à l’aide de modèles Fabric ou Synapse Spark et Machine Learning. Cela se traduit par une livraison personnalisée pour cibler des segments de clientèle, des expériences prédictives pour utilisateur final et un marketing ciblé pour répondre aux besoins de vos utilisateurs finaux. )
Maintenance prédictive IoT
Les innovations de l’IoT industriel ont considérablement réduit les temps d’arrêt des machines et accru l’efficacité globale dans tous les domaines de l’industrie. L’une de ces innovations est l’analytique de maintenance prédictive pour les machines périphérie du cloud.
Voici une architecture utilisant les fonctionnalités HTAP natives cloud dans la maintenance prédictive IoT :
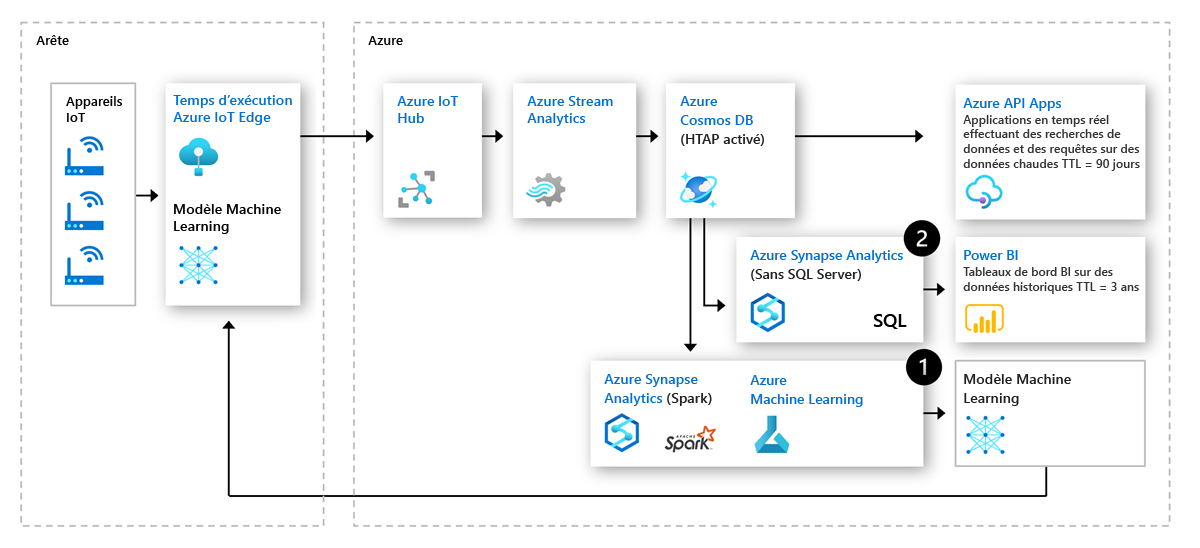
Préparer et effectuer l’apprentissage d’un pipeline prédictif : les données opérationnelles historiques des capteurs d’appareils IoT peuvent être utilisées pour effectuer l’apprentissage de modèles prédictifs, comme les détecteurs d’anomalies. Ces détecteurs d’anomalies sont ensuite déployés en périphérie pour une surveillance en temps réel. Cette boucle vertueuse permet d’effectuer un réapprentissage continu des modèles prédictifs.
Rapports opérationnels : Avec la croissance des initiatives numériques, les entreprises collectent de vastes quantités de données opérationnelles par l’intermédiaire de nombreux capteurs pour créer une copie numérique de chaque ordinateur. Ces données alimentent le décisionnel pour comprendre les tendances sur les données historiques en plus des données chaudes récentes.