Niveaux de cohérence dans Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Les bases de données distribuées qui reposent sur la réplication afin d’offrir une haute disponibilité, une faible latence ou les deux, constituent le compromis fondamental entre la cohérence de la lecture et la disponibilité, la latence et le débit comme déterminé par le théorème PACELC. La linéarisabilité du modèle de cohérence fort constitue la référence en matière de programmabilité des données. Mais cela augmente considérablement le coût des latences d’écriture en raison des données qui doivent être répliquées et validées sur de grandes distances. Une cohérence forte peut également souffrir d’une disponibilité réduite (pendant les défaillances), car les données ne peuvent pas être répliquées et validées dans chaque région. La cohérence éventuelle offre une disponibilité accrue et de meilleures performances, mais il est plus difficile de programmer des applications, car les données peuvent ne pas être cohérentes dans toutes les régions.
La plupart des bases de données NoSQL distribuées disponibles sur le marché offrent uniquement une cohérence forte et éventuelle. Azure Cosmos DB offre cinq niveaux bien définis. De la plus forte à la plus faible cohérence, les niveaux sont les suivants :
Pour plus d’informations sur le niveau de cohérence par défaut, consultez Configuration du niveau de cohérence par défaut ou Remplacer le niveau de cohérence par défaut.
Chaque niveau propose des compromis entre disponibilité et performances. L’illustration suivante montre les différents niveaux de cohérence en tant que spectre.
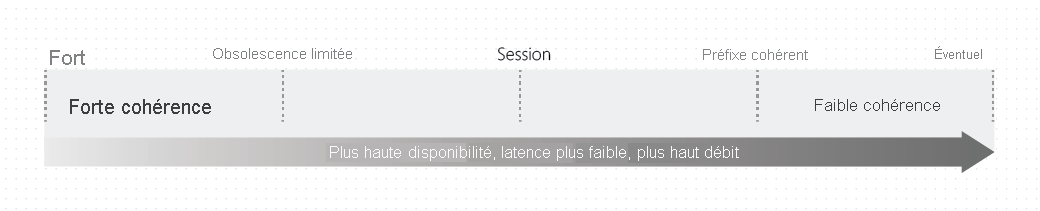
Niveaux de cohérence et API Azure Cosmos DB
Azure Cosmos DB fournit la prise en charge native des API compatibles avec les protocoles filaires pour les bases de données les plus courantes. Ces bases de données incluent le stockage Table Azure, MongoDB, Apache Cassandra et Apache Gremlin. Dans les API pour Gremlin ou Table, le niveau de cohérence configuré par défaut sur le compte Azure Cosmos DB est utilisé. Pour plus d’informations sur le mappage au niveau de cohérence entre Apache Cassandra et Azure Cosmos DB, consultez l’API pour le mappage de cohérence Cassandra. Pour plus d’informations sur le mappage au niveau de cohérence entre MongoDB et Azure Cosmos DB, consultez l’API pour le mappage de cohérence MongoDB.
Étendue de la cohérence de lecture
La cohérence de lecture s’applique à une même opération de lecture dans une partition logique. Un client distant, une procédure stockée ou un déclencheur peut émettre l’opération de lecture.
Configurer le niveau de cohérence par défaut
Vous pouvez configurer le niveau de cohérence par défaut sur votre compte Azure Cosmos DB à tout moment. Le niveau de cohérence par défaut configuré sur votre compte s’applique à toutes les bases de données Azure Cosmos DB et tous les conteneurs sous ce compte. Toutes les lectures et requêtes émises vers un conteneur ou une base de données utilisent le niveau de cohérence par défaut spécifié. Lorsque vous modifiez la cohérence au niveau de votre compte, veillez à redéployer vos applications et à apporter les modifications de code nécessaires pour appliquer ces modifications. Pour en savoir plus, consultez Configurer le niveau de cohérence par défaut. Vous pouvez également remplacer le niveau de cohérence par défaut pour une requête spécifique. Pour plus d’informations, consultez Guide pratique pour remplacer le niveau de cohérence par défaut.
Conseil
Le remplacement du niveau de cohérence par défaut s’applique uniquement aux lectures au sein du client de Kit de développement logiciel (SDK). Un compte configuré pour une cohérence forte par défaut continuera à écrire et à répliquer les données de façon synchrone dans chaque région du compte. Lorsque la requête ou l’instance du client de Kit de développement logiciel (SDK) remplace cette opération par une cohérence de session ou une cohérence plus faible, les lectures sont effectuées en utilisant un seul réplica. Pour plus d’informations, consultez Niveaux de cohérence et débit.
Important
Il est nécessaire de recréer une instance de Kit de développement logiciel (SDK) après avoir modifié le niveau de cohérence par défaut. Pour ce faire, vous pouvez redémarrer l’application. Cela garantit que le Kit de développement logiciel (SDK) utilise le nouveau niveau de cohérence par défaut.
Garanties associées aux niveaux de cohérence
Azure Cosmos DB garantit que 100 % des requêtes de lecture respecteront la garantie de cohérence dans le cadre du niveau de cohérence choisi. Les définitions précises des cinq niveaux de cohérence dans Azure Cosmos DB (en utilisant le langage de spécification TLA +) sont fournies dans le référentiel GitHub azure-cosmos-tla.
La sémantique des cinq niveaux de cohérence est décrite dans les sections suivantes :
Cohérence forte
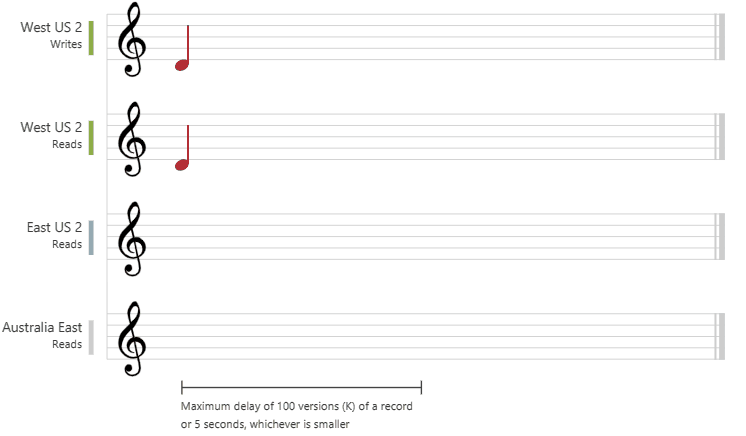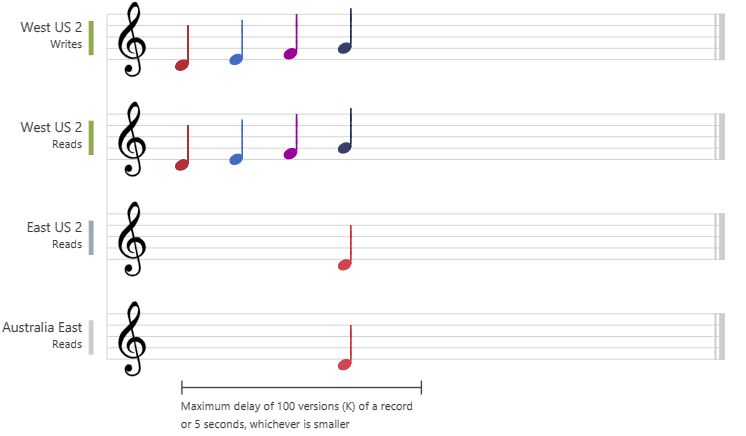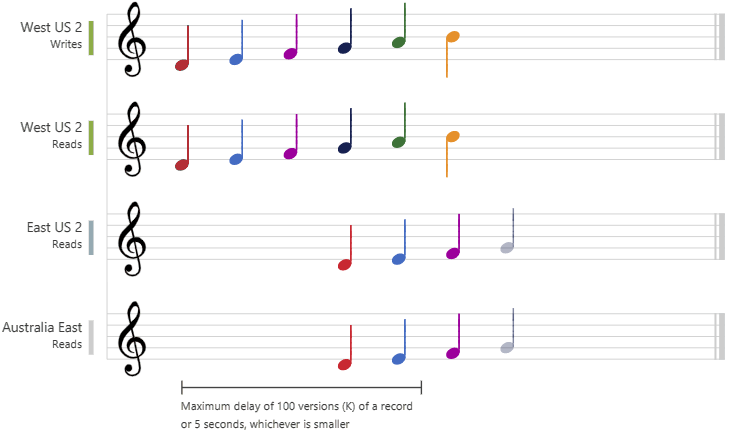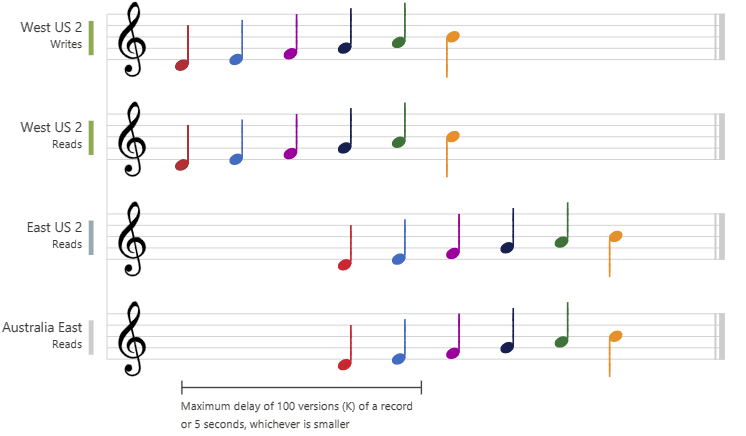
une cohérence forte offre une garantie de linéarisabilité. La linéarisabilité fait référence aux demandes de traitement simultanées. Garantit que les lectures retournent la version validée la plus récente d’un élément. Un client ne voit jamais une écriture partielle ou non validée. Les utilisateurs sont toujours assurés de lire la toute dernière écriture validée.
Le graphique suivant illustre la cohérence forte avec des notes musicales. Une fois les données écrites dans la région « USA Ouest 2 », quand vous lisez les données à partir d’autres régions, vous obtenez la valeur la plus récente :

Quorum dynamique
Dans des circonstances normales, pour un compte avec une cohérence forte, une écriture est considérée comme validée lorsque toutes les régions reconnaissent que l’enregistrement a été répliqué sur celles-ci. Toutefois, pour les comptes avec 3 régions ou plus (y compris la région d’écriture), le système peut « rétrograder » le quorum de régions vers une majorité globale dans les cas où certaines régions ne répondent pas ou répondent lentement. À ce stade, les régions qui ne répondent pas sont retirées de l’ensemble de régions du quorum afin de préserver une cohérence forte. Elles ne seront ré-ajoutées qu’une fois qu’elles sont cohérentes avec les autres régions et fonctionnent comme prévu. Le nombre de régions qui peuvent potentiellement être retirées de l’ensemble du quorum dépend du nombre total de régions. Par exemple, dans un compte à 3 ou 4 régions, la majorité est de 2 ou 3 régions respectivement. Par conséquent, seule 1 région peut être supprimée dans les deux cas. Pour un compte à 5 régions, la majorité est 3, donc jusqu’à 2 régions ne répondant pas peuvent être supprimées. Cette fonctionnalité est appelée « quorum dynamique » et peut améliorer la disponibilité en écriture et la latence de réplication pour les comptes avec 3 régions ou plus.
Remarque
Lorsque les régions sont supprimées de l’ensemble du quorum dans le cadre du quorum dynamique, ces régions ne sont plus en mesure de traiter les lectures jusqu’à ce qu’elles soient ré-ajoutées dans le quorum.
Niveau de cohérence obsolescence limitée
Pour les comptes d’écriture dans une seule région avec au moins deux régions, les données sont répliquées à partir de la région principale vers toutes les régions secondaires (en lecture seule). Pour les comptes d’écriture multirégion avec au moins deux régions, les données sont répliquées à partir de la région dans laquelle elles ont été écrites à l’origine vers toutes les autres régions accessibles en écriture. Dans les deux scénarios, bien que cela ne soit pas courant, il peut parfois y avoir un décalage de réplication d’une région à l’autre.
Dans la cohérence de l’obsolescence limitée, le décalage des données entre deux régions est toujours inférieur à une quantité spécifiée. La quantité peut être exprimée en « K » versions (c’est-à-dire « mises à jour ») d’un élément ou par rapport à « T » intervalles de temps, suivant le seuil qui est atteint en premier. En d’autres termes, lorsque vous choisissez l’obsolescence limitée, « l’obsolescence » maximum des données dans n’importe quelle région peut être configurée de deux manières :
- Nombre de versions (K) de l’élément
- Intervalle de temps (T) pendant lequel les lectures peuvent être en retard par rapport aux écritures
L’obsolescence limitée est principalement bénéfique pour les comptes d’écriture dans une seule région avec deux régions ou plus. Si le décalage des données dans une région (déterminé par partition physique) dépasse la valeur d’obsolescence configurée, les écritures pour cette partition sont limitées jusqu’à ce que l’obsolescence soit rétablie dans la limite supérieure configurée.
Pour un compte monorégion, l’obsolescence limitée fournit les mêmes garanties de cohérence d’écriture que les niveaux de cohérence Session et Éventuel. Avec l’obsolescence limitée, les données sont répliquées vers une majorité locale (trois réplicas dans un jeu de quatre réplicas) dans la région unique.
Important
Avec la cohérence de l’obsolescence limitée, les vérifications de l’obsolescence sont effectuées uniquement entre les régions et pas au sein d’une région. Dans une région donnée, les données sont toujours répliquées vers une majorité locale (trois réplicas dans un jeu de quatre réplicas) quel que soit le niveau de cohérence.
Les lectures lors de l’utilisation de l’obsolescence limitée retournent les dernières données disponibles dans cette région en lisant à partir de deux réplicas disponibles dans cette région. Étant donné que les écritures dans une région sont toujours répliquées vers une majorité locale (trois réplicas sur quatre), la consultation de deux réplicas retourne les données les plus à jour disponibles dans cette région.
Important
Avec la cohérence de l’obsolescence limitée, les lectures émises sur une région non primaire peuvent ne pas nécessairement retourner la version la plus récente des données globalement, mais sont garanties de retourner la version la plus récente des données dans cette région, qui se trouve dans la limite d’obsolescence maximale globale.
L’obsolescence limitée fonctionne mieux pour les applications distribuées à l’échelle mondiale utilisant des comptes d’écriture dans une seule région avec au moins deux régions, où une cohérence presque forte entre les régions est souhaitée. Pour les comptes d’écriture multirégion avec deux régions ou plus, les serveurs d’applications doivent diriger les lectures et les écritures vers la même région dans laquelle les serveurs d’applications sont hébergés. L’obsolescence limitée dans un compte à plusieurs écritures est un anti-modèle. Ce niveau nécessite une dépendance sur le décalage de réplication entre les régions, ce qui n’a pas d’importance si les données sont lues à partir de la même région dans laquelle elles ont été écrites.
Le graphique suivant illustre la cohérence à obsolescence limitée avec des notes musicales. Une fois les données écrites dans la région « USA Ouest 2 », les régions « USA Est 2 » et « Australie Est » lisent la valeur écrite en fonction de la durée de latence maximum configurée ou du nombre maximal d’opérations :
Cohérence de session
Avec une cohérence de session, dans une session à un seul client, il est garanti que les lectures honorent les lectures de vos écritures et les écritures suivant les lectures. Cette garantie suppose une session avec un seul « processus d’écriture » ou le partage du jeton de session pour plusieurs processus d’écriture.
Comme tous les niveaux de cohérence inférieurs au niveau Fort (Strong), les écritures sont répliquées sur un minimum de trois réplicas (dans un jeu de quatre réplicas) dans la région locale, avec une réplication asynchrone vers toutes les autres régions.
Après chaque opération d’écriture, le client reçoit un jeton de session mis à jour du serveur. Le client met en cache les jetons et les envoie au serveur pour les opérations de lecture dans une région spécifiée. Si le réplica sur lequel l’opération de lecture est émise contient des données pour le jeton spécifié (ou un jeton plus récent), les données demandées sont retournées. Si le réplica ne contient pas de données pour cette session, le client renvoie la demande auprès d’un autre réplica dans la région. Si nécessaire, le client retente la lecture dans d’autres régions disponibles jusqu’à ce que les données pour le jeton de session spécifié soient récupérées.
Important
Dans Cohérence de session, l’utilisation par le client d’un jeton de session garantit que les données correspondant à une session plus ancienne ne seront jamais lues. Toutefois, si le client utilise un jeton de session plus ancien et que des mises à jour plus récentes ont été apportées à la base de données, la version plus récente des données est retournée malgré l’utilisation d’un jeton de session plus ancien. Le jeton de session est utilisé comme une barrière de version minimale, mais pas spécifique (éventuellement historique) des données à récupérer à partir de la base de données.
Les jetons de session dans Azure Cosmos DB sont liés à la partition, ce qui signifie qu’ils sont exclusivement associés à une partition. Pour veiller à ce que vous puissiez lire vos écritures, utilisez le jeton de session qui a été généré pour la dernière fois pour le ou les éléments appropriés.
Si le client n’a pas lancé d’écriture dans une partition physique, il ne contient pas de jeton de session dans son cache et les lectures dans cette partition physique se comportent comme des lectures avec Cohérence éventuelle. De même, si le client est recréé, son cache de jetons de session est également recréé. Ici aussi, les opérations de lecture suivent le même comportement que Cohérence éventuelle jusqu’à ce que des opérations d’écriture suivantes regénèrent le cache du client des jetons de session.
Important
Si des jetons de session sont passés d’une instance cliente à une autre, le contenu du jeton ne doit pas être modifié.
La cohérence de session est le niveau de cohérence le plus utilisé pour les applications limitées à une seule région et les applications distribuées dans le monde entier. Elle propose des latences en écriture, une disponibilité et un débit de lecture comparables à ceux de la cohérence éventuelle. La cohérence de session fournit aussi des garanties de cohérence qui répondent aux besoins des applications écrites pour agir dans le contexte de l’utilisateur. Le graphique suivant illustre la cohérence de session avec des notes musicales. Le « processus d’écriture USA Ouest 2 » et le « processus de lecture USA Est 2 » utilisent la même session (session A) et lisent donc les mêmes données en même temps. En revanche, la région « Australie Est » utilise « Session B » et reçoit les données plus tard, mais dans le même ordre que les écritures.

Niveau de cohérence préfixe cohérent
Comme tous les niveaux de cohérence inférieurs au niveau Fort (Strong), les écritures sont répliquées sur un minimum de trois réplicas (dans un jeu de quatre réplicas) dans la région locale, avec une réplication asynchrone vers toutes les autres régions.
Dans le préfixe cohérent, les mises à jour effectuées en tant qu’écritures de documents uniques voient la cohérence éventuelle.
Les mises à jour effectuées en tant que lot dans une transaction, sont retournées cohérentes avec la transaction dans laquelle elles ont été validées. Les opérations d’écriture dans une transaction de plusieurs documents sont toujours visibles ensemble.
Supposons que deux opérations d’écriture sont effectuées de manière transactionnelle (opérations de type tout ou rien) sur le document Doc1 suivi du document Doc2, dans les transactions T1 et T2. Quand le client effectue une lecture dans n’importe quel réplica, l’utilisateur voit « Doc1 v1 et Doc2 v1 » ou « Doc1 v2 et Doc2 v2 » ou aucun des deux documents si le réplica est en retard, mais jamais « Doc1 v1 et Doc2 v2 », ni « Doc1 v2 et Doc2 v1 » pour la même opération de lecture ou de requête.
Le graphique suivant illustre la cohérence avec préfixe cohérent avec des notes musicales. Dans toutes les régions, les lectures ne voient jamais des écritures dans le désordre pour un lot transactionnel d’écritures :

Cohérence éventuelle
Comme tous les niveaux de cohérence inférieurs au niveau Fort (Strong), les écritures sont répliquées sur un minimum de trois réplicas (dans un jeu de quatre réplicas) dans la région locale, avec une réplication asynchrone vers toutes les autres régions.
Dans la cohérence éventuelle, le client émet des demandes de lecture sur l’un des quatre réplicas dans la région spécifiée. Ce réplica peut être en retard et peut retourner des données obsolètes ou aucune donnée.
La cohérence éventuelle est la forme de cohérence la plus faible, car un client peut lire des valeurs plus anciennes que celles qu’il a lues dans le passé. La cohérence éventuelle est idéale quand l’application ne demande aucune garantie de classement. Comme exemples, citons le nombre de retweets, de mentions J’aime ou de commentaires non liés à un thread. Le graphique suivant illustre la cohérence éventuelle avec des notes musicales.

Garanties de cohérence en pratique
En pratique, vous pouvez obtenir de meilleures garanties de cohérence. Les garanties de cohérence pour une opération de lecture correspondent à l’actualisation et au classement de l’état de la base de données que vous demandez. La cohérence de lecture est liée au classement et à la propagation des opérations d’écriture/mise à jour.
Si aucune opération d’écriture n’est effectuée sur la base de données, une opération de lecture avec un niveau de cohérence éventuelle, session ou préfixe cohérent risque de produire les mêmes résultats qu’une opération de lecture avec un niveau de cohérence forte.
Si votre compte est configuré avec un niveau de cohérence autre que la cohérence forte, vous pouvez déterminer la probabilité que vos clients bénéficieront de lectures fortes et cohérentes pour vos charges de travail. Vous pouvez déterminer cette probabilité en examinant la métrique PBS (Probabilistically Bounded Staleness). Cette métrique est exposée dans le portail Azure. Pour en savoir plus, consultez Surveiller la métrique de probabilités en fonction de l’obsolescence limitée (PBS).
La métrique Probabilistically Bounded Staleness montre à quel point votre cohérence éventuelle est possible. Cette métrique fournit une idée de la fréquence à laquelle vous pouvez obtenir une cohérence plus forte que le niveau de cohérence que vous avez configuré sur votre compte Azure Cosmos DB. En d’autres termes, vous pouvez voir la probabilité (mesurée en millisecondes) d’obtenir des lectures cohérentes pour une combinaison de régions d’écriture et de lecture.
Niveaux de cohérence et latence
La latence de lecture est toujours garantie inférieure à 10 millisecondes au 99e centile pour tous les niveaux de cohérence. La latence de lecture moyenne (au 50e centile) est généralement inférieure ou égale à 4 millisecondes.
La latence d’écriture est toujours garantie inférieure à 10 millisecondes au 99e centile pour tous les niveaux de cohérence. La latence d’écriture moyenne (au 50e centile) est généralement inférieure ou égale à 5 millisecondes. Les comptes Azure Cosmos DB qui s’étendent sur plusieurs régions et sont configurés avec une cohérence forte constituent une exception à cette garantie.
Latence d’écriture et cohérence forte
Pour les comptes Azure Cosmos DB configurés avec une cohérence forte et plusieurs régions, la latence d’écriture est égale à deux allers-retours (RTT) entre deux des régions les plus éloignées, plus 10 millisecondes au 99e centile. Un temps d’aller-retour réseau élevé entre les régions se traduira par une latence plus élevée pour les requêtes Azure Cosmos DB, car la cohérence forte effectue une opération seulement après avoir vérifié qu’elle a été validée dans toutes les régions d’un compte.
La latence exacte de la durée des boucles s’exprime en fonction de la distance à la vitesse de la lumière et de la topologie de réseau Azure. La mise en réseau Azure ne fournit pas de contrats SLA de latence pour le RTT entre deux régions Azure. Toutefois, il publie des Statistiques de latence aller-retour réseau Azure. Pour votre compte Azure Cosmos DB, les latences de réplication sont affichées dans le portail Azure. Vous pouvez utiliser le portail Azure en accédant à la section Métriques, puis en sélectionnant l’option Cohérence. En utilisant le portail Azure, vous pouvez superviser les latences de réplication entre les différentes régions associées à votre compte Azure Cosmos DB.
Important
Une cohérence forte pour les comptes dont les régions sont distantes de plus de 8 000 kilomètres est bloquée par défaut en raison d’une latence d’écriture élevée. Pour activer cette fonctionnalité, contactez le support technique.
Niveaux de cohérence et débit
Pour une obsolescence forte et limitée, les lectures sont effectuées sur deux réplicas dans un jeu de quatre réplicas (quorum minoritaire) pour fournir des garanties de cohérence. Les niveaux Session, Préfixe cohérent et À terme font des lectures sur un seul réplica. Le résultat est que, pour le même nombre d’unités de requête, le débit de lecture pour l’obsolescence forte et limitée est la moitié de celui des autres niveaux de cohérence.
Pour un type donné d’opération d’écriture, tel qu’insert, replace, upsert et delete, le débit d’écriture des unités de requête est identique pour tous les niveaux de cohérence. Pour une cohérence forte, les changements doivent être validés dans chaque région (majorité globale), alors que pour tous les autres niveaux de cohérence, la majorité locale (trois réplicas dans un jeu de quatre réplicas) est utilisée.
| Niveau de cohérence | Lectures de quorum | Écritures de quorum |
|---|---|---|
| Fort | Minorité locale | Majorité globale |
| Obsolescence limitée | Minorité locale | Majorité locale |
| Session | Réplica unique (avec un jeton de session) | Majorité locale |
| Préfixe cohérent | Réplica unique | Majorité locale |
| Éventuel | Réplica unique | Majorité locale |
Remarque
Le coût des lectures des RU pour les lectures de minorité locale est le double de celui des niveaux de cohérence plus faibles, car les lectures sont effectuées à partir de deux réplicas afin de fournir des garanties de cohérence pour les niveaux de cohérence Fort et Obsolescence limitée.
Niveaux de cohérence et durabilité des données
Dans un environnement de base de données globalement distribuée, il existe une relation directe entre le niveau de cohérence et la durabilité des données en situation de panne à l'échelle d'une région. Au moment d’élaborer votre plan de continuité d’activité, vous devez déterminer la période maximale de mises à jour de données récentes que l’application peut tolérer de perdre lors de la récupération après un événement perturbateur. Il s’agit de l’objectif de point de récupération (RPO, recovery point objective).
Ce tableau définit la relation entre le modèle de cohérence et la durabilité des données en situation de panne à l’échelle d’une région.
| Région(s) | Mode de réplication | Niveau de cohérence | RPO |
|---|---|---|---|
| 1 | Une ou plusieurs régions d’écriture | Tous les niveaux de cohérence | < 240 minutes |
| >1 | Région d’écriture unique | Session, Préfixe cohérent et Éventuel | < 15 minutes |
| >1 | Région d’écriture unique | Obsolescence limitée | K & T |
| >1 | Région d’écriture unique | Remarque | 0 |
| >1 | Régions d’écriture multiples | Session, Préfixe cohérent et Éventuel | < 15 minutes |
| >1 | Régions d’écriture multiples | Obsolescence limitée | K & T |
K = nombre de versions « K » (mises à jour) d’un élément.
T = intervalle de temps « T » depuis la dernière mise à jour.
Pour un compte à région unique, la valeur minimale de K et de T est de 10 opérations d’écriture ou de 5 secondes. Pour les comptes à plusieurs régions, la valeur minimale de K et T est de 100 000 opérations d’écriture ou de 300 secondes. Cette valeur définit le RPO minimal pour les données lors de l’utilisation de l’obsolescence limitée.
Cohérence forte et régions d’écriture multiples
Les comptes Azure Cosmos DB configurés avec plusieurs régions d’écriture ne peuvent pas être configurés pour une cohérence forte, car il n’est pas possible qu’un système distribué fournisse un objectif de point de récupération (RPO) et un objectif de délai de récupération (RTO) tous de valeur zéro. En outre, il n’y a pas d’avantage en termes de latence d’écriture à utiliser une cohérence forte avec les régions d’écriture multiples, car l’écriture dans une région doit être répliquée et validée dans toutes les régions configurées au sein du compte. Ce scénario aboutit à une latence d’écriture identique à celle d’une région d’écriture unique.
Plus de lecture
Pour en savoir plus sur les concepts de cohérence, lisez les articles suivants :
- Spécifications TLA + de haut niveau pour les cinq niveaux de cohérence proposés par Azure Cosmos DB
- La cohérence des données répliquées expliquée par le base-ball (vidéo) par Doug Terry
- La cohérence des données répliquées expliquée par le base-ball (livre blanc) par Doug Terry
- Garanties de session pour des données répliquées peu cohérentes
- Compromis de cohérence en termes de conception de systèmes de base de données distribuée modernes : CAP n’est qu’une partie de l’histoire
- Probabilistic Bounded Staleness (PBS) for Practical Partial Quorums (Probabilités en fonction de l’obsolescence limitée (PBS) pour les quorums partiels pratiques)
- Niveau de cohérence éventuel repensé