Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Important
La mise à l’échelle automatique Lakebase est disponible dans les régions suivantes : eastus, eastus2, centralus, southcentralus, westus, westus2, canadacentral, brazilsouth, northeurope, uksouth, westeurope, australiaeast, centralindia, southeastasia
La version Lakebase Autoscaling est la dernière de Lakebase, avec l'évolutivité automatique, la mise à l’échelle jusqu'à zéro, la création de branches et la restauration instantanée. Si vous êtes un utilisateur Lakebase Provisionné, consultez Lakebase Provisioned.
Lorsque vous créez un projet, Lakebase crée plusieurs rôles Postgres dans le projet :
- Rôle Postgres pour l’identité Azure Databricks du propriétaire du projet (par exemple,
user@databricks.com), qui possède la base de données par défautdatabricks_postgres - Un
databricks_superuserrôle administratif
Ces deux rôles sont visibles sous l’onglet Rôles et bases de données lorsque vous ouvrez votre projet pour la première fois.
La databricks_postgres base de données est créée pour vous permettre de vous connecter et d’essayer Lakebase immédiatement après la création du projet.
Plusieurs rôles gérés par le système sont également créés. Il s’agit de rôles internes utilisés par les services Azure Databricks pour la gestion, la supervision et les opérations de données.
Note
Les rôles Postgres contrôlent l’accès à la base de données (qui peut interroger des données). Pour les autorisations de projet (qui peuvent gérer l’infrastructure), consultez Autorisations de projet. Pour obtenir un didacticiel sur la configuration des deux, consultez Tutoriel : Accorder l’accès au projet et à la base de données à un nouvel utilisateur.
Consultez les rôles précréés et les rôles système.
Créer des rôles Postgres
Lakebase prend en charge deux types de rôles Postgres pour l’accès à la base de données :
-
Rôles OAuth pour les identités Azure Databricks : Créez-les à l’aide de l’interface utilisateur Lakebase, de l’extension
databricks_authavec SQL ou du Kit de développement logiciel (SDK) Python et de l’API REST. Permet aux identités Azure Databricks (utilisateurs, principaux de service et groupes) de se connecter à l’aide de jetons OAuth. - Rôles de mot de passe Postgres natifs : Créez-les à l’aide de l’interface utilisateur Lakebase, de SQL ou du Kit de développement logiciel (SDK) Python et de l’API REST. Utilisez n’importe quel nom de rôle valide avec l’authentification par mot de passe.
Pour obtenir des conseils sur le choix du type de rôle à utiliser, consultez vue d’ensemble de l’authentification. Chacun est conçu pour différents cas d’usage.
Créer un rôle OAuth pour les identités Azure Databricks
Pour autoriser les identités Azure Databricks (utilisateurs, principaux de service ou groupes) à se connecter à l’aide de jetons OAuth, créez un rôle OAuth à l’aide de l’interface utilisateur Lakebase, de l’extension databricks_auth avec SQL ou de l’API REST.
Pour obtenir des instructions détaillées sur l’obtention de jetons OAuth, consultez Obtenir un jeton OAuth dans un flux utilisateur à machine et obtenir un jeton OAuth dans un flux d’ordinateur à machine.
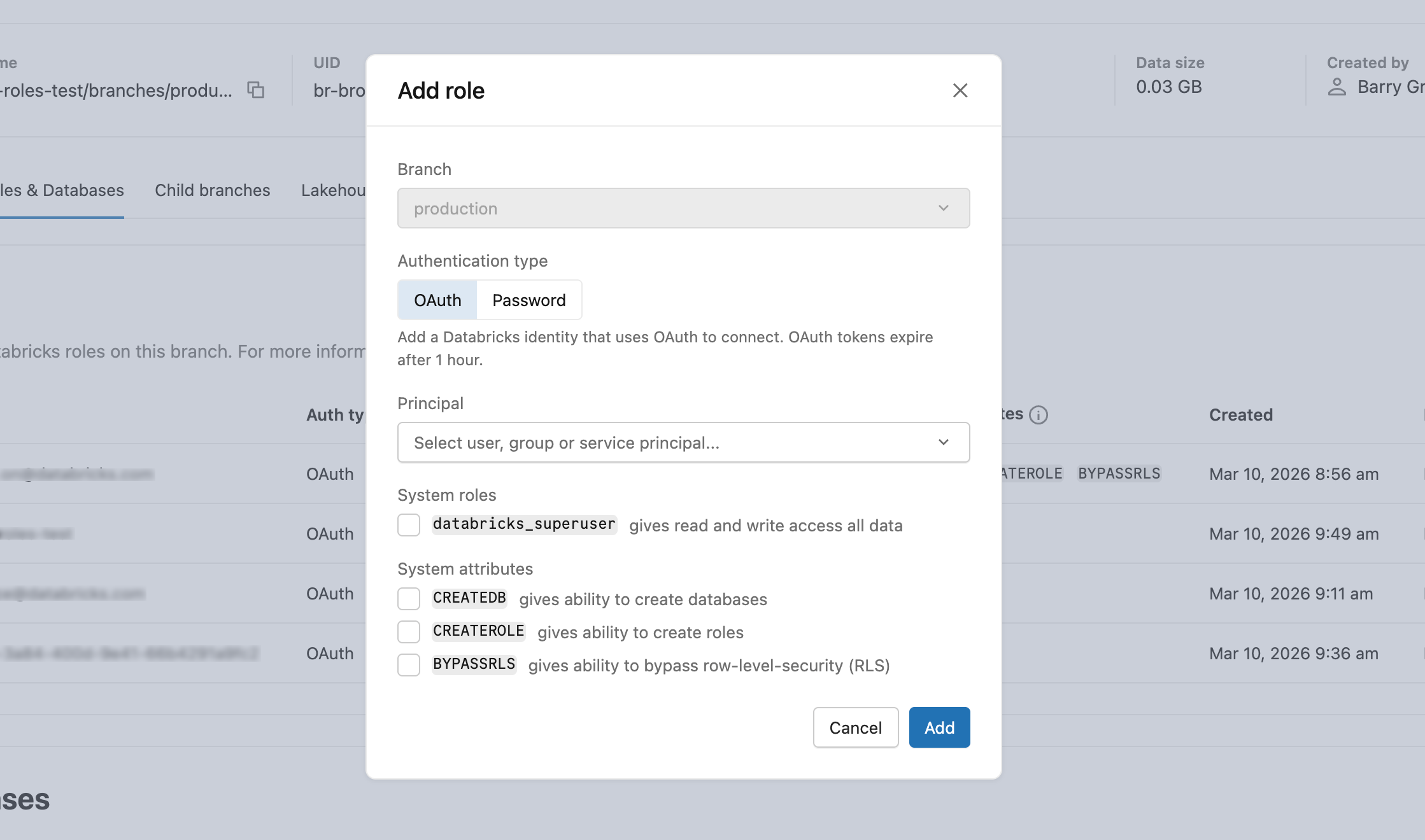
IU
- Dans Rôles & Bases de données>Ajouter un rôle>OAuth , sélectionnez l’utilisateur, le principal de service ou le groupe pour accorder l’accès à la base de données.
- Après avoir créé le rôle, accordez les privilèges de base de données appropriés. Découvrez comment : gérer les autorisations
SQL
Configuration requise :
- Vous devez disposer des autorisations
CREATEetCREATE ROLEsur la base de données - Vous devez être authentifié en tant qu’identité Azure Databricks avec un jeton OAuth valide
- Les sessions authentifiées Postgres natives ne peuvent pas créer de rôles OAuth
Créez l’extension
databricks_auth. Chaque base de données Postgres doit avoir sa propre extension.CREATE EXTENSION IF NOT EXISTS databricks_auth;Utilisez la
databricks_create_rolefonction pour créer un rôle Postgres pour l’identité Azure Databricks :SELECT databricks_create_role('identity_name', 'identity_type');Pour un utilisateur Azure Databricks :
SELECT databricks_create_role('myuser@databricks.com', 'USER');Pour un service principal Azure Databricks :
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');Pour un groupe Azure Databricks :
SELECT databricks_create_role('My Group Name', 'GROUP');Le nom du groupe respecte la casse et doit correspondre exactement comme il apparaît dans votre espace de travail Azure Databricks. Lorsque vous créez un rôle Postgres pour un groupe, tout membre direct ou indirect (utilisateur ou principal de service) de ce groupe Databricks peut s’authentifier auprès de Postgres en tant que rôle de groupe à l’aide de son jeton OAuth individuel. Cela vous permet de gérer les autorisations au niveau du groupe dans Postgres au lieu de conserver des autorisations pour des utilisateurs individuels.
Accordez des autorisations de base de données au rôle nouvellement créé.
La fonction databricks_create_role() crée un rôle Postgres avec uniquement les permissions LOGIN. Après avoir créé le rôle, vous devez accorder les privilèges et autorisations de base de données appropriés sur les bases de données, schémas ou tables spécifiques auxquels l’utilisateur doit accéder. Découvrez comment : gérer les autorisations
Kit de développement logiciel (SDK) Python
Défini identity_type sur USER, SERVICE_PRINCIPALou GROUP. Définissez postgres_role l’adresse e-mail de l’identité, l’ID d’application (UUID) ou le nom d’affichage du groupe respectivement. Cette valeur devient le nom du rôle Postgres que vous utilisez dans les chaînes de connexion et les instructions GRANT.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
identity_type="USER",
postgres_role="user@example.com"
)
)
)
role = operation.wait()
print(f"Created role: {role.name}")
Après avoir créé le rôle, accordez les privilèges de base de données appropriés. Découvrez comment : gérer les autorisations
friser
Défini identity_type sur USER, SERVICE_PRINCIPALou GROUP. Définissez postgres_role l’adresse e-mail de l’identité, l’ID d’application (UUID) ou le nom d’affichage du groupe respectivement. Cette valeur devient le nom du rôle Postgres et est ce que vous utilisez dans les chaînes de connexion et dans les instructions GRANT.
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"identity_type": "USER",
"postgres_role": "user@example.com"
}
}' | jq
Le point de terminaison retourne une opération de longue durée. Sondez jusqu’à ce que done soit true, puis utilisez le champ name du rôle pour les appels API suivants. Consultez les opérations de longue durée.
Après avoir créé le rôle, accordez les privilèges de base de données appropriés. Découvrez comment : gérer les autorisations
Authentification basée sur un groupe
Lorsque vous créez un rôle Postgres pour un groupe Azure Databricks, vous activez l’authentification basée sur un groupe. Cela permet à tout membre du groupe Azure Databricks de s’authentifier auprès de Postgres à l’aide du rôle du groupe, ce qui simplifie la gestion des autorisations.
Fonctionnement :
- Créez un rôle Postgres pour un groupe Databricks.
- Accordez des autorisations de base de données au rôle de groupe dans Postgres. Consultez Gérer les autorisations.
- Tout membre direct ou indirect (utilisateur ou principal de service) du groupe Databricks peut se connecter à Postgres à l’aide de son jeton OAuth individuel.
- Lors de la connexion, le membre s’authentifie en tant que rôle de groupe et hérite de toutes les autorisations accordées à ce rôle.
Flux d’authentification :
Lorsqu’un membre du groupe se connecte, il spécifie le nom du rôle Postgres du groupe comme nom d’utilisateur et son propre jeton OAuth comme mot de passe :
export PGPASSWORD='<OAuth token of a group member>'
export GROUP_ROLE_NAME='<pg-case-sensitive-group-role-name>'
psql -h $HOSTNAME -p 5432 -d databricks_postgres -U $GROUP_ROLE_NAME
Considérations importantes :
- Validation de l’appartenance au groupe : L’appartenance au groupe est validée uniquement au moment de l’authentification. Si un membre est supprimé du groupe Azure Databricks après avoir établi une connexion, la connexion reste active. Les nouvelles tentatives de connexion des membres supprimés sont rejetées.
- Étendue de l’espace de travail : Seuls les groupes affectés au même espace de travail Azure Databricks que le projet sont pris en charge pour l’authentification basée sur un groupe. Pour savoir comment affecter des groupes à un espace de travail, consultez Gérer les groupes.
-
Sensibilité de la casse : Le nom du groupe utilisé dans
databricks_create_role()doit correspondre exactement au nom du groupe tel qu’il apparaît dans votre espace de travail Azure Databricks, y compris le cas. - Gestion des autorisations : La gestion des autorisations au niveau du groupe dans Postgres est plus efficace que la gestion des autorisations utilisateur individuelles. Lorsque vous accordez des autorisations au rôle de groupe, tous les membres actuels et futurs du groupe héritent automatiquement de ces autorisations.
- Changement de nom d’identité : Si le nom d’affichage de messagerie ou de groupe d’un utilisateur change dans Azure Databricks, l’authentification et les subventions de base de données existantes s’interrompent. Supprimez l’ancien rôle, créez-en un avec le nom mis à jour et mettez à jour les chaînes de connexion et les octrois.
Note
Les noms de rôles ne peuvent pas dépasser 63 caractères et certains noms ne sont pas autorisés. En savoir plus : Gérer les rôles
Créer un rôle de mot de passe Postgres natif
Les connexions de mot de passe peuvent être désactivées au niveau du projet ou du calcul. Consultez Bloquer les connexions de mot de passe.
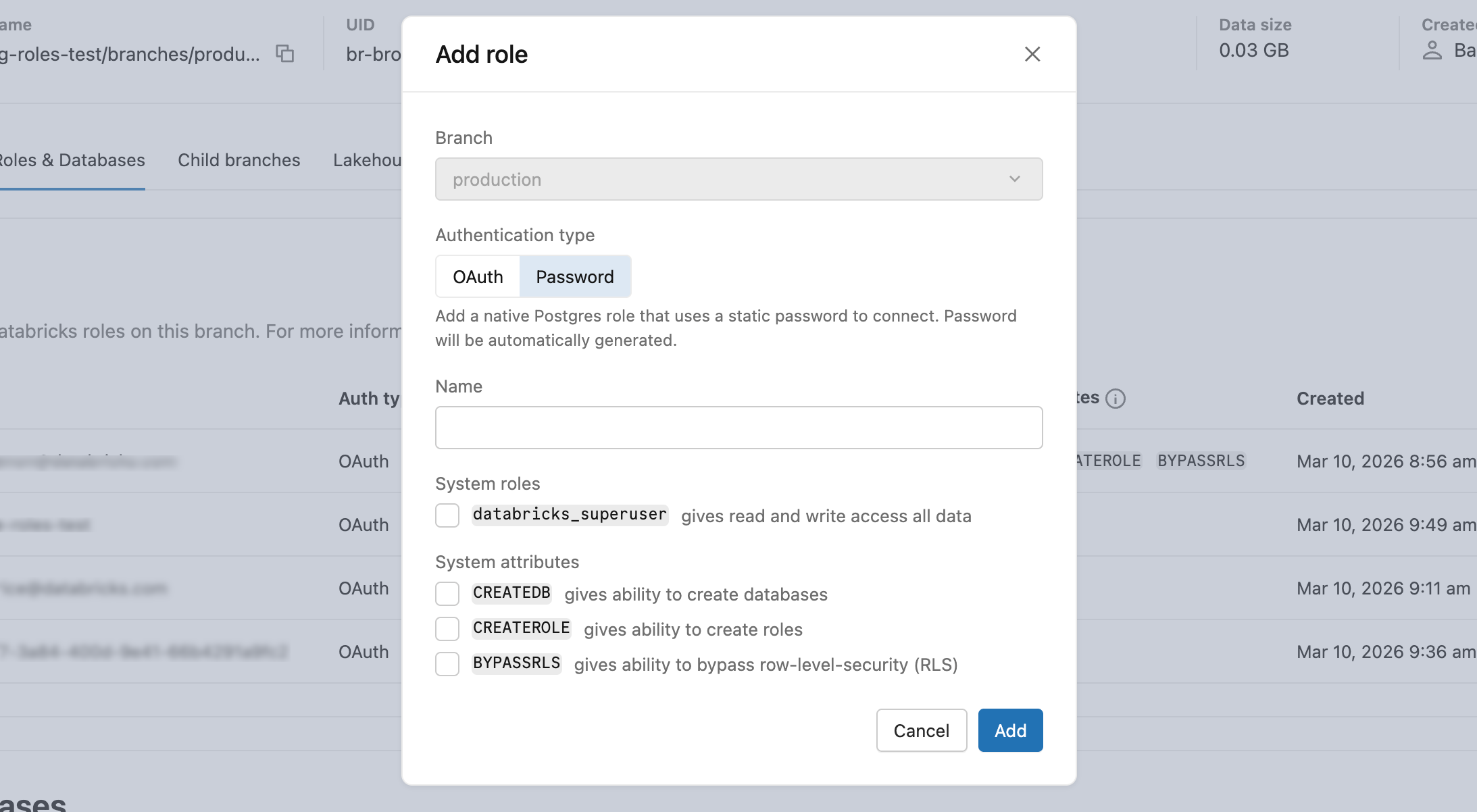
IU
- Dans l'onglet
Rôles & Bases de données Ajouter un rôle , entrez un nom de rôle et, éventuellement, attribuez des privilèges ou des attributs système (, , ). - Copiez le mot de passe généré et fournissez-le en toute sécurité à l’utilisateur. Il n’est pas montré à nouveau.
SQL
CREATE ROLE role_name WITH LOGIN PASSWORD 'your_secure_password';
Le mot de passe doit comporter au moins 12 caractères avec un mélange de caractères minuscules, majuscules, nombre et symboles. Les mots de passe définis par l’utilisateur sont validés au moment de la création pour garantir l’entropie 60 bits.
Kit de développement logiciel (SDK) Python
Omettez identity_type pour créer un rôle associé au mot de passe. L’API retourne un mot de passe généré dans la réponse.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
postgres_role="my-app-role"
)
)
)
role = operation.wait()
print(f"Created role: {role.name}")
friser
Omettez identity_type pour créer un rôle lié au mot de passe. Le point de terminaison retourne une opération de longue durée. Interrogez jusqu'à ce que done soit true.
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"postgres_role": "my-app-role"
}
}' | jq
Afficher les rôles Postgres
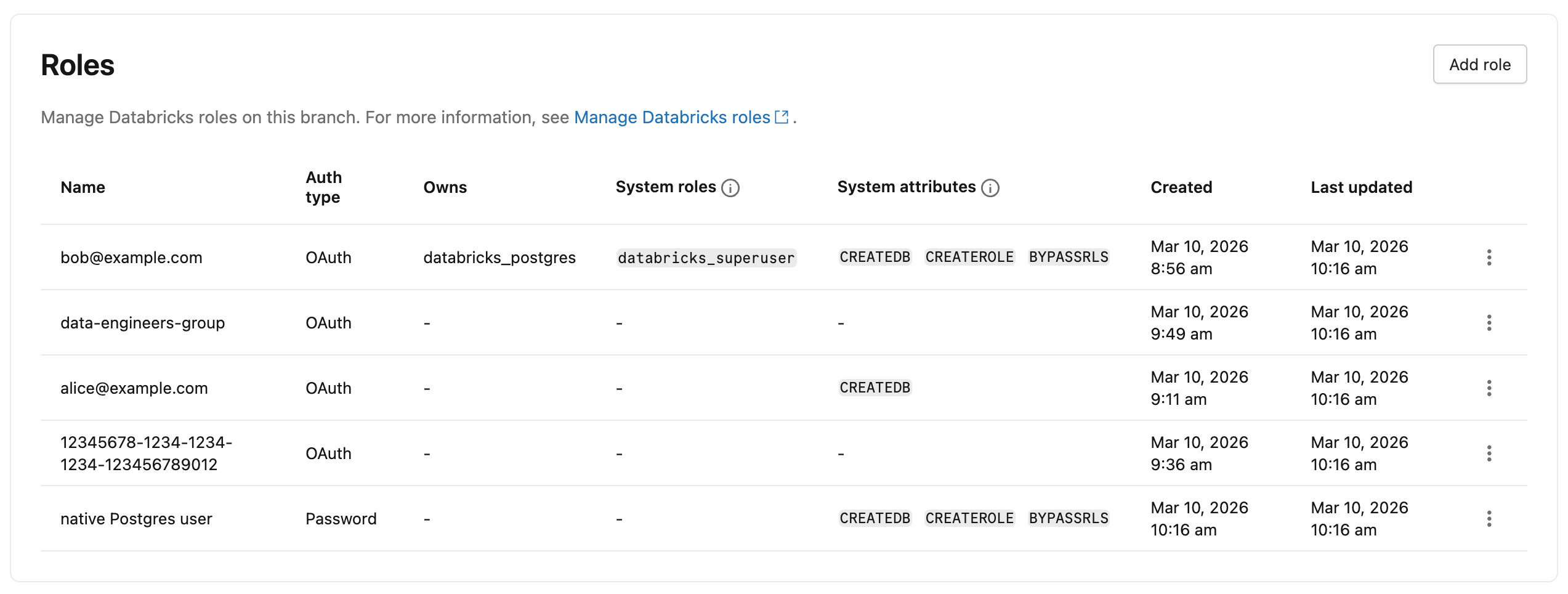
IU
Pour afficher tous les rôles Postgres dans votre projet, accédez à l’onglet Rôles et bases de données de votre branche dans l’application Lakebase. Tous les rôles créés dans la branche, à l’exception des rôles système, sont répertoriés. La colonne Type d’authentification indique si chaque rôle utilise l’authentification OAuth ou Password.
PostgreSQL
Affichez tous les rôles avec \du la commande :
Vous pouvez afficher tous les rôles Postgres, y compris les rôles système, à l’aide de la \du méta-commande à partir de n’importe quel client Postgres (par exemple psql) ou de l’éditeur SQL Lakebase :
\du
List of roles
Role name | Attributes
-----------------------------+------------------------------------------------------------
cloud_admin | Superuser, Create role, Create DB, Replication, Bypass RLS
my.user@databricks.com | Create role, Create DB, Bypass RLS
databricks_control_plane | Superuser
databricks_gateway |
databricks_monitor |
databricks_reader_12345 | Create role, Create DB, Replication, Bypass RLS
databricks_replicator | Replication
databricks_superuser | Create role, Create DB, Cannot login, Bypass RLS
databricks_writer_12345 | Create role, Create DB, Replication, Bypass RLS
Kit de développement logiciel (SDK) Python
Répertorier tous les rôles :
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
roles = w.postgres.list_roles(parent="projects/my-project/branches/production")
for role in roles:
print(f"{role.status.postgres_role} ({role.status.identity_type or 'PASSWORD'}): {role.name}")
Obtenez un rôle spécifique :
role = w.postgres.get_role(
name="projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx"
)
print(role)
friser
Répertorier tous les rôles :
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Obtenez un rôle spécifique :
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
La réponse inclut le champ (par exemple, name) requis pour les rol-xxxx-xxxxxxxxxx appels de mise à jour et de suppression.
Mettre à jour un rôle
Pour mettre à jour les attributs d’un rôle dans l’interface utilisateur, sélectionnez Modifier le rôle dans le menu rôle de l’onglet Rôles et bases de données .
Utilisez l’API pour mettre à jour les rôles ou attributs système d’un rôle. Utilisez update_mask comme paramètre de requête pour spécifier les champs à modifier ; seuls les champs masqués sont modifiés.
Note
Pour obtenir le nom de ressource d’un rôle à utiliser dans les appels de mise à jour et de suppression, utilisez le point de terminaison list roles. Les noms de ressources de rôle utilisent un identificateur généré par le système (par exemple, rol-xxxx-xxxxxxxxxx), et non la valeur fournie lors de la postgres_role création.
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx?update_mask=spec.membership_roles%2Cspec.attributes.createdb" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx",
"spec": {
"membership_roles": ["DATABRICKS_SUPERUSER"],
"attributes": { "createdb": true }
}
}' | jq
Pour supprimer databricks_superuser, passez un tableau vide : "membership_roles": [].
Supprimer un rôle Postgres
Vous pouvez supprimer les rôles databricks basés sur les identités et les rôles de mot de passe Postgres natifs.
IU
La suppression d’un rôle est une action permanente qui ne peut pas être annulée. Pour supprimer un rôle propriétaire d’une base de données, vous devez spécifier le rôle auquel réaffecter les objets détenus. Sinon, la base de données doit être supprimée manuellement avant de supprimer le rôle propriétaire de la base de données.
Pour supprimer n’importe quel rôle Postgres à l’aide de l’interface utilisateur :
- Accédez à l’onglet Rôles et bases de données de votre branche dans l’application Lakebase.
- Sélectionnez Supprimer le rôle dans le menu rôle et confirmez la suppression.
PostgreSQL
Vous pouvez supprimer n’importe quel rôle Postgres à l’aide de commandes Postgres standard. Pour plus d’informations, consultez la documentation PostgreSQL sur la suppression de rôles.
Supprimez un rôle :
DROP ROLE role_name;
Une fois qu’un rôle basé sur l’identité Azure Databricks est supprimé, cette identité ne peut plus s’authentifier auprès de Postgres à l’aide de jetons OAuth jusqu’à ce qu’un nouveau rôle soit créé.
Kit de développement logiciel (SDK) Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
operation = w.postgres.delete_role(
name="projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx"
)
operation.wait()
friser
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles/rol-xxxx-xxxxxxxxxx" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Rôles précréés
Une fois qu’un projet est créé, Azure Databricks crée automatiquement des rôles Postgres pour l’administration de projet et la prise en main.
| Role | Descriptif | Privilèges hérités |
|---|---|---|
<project_owner_role> |
Identité Azure Databricks du créateur de projet (par exemple). my.user@databricks.com Ce rôle possède la base de données par défaut databricks_postgres et peut se connecter et administrer le projet. |
Membre de databricks_superuser |
databricks_superuser |
Rôle d’administration interne. Permet de configurer et de gérer l’accès dans le projet. Ce rôle reçoit de larges privilèges. | Hérite de pg_read_all_data, pg_write_all_dataet pg_monitor. |
En savoir plus sur les fonctionnalités et privilèges spécifiques de ces rôles : fonctionnalités de rôle précréé
Rôles système créés par Azure Databricks
Azure Databricks crée les rôles système suivants requis pour les services internes. Vous pouvez afficher ces rôles en émettant une \du commande à partir de psql ou dans l’éditeur SQL Lakebase.
| Role | Objectif |
|---|---|
cloud_admin |
Rôle superutilisateur utilisé pour la gestion de l’infrastructure cloud |
databricks_control_plane |
Rôle superutilisateur utilisé par les composants Databricks internes pour les opérations de gestion |
databricks_monitor |
Utilisé par les services de collecte de métriques internes |
databricks_replicator |
Utilisé pour les opérations de réplication de base de données |
databricks_writer_<dbid> |
Rôle par base de données utilisé pour créer et gérer des tables synchronisées |
databricks_reader_<dbid> |
Rôle par base de données utilisé pour lire les tables inscrites dans le catalogue Unity |
databricks_gateway |
Utilisé pour les connexions internes pour les services de service de données managées |
Pour savoir comment fonctionnent les rôles, les privilèges et les appartenances aux rôles dans Postgres, utilisez les ressources suivantes dans la documentation Postgres :