Transformation d’analyse dans un flux de données de mappage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
Utilisez la transformation Analyse pour analyser les colonnes de texte de vos données qui sont des chaînes sous forme de documents. Les types de documents incorporés actuellement pris en charge et qui peuvent être analysés sont JSON, XML et Texte délimité.
Configuration
Dans le panneau de configuration de la transformation d’analyse, vous devez d’abord choisir le type de données contenu dans les colonnes que vous souhaitez analyser en ligne. La transformation d’analyse contient également les paramètres de configuration suivants.

Colonne
À l’instar des colonnes dérivées et des agrégats, la propriété Colonne vous permet de modifier une colonne existante en la sélectionnant à partir du menu déroulant. Vous pouvez également saisir le nom d’une nouvelle colonne ici. ADF stocke les données sources analysées dans cette colonne. Dans la plupart des cas, vous pouvez définir une nouvelle colonne qui analyse le champ de chaîne du document incorporé entrant.
Expression
Utilisez le générateur d’expressions pour définir la source de votre analyse. Définir la source peut être aussi simple que de sélectionner la colonne source avec les données autonomes que vous souhaitez analyser, ou vous pouvez créer des expressions complexes à analyser.
Exemples d’expressions
Données de la chaîne source :
chrome|steel|plastic- Expression :
(desc1 as string, desc2 as string, desc3 as string)
- Expression :
Données JSON sources :
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- Expression :
(level as string, registration as long)
- Expression :
Données JSON sources imbriquées :
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- Expression :
(car as (model as string, year as integer), color as string, transmission as string)
- Expression :
Données XML sources :
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- Expression :
(Customers as (Customer as integer, CompanyName as string))
- Expression :
XML source avec données d’attribut :
<cars><car model="camaro"><year>1989</year></car></cars>- Expression :
(cars as (car as ({@model} as string, year as integer)))
- Expression :
Expressions avec des caractères réservés :
{ "best-score": { "section 1": 1234 } }- L’expression ci-dessus ne fonctionne pas, car le caractère « - » est interprété dans
best-scorecomme une opération de soustraction. Dans ces cas, utilisez une variable avec une notation entre crochets pour indiquer au moteur JSON d’interpréter le texte littéralement :var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
- L’expression ci-dessus ne fonctionne pas, car le caractère « - » est interprété dans
Remarque : Si vous rencontrez des erreurs lors de l’extraction d’attributs (plus spécifiquement, @model) d’un type complexe, une solution de contournement consiste à convertir le type complexe en chaîne, à supprimer le symbole @ (plus spécifiquement, replace(toString(your_xml_string_parsed_column_name.cars.car),'@','') ), puis à utiliser l’activité de transformation JSON d’analyse.
Type de colonne de sortie
Ici, vous configurez le schéma de sortie cible à partir de l’analyse qui est écrite dans une seule colonne. Le moyen le plus simple de définir un schéma pour la sortie de l’analyse consiste à sélectionner le bouton « Détecter le type » en haut à droite du générateur d’expressions. ADF tente de détecter automatiquement le schéma à partir du champ de chaîne que vous analysez et de le définir pour vous dans l’expression de sortie.
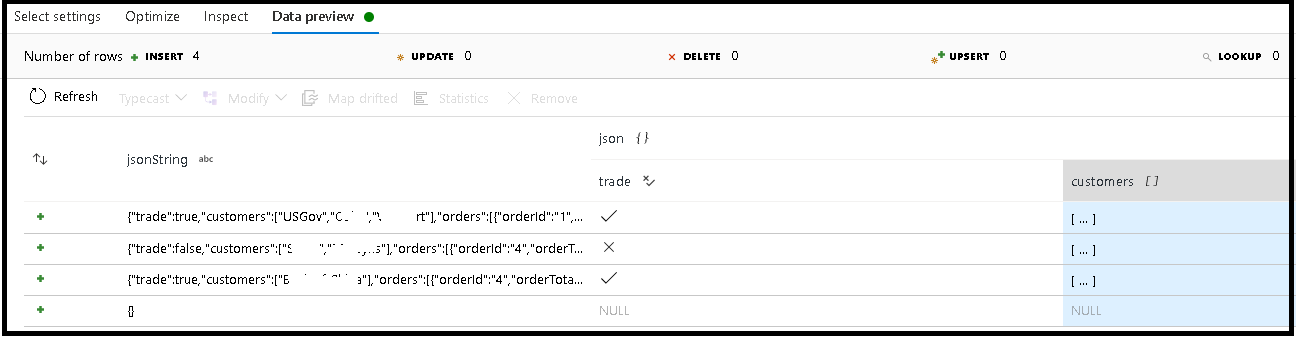
Dans cet exemple, nous avons défini l’analyse du champ entrant « jsonString », qui est du texte brut, mais formaté selon une structure JSON. Nous allons stocker les résultats analysés au format JSON dans une nouvelle colonne appelée « json » suivant ce schéma :
(trade as boolean, customers as string[])
Pour vérifier que votre sortie est correctement mappée, reportez-vous à l’onglet Inspection et à l’aperçu des données.
Utilisez l’activité Colonne dérivée pour extraire les données hiérarchiques (autrement dit, votre_nom_de_colonne_complexe.car.model dans le champ d’expression)
Exemples
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
Script de flux de données
Syntaxe
Exemples
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
Contenu connexe
- Utilisez la transformation d’aplatissement pour convertir des lignes en colonnes.
- Utilisez la Transformation de colonne dérivée pour transformer des lignes.