Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Les expériences sont des unités d’organisation pour vos exécutions d’entraînement de modèle. Il existe deux types d’expériences : espace de travail et bloc-notes.
- Vous pouvez créer une expérience d’espace de travail à partir de l’interface utilisateur Databricks Mosaic AI ou de l’API MLflow. Les expériences d’espace de travail ne sont associées à aucun bloc-notes, et tout Notebook peut consigner une série de tests à l’aide de l’ID d’expérimentation ou du nom de l’expérience.
- Une expérience de Notebook est associée à un bloc-notes spécifique. Azure Databricks crée automatiquement une expérience de bloc-notes s’il n’y a pas d’expérience active lorsque vous démarrez une exécution à l’aide de mlflow.start_run ().
Pour voir toutes les expériences d'un espace de travail auquel vous avez accès, sélectionnez Machine Learning > Expériences dans la barre latérale.
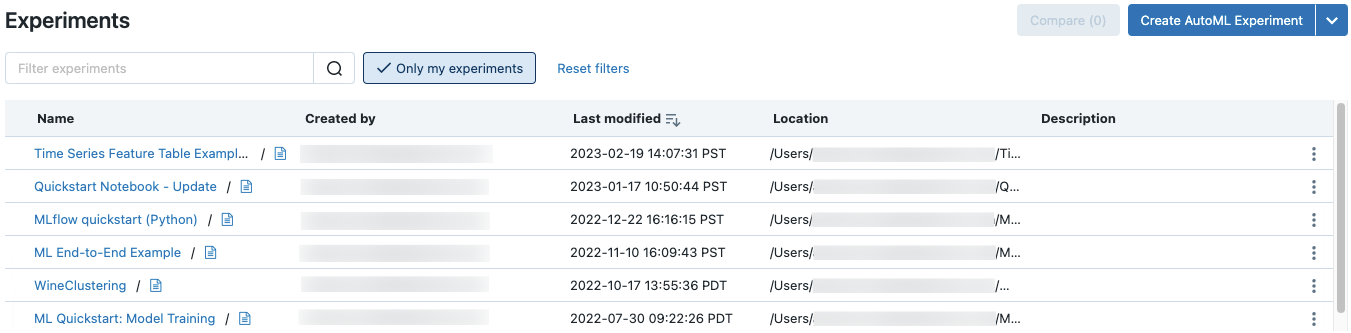
Créer une expérience d’espace de travail
Cette section décrit comment créer une expérience d’espace de travail à l’aide de l’interface utilisateur Azure Databricks. Vous pouvez créer une expérience d’espace de travail directement à partir de l’espace de travail ou de la page Expériences.
Vous pouvez aussi utiliser l’API MLflow ou le fournisseur Databricks Terraform avec databricks_mlflow_experiment.
Pour obtenir des instructions sur la journalisation des exécutions et des modèles dans des expériences d’espace de travail, consultez Journal des exécutions et des modèles dans une expérience.
Créer une expérience à partir de l’espace de travail
Dans la barre latérale, cliquez sur
 Espace de travail.
Espace de travail.Naviguez jusqu’au dossier dans lequel vous souhaitez créer l’expérience.
Cliquez avec le bouton droit sur le dossier, puis sélectionnez Créer > une expérience MLflow.
Dans la boîte de dialogue créer une expérience MLflow, entrez un nom pour l’expérience et un emplacement d’artefact facultatif. Si vous ne spécifiez pas d’emplacement d’artefact, les artefacts sont stockés dans le stockage d’artefacts géré par MLflow :
dbfs:/databricks/mlflow-tracking/<experiment-id>.Azure Databricks prend en charge les volumes Unity Catalog, le stockage Blob Azure et les emplacements d’artefacts de stockage Azure Data Lake.
Dans MLflow 2.15.0 et versions ultérieures, vous pouvez stocker des artefacts dans un volume de catalogue Unity. Lorsque vous créez une expérience MLflow, spécifiez un chemin de volumes sous la forme de
dbfs:/Volumes/catalog_name/schema_name/volume_name/user/specified/pathen tant qu’emplacement d’artefact, comme indiqué dans le code suivant :EXP_NAME = "/Users/first.last@databricks.com/my_experiment_name" CATALOG = "my_catalog" SCHEMA = "my_schema" VOLUME = "my_volume" ARTIFACT_PATH = f"dbfs:/Volumes/{CATALOG}/{SCHEMA}/{VOLUME}" mlflow.set_tracking_uri("databricks") mlflow.set_registry_uri("databricks-uc") if mlflow.get_experiment_by_name(EXP_NAME) is None: mlflow.create_experiment(name=EXP_NAME, artifact_location=ARTIFACT_PATH) mlflow.set_experiment(EXP_NAME)Pour stocker des artefacts dans le stockage d’objets BLOB Azure, spécifiez un URI sous la forme
wasbs://<container>@<storage-account>.blob.core.windows.net/<path>. Les Artifacts stockées dans le stockage d’objets blob Azure n’apparaissent pas dans l’interface utilisateur MLflow ; vous devez les télécharger à l’aide d’un client de stockage d’objets blob.Remarque
Lorsque vous stockez un artefact dans un autre emplacement que DBFS, l’artefact n’apparaît pas dans l’interface utilisateur MLflow. Les modèles stockés dans des emplacements autres que DBFS ne peuvent pas être inscrits dans le Registre du modèle.
Cliquez sur Créer. La page des détails de l’expérience pour la nouvelle expérience s’affiche.
Pour consigner des exécutions dans cette expérience, appelez
mlflow.set_experiment()avec le chemin d’expérimentation. Pour afficher le chemin de l’expérience, cliquez sur l’icône d’informations à droite du nom de l’expérience. Consultez l'enregistrement des exécutions et des modèles dans une expérience pour des informations détaillées et un exemple de cahier.
à droite du nom de l’expérience. Consultez l'enregistrement des exécutions et des modèles dans une expérience pour des informations détaillées et un exemple de cahier.
Créer une expérience à partir de la page Expériences
Pour créer un réglage fin de modèle de fondement, AutoML ou une expérience personnalisée, cliquez sur Expériences ou sélectionnez Nouvelle > Expérience dans le volet latéral gauche.
En haut de la page, sélectionnez l’une des options suivantes pour configurer une expérience :
- Ajustement du Modèle Fondamental. La boîte de dialogue Foundation Model Fine-tuning s’affiche. Pour plus d’informations, consultez Créer un lancement de formation à l’aide de l’interface utilisateur de réglage fin du modèle Foundation.
- Prévision. La boîte de dialogue Configurer l’expérience de prévision s’affiche. Pour plus d’informations, consultez Configurer l’expérience AutoML.
- Classification. La boîte de dialogue Configurer l’expérience de classification s’affiche. Pour plus d’informations, consultez Configurer l’expérience de classification avec l’interface utilisateur.
- Régression. La boîte de dialogue Configurer l’expérience de classification s’affiche. Pour plus d’informations, consultez Configurer l’expérience de régression avec l’interface utilisateur.
- Personnalisez. La boîte de dialogue créer une expérience MLflow s’affiche. Pour plus d’informations, consultez l’étape 4 dans Créer une expérience à partir de l’espace de travail.
Créer une expérience de notebook
Lorsque vous utilisez la commande mlflow.start_run () dans un bloc-notes, l’exécution enregistre les métriques et les paramètres dans l’expérience active. Si aucune expérimentation n’est active, Azure Databricks crée une expérience de bloc-notes. Une expérience de bloc-notes partage le même nom et le même ID que son bloc-notes correspondant. L’ID du bloc-notes est l’identificateur numérique à la fin de l' URL et de l’ID du bloc-notes.
Remarque
Les utilisateurs qui exécutent MLflow sur le calcul avec un accès de groupe dédié doivent vérifier que le groupe est autorisé à écrire dans le répertoire dans lequel se trouve le bloc-notes ou mlflow.set_tracking_uri("<path>") à utiliser pour spécifier un dossier dans lequel MLflow doit écrire.
Vous pouvez également passer un chemin d’accès d’espace de travail Azure Databricks vers un notebook existant dans mlflow.set_experiment() pour créer une expérience de notebook pour celle-ci.
Pour obtenir des instructions sur la journalisation des exécutions dans des expériences de notebook, consultez Journaliser les exécutions et les modèles dans une expérience.
Remarque
Si vous supprimez une expérience de bloc-notes à l’aide de l’API (par exemple, MlflowClient.tracking.delete_experiment() dans Python), le bloc-notes lui-même est déplacé dans le dossier Corbeille.
Afficher les expériences
Chaque expérience à laquelle vous avez accès apparaît sur la page expériences. À partir de cette page, vous pouvez afficher n’importe quelle expérience. Cliquez sur un nom d’expérience pour afficher la page des détails de l’expérience.
Autres façons d’accéder à la page des détails de l’expérience :
- Vous pouvez accéder à la page des détails de l’expérience d’une expérience d’espace de travail à partir du menu de l’espace de travail.
- Vous pouvez accéder à la page de détails de l'expérience pour une expérience sur bloc-notes depuis le carnet.
Pour rechercher des expériences, tapez du texte dans le champ Filtrer les expériences, puis appuyez sur Entrée ou cliquez sur l’icône de loupe. La liste d’expérimentation change pour afficher uniquement les expériences qui contiennent le texte recherché dans la colonne nom, créé par, emplacement ou description.
Cliquez sur le nom d’une expérience dans le tableau pour afficher sa page de détails de l’expérience :
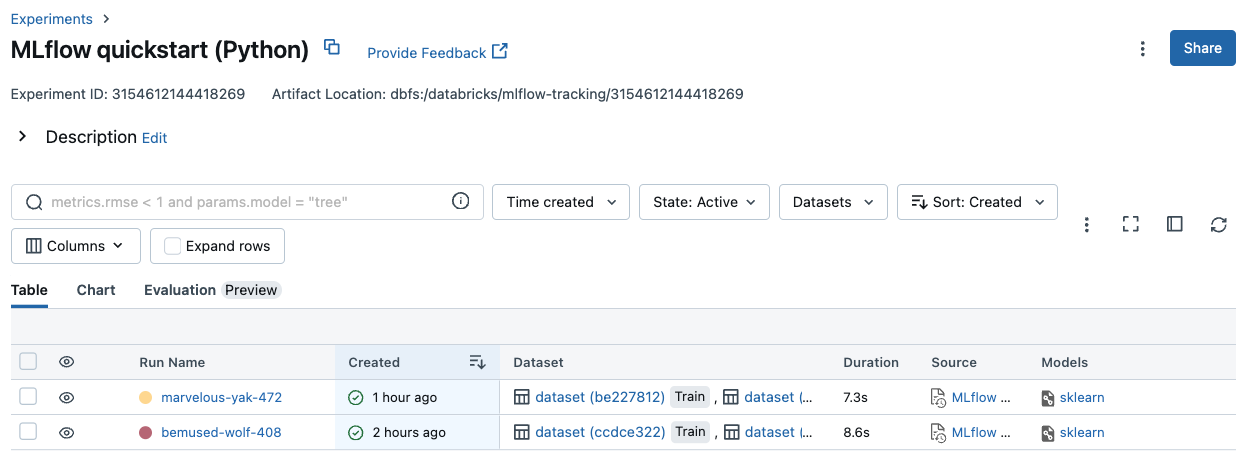
La page de détails de l’expérience répertorie toutes les exécutions associées à l’expérience. À partir de la table, vous pouvez ouvrir la page exécuter pour toute exécution associée à l’expérience en cliquant sur l'heure de l’exécution. La colonne source vous donne accès à la version du Notebook qui a créé l’exécution. Vous pouvez également rechercher et Filtrer les exécutions par métriques ou paramètres de paramètres.
Afficher une expérience d’espace de travail
- Dans la barre latérale, cliquez sur Espace de travail.
- Accédez au dossier qui contient l’expérience.
- Cliquez sur le nom de l’expérience.
Afficher une expérience de notebook
Dans la barre latérale droite du bloc-notes, cliquez sur .Experiment icon
L’encadré exécuter l’expérimentation apparaît et affiche un résumé de chaque exécution associée à l’expérience du Notebook, y compris les paramètres et les métriques d’exécution. En haut de la barre latérale figure le nom de l’expérience dans laquelle le dernier bloc-notes s’est connecté (une expérience de bloc-notes ou une expérience de l’espace de travail).
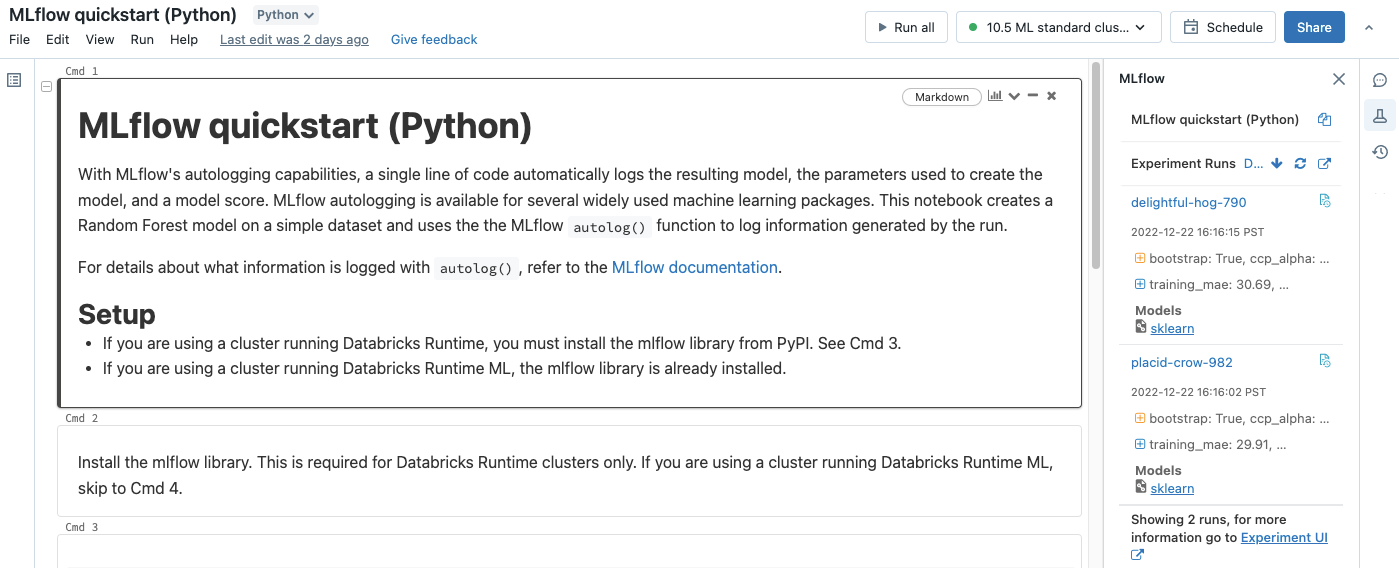
Dans la barre latérale, vous pouvez accéder à la page des détails de l’expérience ou directement à une exécution.
- Pour visualiser l'expérience, cliquez sur
 à l'extrême droite, à côté de Exécutions d’expériences.
à l'extrême droite, à côté de Exécutions d’expériences. - Pour afficher une exécution, cliquez sur le nom de l’exécution.
Gérer les expériences
Vous pouvez renommer, supprimer ou gérer des autorisations pour une expérience que vous possédez à partir de la page expériences, de la page de détails de l’expérience ou du menu de l’espace de travail.
Remarque
Vous ne pouvez pas directement renommer, supprimer ou gérer les permissions sur une expérience MLflow qui a été créée par un notebook dans un dossier Databricks Git. Vous devez effectuer ces actions au niveau du dossier Git.
Renommer l’expérience
Vous pouvez renommer une expérience que vous possédez à partir de la page Experiments ou à partir de la page de détails de l'expérience.
- Dans la page Expériences, dans la colonne la plus à droite, cliquez sur
 puis cliquez sur Renommer.
puis cliquez sur Renommer.
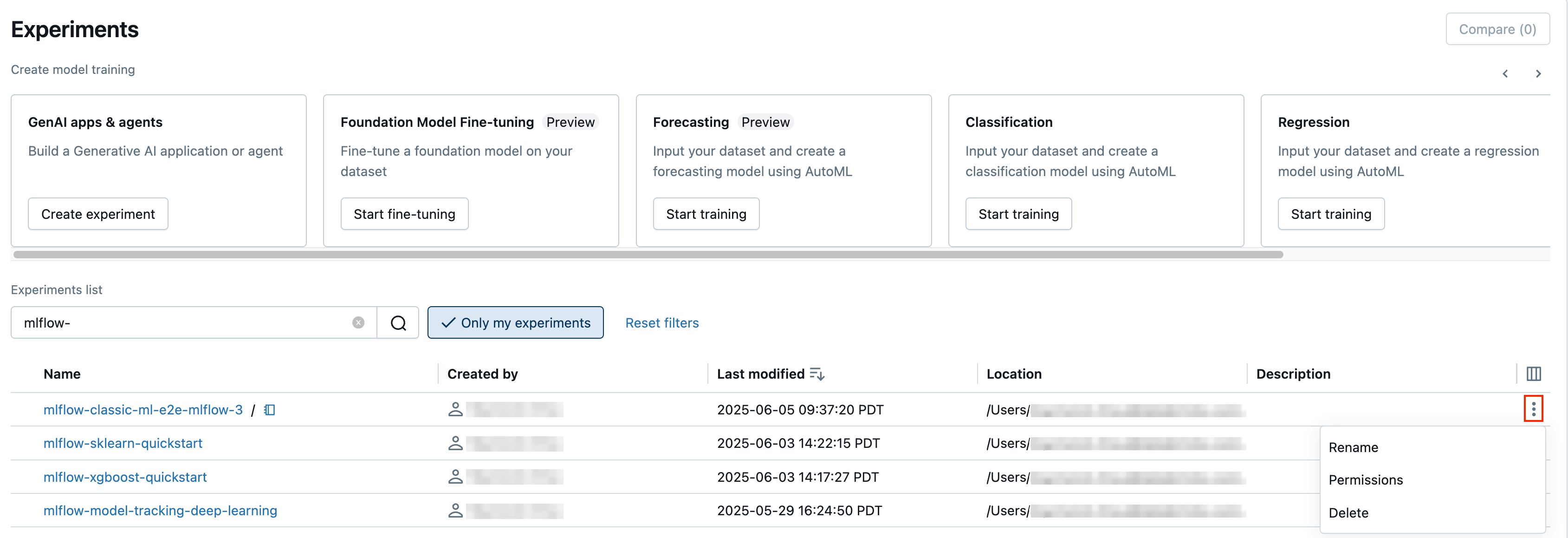
- Dans la page des détails de l’expérience, cliquez sur à côté de des autorisations, puis cliquez sur Renommer.

Vous pouvez renommer une expérience d’espace de travail à partir de l’espace de travail. Cliquez avec le bouton droit sur le nom de l’expérience, puis cliquez sur Renommer.
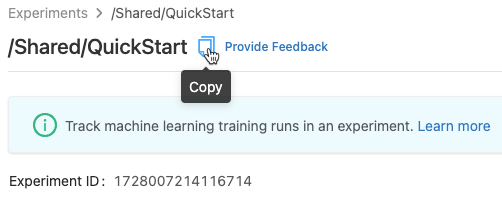
Obtenir l’identifiant (ID) de l'expérience et le chemin vers l'expérience
Dans la page des détails de l’expérience, vous pouvez obtenir le chemin d’accès à une expérience de bloc-notes en cliquant sur l’icône d’informations ![]() à droite du nom de l’expérience. Une note contextuelle s’affiche qui affiche le chemin d’accès à l’expérience, l’ID de l’expérience et l’emplacement de l’artefact. Vous pouvez utiliser l’ID d’expérience dans la commande MLflow
à droite du nom de l’expérience. Une note contextuelle s’affiche qui affiche le chemin d’accès à l’expérience, l’ID de l’expérience et l’emplacement de l’artefact. Vous pouvez utiliser l’ID d’expérience dans la commande MLflow set_experiment pour définir l’expérience MLflow active.

À partir d’un bloc-notes, vous pouvez copier le chemin complet de l’expérience en cliquant sur ![]() Dans la barre latérale de l’expérience du bloc-notes.
Dans la barre latérale de l’expérience du bloc-notes.
Supprimer une expérience de notebook
Les expériences des Notebooks font partie du bloc-notes et ne peuvent pas être supprimées séparément. Lorsque vous supprimez un bloc-notes, l’expérience du bloc-notes associée est supprimée. Lorsque vous supprimez une expérience de bloc-notes en utilisant l’interface utilisateur, le bloc-notes est également supprimé.
Pour supprimer des expériences de notebook à l’aide de l’API, utilisez l’API Espace de travail pour vous assurer que le bloc-notes et l’expérience sont supprimés de l’espace de travail.
Supprimer une expérience d'espace de travail ou de carnet
Vous pouvez supprimer une expérience que vous possédez à partir de la page des expériences ou de la page de détails de l’expérience.
Important
Lorsque vous supprimez une expérience de bloc-notes, le bloc-notes est également supprimé.
- Dans la page Expériences, cliquez sur dans la colonne la plus à droite, puis cliquez sur Supprimer.
- Dans la page des détails de l’expérience, cliquez sur à côté de des autorisations, puis cliquez sur Supprimer.
Vous pouvez supprimer une expérience d’espace de travail à partir de l’espace de travail. Faites un clic droit sur le nom de l'expérience, puis cliquez sur Déplacer vers la Corbeille.
Modifier les autorisations d’une expérience
Pour modifier les autorisations d’une expérience à partir de la page de détails de l’expérience , cliquez sur Autorisations.

Vous pouvez modifier les autorisations d’une expérience que vous possédez à partir de la page Expériences . Cliquez sur l'icône du ![]() dans la colonne la plus à droite, puis cliquez sur Autorisations.
dans la colonne la plus à droite, puis cliquez sur Autorisations.
Pour obtenir plus d’informations sur les niveaux d’autorisation des expériences, consultez ACL d’expérience MLflow.
Copier des expériences entre des espaces de travail
Pour migrer des expériences MLflow entre des espaces de travail, vous pouvez utiliser le projet open source MLflow Export-Import alimenté par la communauté.
Grâce à ces outils, vous pouvez :
- Partagez et collaborez avec d’autres scientifiques des données dans le même serveur de suivi ou un autre. Par exemple, vous pouvez cloner une expérience d’un autre utilisateur dans votre espace de travail.
- Copiez des expériences et exécutions MLflow de votre serveur de suivi local vers votre espace de travail Databricks.
- Sauvegardez les expériences et modèles stratégiques dans un autre espace de travail Databricks.