Optimisation des récepteurs
Quand des flux de données écrivent dans des récepteurs, tout partitionnement personnalisé se produit immédiatement avant l’écriture. Comme pour la source, dans la plupart des cas, il est recommandé de conserver l’option de partition Utiliser le partitionnement actuel en tant qu’option de partition sélectionnée. L’écriture de données partitionnées est beaucoup plus rapide que l’écriture de données non partitionnées, même si votre destination n’est pas partitionnée. Vous trouverez ci-dessous des considérations spécifiques concernant les différents types de récepteurs.
Récepteurs Azure SQL Database
Avec Azure SQL Database, le partitionnement par défaut doit fonctionner dans la plupart des cas. Il est possible que votre récepteur ait un nombre de partitions trop important à gérer pour votre base de données SQL. Si vous rencontrez ce problème, réduisez le nombre de partitions générées par votre récepteur SQL Database.
Meilleure pratique pour supprimer des lignes dans un récepteur en fonction de lignes manquantes dans la source
Voici un aperçu vidéo de l’utilisation des flux de données avec les sorties, la modification de ligne et les transformations de récepteur pour obtenir ce modèle commun :
Impact de la gestion des lignes d’erreur sur les performances
Lorsque vous activez la gestion des lignes d’erreur (« continuer en cas d’erreur ») dans la transformation du récepteur, le service effectue une étape supplémentaire avant d’écrire les lignes compatibles dans votre table de destination. Cette étape supplémentaire entraîne une faible baisse des performances, qui peut être de l’ordre de 5 % pour cette étape, avec une faible incidence supplémentaire sur les performances si vous définissez l’option de consigner également les lignes incompatibles dans un fichier journal.
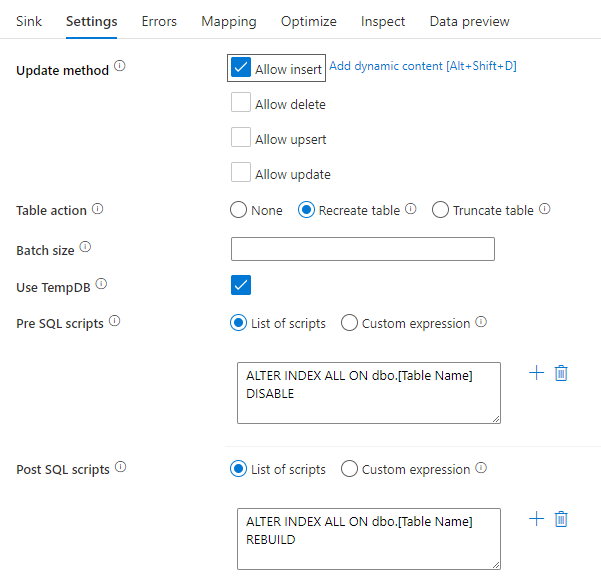
Désactivation des index à l’aide d’un script SQL
La désactivation des index avant un chargement dans une base de données SQL peut améliorer considérablement les performances d’écriture dans la table. Avant d’écrire sur votre récepteur SQL, exécutez la commande ci-dessous.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Une fois l’écriture terminée, régénérez les index à l’aide de la commande suivante :
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Ces opérations peuvent être effectuées en mode natif à l’aide de scripts Pre-SQL et Post-SQL au sein d’une base de données SQL Azure ou d’un récepteur Synapse dans le mappage de flux de données.
Avertissement
Lors de la désactivation des index, le flux de données prend le contrôle d’une base de données et les requêtes sont peu susceptibles d’aboutir à ce moment. Par conséquent, de nombreux travaux ETL sont déclenchés de nuit pour éviter ce conflit. Pour plus d’informations, découvrez les contraintes de la désactivation des index SQL
Augmentation de l’échelle de votre base de données
Planifiez un redimensionnement de vos bases de données Azure SQL DB et Azure SQL DW de source et de récepteur avant l’exécution de votre pipeline pour augmenter le débit et réduire la limitation de requêtes Azure une fois que vous atteignez les limites DTU. Une fois l’exécution de votre pipeline terminée, redimensionnez vos bases de données à leur fréquence d’exécution normale.
Récepteurs Azure Synapse Analytics
Lors de l’écriture dans Azure Synapse Analytics, assurez-vous que l’option Activer le mode de préproduction est définie sur true. Cela permet au service d’écrire à l’aide de la commande SQL COPY qui charge efficacement les données en bloc. Vous devez référencer un compte Azure Data Lake Storage Gen2 ou Stockage Blob Azure pour la mise en lots des données lors de l’utilisation de Mise en lots.
Outre Mise en lots, les mêmes meilleures pratiques s’appliquent à Azure Synapse Analytics qu’à Azure SQL Database.
Récepteurs basés sur des fichiers
Si les flux de données prennent en charge différents types de fichiers, le format Parquet natif de Spark est recommandé pour optimiser les temps de lecture et d’écriture.
Si les données sont distribués uniformément, Utiliser le partitionnement actuel est l’option de partitionnement la plus rapide pour l’écriture de fichiers.
Options de nom de fichier
Lorsque vous écrivez des fichiers, vous avez le choix entre plusieurs options de nommage qui ont toutes une incidence sur les performances.
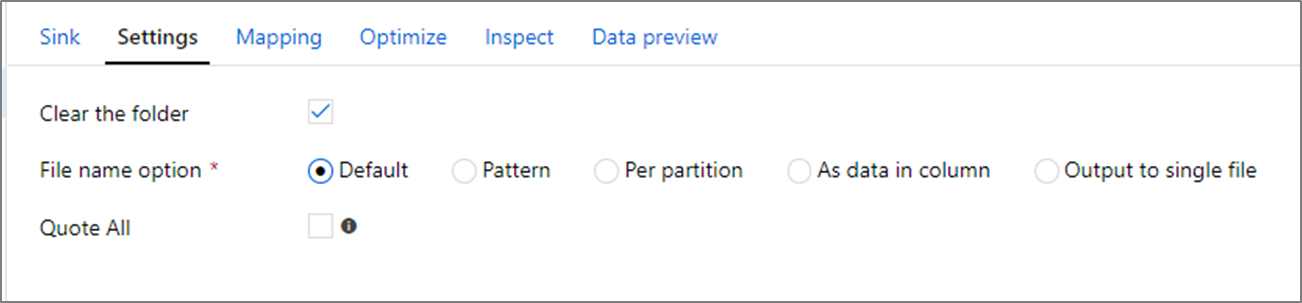
La sélection de l’option Par défaut permet d’écrire le plus rapidement. Chaque partition correspond à un fichier avec le nom par défaut Spark. Cela est utile si vous lisez simplement à partir du dossier de données.
La définition d’un modèle de nommage a pour effet de renommer chaque fichier de partition en lui attribuant un nom plus convivial. Cette opération a lieu après l’écriture et est légèrement plus lente que le choix de la valeur par défaut.
L’option Par partition vous permet de nommer chaque partition manuellement.
Si une colonne correspond à la sortie de données que vous souhaitez, vous pouvez sélectionner l’option Name file as column data (Nom du fichier en tant que données de colonne). Cela a pour effet de remanier les données et peut avoir une incidence sur les performances si les colonnes ne sont pas distribuées uniformément.
Si une colonne correspond à la façon dont vous souhaitez générer des noms de dossier, sélectionnez Name folder as column data (Nom du fichier en tant que données de colonne).
La sortie vers un fichier unique combine toutes les données dans une seule partition. Cela se traduit par des temps d’écriture longs, en particulier pour des jeux de données volumineux. Cette option est déconseillée à moins qu’il y ait une raison commerciale explicite de l’utiliser.
Récepteurs Azure Cosmos DB
Lors de l’écriture dans Azure Cosmos DB, la modification du débit et de la taille de lot lors de l’exécution du flux de données peut améliorer les performances. Ces modifications ne prennent effet que lors de l’exécution de l’activité de flux de données et les paramètres de collecte d’origine sont rétablis une fois l’exécution terminée.
Taille du lot : En général, la taille de lot par défaut est suffisante pour commencer. Pour affiner cette valeur, calculez la taille approximative de l'objet de vos données et assurez-vous que la taille de l'objet x la taille du lot est inférieure à 2 Mo. Si tel est le cas, vous pouvez augmenter la taille du lot pour obtenir un meilleur débit.
Débit : définissez un paramètre de débit plus élevé ici pour permettre aux documents d’écrire plus rapidement sur Azure Cosmos DB. N’oubliez pas les coûts d’unité de requête supérieurs inhérents à un paramètre de débit élevé.
Budget du débit d’écriture : utilisez une valeur inférieure au nombre total d’unités de requête par minute. Si vous avez un flux de données avec un grand nombre de partitions Spark, la définition d’un budget de débit permet d’équilibrer davantage ces partitions.
Contenu connexe
- Vue d’ensemble des performances de flux de données
- Optimisation des sources
- Optimisation des transformations
- Utilisation des flux de données dans des pipelines
Consultez d’autres articles sur les flux de données consacrés aux performances :