Transformer des données dans un réseau virtuel Azure en utilisant l’activité Hive d’Azure Data Factory à partir du portail Azure
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce didacticiel, vous utilisez le portail Azure pour créer un pipeline Azure Data Factory qui transforme des données à l’aide d’une activité Hive sur un cluster HDInsight qui se trouve dans un réseau virtuel Azure (VNet). Dans ce tutoriel, vous allez effectuer les étapes suivantes :
- Créer une fabrique de données.
- Créer un runtime d’intégration auto-hébergé
- Créer les services liés Stockage Azure et Azure HDInsight
- Créer un pipeline avec une activité Hive.
- Déclencher une exécution du pipeline.
- Surveiller l’exécution du pipeline.
- Vérifier la sortie
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour commencer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Compte Stockage Azure. Vous créez un script Hive et le téléchargez vers le stockage Azure. La sortie du script Hive est stockée dans ce compte de stockage. Dans cet exemple, le cluster HDInsight utilise ce compte de stockage Azure en tant que stockage principal.
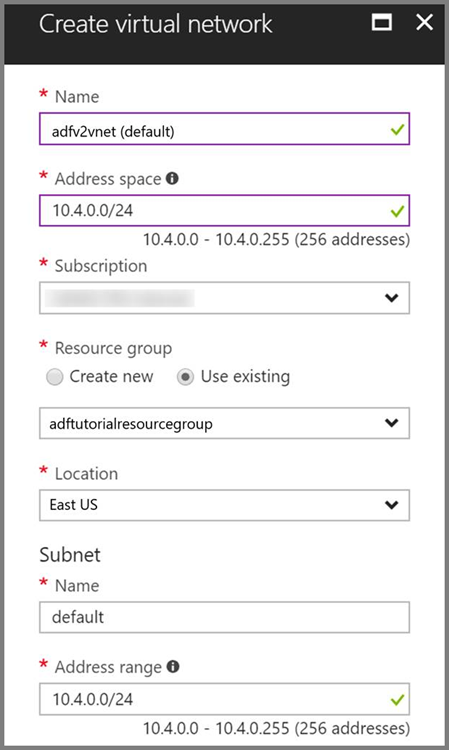
Réseau virtuel Azure. Si vous ne disposez pas d’un réseau virtuel Azure, créez-le en suivant ces instructions. Dans cet exemple, HDInsight est dans un réseau virtuel Azure. Voici un exemple de configuration du réseau virtuel Azure.
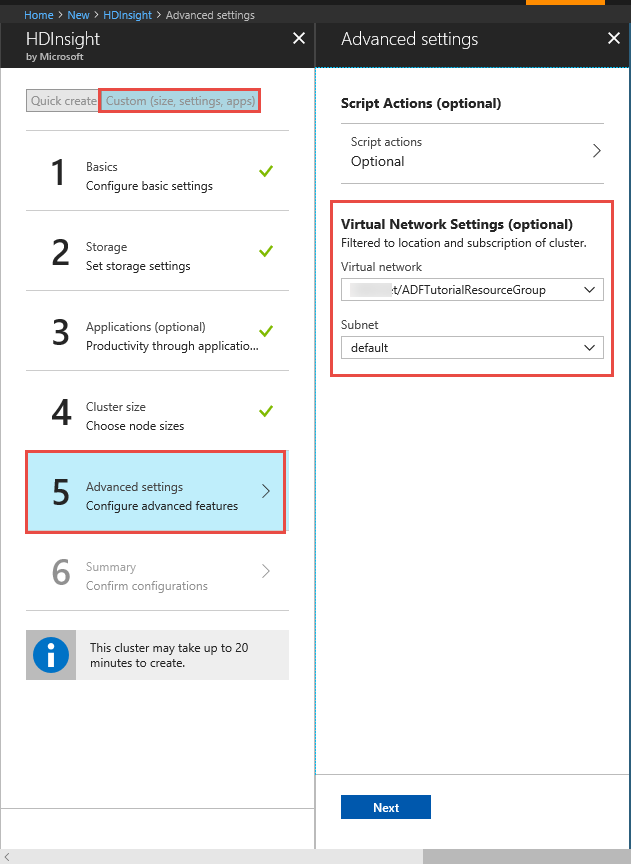
Cluster HDInsight. Créez un cluster HDInsight et joignez-le au réseau virtuel que vous avez créé à l’étape précédente en suivant les instructions de cet article : Étendre Azure HDInsight à l’aide d’un réseau virtuel Azure. Voici un exemple de configuration de HDInsight dans un réseau virtuel.
Azure PowerShell. Suivez les instructions de la page Installation et configuration d’Azure PowerShell.
Une machine virtuelle. Créez une machine virtuelle Azure et joignez-la au réseau virtuel qui contient votre cluster HDInsight. Pour plus d’informations, reportez-vous à Créer des machines virtuelles.
Téléchargez le script Hive sur votre compte de stockage Blob
Créez un fichier SQL Hive nommé hivescript.hql avec le contenu suivant :
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableDans votre stockage Blob Azure, créez un conteneur nommé adftutorial s’il n’existe pas.
Créez un dossier nommé hivescripts.
Téléchargez le fichier hivescript.hql dans le sous-dossier hivescripts.
Créer une fabrique de données
Si vous n’avez pas encore créé votre fabrique de données, suivez les étapes de démarrage rapide : Créer une fabrique de données à l’aide du Portail Azure et Azure Data Factory Studio pour en créer une. Après la création, accédez à la fabrique de données dans le Portail Azure.
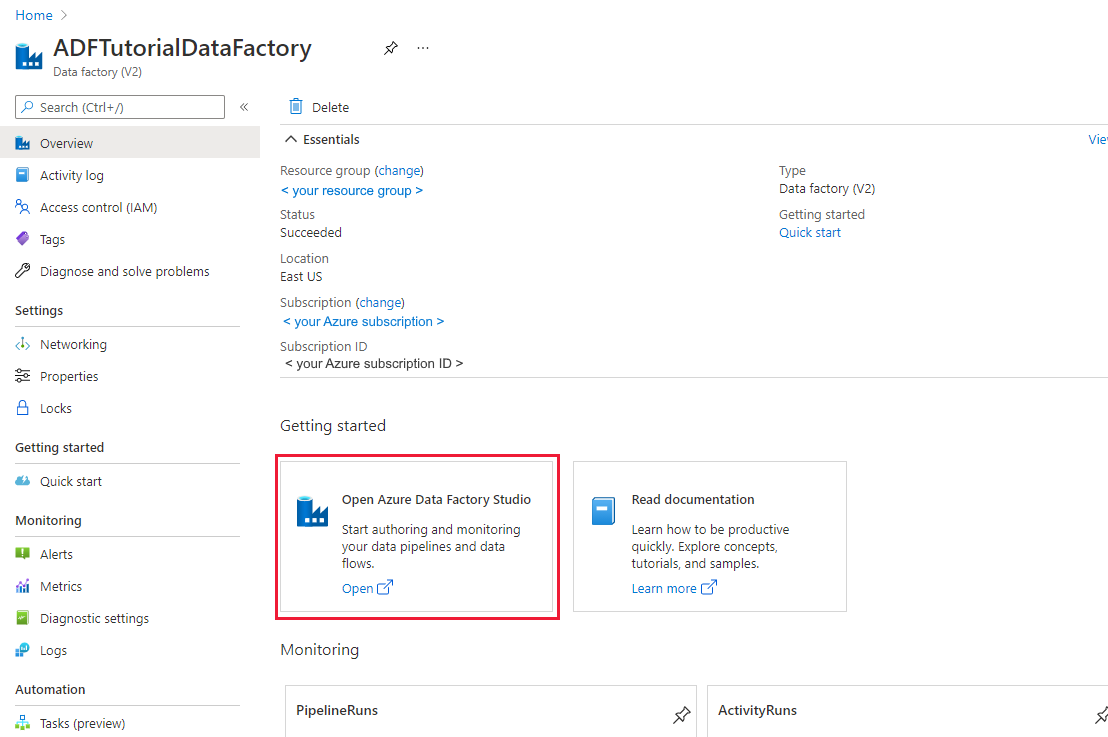
Sélectionnez Ouvrir dans la mosaïque Ouvrir Azure Data Factory Studio pour lancer l’application d’intégration de données dans un onglet distinct.
Créer un runtime d’intégration auto-hébergé
Le cluster Hadoop se trouvant dans un réseau virtuel, vous devez installer un runtime d’intégration auto-hébergé (IR) dans le même réseau virtuel. Dans cette section, vous créez une nouvelle machine virtuelle, vous la joignez au même réseau virtuel et vous installez IR auto-hébergé sur celle-ci. L’IR auto-hébergé permet au service Data Factory de distribuer le traitement des requêtes à un service de calcul tel que HDInsight dans un réseau virtuel. Il vous permet également de déplacer des données vers/depuis des magasins de données dans un réseau virtuel dans Azure. Vous utilisez un IR auto-hébergé lorsque le magasin de données ou le calcul se trouve également dans un environnement local.
Dans l’interface utilisateur d’Azure Data Factory, cliquez sur Connexions au bas de la fenêtre, basculez vers l’onglet Runtimes d’intégration, puis cliquez sur le bouton + Nouveau dans la barre d’outils.
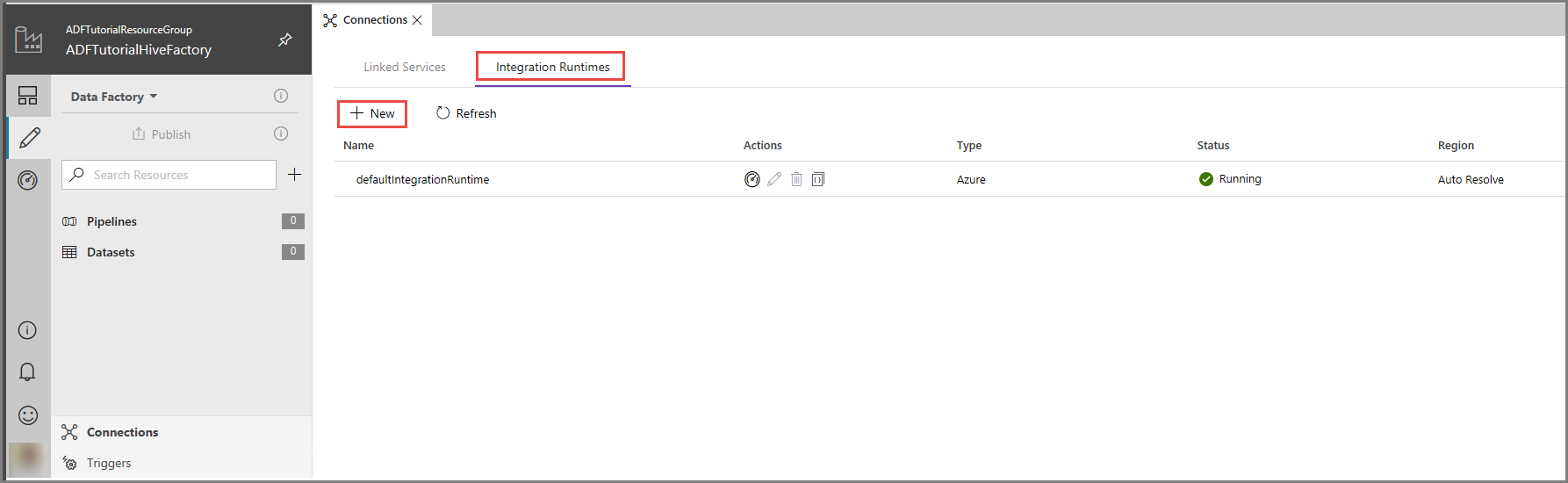
Dans la fenêtre Installation du runtime d’intégration, sélectionnez l’option Perform data movement and dispatch activities to external computes (Effectuer des activités de déplacement des données et distribuer des activités à des services de calcul), puis cliquez sur Suivant.
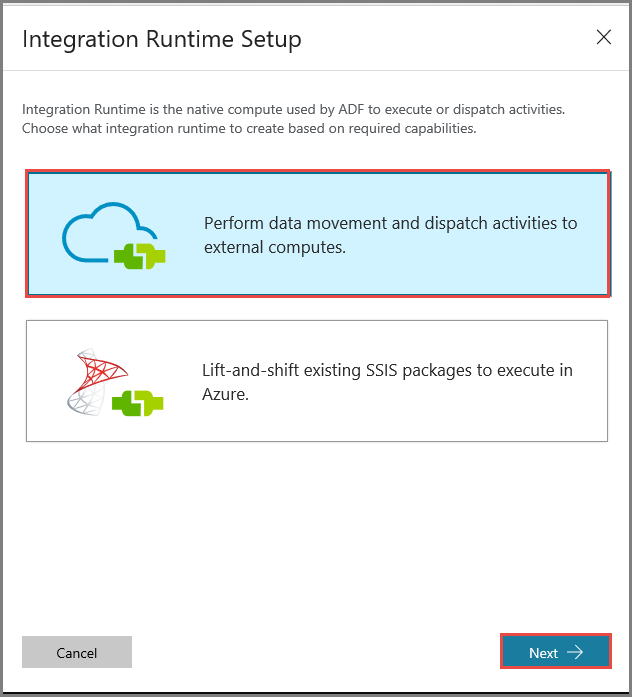
Sélectionnez Réseau privé, puis cliquez sur Suivant.
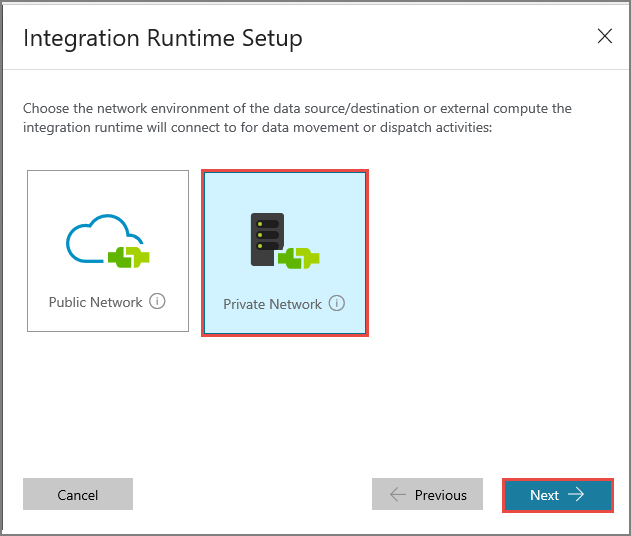
Entrez MySelfHostedIR pour le Nom, puis cliquez sur Suivant.
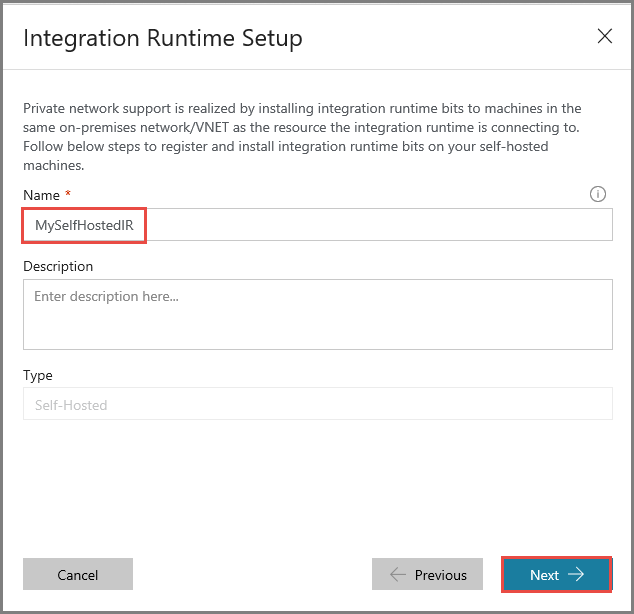
Copiez la clé d’authentification du runtime d’intégration en cliquant sur le bouton Copier, puis enregistrez-la. Gardez la fenêtre ouverte. Vous utilisez cette clé pour inscrire l’IR installé sur une machine virtuelle.
Installer IR sur une machine virtuelle
Sur la machine virtuelle Azure, téléchargez le runtime d’intégration autohébergé. Utilisez la clé d’authentification obtenue à l’étape précédente pour inscrire manuellement le runtime d’intégration auto-hébergé.
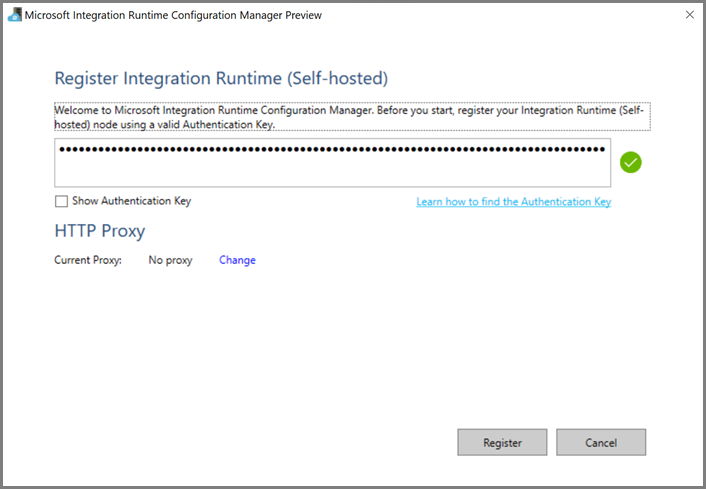
Le message suivant s’affiche une fois que le runtime d’intégration auto-hébergé est bien inscrit.
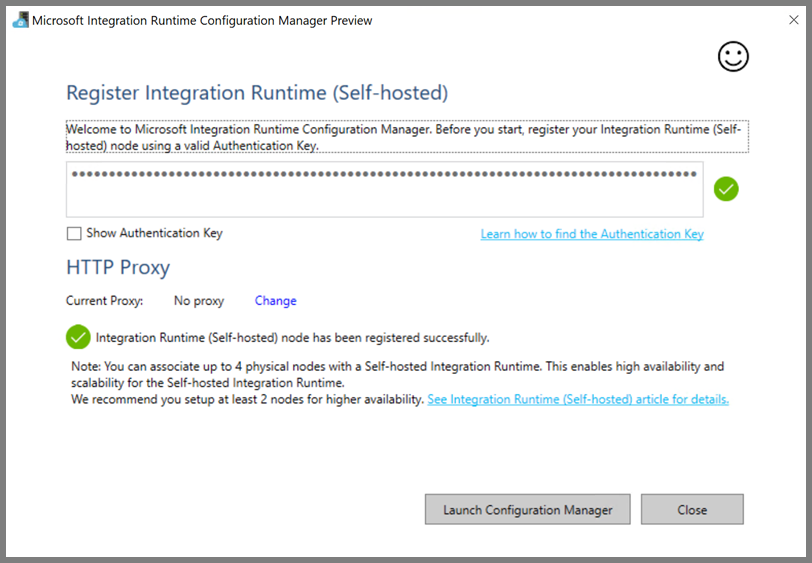
Cliquez sur Lancer Configuration Manager. La page suivante apparaît une fois que le nœud est connecté au service cloud :
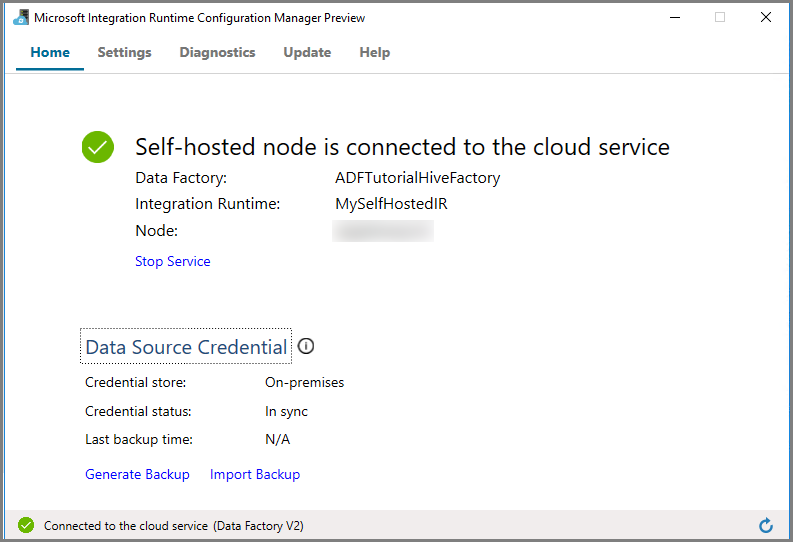
IR auto-hébergé dans l’interface utilisateur d’Azure Data Factory
Dans l’interface utilisateur d’Azure Data Factory, vous devez voir le nom de la machine virtuelle auto-hébergée et son état.
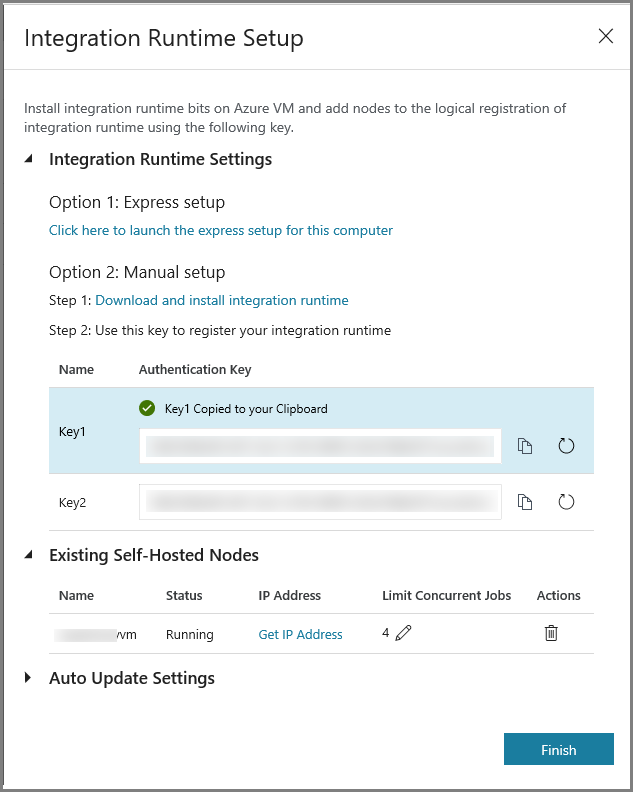
Cliquez sur Terminer pour fermer la fenêtre Installation du runtime d’intégration. L’IR auto-hébergé apparaît dans la liste des runtime d’intégration.

Créez des services liés
Cette section explique comment créer et déployer deux services liés :
- Un service lié au stockage Azure relie un compte de stockage Azure à la fabrique de données. Il s’agit du stockage principal utilisé par votre cluster HDInsight. Dans ce cas, vous utilisez ce compte de stockage Azure pour stocker le script Hive et la sortie du script.
- Un service lié HDInsight. Azure Data Factory soumet le script Hive à ce cluster HDInsight en vue de son exécution.
Créer le service lié Stockage Azure
Basculez vers l’onglet Services liés, puis cliquez sur Nouveau.
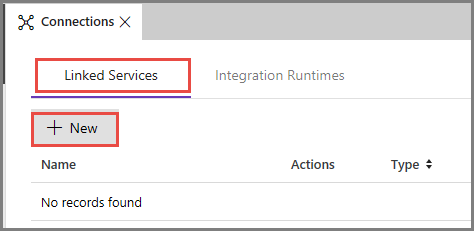
Dans la fenêtre Nouveau service lié, sélectionnez Stockage Blob Azure, puis cliquez sur Continuer.
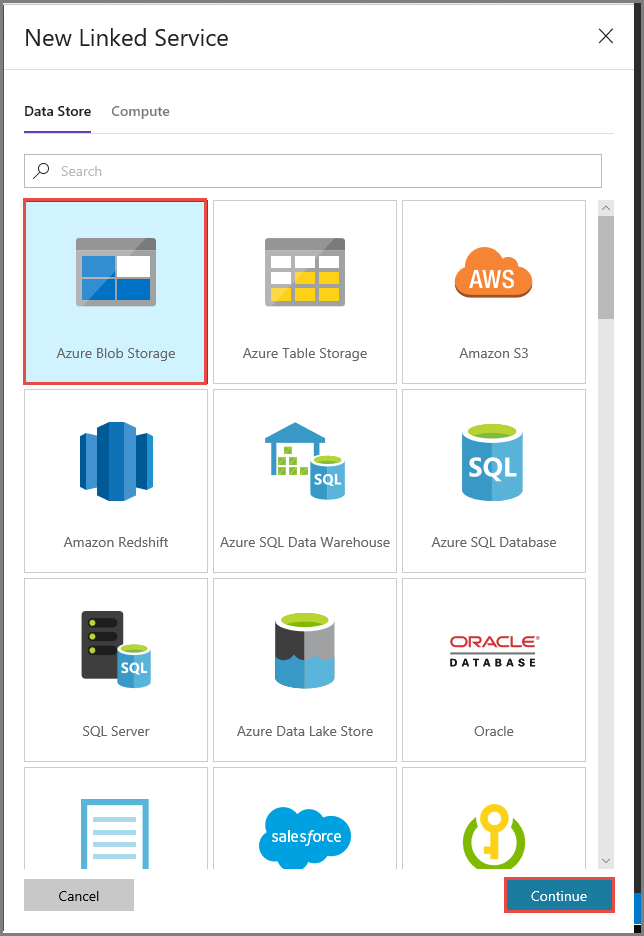
Dans la fenêtre Nouveau service lié, procédez comme suit :
Entrez AzureStorageLinkedService pour Nom.
Sélectionnez MySelfHostedIR pour se connecter via le runtime d’intégration.
Sélectionnez votre compte de stockage Azure pour le Nom du compte de stockage.
Pour tester la connexion au compte de stockage, cliquez sur Tester la connexion.
Cliquez sur Enregistrer.
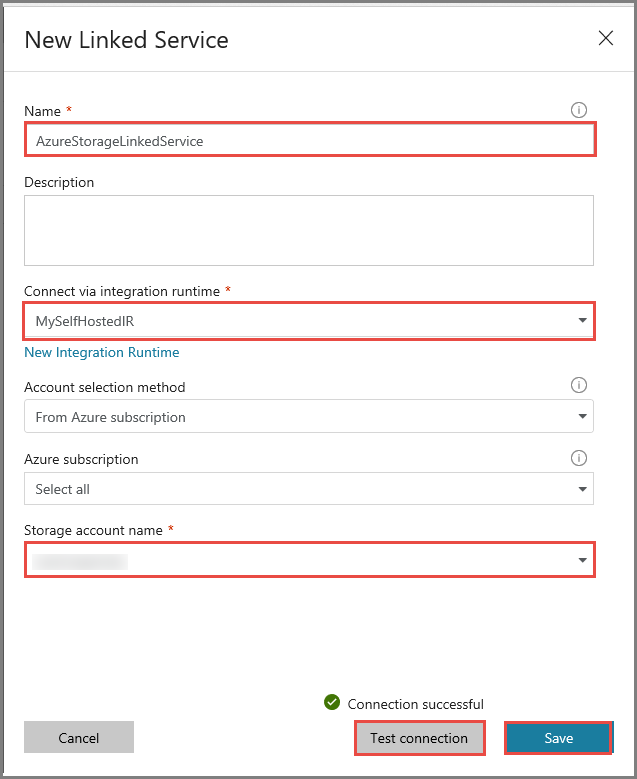
Créer un service lié Azure HDInsight
Cliquez de nouveau sur Nouveau pour créer un autre service lié.
Basculez vers l’onglet Calcul, sélectionnez Azure HDInsight, puis cliquez sur Continuer.
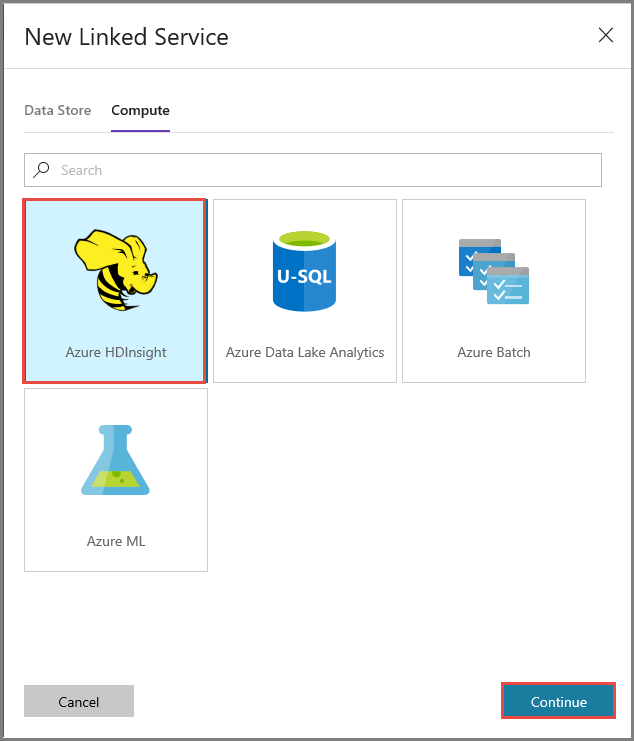
Dans la fenêtre Nouveau service lié, procédez comme suit :
Entrez AzureHDInsightLinkedService pour le Nom.
Sélectionnez Apportez votre propre HDInsight.
Sélectionnez votre cluster HDInsight pour Cluster Hdi.
Entrez le nom d’utilisateur pour le cluster HDInsight.
Entrez le mot de passe correspondant à l’utilisateur.
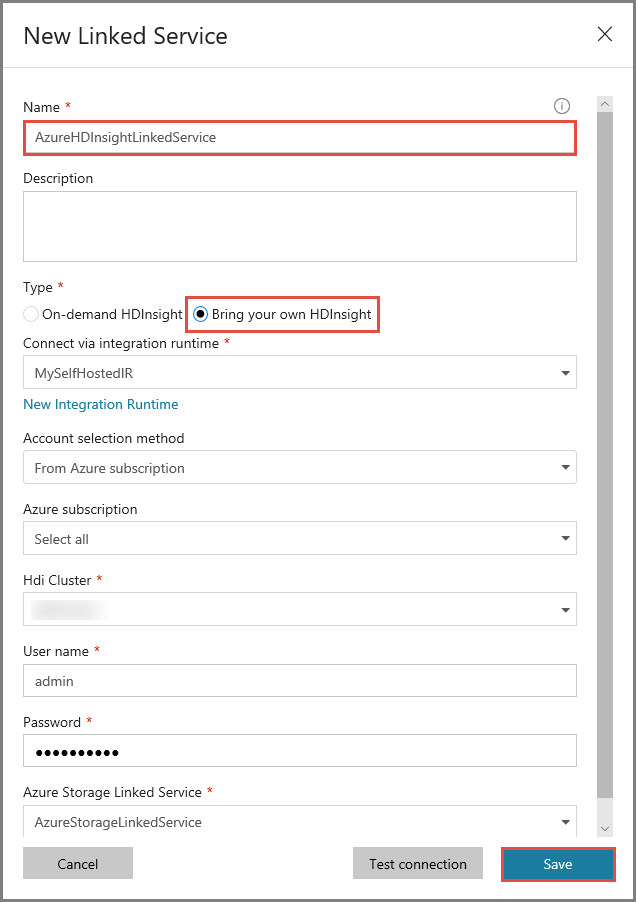
Cet article part du principe que vous avez accès au cluster via Internet. Par exemple, vous devez pouvoir vous connecter au cluster à l’adresse https://clustername.azurehdinsight.net. Cette adresse utilise la passerelle publique qui n’est pas disponible si vous avez utilisé des groupes de sécurité réseau ou des itinéraires définis par l’utilisateur pour restreindre l’accès à partir d’Internet. Pour que la fabrique de données puisse envoyer des travaux au cluster HDInsight sur le réseau virtuel Azure, vous devez configurer votre réseau virtuel Azure de telle sorte que l’URL puisse être résolue sur l’adresse IP privée de la passerelle utilisée par HDInsight.
À partir du portail Azure, ouvrez le réseau virtuel dans lequel HDInsight se trouve. Ouvrez l’interface réseau dont le nom commence par
nic-gateway-0. Notez son adresse IP privée. Par exemple, 10.6.0.15.Si votre réseau virtuel Azure contient un serveur DNS, mettez à jour l’enregistrement DNS pour que l’URL du cluster HDInsight
https://<clustername>.azurehdinsight.netpuisse être résolu en10.6.0.15. Si vous n’avez pas de serveur DNS dans votre réseau virtuel Azure, vous pouvez utiliser une solution de contournement temporaire en modifiant le fichier hosts (C:\Windows\System32\drivers\etc) de toutes les machines virtuelles inscrites en tant que nœuds runtime d’intégration auto-hébergés en ajoutant une entrée semblable à la suivante :10.6.0.15 myHDIClusterName.azurehdinsight.net
Créer un pipeline
Au cours de cette étape, vous allez créer un pipeline avec une activité Hive. L’activité exécute le script Hive en vue de renvoyer des données à partir d’un exemple de table et de les enregistrer sur un chemin d’accès que vous avez défini.
Notez les points suivants :
- scriptPath pointe vers le chemin d’accès au script Hive sur le compte de stockage Azure que vous avez utilisé pour MyStorageLinkedService. Le chemin d'accès respecte la casse.
- Output est un argument utilisé dans le script Hive. Utilisez le format
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/pour le faire pointer vers un dossier existant de votre stockage Azure. Le chemin d'accès respecte la casse.
Dans l’interface utilisateur de Data Factory, cliquez sur + (plus) dans le volet gauche, puis cliquez sur Pipeline.
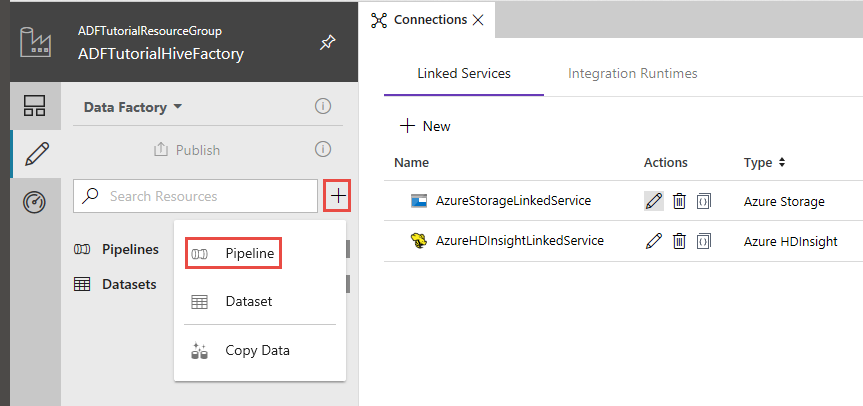
Dans la boîte à outils Activités, développez l’activité HDInsightet glissez-déposez l’activité Hive vers la surface du concepteur de pipeline.
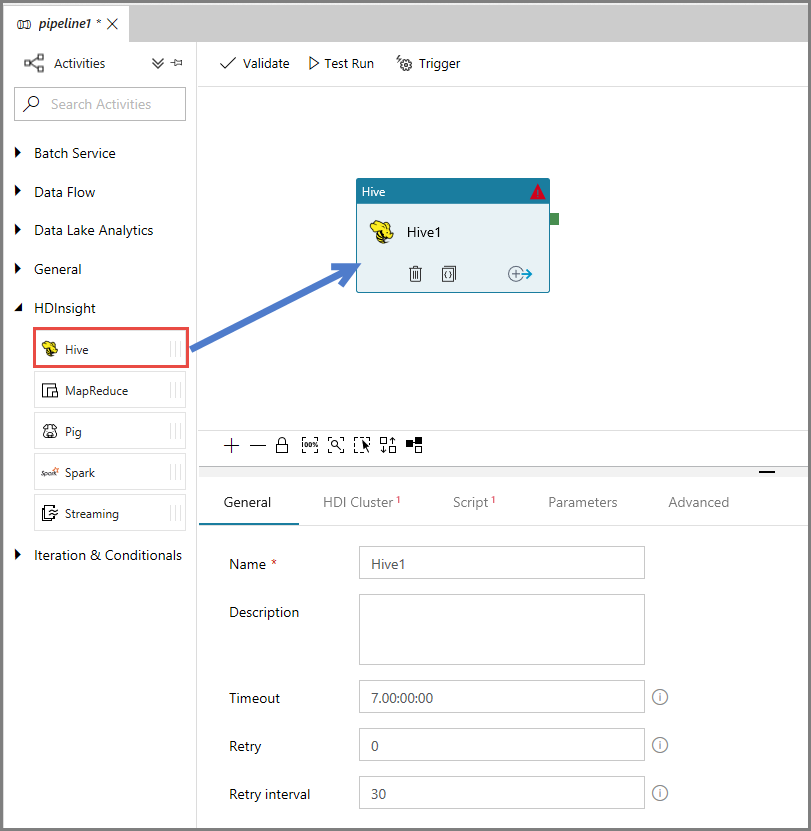
Dans la fenêtre des propriétés, basculez vers l’onglet Cluster HDI, puis sélectionnez AzureHDInsightLinkedService pour Service lié HDInsight.

Basculez vers l’onglet Scripts, et procédez comme suit :
Sélectionnez AzureStorageLinkedService pour Service lié de script.
Pour Chemin d’accès au fichier, cliquez sur Parcourir le stockage.
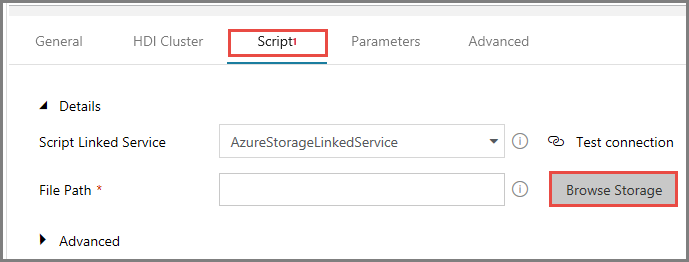
Dans la fenêtre Choisir un fichier ou dossier, accédez au dossier hivescripts du conteneur adftutorial, sélectionnez hivescript.hql, puis cliquez sur Terminer.
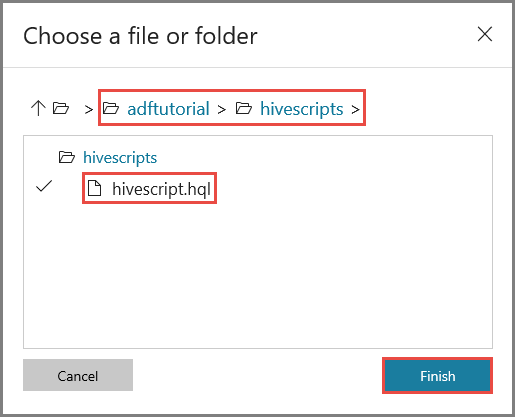
Vérifiez que adftutorial/hivescripts/hivescript.hql pour Chemin d’accès au fichier apparaît.
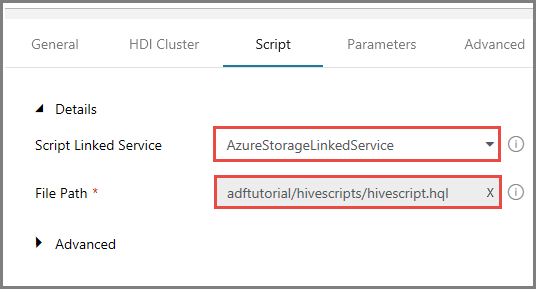
Dans l’onglet Script, développez la section Avancé.
Cliquez sur Auto-fill from script (Remplissage automatique à partir du script) pour Paramètres.
Entrez la valeur du paramètre Sortie au format suivant :
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Par exemple :wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.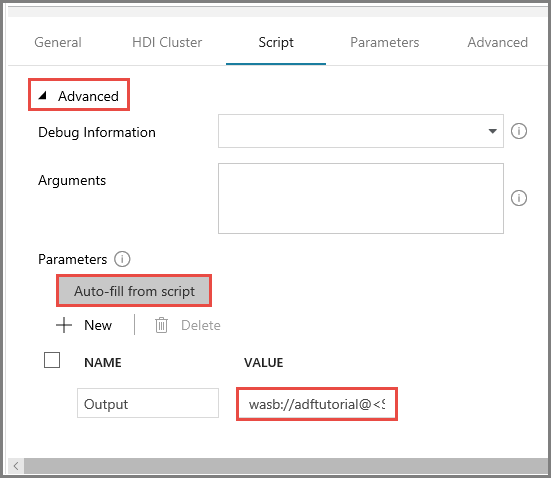
Pour publier les artefacts Data Factory, cliquez sur Publier.
Déclencher une exécution du pipeline
Validez tout d’abord le pipeline en cliquant sur le bouton Valider dans la barre d’outils. Fermez la fenêtre Pipeline Validation Output (Sortie de validation du pipeline) en cliquant sur la flèche droite (>>).
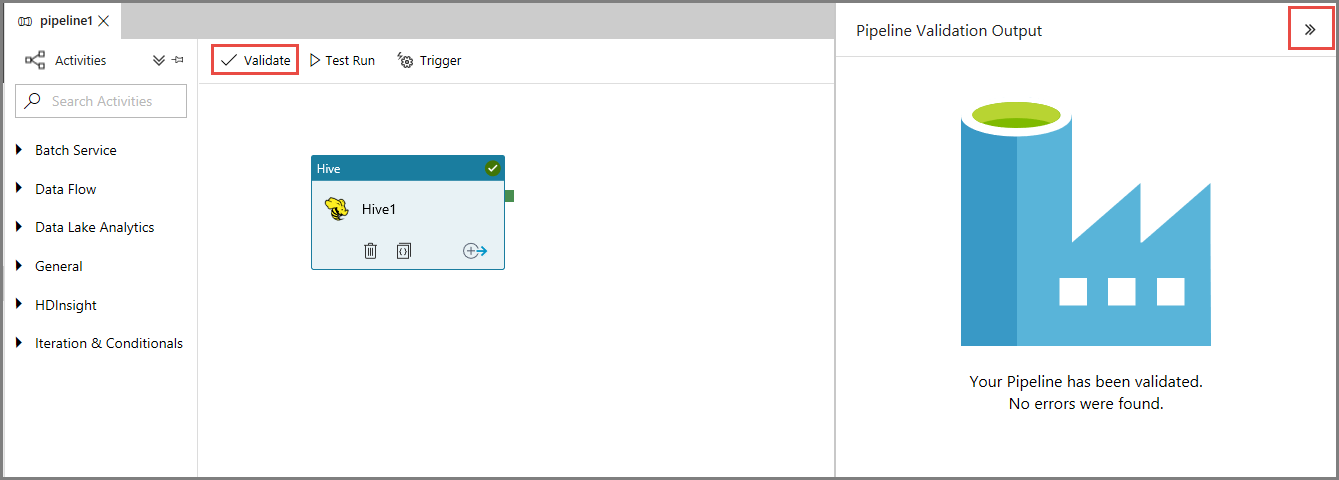
Pour déclencher une exécution du pipeline, cliquez sur Déclencher dans la barre d’outils, puis sur Déclencher maintenant.
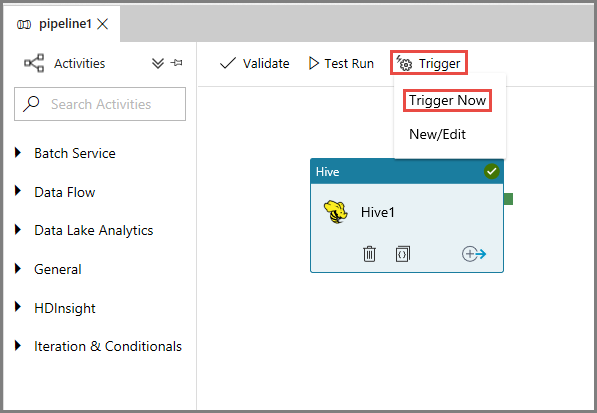
Surveiller l’exécution du pipeline.
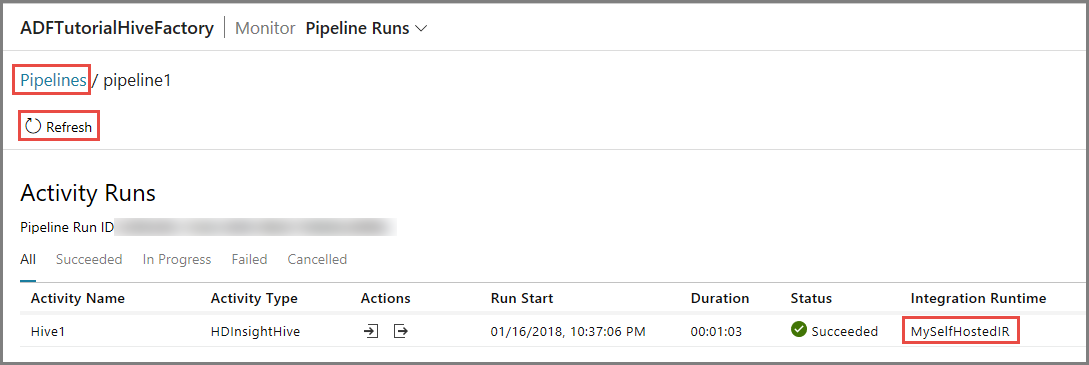
Basculez vers l’onglet Surveiller sur la gauche. Vous voyez une exécution du pipeline dans la liste Exécutions du pipeline.
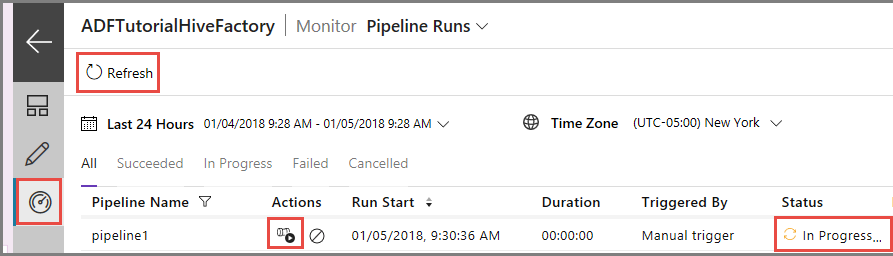
Pour actualiser la liste, cliquez sur Actualiser.
Pour afficher les exécutions d’activités associées aux exécutions du pipeline, cliquez sur Afficher les exécutions d’activités dans la colonneAction. Les autres liens d’action permettent d’arrêter/de réexécuter le pipeline.
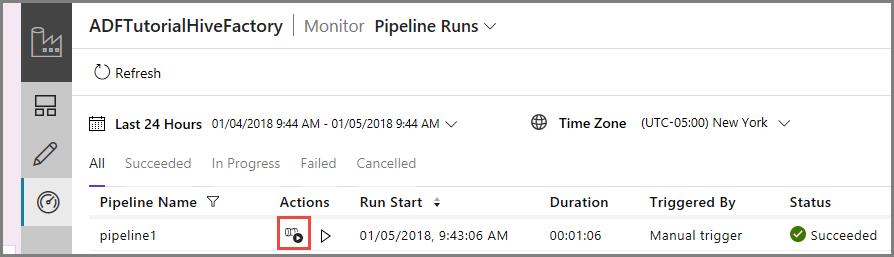
Vous ne voyez qu’une seule exécution d’activité car il n’y a qu’une seule activité dans le pipeline de type HDInsightHive. Pour revenir à l’affichage précédent, cliquez sur le lien Pipelines en haut.
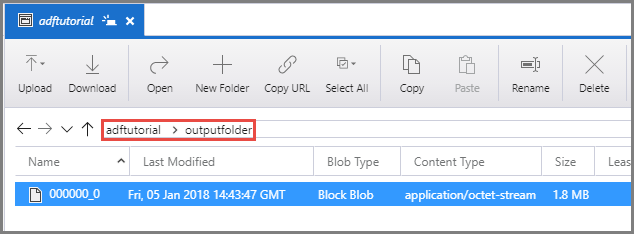
Vérifiez qu’un fichier de sortie apparaît bien dans outputfolder dans le conteneur adftutorial.
Contenu connexe
Dans ce tutoriel, vous avez effectué les étapes suivantes :
- Créer une fabrique de données.
- Créer un runtime d’intégration auto-hébergé
- Créer les services liés Stockage Azure et Azure HDInsight
- Créer un pipeline avec une activité Hive.
- Déclencher une exécution du pipeline.
- Surveiller l’exécution du pipeline.
- Vérifier la sortie
Passez au tutoriel suivant pour en savoir plus sur la transformation des données en utilisant un cluster Spark sur Azure :