Superviser les flux de données
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Après avoir généré et débogué votre flux de données, vous pouvez le planifier de façon à l’exécuter selon une planification dans le contexte d’un pipeline. Vous pouvez planifier le pipeline à l’aide de déclencheurs. Pour tester et déboguer votre flux de données à partir d'un pipeline, vous pouvez utiliser le bouton Déboguer du ruban de la barre d'outils ou l'option Déclencher maintenant du Pipeline Builder pour effectuer une exécution unique afin de tester votre flux de données dans le contexte du pipeline.
Lors de l’exécution de votre pipeline, vous pouvez superviser celui-ci ainsi que toutes les activités qu’il contient, dont celle du flux de données. Sélectionnez l'icône du moniteur dans le panneau gauche de l'interface utilisateur. Un écran similaire à celui qui suit s'affiche. Les icônes en surbrillance vous permettent d’explorer les activités du pipeline, dont celle du flux de données.
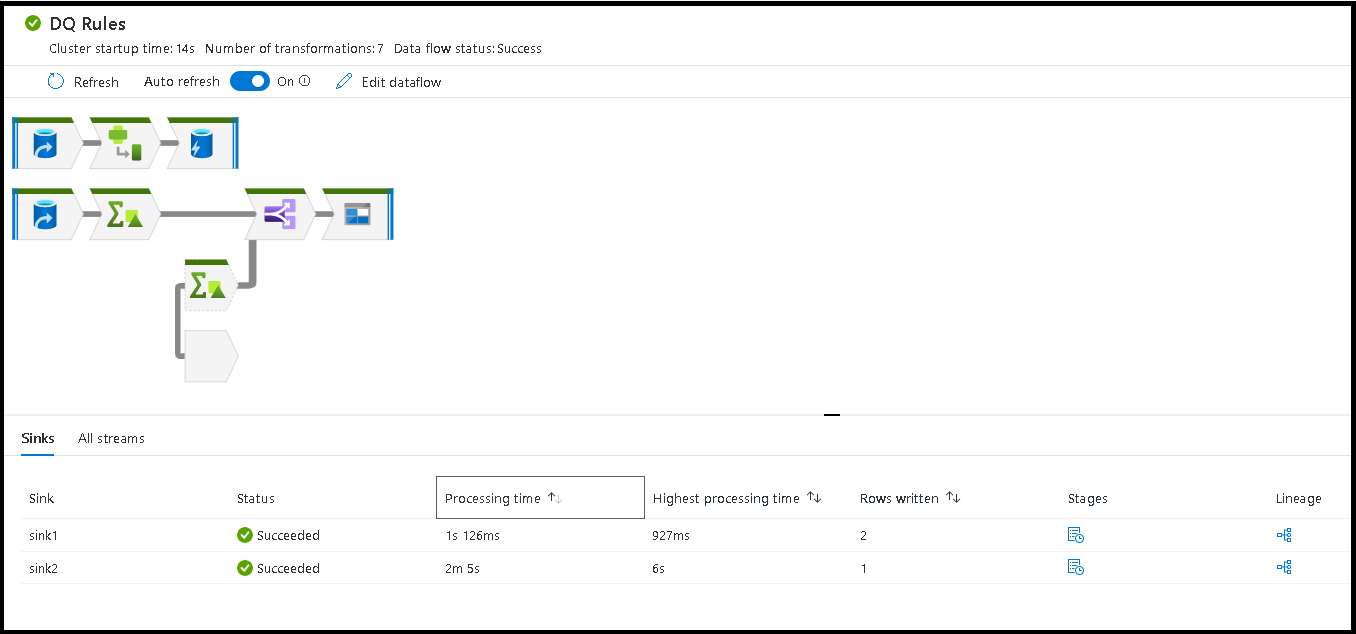
À ce niveau, vous voyez également des statistiques, notamment l’état et le temps d’exécution. L’ID d’exécution au niveau d’une activité diffère de celui au niveau du pipeline. L’ID d’exécution au niveau précédent a trait au pipeline. En cliquant sur les lunettes, vous pouvez obtenir des informations détaillées sur l’exécution de votre flux de données.

Dans l’affichage de surveillance des nœuds sous forme graphique, vous pouvez voir une version simplifiée en lecture seule de votre graphique de flux de données. Pour voir l’affichage des détails avec des nœuds de graphique plus volumineux qui incluent des étiquettes d’étape de transformation, utilisez le curseur de zoom sur le côté droit de votre canevas. Vous pouvez également utiliser le bouton Rechercher sur le côté droit pour trouver des parties de votre logique de flux de données dans le graphique.
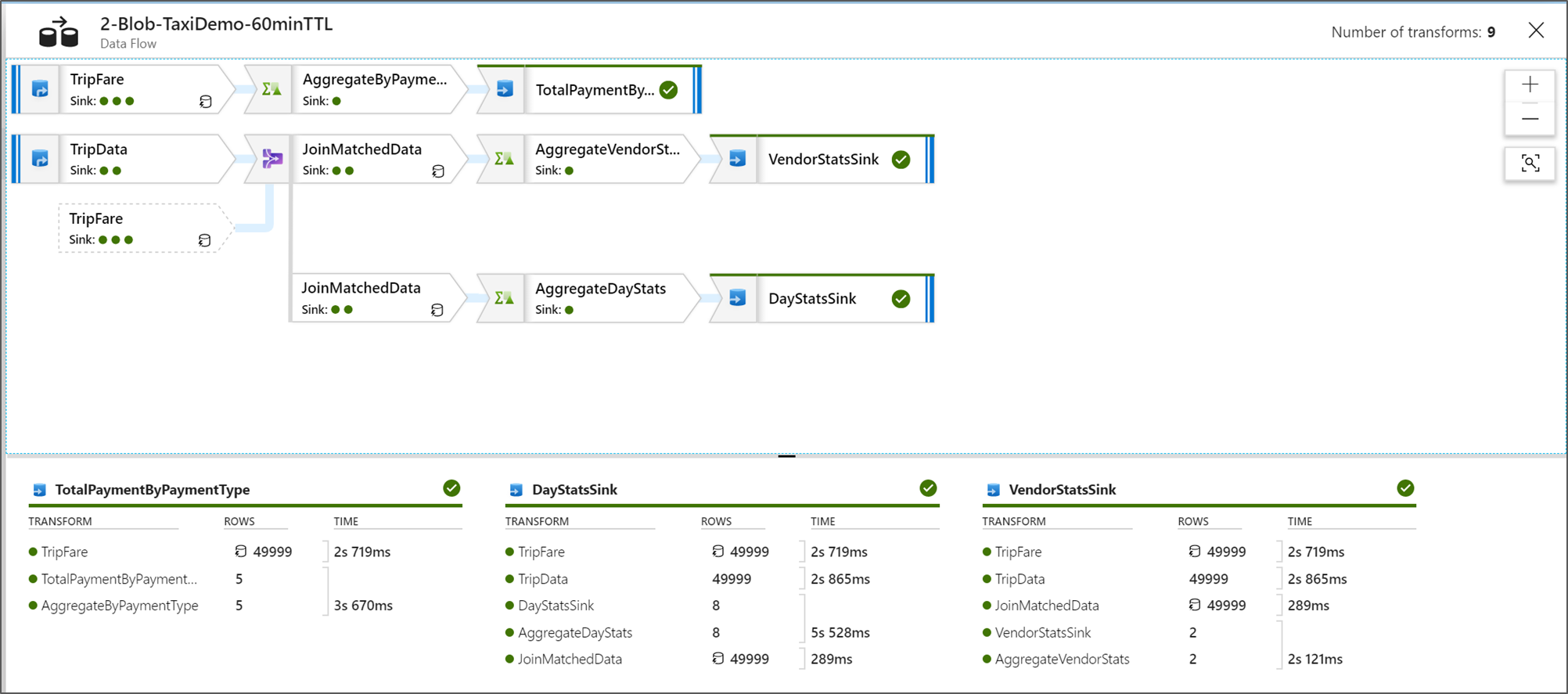
Afficher les plans d’exécution de flux de données
Quand votre flux de données Data Flow est exécuté dans Spark, le service détermine les chemins de code optimaux en fonction de l’intégralité de votre flux de données. En outre, les chemins d'exécution peuvent se produire sur différents nœuds scale-out et partitions de données. Par conséquent, le graphique de supervision reflète la conception de votre flux, en tenant compte du chemin d’exécution de vos transformations. En sélectionnant différents nœuds, vous pouvez voir des « phases » représentant du code exécuté simultanément sur le cluster. Les minutages et les chiffres qui apparaissent correspondent à ces groupes ou à ces phases, par opposition aux étapes de votre conception prises individuellement.
Lorsque vous sélectionnez l’espace disponible dans la fenêtre de supervision, les statistiques dans le volet inférieur affichent le minutage et le nombre de lignes pour chaque récepteur, ainsi que les transformations ayant conduit aux données du récepteur pour la traçabilité des transformations.
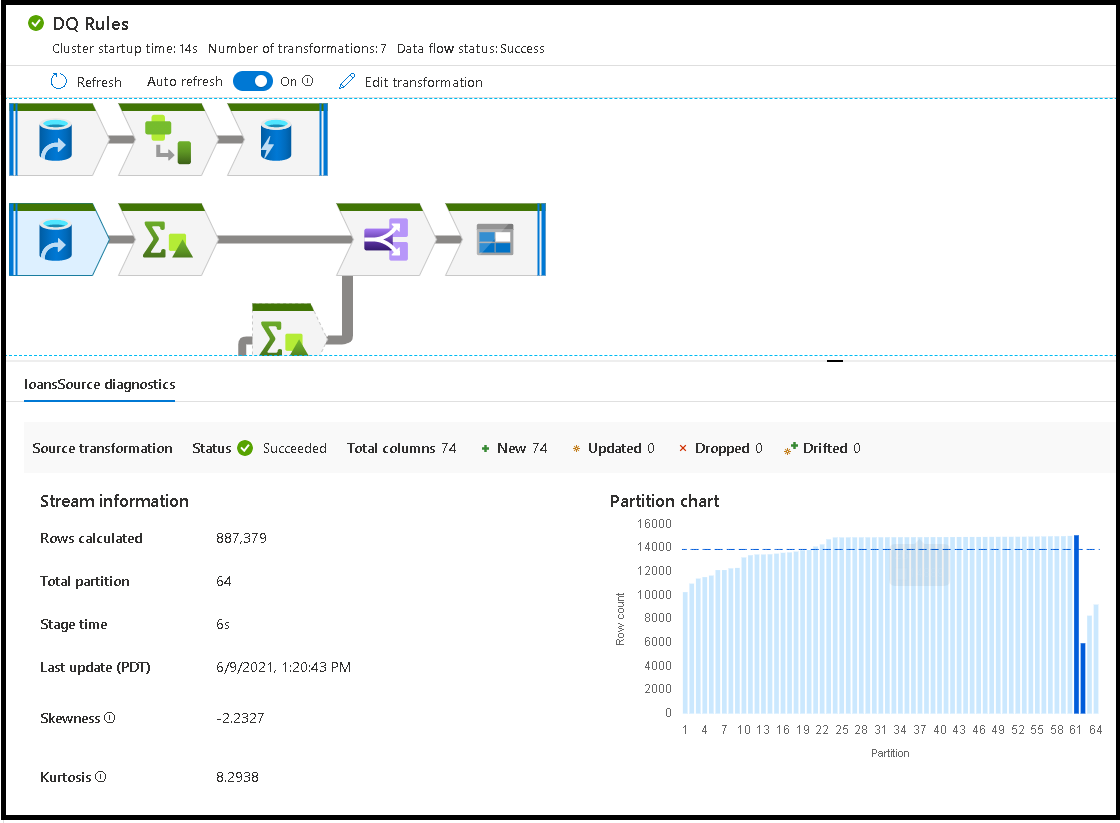
Lorsque vous sélectionnez des transformations individuelles, vous obtenez des informations supplémentaires dans le panneau de droite qui indique les statistiques de la partition, le nombre de colonnes, l'asymétrie (l'uniformité de la distribution des données entre les partitions) et le kurtosis (l'irrégularité des données).
Un tri par heure de traitement vous permet d'identifier les étapes de votre flux de données qui ont pris le plus de temps.
Pour trouver les transformations à chaque étape qui ont pris le plus de temps, triez sur le temps de traitement le plus long.
Les *lignes écrites peuvent également être triées afin d'identifier les flux de données qui écrivent le plus de données dans votre flux de données.
Lorsque vous sélectionnez le récepteur dans la vue du nœud, vous voyez la traçabilité des données de la colonne. Avant d’arriver dans le récepteur, les données sont cumulées tout au long de votre flux de données selon trois méthodes différentes. Il s'agit de :
- Calculée : Vous utilisez la colonne pour le traitement conditionnel ou dans une expression de votre flux de données, mais les données n’arrivent pas dans le récepteur.
- Dérivée : la colonne est une nouvelle colonne que vous avez générée dans votre flux, c'est-à-dire qu'elle n'était pas présente dans la source.
- Mappée : la colonne provient de la source et vous la mappez avec un champ de récepteur.
- État du flux de données : État actuel de l’exécution
- Heure de démarrage du cluster : Durée d’acquisition de l’environnement de calcul JIT Spark pour l’exécution de votre flux de données
- Nombre de transformations : Nombre d’étapes de transformation exécutées dans votre flux

Différence entre le temps de traitement du récepteur et le temps de traitement de la transformation
Chaque étape de transformation indique une durée totale d’exécution, dans laquelle sont totalisés les temps d’exécution de chaque partition. Lorsque vous sélectionnez le récepteur, « Durée de traitement du récepteur. » Cette durée comprend la durée totale de la transformation plus le temps d’E/S nécessaire à l’écriture de vos données dans le magasin de destination. C’est le temps d’E/S nécessaire à l’écriture de vos données qui fait la différence entre le temps de traitement du récepteur et la durée totale de la transformation.
Vous pouvez également voir le minutage détaillé de chaque étape de transformation de partition en ouvrant la sortie JSON de votre activité de flux de données dans la vue de supervision du pipeline. La sortie JSON contient la durée en millisecondes de chaque partition, tandis que la vue de supervision de l’expérience utilisateur présente le minutage agrégé des partitions :
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Temps de traitement du récepteur
Lorsque vous sélectionnez une icône de transformation de récepteur dans votre mappage, le panneau coulissant de droite présente un point de données supplémentaire appelé « durée de post-traitement » dans le coin inférieur. Il s’agit du temps consacré à l’exécution de votre travail sur le cluster Spark après que vos données ont été chargées, transformées et écrites. Ce temps peut comprendre la fermeture de pools de connexions, l’arrêt de pilotes, la suppression de fichiers, la fusion de fichiers, etc. Lorsque vous effectuez des actions dans votre flux comme « déplacer des fichiers » et « générer dans un seul fichier », il est probable que vous constatiez une augmentation de la valeur du temps de post-traitement.
- Durée de l'étape d'écriture : temps nécessaire à l'écriture des données à un emplacement intermédiaire pour Synapse SQL
- Durée SQL de l'opération de table : temps passé à déplacer les données des tables temporaires vers la table cible
- Durée pré- et post-SQL : temps passé à exécuter des commandes pré/post-SQL
- Durée pré-commandes et durée post-commandes : temps passé à exécuter des opérations pré/post pour les sources/récepteurs basés sur des fichiers. Par exemple, déplacez ou supprimez des fichiers après traitement.
- Durée de la fusion : temps consacré à la fusion du fichier. Les fichiers fusionnés sont utilisés pour les récepteurs basés sur des fichiers lors de l'écriture dans un seul fichier ou lorsque « Nom de fichier en tant que données de colonne » est utilisé. Si le temps consacré à cette métrique est important, évitez d'utiliser ces options.
- Durée de la phase : temps total passé à l’intérieur de Spark pour réaliser l’opération en tant que phase.
- Table intermédiaire temporaire : nom de la table temporaire utilisée par les flux de données pour effectuer une copie intermédiaire des données dans la base de données.
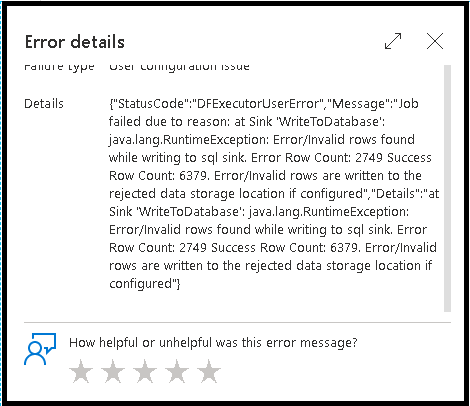
Lignes d’erreur
L’activation de la gestion des lignes d’erreur dans votre récepteur de flux de données se reflète dans la sortie de la surveillance. Lorsque vous réglez le récepteur sur « signaler un succès en cas d'erreur », la sortie d'analyse indique le nombre de lignes réussies et échouées lorsque vous sélectionnez le nœud d'analyse du récepteur.
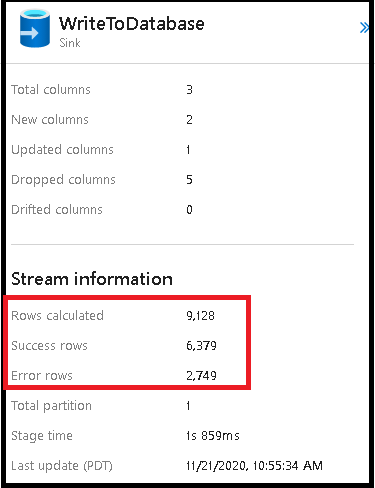
Lorsque vous sélectionnez « signaler un échec en cas d'erreur », la même sortie est présentée uniquement dans le texte de sortie d'analyse de l'activité. En effet, l'activité de flux de données renvoie un échec d'exécution et l'affichage d'analyse détaillée n'est pas disponible.
Icônes Superviser
Cette icône signifie que les données de la transformation étaient déjà en cache sur le cluster. Les minutages et le chemin d’exécution en ont donc tenu compte :
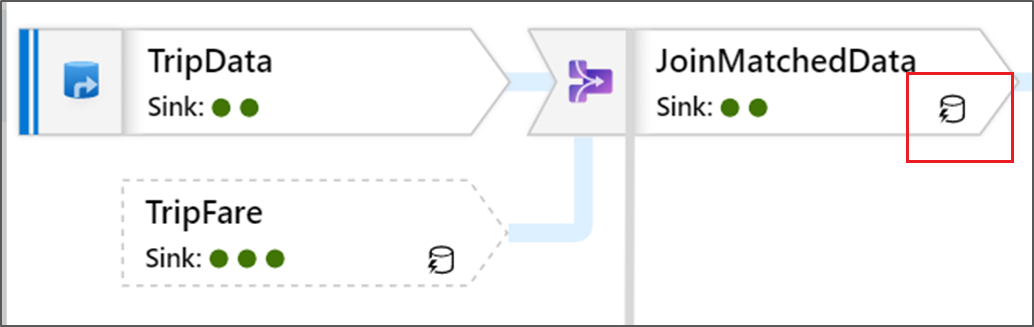
Vous pouvez également voir des icônes de cercle vert dans la transformation. Elles représentent un décompte du nombre de récepteurs dans lesquels les données s’écoulent.