Copier de nouveaux fichiers de façon incrémentielle sur la base du nom de fichier partitionné dans le temps à l’aide de l’outil Copier des données
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce didacticiel, vous utilisez le portail Azure pour créer une fabrique de données. Ensuite, vous utilisez l’outil Copier des données pour créer un pipeline qui copie de façon incrémentielle de nouveaux fichiers sur la base du nom de fichier partitionné dans le temps de Stockage Blob Azure vers Stockage Blob Azure.
Notes
Si vous débutez avec Azure Data Factory, consultez Présentation d’Azure Data Factory.
Dans ce tutoriel, vous effectuerez les étapes suivantes :
- Créer une fabrique de données.
- Utiliser l’outil Copier les données pour créer un pipeline.
- Surveiller les exécutions de pipeline et d’activité.
Prérequis
- Abonnement Azure : Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Compte de stockage Azure : utilisez le stockage d’objets blob en tant que magasin de données source et récepteur. Si vous ne possédez pas de compte de stockage Azure, consultez les instructions dans Créer un compte de stockage.
Créer deux conteneurs dans le stockage d’objets blob
Préparez votre stockage d’objets blob pour ce tutoriel en effectuant les étapes suivantes.
Créez un conteneur nommé source. Créez un chemin de dossier 2021/07/15/06 dans votre conteneur. Créez un fichier texte vide et nommez-le file1.txt. Chargez le fichier file1.txt vers le chemin de dossier source/2021/07/15/06 dans votre compte de stockage. Vous pouvez utiliser différents outils pour effectuer ces tâches, comme l’Explorateur Stockage Azure.

Notes
Ajustez le nom du dossier en fonction de votre heure UTC. Par exemple, si l’heure UTC actuelle est 6:10 AM le 15 juillet 2021, vous pouvez créer le chemin de dossier source/2021/07/15/06/ d’après la règle source/{Année}/{Mois}/{Jour}/{Heure}/ .
Créez un conteneur nommé destination. Vous pouvez utiliser différents outils pour effectuer ces tâches, comme l’Explorateur Stockage Azure.
Créer une fabrique de données
Dans le menu de gauche, sélectionnez Créer une ressource>Intégration>Data Factory :
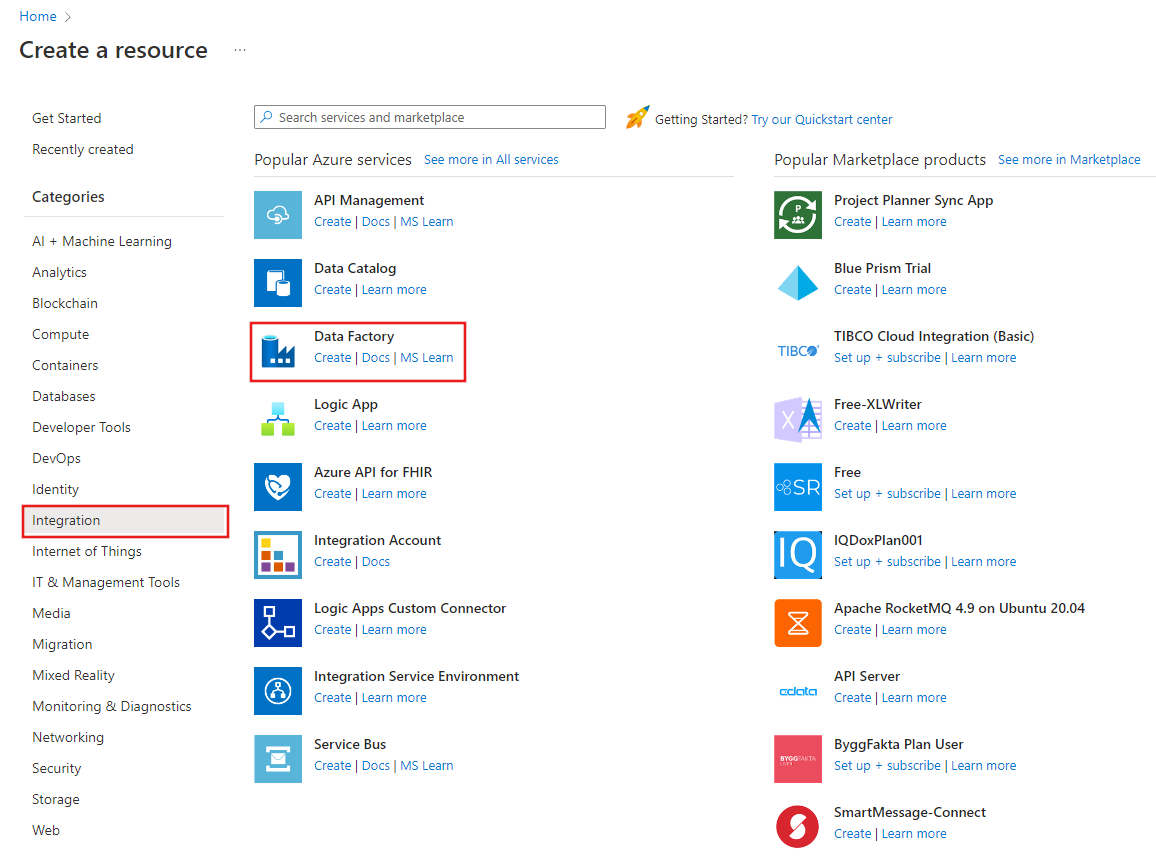
Sur la page Nouvelle fabrique de données, entrez ADFTutorialDataFactory dans le champ Nom.
Le nom de votre fabrique de données doit être un nom global unique. Vous pouvez recevoir le message d’erreur suivant :
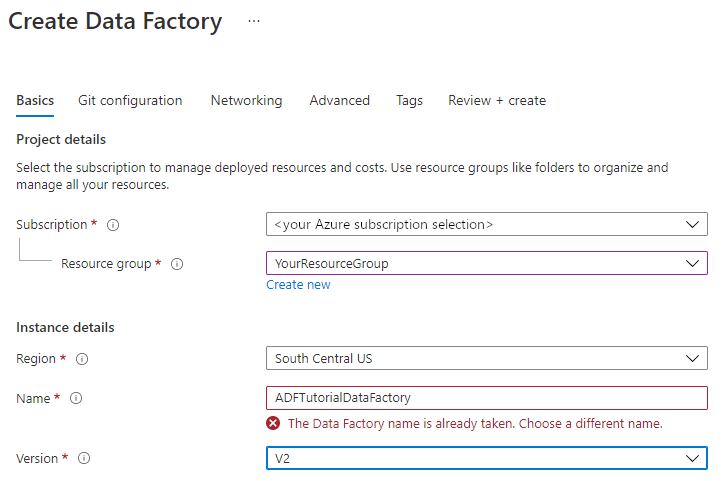
Si vous recevez un message d’erreur concernant la valeur du nom, saisissez un autre nom pour la fabrique de données. Par exemple, utilisez le nom votrenomADFTutorialDataFactory. Pour savoir comment nommer les artefacts Data Factory, voir Data Factory - Règles d’affectation des noms.
Sélectionnez l’abonnement Azure dans lequel vous créez la nouvelle fabrique de données.
Pour Groupe de ressources, réalisez l’une des opérations suivantes :
a. Sélectionnez Utiliser l’existant, puis sélectionnez un groupe de ressources existant dans la liste déroulante.
b. Sélectionnez Créer, puis entrez le nom d’un groupe de ressources.
Pour plus d’informations sur les groupes de ressources, consultez Utilisation des groupes de ressources pour gérer vos ressources Azure.
Sous Version, sélectionnez V2 pour la version.
Sous Emplacement, sélectionnez l’emplacement de la fabrique de données. Seuls les emplacements pris en charge sont affichés dans la liste déroulante. Les magasins de données (tels que le Stockage Azure et SQL Database) et les services de calcul (comme Azure HDInsight) utilisés par votre fabrique de données peuvent se trouver dans d’autres emplacements et régions.
Sélectionnez Create (Créer).
Une fois la création terminée, la page d’accueil Data Factory s’affiche.
Pour lancer l’interface utilisateur Azure Data Factory dans un onglet séparé, sélectionnez Ouvrir dans la mosaïque Ouvrir Azure Data Factory Studio.

Utiliser l’outil Copier les données pour créer un pipeline
Sur la page d’accueil d’Azure Data Factory, sélectionnez le titre Ingérer pour lancer l’outil Copier des données.
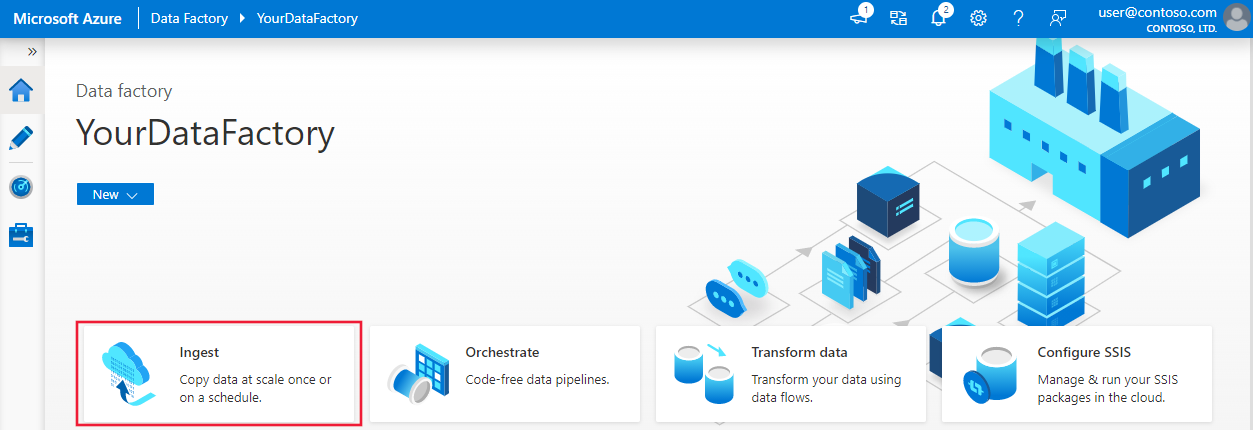
Dans la page Propriétés, effectuez les opérations suivantes :
Sous Type de tâche, choisissez Tâche de copie intégrée.
Sous Cadence des tâches ou calendrier des tâches, sélectionnez Fenêtre bascule.
Sous Périodicité, entrez 1 Heure(s) .
Sélectionnez Suivant.

Sur la page Banque de données source, procédez comme suit :
a. Sélectionnez + Nouvelle connexion pour ajouter une connexion.
b. Sélectionnez Stockage Blob Azure à partir de la galerie, puis sélectionnez Continuer.
c. Sur la page Nouvelle connexion (Stockage blob Azure) , entrez un nom pour la connexion. Sélectionnez votre abonnement Azure et ensuite votre compte de stockage dans la liste Nom du compte de stockage. Testez la connexion, puis sélectionnez Créer.

d. Sur la page Magasin de données source, sélectionnez la connexion nouvellement créée dans la section Connexion.
e. Dans la section Fichier ou dossier, parcourez et sélectionnez le conteneur source, puis sélectionnez OK.
f. Sous Comportement de chargement de fichier, sélectionnez Chargement incrémentiel : noms de fichiers/dossiers partitionnés dans le temps.
g. Écrivez le chemin de dossier dynamique source/{Année}/{Mois}/{Jour}/{Heure}/ , puis modifiez le format comme le montre la capture d’écran suivante.
h. Cochez la case Copie binaire et sélectionnez Suivant.

Sur la page Magasin de données de destination, procédez comme suit :
Sélectionnez l’AzureBlobStorage, qui est le même compte de stockage que le magasin de la source de données.
Recherchez et sélectionnez le dossier destination, puis OK.
Écrivez le chemin de dossier dynamique destination/{Année}/{Mois}/{Jour}/{Heure}/ , puis modifiez le format comme le montre la capture d’écran suivante.
Sélectionnez Suivant.

Sur la page Paramètres, sous Nom de la tâche, saisissez DeltaCopyFromBlobPipeline et sélectionnez Suivant. L’interface utilisateur de Data Factory crée un pipeline avec le nom spécifié.

Sur la page Résumé, vérifiez les paramètres, puis sélectionnez Suivant.

Sur la page Déploiement, sélectionnez Analyse pour analyser le pipeline (tâche).
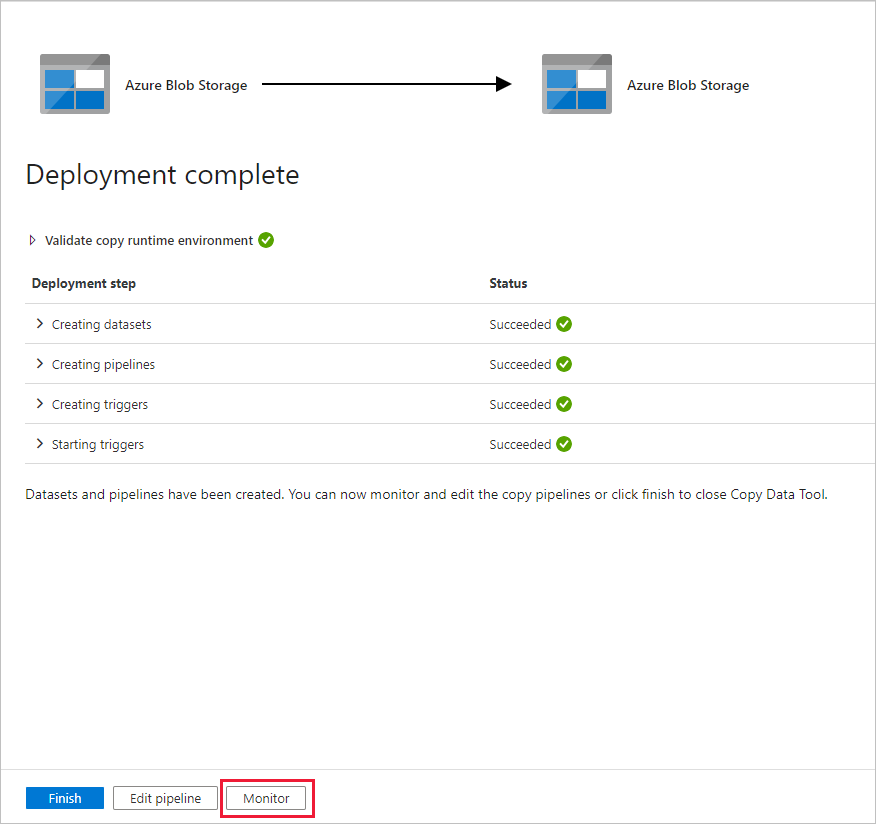
Notez que l’onglet Surveiller sur la gauche est sélectionné automatiquement. Vous devez attendre l’exécution du pipeline quand elle est déclenchée automatiquement (après environ une heure). Lorsqu’il s’exécute, sélectionnez le lien du nom du pipeline DeltaCopyFromblobPipeline pour afficher les détails de l’exécution de l’activité ou réexécuter le pipeline. Sélectionnez Actualiser pour actualiser la liste.

Il n’y a qu’une seule activité (activité de copie) dans le pipeline ; vous ne voyez donc qu’une seule entrée. Ajustez la largeur des colonnes source et destination (si nécessaire) pour afficher plus de détails. Vous pouvez voir que le fichier source (file1.txt) a été copié de source/2021/07/15/06/ vers destination/2021/07/15/06/ avec le même nom de fichier.

Vous pouvez également vérifier cela à l’aide de l’Explorateur Stockage Azure (https://storageexplorer.com/) pour analyser les fichiers.

Créez un autre fichier texte vide nommé file2.txt. Chargez le fichier file2.txt vers le chemin de dossier source/2021/07/15/07 dans votre compte de stockage. Vous pouvez utiliser différents outils pour effectuer ces tâches, comme l’Explorateur Stockage Azure.
Notes
Vous serez peut-être informé qu’un nouveau chemin de dossier doit être créé. Ajustez le nom du dossier en fonction de votre heure UTC. Par exemple, si l’heure UTC actuelle est 7:30 AM le 15 juillet 2021, vous pouvez créer le chemin de dossier source/2021/07/15/07/ avec la règle {Year}/{Month}/{Day}/{Hour}/ .
Pour revenir à la vue Exécutions de pipelines, sélectionnez Toutes les exécutions de pipelines et attendez que le même pipeline soit redéclenché automatiquement après une heure.

Sélectionnez le nouveau lien DeltaCopyFromBlobPipeline pour la deuxième exécution du pipeline en temps voulu, puis appliquez la même procédure pour examiner les détails. Vous constatez que le fichier source (file2.txt) a été copié de source/2021/07/15/07/ vers destination/2021/07/15/07/ avec le même nom de fichier. Vous pouvez le également vérifier à l’aide de l’Explorateur Stockage Azure (https://storageexplorer.com/) pour analyser les fichiers dans le conteneur destination.
Contenu connexe
Passez au tutoriel suivant pour en savoir plus sur la transformation des données en utilisant un cluster Spark sur Azure :