Accéder à Azure Data Lake Storage en utilisant le passage direct des informations d’identification Microsoft Entra ID (hérité)
Important
Cette documentation a été mise hors service et peut ne pas être mise à jour.
Le passage des informations d’identification a été mis hors service à partir de Databricks Runtime 15.0 et sera supprimé dans ses versions ultérieures. Databricks vous recommande une mise à niveau vers Unity Catalog. Unity Catalog facilite la sécurité et la gouvernance de vos données en fournissant un emplacement central pour administrer et auditer l’accès aux données dans plusieurs espaces de travail de votre compte. Consultez Qu’est-ce que Unity Catalog ?.
Pour une sécurité et une gouvernance renforcées, contactez l’équipe de votre compte Azure Databricks pour désactiver la transmission des informations d’identification dans votre compte Azure Databricks.
Remarque
Cet article contient des références au terme en liste blanche, un terme qu’Azure Databricks n’utilise pas. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de cet article.
Vous pouvez vous authentifier automatiquement pour Accéder à Azure Data Lake Storage Gen1 depuis Azure Databricks (ADLS Gen1) et ADLS Gen2 depuis des clusters Azure Databricks en utilisant l’identité Microsoft Entra ID que vous utilisez pour vous connecter à Azure Databricks. Quand vous activez le passage des informations d’identification Azure AD Lake Storage pour votre cluster, les commandes que vous exécutez sur ce cluster peuvent lire et écrire les données dans Azure Data Lake Storage sans que vous ayez besoin de configurer les informations d’identification du principal de service pour l’accès au stockage.
Le passage des informations d’identification Azure Data Lake Storage est pris en charge avec Azure Data Lake Storage Gen1 et Gen2 uniquement. Le stockage d’objets Blob Azure ne prend pas en charge le passage des informations d’identification.
Cet article couvre les points suivants :
- Activation du passage des informations d’identification pour les clusters standard et de haute concurrence.
- Configuration du passage des informations d’identification et initialisation des ressources de stockage dans les comptes ADLS.
- Accès direct aux ressources ADLS lorsque le passage des informations d’identification est activé.
- Accès aux ressources ADLS via un point de montage lorsque le passage des informations d’identification est activé.
- Fonctionnalités prises en charge et limitations lors de l’utilisation du passage des informations d’identification.
Des notebooks sont inclus pour fournir des exemples d’utilisation du passage des informations d’identification avec ADLS Gen1 et les comptes de stockage ADLS Gen2.
Exigences
- Plan Premium. Consultez Mettre à niveau ou rétrograder un espace de travail Azure Databricks pour plus d’informations sur la mise à niveau d’un plan standard vers un plan Premium.
- Un compte de stockage Azure Data Lake Storage Gen1 ou Gen2. Les comptes de stockage Azure Data Lake Storage Gen2 doivent utiliser l’espace de noms hiérarchique pour fonctionner avec le passage d’informations d’identification Azure Data Lake Storage. Consultez Créer un compte de stockage pour obtenir des instructions sur la création d’un compte ADLS Gen2, notamment sur l’activation de l’espace de noms hiérarchique.
- Des autorisations utilisateur configurées correctement pour Azure Data Lake Storage. Un administrateur Azure Databricks doit s’assurer que les utilisateurs ont les rôles adéquats, par exemple, contributeur de données Storage Blob, pour lire et écrire les données stockées dans Azure Data Lake Storage. Consultez Utiliser le portail Azure afin d’attribuer un rôle Azure pour l’accès aux données de blob et de file d’attente.
- Comprendre les privilèges des administrateurs d’espace de travail dans les espaces de travail activés pour le transfert et passer en revue vos attributions d’administrateur d’espace de travail existantes. Les administrateurs d’espace de travail peuvent gérer les opérations de leur espace de travail, notamment ajouter des utilisateurs et des principaux de service, créer des clusters et déléguer le rôle d’administrateur d’espace de travail à d’autres utilisateurs. Les tâches de gestion de l’espace de travail, telles que la gestion de la propriété des travaux et l’affichage des notebooks, peuvent donner un accès indirect aux données inscrites dans Azure Data Lake Storage. Le rôle d’administrateur d’espace de travail est un rôle privilégié que vous devez distribuer avec soin.
- Vous ne pouvez pas utiliser un cluster configuré avec les informations d’identification ADLS, par exemple, les informations d’identification du principal de service, avec le passage des informations d’identification.
Important
Vous ne pouvez pas vous authentifier auprès d’Azure Data Lake Storage avec vos informations d’identification Microsoft Entra ID si vous êtes derrière un pare-feu qui n’a pas été configuré pour autoriser le trafic vers Microsoft Entra ID. Le Pare-feu Azure bloque l’accès à Active Directory par défaut. Pour autoriser l’accès, configurez l’étiquette du service Azure Active Directory. Vous trouverez des informations équivalentes pour les appliances virtuelles réseau sous la balise AzureActiveDirectory dans le fichier JSON des balises de service et des plages d’adresses IP Azure. Pour plus d’informations, consultez Étiquettes du service Pare-feu Azure.
Recommandations de journalisation
Vous pouvez consigner les identités transmises au stockage ADLS dans les journaux de diagnostic Azure Storage. La journalisation des identités permet aux requêtes ADLS d’être liées à des utilisateurs individuels à partir de clusters Azure Databricks. Activez la journalisation des diagnostics sur votre compte de stockage pour commencer à recevoir les journaux suivants :
- Azure Data Lake Storage Gen1 : suivez les instructions de la procédure Activer la journalisation de diagnostic pour votre compte Data Lake Storage Gen1.
- Azure Data Lake Storage Gen2 : configurez à l’aide de PowerShell avec la commande
Set-AzStorageServiceLoggingProperty. Spécifiez 2.0 en tant que version, car le format d’entrée de journal 2.0 contient le nom d’utilisateur principal dans la requête.
Activer le passage des informations d’identification Azure Data Lake Storage pour un cluster à concurrence élevée
Les clusters à forte concurrence peuvent être partagés par plusieurs utilisateurs. Ils prennent uniquement en charge Python et SQL avec le passage d’informations d’identification Azure Data Lake Storage.
Important
L’activation du passage des informations d’identification Azure Data Lake Storage pour un cluster à concurrence élevée bloque tous les ports du cluster, à l’exception des ports 44, 53 et 80.
- Lorsque vous créez un cluster, définissez le mode cluster sur Haute concurrence.
- Sous Options avancées, sélectionnez Enable credential passthrough for user-level data access and only allow Python and SQL commands (Activer le passage des informations d’identification pour l’accès aux données de niveau utilisateur et autoriser uniquement les commandes Python et SQL).

Activer le passage des informations d’identification à Azure Data Lake Storage pour un cluster Standard
Les clusters Standard avec passage d’informations d’identification sont limités à un seul utilisateur. Les clusters Standard prennent en charge Python, SQL, Scala et R. Sur Databricks Runtime 10.4 LTS et versions ultérieures, sparklyr est pris en charge.
Vous devez affecter un utilisateur lors de la création du cluster, mais le cluster peut être modifié par un utilisateur avec l’autorisation PEUT GÉRER à tout moment pour remplacer l’utilisateur d’origine.
Important
L’utilisateur affecté au cluster doit disposer au moins de l’autorisation PEUT JOINDRE À au cluster afin d’exécuter des commandes sur le cluster. Les administrateurs d’espaces de travail et le créateur du cluster disposent de l’autorisation PEUT GÉRER. Cependant, ils ne peuvent exécuter aucune commande sur le cluster, sauf s’ils sont l’utilisateur du cluster désigné.
- Lorsque vous créez un cluster, définissez le Mode cluster sur Standard.
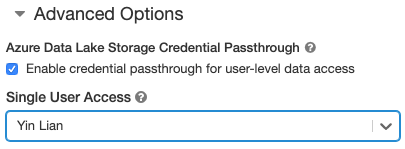
- Sous Options avancées, sélectionnez Activer le passage des informations d’identification pour l’accès aux données de niveau utilisateur et sélectionnez le nom d’utilisateur dans la liste déroulante Accès utilisateur unique.
Créer un conteneur
Les conteneurs permettent d’organiser les objets dans un compte de stockage Azure.
Accéder directement à Azure Data Lake Storage à l’aide du passage des informations d’identification
Après avoir configuré le passage des informations d’identification Azure Data Lake Storage et créé des conteneurs de stockage, vous pouvez accéder aux données directement dans Azure Data Lake Storage Gen1 à l’aide d’un chemin d’accès adl:// et dans Azure Data Lake Storage Gen2 à l’aide d’un chemin d’accès abfss://.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Remplacez
<storage-account-name>par le nom du compte de stockage ADLS Gen1.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Remplacez
<container-name>par le nom d’un conteneur dans le compte de stockage ADLS Gen2. - Remplacez
<storage-account-name>par le nom du compte de stockage ADLS Gen2.
Monter Azure Data Lake Storage sur DBFS à l’aide du passage des informations d’identification
Vous pouvez monter un compte Azure Data Lake Storage ou un dossier à l’intérieur de celui-ci dans Qu’est-ce que DBFS ?. Le montage étant un pointeur vers un magasin Data Lake Store, les données ne sont jamais synchronisées localement.
Lorsque vous montez des données à l’aide d’un cluster activé avec les relais d’informations d’identification Azure Data Lake Storage, toute lecture ou écriture sur le point de montage utilise vos informations d’identification Microsoft Entra ID. Ce point de montage sera visible par les autres utilisateurs, mais les seuls utilisateurs qui auront un accès en lecture et en écriture sont ceux qui répondent aux critères suivants :
- Avoir accès au compte de stockage Azure Data Lake Storage sous-jacent
- Utiliser un cluster activé pour le relais des informations d’identification Azure Data Lake Storage
Azure Data Lake Storage Gen1
Pour monter une ressource Azure Data Lake Storage Gen1, ou un dossier à l’intérieur de celle-ci, utilisez les commandes suivantes :
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Remplacez
<storage-account-name>par le nom du compte de stockage ADLS Gen2. - Remplacez
<mount-name>par le nom du point de montage prévu dans DBFS.
Azure Data Lake Storage Gen2
Pour monter un système de fichiers Azure Data Lake Storage Gen2 ou un dossier à l’intérieur de celui-ci, utilisez les commandes suivantes :
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Remplacez
<container-name>par le nom d’un conteneur dans le compte de stockage ADLS Gen2. - Remplacez
<storage-account-name>par le nom du compte de stockage ADLS Gen2. - Remplacez
<mount-name>par le nom du point de montage prévu dans DBFS.
Avertissement
Ne fournissez pas vos clés d’accès au compte de stockage ou les informations d’identification du principal du service pour l’authentification auprès du point de montage. Cela permettrait à d’autres utilisateurs d’accéder au système de fichiers à l’aide de ces informations d’identification. L’objectif du passage des informations d’identification d’Azure Data Lake Storage est de vous éviter d’avoir à utiliser ces informations d’identification et de garantir que l’accès au système de fichiers est limité aux utilisateurs qui ont accès au compte Azure Data Lake Storage sous-jacent.
Sécurité
Il est possible de partager en toute sécurité des clusters d’informations d’identification Azure Data Lake Storage avec d’autres utilisateurs. Vous serez isolé les uns des autres et ne pourrez pas lire ou utiliser les informations d’identification d’une autre personne.
Fonctionnalités prises en charge
| Fonctionnalité | Version minimale de Databricks Runtime | Notes |
|---|---|---|
| Python et SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | les informations d’identification sont transmises uniquement si le chemin d’accès DBFS correspond à un emplacement dans Azure Data Lake Storage Gen1 ou Gen2. Pour les chemins d’accès DBFS qui sont résolus en d’autres systèmes de stockage, utilisez une autre méthode pour spécifier vos informations d’identification. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| mise en cache du disque | 5.5 | |
| API PySpark ML | 5.5 | Les classes ML suivantes ne sont pas prises en charge : - org/apache/spark/ml/classification/RandomForestClassifier- org/apache/spark/ml/clustering/BisectingKMeans- org/apache/spark/ml/clustering/GaussianMixture- org/spark/ml/clustering/KMeans- org/spark/ml/clustering/LDA- org/spark/ml/evaluation/ClusteringEvaluator- org/spark/ml/feature/HashingTF- org/spark/ml/feature/OneHotEncoder- org/spark/ml/feature/StopWordsRemover- org/spark/ml/feature/VectorIndexer- org/spark/ml/feature/VectorSizeHint- org/spark/ml/regression/IsotonicRegression- org/spark/ml/regression/RandomForestRegressor- org/spark/ml/util/DatasetUtils |
| Variables de diffusion | 5.5 | Dans PySpark, il existe une limite quant à la taille des fonctions définies par l’utilisateur Python que vous pouvez construire, car les fonctions définies par l’utilisateur volumineuses sont envoyées en tant que variables de diffusion. |
| Bibliothèques délimitées aux notebooks | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| Exécuter un notebook Databricks à partir d’un autre notebook | 6.1 | |
| API PySpark ML | 6.1 | Toutes les classes ML PySpark prises en charge. |
| Métriques de cluster | 6.1 | |
| Databricks Connect | 7.3 | Le mode de passage des informations d’identification est pris en charge sur les clusters standard. |
Limitations
Les fonctionnalités suivantes ne sont pas prises en charge avec le passage des informations d’identification Azure Data Lake Storage :
%fs(utilisez à la place la commande dbutils.fs équivalente).- Travaux Databricks.
- Les informations de référence sur l’API REST Databricks.
- Unity Catalog.
- Contrôle d’accès aux tables. Les autorisations accordées par le passage d’informations d’identification Azure Data Lake Storage pourraient être utilisées pour contourner les autorisations précises des ACL de table, tandis que les restrictions supplémentaires des ACL de table limiteront certains des avantages que vous obtenez du passage d’informations d’identification. En particulier :
- Si vous avez l’autorisation Microsoft Entra ID d’accéder aux fichiers de données qui sous-tendent une table particulière, vous disposerez de toutes les autorisations sur cette table via l’API RDD, quelles que soient les restrictions imposées par les ACL de la table.
- Vous serez limité par les autorisations des ACL de table uniquement lorsque vous utiliserez l’API DataFrame. Vous verrez des avertissements relatifs à l’absence d’autorisation
SELECTsur un fichier si vous tentez de lire des fichiers directement avec l’API DataFrame même si vous pouvez lire ces fichiers directement via l’API RDD. - Vous ne pourrez pas lire à partir des tables sauvegardées par des systèmes de fichiers autres que Azure Data Lake Storage, même si vous avez l’autorisation de lire les tables dans la liste de contrôle d’accès de table.
- Les méthodes suivantes sur les objets SparkContext (
sc) et SparkSession (spark) sont les suivantes :- Méthodes déconseillées.
- Des méthodes telles que
addFile()etaddJar()qui permettent aux utilisateurs non administrateurs d’appeler du code Scala. - Toute méthode qui accède à un système de fichiers autre qu’Azure Data Lake Storage Gen1 ou Gen2 (pour accéder à d’autres systèmes de fichiers sur un cluster avec le passage des informations d’identification Azure Data Lake Storage activé ; utilisez une autre méthode pour spécifier vos informations d’identification et consultez la section sur les systèmes de fichiers approuvés sous Résolution des problèmes).
- Les anciennes API Hadoop (
hadoopFile()ethadoopRDD()). - Les API de diffusion en continu, puisque les informations d’identification transmises expirent alors que le flux est toujours en cours d’exécution.
- Les montages DBFS (
/dbfs) sont disponibles uniquement dans Databricks Runtime 7.3 LTS et versions ultérieures. Les points de montage avec le passage des informations d’identification configuré ne sont pas pris en charge par ce chemin d'accès. - Azure Data Factory.
- MLflow sur des clusters à forte concurrence.
- Package Python azureml-sdk sur des clusters à forte concurrence.
- Vous ne pouvez pas étendre la durée de vie des jetons de passe de Microsoft Entra ID en utilisant les stratégies de durée de vie des jetons d’entrée Microsoft Entra ID. Par conséquent, si vous envoyez une commande au cluster qui prend plus d’une heure, elle échoue si une ressource Azure Data Lake Storage est accessible au-delà d’une heure.
- Lors de l’utilisation de Hive 2.3 et versions ultérieures, vous ne pouvez pas ajouter une partition sur un cluster avec le passage des informations d’identification activé. Pour plus d’informations, consultez la section Résolution des problèmes adéquate.
Exemples de notebooks
Les notebooks suivants montrent le passage des informations d’identification Azure Data Lake Storage pour Azure Data Lake Storage Gen1 et Gen2.
Notebook de passage des informations d’identification Azure Data Lake Storage Gen1
Notebook de passage des informations d’identification Azure Data Lake Storage Gen2
Résolution des problèmes
py4j.security.Py4JSecurityException : … n’est pas dans la liste verte
Cette exception est levée quand vous avez accédé à une méthode qui n’a pas été explicitement marquée comme étant sécurisée par Azure Databricks pour les clusters Azure Data Lake Storage assurant le passage des informations d’identification. Dans la plupart des cas, cela signifie que la méthode aurait pu permettre à un utilisateur d’un cluster Azure Data Lake Storage assurant le passage des informations d’identification d’accéder aux informations d’identification d’un autre utilisateur.
org.apache.spark.api.python.PythonSecurityException : chemin d’accès … utilise un système de fichiers non approuvé
Cette exception est déclenchée lorsque vous avez essayé d’accéder à un système de fichiers dont la sécurité n’est pas reconnue par le cluster de passage des informations d’identification Azure Data Lake Storage. L’utilisation d’un système de fichiers non approuvé peut permettre à un utilisateur d’un cluster de passage des informations d’identification Azure Data Lake Storage d’accéder aux informations d’identification d’un autre utilisateur, c’est pourquoi nous refusons tous les systèmes de fichiers dont nous ne sommes pas sûrs qu’ils sont utilisés en toute sécurité.
Pour configurer l’ensemble des systèmes de fichiers de confiance sur un cluster de passage des informations d’identification Azure Data Lake Storage, définissez la clé Spark conf spark.databricks.pyspark.trustedFilesystems sur ce cluster comme une liste séparée par des virgules des noms de classe qui sont des implémentations de confiance de org.apache.hadoop.fs.FileSystem.
L’ajout d’une partition échoue avec AzureCredentialNotFoundException lorsque le passage des informations d’identification est activé
Lors de l’utilisation de Hive 2.3-3.1, si vous tentez d’ajouter une partition sur un cluster alors que le passage des informations d’identification est activé, l’exception suivante se produit :
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Pour contourner ce problème, ajoutez des partitions sur un cluster sans activation du passage des informations d’identification.