Superviser les performances, l’intégrité et l’utilisation d’Azure Data Explorer avec des métriques
Les métriques Azure Data Explorer fournissent des indicateurs clés concernant l’intégrité et les performances des ressources du cluster Azure Data Explorer. Utilisez les métriques détaillées dans cet article pour superviser l’utilisation, l’intégrité et les performances du cluster Azure Data Explorer dans votre scénario spécifique en tant que métriques autonomes. Vous pouvez également utiliser des métriques comme base pour les tableaux de bord Azure et les alertes Azure operationnels.
Pour plus d’informations sur Azure Metrics Explorer, consultez Metrics Explorer.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
Utiliser des métriques pour superviser vos ressources Azure Data Explorer
- Connectez-vous au portail Azure.
- Dans le volet gauche de votre cluster Azure Data Explorer, recherchez métriques.
- Sélectionnez Métriques pour ouvrir le volet de métriques et commencer l’analyse sur votre cluster.
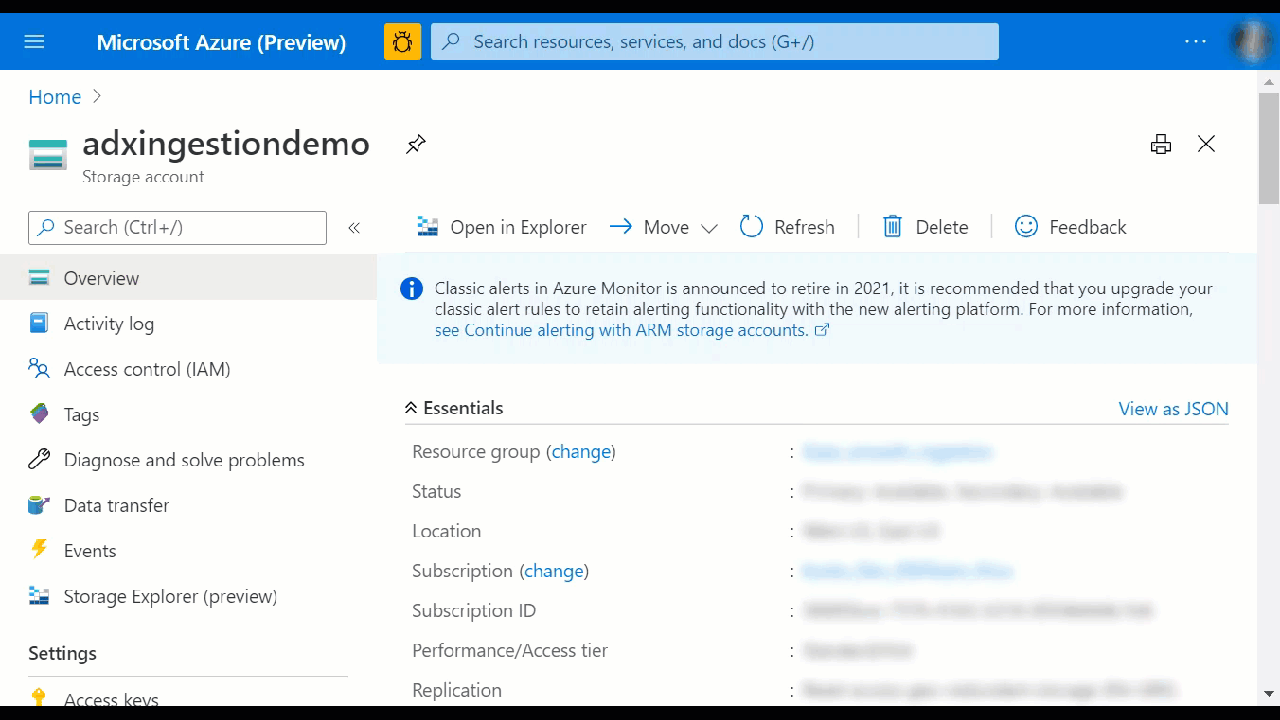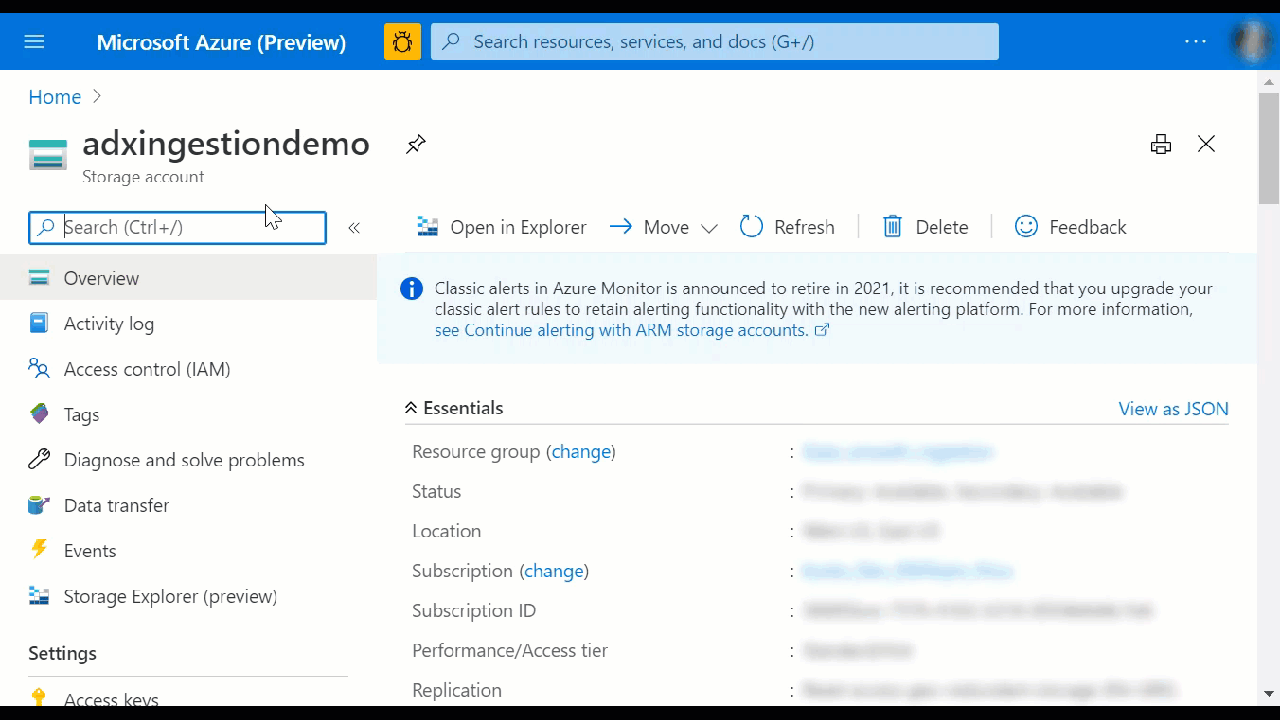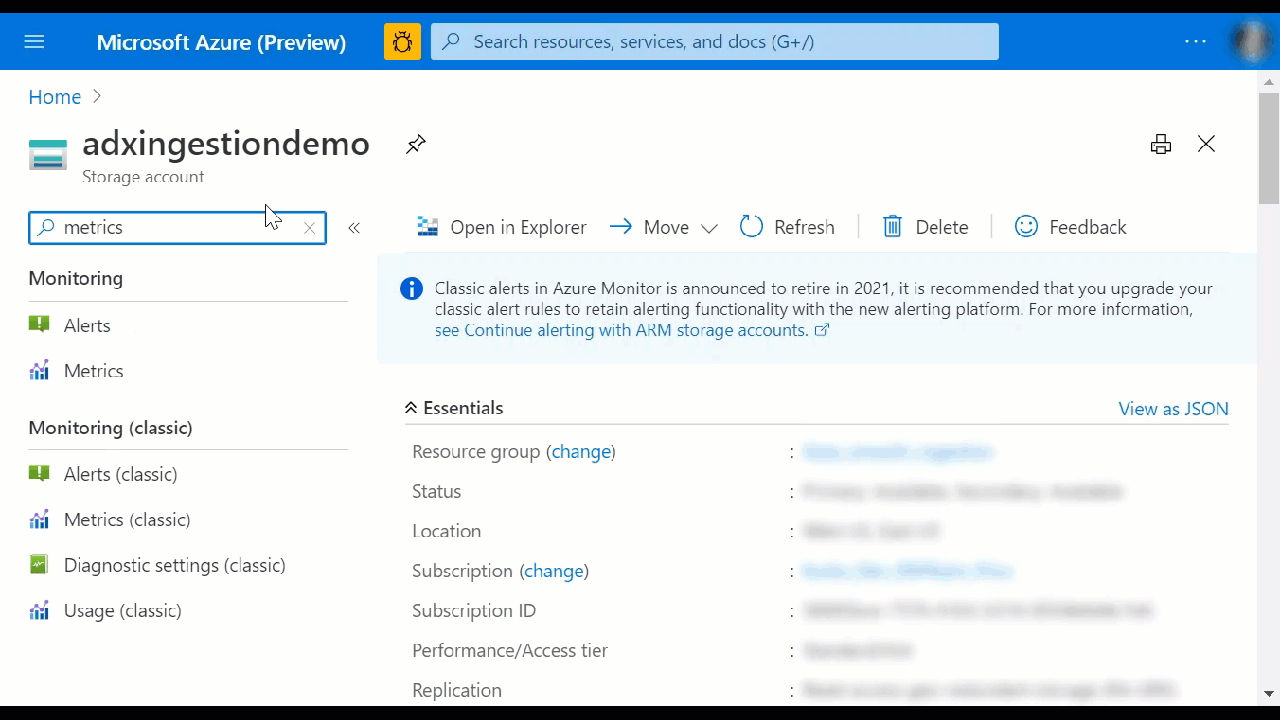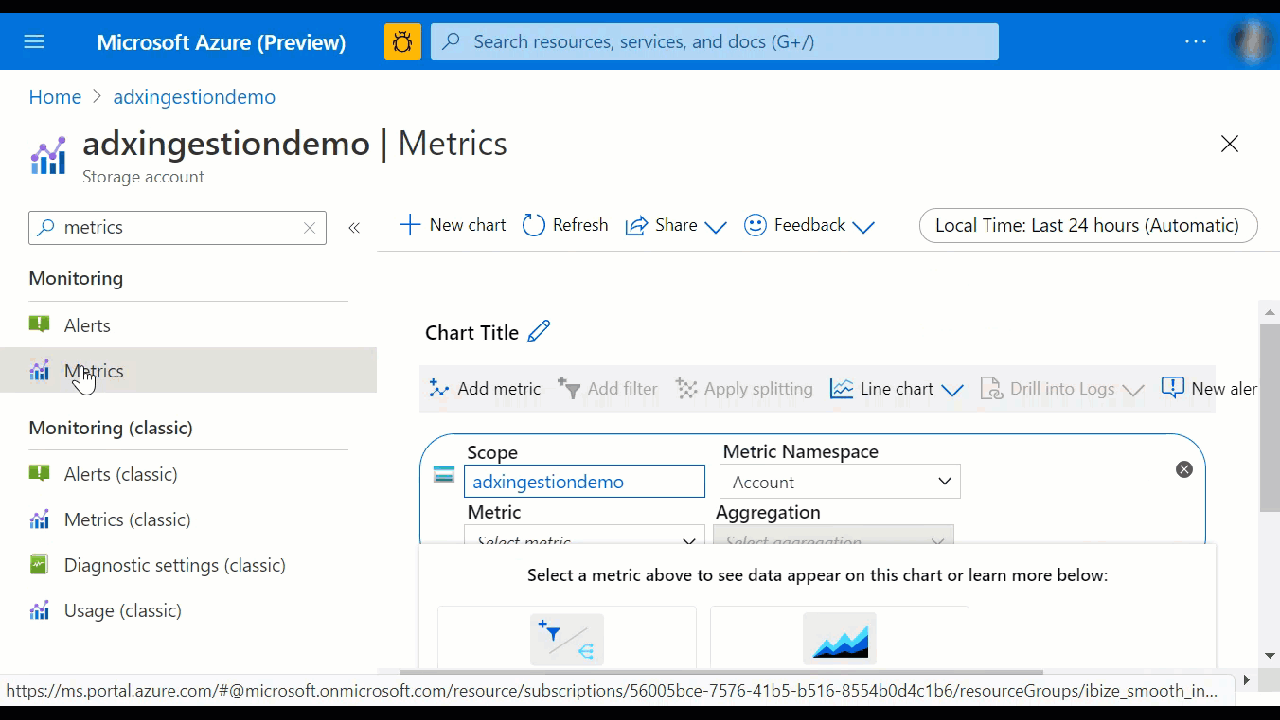
Utiliser le volet Métriques
Dans le volet Métriques, sélectionnez des métriques spécifiques à suivre, choisissez comment agréger vos données et créez des graphiques de métriques à afficher sur votre tableau de bord.
Les sélecteurs Ressource et Espace de noms de métrique sont présélectionnés pour votre cluster Azure Data Explorer. Les numéros figurant dans l’image suivante correspondent à la liste numérotée ci-dessous. Ils vous guident dans les différentes options de configuration et d’affichage des métriques.
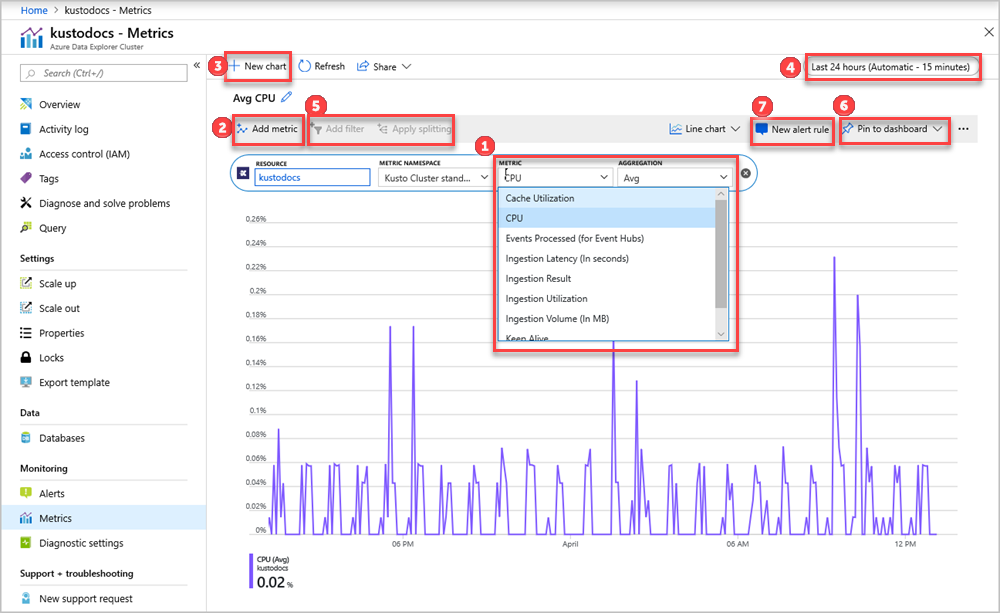
- Pour créer un graphique de métriques, sélectionnez le nom de la Métrique et l’agrégation pertinente par métrique. Pour plus d’informations sur les différentes métriques, consultez Métriques Azure Data Explorer prises en charge.
- Sélectionnez Ajouter une métrique pour afficher le tracé de plusieurs métriques sur le même graphique.
- Sélectionnez + Nouveau graphique pour afficher plusieurs graphiques dans une même vue.
- Utilisez le sélecteur de temps pour modifier l’intervalle de temps (par défaut : les dernières 24 heures).
- Utilisez Ajouter un filtre et Appliquer la division pour les métriques qui ont des dimensions.
- Sélectionnez Épingler au tableau de bord pour ajouter la configuration de votre graphique aux tableaux de bord afin de pouvoir le visualiser à nouveau.
- Définissez Nouvelle règle d’alerte pour visualiser vos métriques à l’aide des critères définis. La nouvelle règle d’alerte inclura les dimensions de la ressource, de la métrique, du fractionnement et du filtre cibles de votre graphique. Modifiez ces paramètres dans le volet de création de règle d’alerte.
Métriques Azure Data Explorer prises en charge
Les métriques Azure Data Explorer permettent de mieux comprendre les performances globales et l’utilisation de vos ressources, et fournissent des informations sur des actions spécifiques, telles que l’ingestion ou la requête. Les métriques de cet article ont été regroupées par type d’utilisation.
Les types de métriques sont les suivants :
- Métriques de cluster
- Exporter des métriques
- Métriques d’ingestion
- Métriques d’ingestion de streaming
- Métriques de requête
- Métriques de vue matérialisée
Pour obtenir la liste alphabétique des métriques d’Azure Monitor pour Azure Data Explorer, consultez Métriques de cluster Azure Data Explorer prises en charge.
Métriques de cluster
Les métriques de cluster assurent le suivi de l’intégrité générale du cluster. Par exemple, l’utilisation et la réactivité des ressources et de l’ingestion.
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| Utilisation du cache (déconseillée) | Pourcentage | Moy, Max, Min | Pourcentage de ressources de cache allouées actuellement utilisées par le cluster. Le cache désigne la taille du disque SSD allouée pour l’activité des utilisateurs conformément à la stratégie de cache définie. Une utilisation moyenne du cache de 80 % ou moins est un état acceptable pour un cluster. Si l’utilisation moyenne du cache est supérieure à 80 %, le cluster doit faire l’objet d’un scale-up vers un niveau tarifaire optimisé pour le stockage ou d’un scale-out vers plus d’instances. Vous pouvez également adapter la stratégie de cache à moins de jours dans le cache. Si l’utilisation du cache est supérieure à 100 %, la taille des données à mettre en cache est supérieure à la taille totale du cache sur le cluster. Cette métrique est déconseillée. Elle est présentée à des fins de compatibilité descendante uniquement. Utilisez plutôt la métrique « Facteur d’utilisation du cache ». |
Aucune |
| Facteur d’utilisation du cache | Pourcentage | Moy, Max, Min | Pourcentage d’espace disque utilisé dédié au cache chaud dans le cluster. 100 % signifie que l’espace disque affecté aux données chaudes est utilisé de manière optimale. Aucune action n’est nécessaire et le cluster est complètement correct. Moins de 100 % signifie que l’espace disque affecté pour les données chaudes n’est pas entièrement utilisé. Plus de 100 % signifie que l’espace disque du cluster n’est pas suffisamment grand pour prendre en charge les données chaudes, comme défini par vos stratégies de mise en cache. Pour garantir que l’espace suffisant est disponible pour toutes les données chaudes, la quantité de données chaudes doit être réduite ou le cluster doit faire l’objet d’un scale-out. Nous vous recommandons d’activer la mise à l’échelle automatique. |
Aucune |
| UC | Pourcentage | Moy, Max, Min | Pourcentage de ressources de calcul allouées actuellement utilisées par les machines du cluster. Une utilisation moyenne de l’UC de 80 % ou moins est acceptable pour un cluster. La valeur maximale d’utilisation de l’UC est de 100 %, ce qui signifie qu’il n’existe aucune ressource de calcul supplémentaire pour traiter les données. Quand les performances d’un cluster ne sont pas satisfaisantes, vérifiez la valeur maximale d’utilisation de l’UC afin de déterminer si des UC spécifiques sont bloquées. |
Aucune |
| Utilisation de l’ingestion | Pourcentage | Moy, Max, Min | Pourcentage de ressources réelles utilisées pour ingérer les données des ressources totales allouées, dans la stratégie de capacité, pour effectuer l’ingestion. La stratégie de capacité par défaut est la suivante : pas plus de 512 opérations d’ingestion simultanées ou 75 % des ressources de cluster investies dans l’ingestion. Une utilisation moyenne de l’ingestion de 80 % ou moins est un état acceptable pour un cluster. La valeur maximale de l’utilisation d’ingestion est 100 %, ce qui signifie que toute la capacité d’ingestion de cluster est utilisée et qu’une file d’attente d’ingestion risque d’être créée. |
Aucune |
| InstanceCount | Count | Avg | Nombre total d’instances. | |
| Keep alive | Count | Avg | Effectue le suivi de la réactivité du cluster. Un cluster entièrement réactif retourne la valeur 1, et un cluster bloqué ou déconnecté retourne 0. |
|
| Nombre total de commandes limitées | Count | Moy, Max, Min, Somme | Nombre de commandes limitées (rejetées) dans le cluster, étant donné que le nombre maximal autorisé de commandes simultanées (parallèles) a été atteint. | Aucune |
| Nombre total d’étendues | Count | Moy, Max, Min, Somme | Nombre total d’étendues de données dans le cluster. Les modifications de cette métrique peuvent impliquer des modifications massives de structures de données et une charge importante sur le cluster, car la fusion d’étendues de données est une activité gourmande en ressources d’UC. |
Aucune |
| Latence des abonnés | Millisecondes | Moy, Max, Min | La base de données abonnée synchronise les changements des bases de données leaders. En raison de la synchronisation, il y a un décalage de quelques secondes à quelques minutes au niveau de la disponibilité des données. Cette métrique mesure la durée du décalage. Le décalage de temps dépend de plusieurs facteurs comme : la taille globale et le débit des données ingérées vers le leader, le nombre de bases de données abonnées, le débit des opérations internes effectuées sur le leader (opérations de fusion/regénération). Il s’agit d’une métrique au niveau du cluster : les abonnés interceptent les métadonnées de toutes les bases de données qui sont suivies. Cette métrique représente la latence du processus. |
Aucune |
Exporter mesures
Les métriques d’exportation permettent d’effectuer le suivi de l’intégrité générale et des performances des opérations d’exportation telles que le retard, les résultats, le nombre d’enregistrements et l’utilisation.
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| Exportation continue : Nombre d’enregistrements exportés | Count | Sum | Nombre d’enregistrements exportés dans tous les travaux d’exportation continue. | ContinuousExportName |
| Retard max. pour l’exportation continue | Count | Max | Retard (en minutes) signalé par les travaux d’exportation continue dans le cluster. | Aucune |
| Nombre d’exportations continues en attente | Count | Max | Nombre de travaux d’exportation continue en attente. Ces travaux sont prêts à être exécutés mais attendent dans une file d’attente, probablement en raison d’une capacité insuffisante. | |
| Résultat de l’exportation continue | Count | Count | Échec ou réussite de chaque exécution d’exportation continue. | ContinuousExportName |
| Utilisation de l’exportation | Pourcentage | Max | Capacité d’exportation utilisée, hors de la capacité totale d’exportation dans le cluster (entre 0 et 100). | Aucune |
Métriques d’ingestion
Les métriques d’ingestion permettent d’effectuer le suivi de l’intégrité générale et des performances des opérations d’ingestion telles que la latence, les résultats et le volume. Pour affiner votre analyse :
- Appliquer des filtres aux graphiques pour tracer des données partielles par dimensions. Par exemple, explorez l’ingestion dans un
Databasespécifique. - Appliquer un fractionnement à un graphique pour visualiser les données selon différents composants. Ce processus est utile pour analyser les métriques signalées par chaque étape du pipeline d’ingestion, par exemple
Blobs received.
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| Nombre d’objets blob du lot | Count | Moy, Max, Min | Nombre de sources de données dans un lot terminé pour l’ingestion. | Base de données |
| Durée du lot | Secondes | Moy, Max, Min | Durée de la phase de traitement par lot du flux d’ingestion. | Base de données |
| Taille du lot | Octets | Moy, Max, Min | Taille de données attendue non compressée dans un lot agrégé pour l’ingestion. | Base de données |
| Lots traités | Count | Sum, Max, Min | Nombre de lots terminés pour l’ingestion. Batching Type : déclencheur du scellement d’un lot. Pour obtenir la liste complète des types de traitement par lot, consultez Types de traitement par lot. |
Base de données, type de traitement par lot |
| Objets blob reçus | Count | Sum, Max, Min | Nombre d’objets blob reçus à partir du flux d’entrée par un composant. Utilisez Appliquer le fractionnement pour analyser chaque composant. |
Base de données, type de composant, nom du composant |
| Objets blob traités | Count | Sum, Max, Min | Nombre d’objets blob traités par un composant. Utilisez Appliquer le fractionnement pour analyser chaque composant. |
Base de données, type de composant, nom du composant |
| Objets blob supprimés | Count | Sum, Max, Min | Nombre d’objets blob supprimés définitivement par un composant. Pour chacun de ces objets blob, une métrique Ingestion result avec un motif d’échec est envoyée. Utilisez Appliquer le fractionnement pour analyser chaque composant. |
Base de données, type de composant, nom du composant |
| Latence de découverte | Secondes | Avg | Délai entre la mise en file d’attente des données et la découverte par les connexions de données. Ce délai n’est pas inclus dans les métriques Latence des étapes ni Latence d’ingestion. La latence de découverte peut augmenter dans les situations suivantes :
|
Type de composant, nom du composant |
| Événements reçus | Count | Sum, Max, Min | Nombre d’événements reçus par les connexions de données à partir du flux d’entrée. | Type de composant, nom du composant |
| Événements traités | Count | Sum, Max, Min | Nombre d’événements traités par les connexions de données. | Type de composant, nom du composant |
| Événements supprimés | Count | Sum, Max, Min | Nombre d’événements supprimés définitivement par les connexions de données. Pour chacun de ces événements, une métrique Ingestion result avec un motif d’échec est envoyée. |
Type de composant, nom du composant |
| Latence d’ingestion | Secondes | Moy, Max, Min | Latence des données ingérées, à partir du moment où les données ont été reçues dans le cluster jusqu’à ce qu’elles sont prêtes pour la requête. La période de latence d’ingestion varie en fonction du scénario d’ingestion.Ingestion Kind : Ingestion de streaming ou ingestion mise en file d’attente |
Type d’ingestion |
| Résultat de l’ingestion | Count | Sum | Nombre total de sources ayant échoué ou réussi à être ingérées.Status : Réussite pour une l’ingestion réussie ou catégorie d’échec en cas d’échec. Pour obtenir la liste complète des catégories d’échecs possibles, consultez Codes d’erreur d’ingestion dans Azure Data Explorer. Failure Status Type : Indique si l’échec est permanent ou temporaire. Pour une ingestion réussie, cette dimension est None.Remarque :
|
État, Type d’état d’échec |
| Volume d’ingestion (en octets) | Count | Max, Sum | Taille totale des données ingérées dans le cluster (en octets) avant la compression. | Base de données |
| Longueur de la file d’attente | Count | Avg | Nombre de messages en attente dans la file d’attente d’entrée d’un composant. Le composant Gestionnaire de traitement par lot comporte un message par objet blob. Le composant Gestionnaire d’ingestion comporte un message par lot. Un lot est une commande d’ingestion unique avec un ou plusieurs objets blob. | Type de composant |
| Message le plus ancien de la file d’attente | Secondes | Avg | Durée en secondes à partir de laquelle le message le plus ancien dans la file d’attente d’entrée d’un composant a été inséré. | Type de composant |
| Taille des données reçues en octets | Octets | Avg, Sum | Taille des données reçues par les connexions de données à partir du flux d’entrée. | Type de composant, nom du composant |
| Latence des étapes | Secondes | Avg | Heure à partir de laquelle un message est accepté par Azure Data Explorer, jusqu’à ce que son contenu soit reçu par un composant d’ingestion pour traitement. Pour afficher la latence d’ingestion totale, utilisez Appliquer des filtres et sélectionnez Type de composant StorageEngine >. |
Base de données, type de composant |
Métriques d’ingestion de streaming
Les métriques d’ingestion de streaming effectuent le suivi des données d’ingestion de streaming ainsi que du taux, de la durée et des résultats de requêtes.
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| Taux de données d’ingestion en streaming | Count | RateRequestsPerSecond | Volume total de données ingérées dans le cluster. | Aucune |
| Durée de l’ingestion en streaming | Millisecondes | Moy, Max, Min | Durée totale de toutes les demandes d’ingestion de streaming. | Aucune |
| Taux de demandes d’ingestion en streaming | Count | Count, Moy, Max, Min, Somme | Nombre total de demandes d’ingestion de streaming. | Aucune |
| Résultat de l’ingestion en streaming | Count | Avg | Nombre total de demandes d’ingestion de streaming par type de résultat. | Result |
Métriques de requête
Les métriques de performances des requêtes effectuent le suivi de la durée des requêtes et du nombre total de requêtes simultanées ou limitées.
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| Durée de la requête | Millisecondes | Moy, Min, Max, Somme | Temps total jusqu’à ce que les résultats de la requête soient reçus (n’inclut pas la latence réseau). | QueryStatus |
| QueryResult | Count | Count | Nombre total de requêtes. | QueryStatus |
| Nombre total de demandes simultanées | Count | Moy, Max, Min, Somme | Nombre de requêtes exécutées en parallèle dans le cluster. Cette métrique est un bon moyen d’estimer la charge sur le cluster. | Aucune |
| Nombre total de demandes limitées | Count | Moy, Max, Min, Somme | Nombre de requêtes limitées (rejetées) dans le cluster. Le nombre maximal de requêtes simultanées (parallèles) autorisées est défini dans la stratégie de limites de taux de demandes. | Aucune |
Métriques de vue matérialisée
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| MaterializedViewHealth | 1, 0 | Avg | La valeur est 1 si la vue est considérée comme saine, sinon 0. | Base de données, MaterializedViewName |
| MaterializedViewAgeSeconds | Secondes | Avg | L’age de la vue est défini par l’heure actuelle moins la dernière heure d’ingestion traitée par la vue. La métrique est une valeur de temps en secondes (plus la valeur est faible, plus la vue est « saine »). |
Base de données, MaterializedViewName |
| MaterializedViewResult | 1 | Avg | La métrique inclut une Result dimension indiquant le résultat du dernier cycle de matérialisation (consultez la métrique MaterializedViewResult pour plus d’informations sur les valeurs possibles). La valeur de la métrique est toujours égale à 1. |
Base de données, MaterializedViewName, Résultat |
| MaterializedViewRecordsInDelta | Nombre d’enregistrements | Avg | Nombre d’enregistrements actuellement dans la partie non traitée de la table source. Pour plus d’informations, découvrez comment fonctionnent les vues matérialisées | Base de données, MaterializedViewName |
| MaterializedViewExtentsRebuild | Nombre d’étendues | Avg | Nombre d’étendues qui ont nécessité des mises à jour dans le cycle de matérialisation. | Base de données, MaterializedViewName |
| MaterializedViewDataLoss | 1 | Max | La métrique est déclenchée lorsque les données sources non traitées approchent de la rétention. Indique que la vue matérialisée n’est pas saine. | Base de données, MaterializedViewName, Genre |
Métriques de partitionnement
Les métriques de partitionnement surveillent le processus de partitionnement des tables avec une stratégie de partitionnement.
| Mesure | Unité | Agrégation | Description de la métrique | Dimensions |
|---|---|---|---|---|
| PartitioningPercentage | Pourcentage | Moy, Min, Max | Pourcentage d’enregistrements partitionnés par rapport au nombre total d’enregistrements. | Base de données, Table |
| PartitioningPercentageHot | Pourcentage | Moy, Min, Max | Pourcentage d’enregistrements partitionnés liés au nombre total d’enregistrements (dans le cache « chaud » uniquement). | Base de données, Table |
| ProcessedPartitionedRecords | Pourcentage | Moy, Min, Max, Somme | Nombre d’enregistrements partitionnés dans la fenêtre de temps mesurée. | Base de données, Table |