Les jeux de données dans Azure Data Factory et Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit ce que sont les jeux de données, la manière dont ils sont définis au format JSON et la façon dont ils sont utilisés dans les pipelines Azure Data Factory et Synapse.
Si vous débutez avec Data Factory, consultez Présentation d’Azure Data Factory pour en avoir une vue d’ensemble. Pour plus d’informations sur Azure Synapse, consultez Qu’est-ce que Azure Synapse ?
Vue d’ensemble
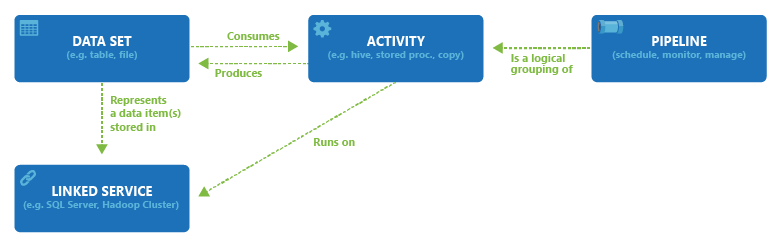
Un espace de travail Azure Data Factory ou Synapse peut avoir un ou plusieurs pipelines. Un pipeline constitue un regroupement logique d’activités qui exécutent ensemble une tâche. Les activités d’un pipeline définissent les actions à effectuer sur les données. À présent, un jeu de données est une vue de données nommée qui pointe ou fait référence simplement aux données que vous souhaitez utiliser dans vos activités en tant qu’entrées et sorties. Les jeux de données identifient les données dans différents magasins de données, par exemple des tables, des fichiers, des dossiers et des documents. Par exemple, un jeu de données Blob Azure spécifie le conteneur de blobs et le dossier dans Stockage Blob à partir duquel l’activité doit lire les données.
Avant de créer un jeu de données, vous devez créer un service lié afin d’établir un lien entre votre banque de données et le service. Les services liés ressemblent à des chaînes de connexion. Ils définissent les informations de connexion nécessaires au service pour se connecter à des ressources externes. Considérez les choses de la façon suivante : le jeu de données représente la structure des données à l’intérieur des magasins de données liés, et le service lié définit la connexion à la source de données. Par exemple, un service lié de stockage Azure relie un compte de stockage. Un jeu de données d'objets blob représente le conteneur d’objets blob et le dossier à l’intérieur de ce compte Stockage Azure contenant les objets blob d’entrée à traiter.
Voici un exemple de scénario. Pour copier des données du stockage Blob vers une base de données SQL Database, vous devez créer deux services liés : Stockage Blob Azure et Azure SQL Database. Créez ensuite deux jeux de données : un jeu de données de texte délimité (qui fait référence au service lié Stockage Blob Azure, en supposant que vous disposez de fichiers texte comme source) et un jeu de données Azure SQL Table (qui fait référence au service lié Azure SQL Database). Les services liés Stockage Blob Azure et Azure SQL Database contiennent des chaînes de connexion utilisées par le service pendant l’exécution pour se connecter à votre instance Stockage Azure et Azure SQL Database, respectivement. Le jeu de données Texte délimité spécifie le conteneur de blobs et le dossier de blobs qui contient les blobs d’entrée dans votre stockage Blob, en même temps que des paramètres spécifiques au format. Le jeu de données de table SQL Azure spécifie la table SQL dans votre base de données SQL Database dans laquelle les données doivent être copiées.
Le diagramme suivant montre la relation entre le pipeline, l’activité, le jeu de données et les services liés :
Créer un jeu de données à l’aide de l’interface utilisateur
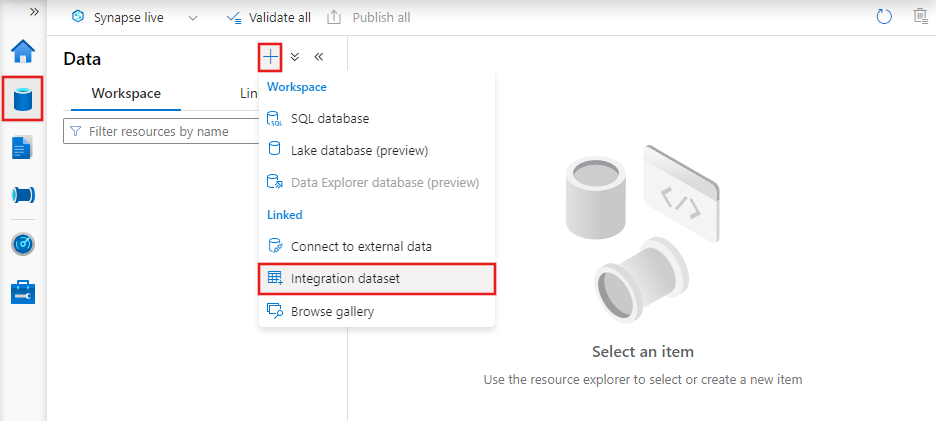
Pour créer un jeu de données à l’aide d’Azure Data Factory Studio, sélectionnez l’onglet Auteur (avec l’icône en forme de crayon), puis l’icône du signe plus pour choisir Jeu de données.
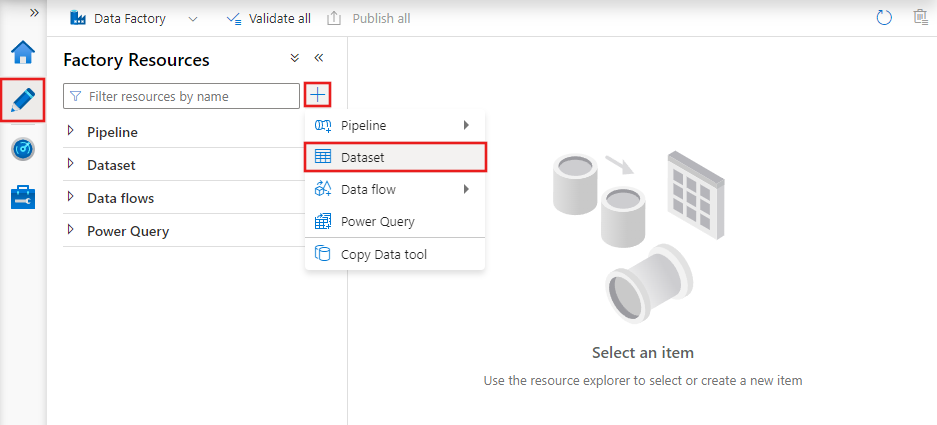
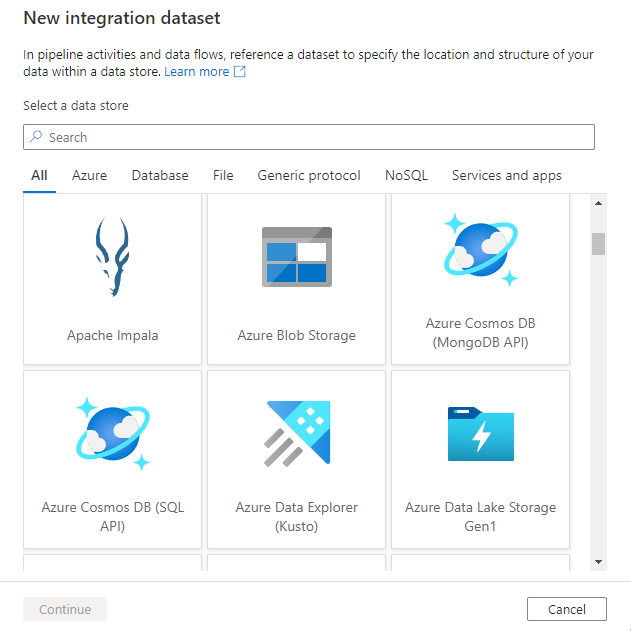
La fenêtre du nouveau jeu de données vous permet de choisir l’un des connecteurs disponibles dans Azure Data Factory pour configurer un service lié existant ou nouveau.
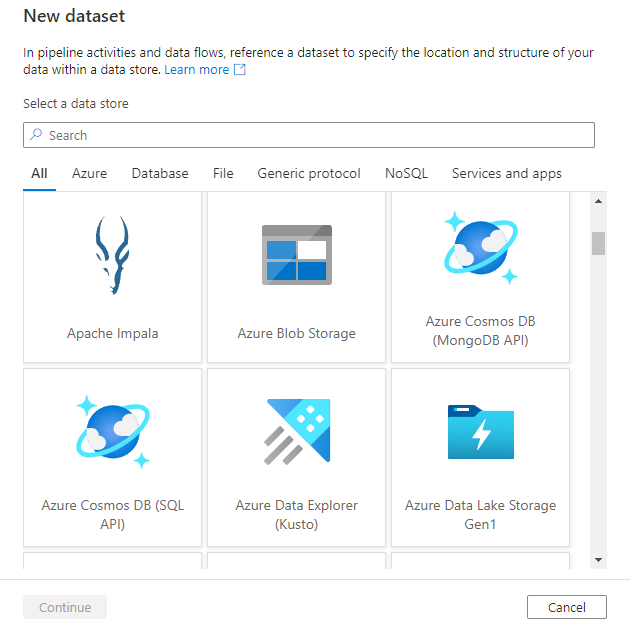
Vous serez ensuite invité à choisir le format du jeu de données.

Enfin, vous pouvez choisir un service lié existant du type que vous avez sélectionné pour le jeu de données ou en créer un s’il n’est pas déjà défini.
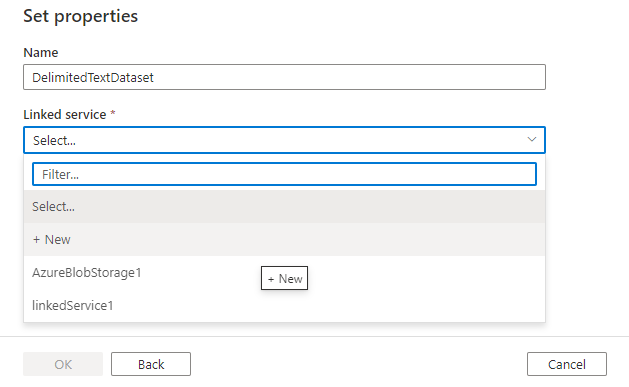
Une fois que vous avez créé le jeu de données, vous pouvez l’utiliser dans n’importe quel pipeline dans Azure Data Factory.
Jeu de données JSON
Un jeu de données est défini au format JSON suivant :
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
La table suivante décrit les propriétés dans le JSON ci-dessus :
| Propriété | Description | Obligatoire |
|---|---|---|
| name | Nom du jeu de données Consultez Règles de nommage. | Oui |
| type | Type du jeu de données. Spécifiez l’un des types pris en charge par la fabrique de données (par exemple : DelimitedText, AzureSqlTable). Pour plus de détails, voir Types de jeux de données. |
Oui |
| schéma | Schéma du jeu de données, représente le type des données physiques et leur forme. | Non |
| typeProperties | Les propriétés de type sont différentes pour chaque type. Pour plus d’informations sur les types pris en charge et leurs propriétés, consultez Type du jeu de données. | Oui |
Lorsque vous importez le schéma d’un jeu de données, sélectionnez le bouton Importer un schéma, puis choisissez de l’importer à partir de la source ou d’un fichier local. Dans la plupart des cas, vous allez importer le schéma directement à partir de la source. Cependant, si vous disposez déjà d’un fichier de schéma local (un fichier Parquet ou CSV avec en-têtes), vous pouvez demander au service de baser le schéma sur ce fichier.
Dans l’activité de copie, les jeux de données sont utilisés dans la source et le récepteur. Le schéma défini dans le jeu de données est facultatif en tant que référence. Si vous souhaitez appliquer un mappage de colonne/champ entre la source et le récepteur, reportez-vous à Mappage de schéma et de type.
Dans Data Flow, les jeux de données sont utilisés dans les transformations de source et de récepteur. Les jeux de données définissent les schémas de données de base. Si vos données n’ont pas de schéma, vous pouvez utiliser la dérive du schéma pour votre source et votre récepteur. Les métadonnées des jeux de données s’affichent dans votre transformation source en tant que projection source. La projection dans la transformation source représente les données Data Flow avec les types et les noms définis.
Type de jeu de données
Le service prend en charge de nombreux types de jeux de données, selon les magasins de données que vous utilisez. Vous trouverez la liste des magasins de données pris en charge dans l’article Vue d’ensemble du connecteur. Sélectionnez un magasin de données pour découvrir comment créer un service lié et un jeu de données pour ce dernier.
Par exemple, pour un jeu de données de texte délimité, le type de jeu de données est défini sur DelimitedText comme indiqué dans l’exemple de code JSON suivant :
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Créez les jeux de données
Vous pouvez créer des jeux de données en utilisant l’un des outils ou kits de développement logiciel suivants : .NET API, PowerShell, REST API, modèle Azure Resource Manager et portail Azure
Jeux de données de la version actuelle et de la version 1
Voici quelques différences entre les jeux de données dans la version actuelle de Data Factory (et Azure Synapse) et la version hérité Data Factory 1 :
- La propriété externe n’est pas prise en charge dans la version actuelle. Elle est remplacée par un déclencheur.
- Les propriétés de stratégie et de disponibilité ne sont pas prises en charge dans la version actuelle. L’heure de début d’un pipeline dépend des déclencheurs.
- Les jeux de données limités (définis dans un pipeline) ne sont pas pris en charge dans la version actuelle.
Contenu connexe
Consultez les didacticiels suivants pour obtenir des instructions pas à pas sur la création de pipelines et de jeux de données à l’aide de l’un de ces outils ou Kits de développement logiciel (SDK).