Création de systèmes avancés de génération augmentée de récupération
L’article précédent a abordé deux options pour créer une application « discuter sur vos données », l’un des principaux cas d’usage pour l’IA générative dans les entreprises :
- Récupération de génération augmentée (RAG) qui complète l’apprentissage du modèle de langage volumineux (LLM) avec une base de données d’articles pouvant être récupérés en fonction de la similarité des requêtes des utilisateurs et transmis au LLM pour l’achèvement.
- Réglage précis, qui étend l’entraînement du LLM pour en savoir plus sur le domaine du problème.
L’article précédent a également discuté de l’utilisation de chaque approche, du pro et du con de chaque approche et de plusieurs autres considérations.
Cet article explore RAG plus en détail, en particulier, tout le travail nécessaire à la création d’une solution prête pour la production.
L’article précédent a décrit les étapes ou les phases de RAG à l’aide du diagramme suivant.
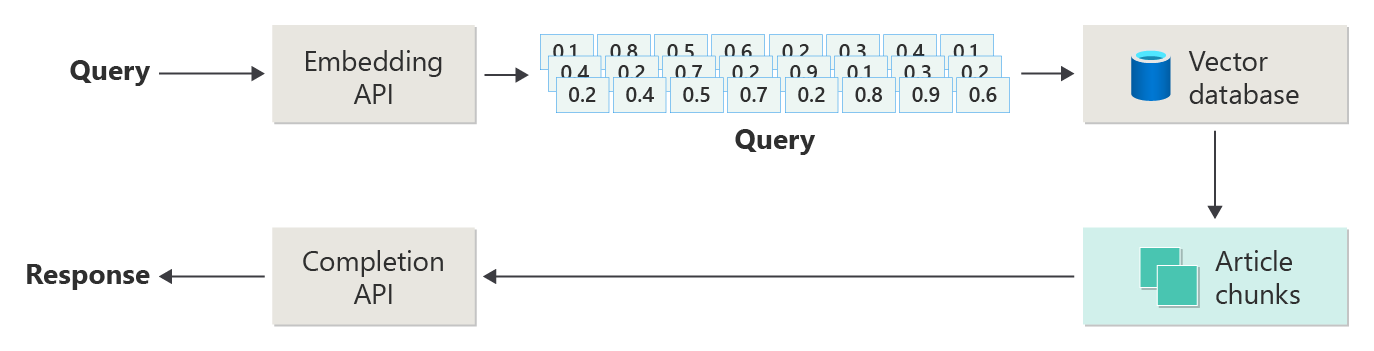
Cette représentation a été appelée « RAG naïve » et est un moyen utile de comprendre d’abord les mécanismes, les rôles et les responsabilités nécessaires pour implémenter un système de conversation basé sur RAG.
Toutefois, une implémentation plus réelle a de nombreuses étapes de pré-traitement et de post-traitement pour préparer les articles, les requêtes et les réponses à utiliser. Le diagramme suivant est une représentation plus réaliste d’un RAG, parfois appelé « RAG avancé ».

Cet article fournit un cadre conceptuel permettant de comprendre les types de problèmes de pré-traitement et de post-traitement dans un système de conversation basé sur RAG réel, organisé comme suit :
- Phase d’ingestion
- Phase de pipeline d’inférence
- Phase d’évaluation
En guise de vue d’ensemble conceptuelle, les mots clés et les idées sont fournis en tant que contexte et point de départ pour une exploration et une recherche plus approfondies.
Ingestion
L’ingestion concerne principalement le stockage des documents de votre organisation de telle sorte qu’ils puissent être facilement récupérés pour répondre à la question d’un utilisateur. Le défi est de s’assurer que les parties des documents qui correspondent le mieux à la requête de l’utilisateur sont situées et utilisées pendant l’inférence. La correspondance est effectuée principalement par le biais d’incorporations vectorisées et d’une recherche de similarité cosinus. Toutefois, elle est facilitée par la compréhension de la nature du contenu (modèles, formulaires, etc.) et de la stratégie de l’organisation des données (structure des données lorsqu’elles sont stockées dans la base de données vectorielle).
À cette fin, les développeurs doivent prendre en compte les éléments suivants :
- Prétraitement et extraction du contenu
- Stratégie de segmentation
- Organisation de segmentation
- Stratégie de mise à jour
Prétraitement et extraction du contenu
Le contenu propre et précis est l’une des meilleures façons d’améliorer la qualité globale d’un système de conversation basé sur RAG. Pour ce faire, les développeurs doivent commencer par analyser la forme et la forme des documents à indexer. Les documents sont-ils conformes aux modèles de contenu spécifiés comme la documentation ? Si ce n’est pas le cas, quels types de questions les documents peuvent-ils répondre ?
Au minimum, les développeurs doivent créer des étapes dans le pipeline d’ingestion pour :
- Normaliser les formats de texte
- Gérer des caractères spéciaux
- Supprimer du contenu non lié et obsolète
- Compte du contenu versionné
- Compte de l’expérience de contenu (onglets, images, tables)
- Extraire les métadonnées
Certaines de ces informations (comme les métadonnées, par exemple) peuvent être utiles pour être conservées avec le document de la base de données vectorielle à utiliser pendant le processus d’extraction et d’évaluation dans le pipeline d’inférence, ou combinées avec le bloc de texte pour persuader l’incorporation du vecteur du bloc.
Stratégie de segmentation
Les développeurs doivent décider comment décomposer un document plus long en blocs plus petits. Cela peut améliorer la pertinence du contenu supplémentaire envoyé dans le LLM pour répondre avec précision à la requête de l’utilisateur. En outre, les développeurs doivent prendre en compte la façon d’utiliser les blocs lors de la récupération. Il s’agit d’un domaine où les concepteurs de systèmes doivent effectuer des recherches sur les techniques utilisées dans l’industrie et effectuer certaines expérimentations, même les tester dans une capacité limitée dans leur organisation.
Les développeurs doivent prendre en compte les éléments suivants :
- Optimisation de la taille de bloc : déterminez la taille idéale du bloc et comment désigner un bloc. Par section ? Par paragraphe ? Par phrase ?
- Segments de fenêtre qui se chevauchent et glissants : déterminez comment diviser le contenu en blocs discrets. Ou les blocs se chevauchent-ils ? Ou les deux (fenêtre glissante) ?
- Small2Big - Lors de la segmentation à un niveau granulaire comme une seule phrase, le contenu sera-t-il organisé de telle façon qu’il est facile de trouver les phrases voisines ou de contenir des paragraphes ? (Voir « Organisation de segmentation »). La récupération de ces informations supplémentaires et la fourniture de ces informations au LLM peuvent fournir davantage de contexte lors de la réponse à la requête de l’utilisateur.
Organisation de segmentation
Dans un système RAG, l’organisation des données dans la base de données vectorielle est essentielle pour une récupération efficace des informations pertinentes afin d’augmenter le processus de génération. Voici les types de stratégies d’indexation et de récupération que les développeurs peuvent prendre en compte :
- Index hiérarchiques : cette approche implique la création de plusieurs couches d’index, où un index de niveau supérieur (index récapitulative) réduit rapidement l’espace de recherche à un sous-ensemble de blocs potentiellement pertinents, et un index de deuxième niveau (index de blocs) fournit des pointeurs plus détaillés vers les données réelles. Cette méthode peut accélérer considérablement le processus de récupération, car elle réduit le nombre d’entrées à analyser dans l’index détaillé en filtrant d’abord l’index de synthèse.
- Index spécialisés : des index spécialisés comme des bases de données relationnelles ou basées sur des graphiques peuvent être utilisés en fonction de la nature des données et des relations entre les blocs. Par exemple :
- Les index basés sur des graphiques sont utiles lorsque les blocs ont des informations ou des relations interconnectées qui peuvent améliorer la récupération, telles que les réseaux de citations ou les graphiques de connaissances.
- Les bases de données relationnelles peuvent être efficaces si les blocs sont structurés dans un format tabulaire où les requêtes SQL peuvent être utilisées pour filtrer et récupérer des données en fonction d’attributs ou de relations spécifiques.
- Index hybrides : une approche hybride combine plusieurs stratégies d’indexation pour tirer parti des forces de chacun d’eux. Par exemple, les développeurs peuvent utiliser un index hiérarchique pour le filtrage initial et un index basé sur un graphique pour explorer les relations entre les blocs dynamiquement pendant la récupération.
Optimisation de l’alignement
Pour améliorer la pertinence et la précision des blocs récupérés, il peut être utile de les aligner plus étroitement avec les types de questions ou de requêtes qu’ils sont destinés à répondre. Une stratégie pour y parvenir consiste à générer et à insérer une question hypothétique pour chaque segment qui représente la question à laquelle le segment est le mieux adapté pour répondre. Cela permet de plusieurs façons :
- Amélioration de la correspondance : lors de la récupération, le système peut comparer la requête entrante à ces questions hypothétiques pour trouver la meilleure correspondance, ce qui améliore la pertinence des blocs récupérés.
- Données d’apprentissage pour les modèles Machine Learning : ces paires de questions et de blocs peuvent servir de données d’apprentissage pour améliorer les modèles Machine Learning sous-jacents au système RAG, ce qui lui permet d’apprendre quels types de questions sont les mieux répondus par les segments.
- Gestion des requêtes directes : si une requête utilisateur réelle correspond étroitement à une question hypothétique, le système peut rapidement récupérer et utiliser le bloc correspondant, accélérant ainsi le temps de réponse.
La question hypothétique de chaque segment agit comme un type d'« étiquette » qui guide l’algorithme de récupération, ce qui le rend plus concentré et contextuel. Cela est utile dans les scénarios où les segments couvrent un large éventail de rubriques ou de types d’informations.
Stratégies de mise à jour
Si votre organisation doit indexer des documents fréquemment mis à jour, il est essentiel de conserver un corpus mis à jour pour garantir que le composant retriever (la logique dans le système responsable de l’exécution de la requête sur la base de données vectorielle et le renvoi des résultats) peut accéder aux informations les plus actuelles. Voici quelques stratégies pour mettre à jour la base de données vectorielle dans de tels systèmes :
- Mises à jour incrémentielles :
- Intervalles réguliers : planifiez des mises à jour à intervalles réguliers (par exemple, quotidiennes, hebdomadaires) en fonction de la fréquence des modifications de document. Cette méthode garantit que la base de données est régulièrement actualisée.
- Mises à jour basées sur les déclencheurs : implémentez un système où les mises à jour déclenchent une réindexation. Par exemple, toute modification ou ajout d’un document peut lancer automatiquement une réindexation des sections concernées.
- Mises à jour partielles :
- Réindexation sélective : au lieu de réindexer l’ensemble de la base de données, mettez à jour sélectivement uniquement les parties du corpus qui ont changé. Cela peut être plus efficace que l’indexation complète, en particulier pour les jeux de données volumineux.
- Encodage delta : stockez uniquement les différences entre les documents existants et leurs versions mises à jour. Cette approche réduit la charge de traitement des données en évitant la nécessité de traiter des données inchangées.
- Contrôle de version :
- Capture instantanée : conservez les versions du corpus de documents à différents moments dans le temps. Cela permet au système de rétablir ou de faire référence aux versions précédentes si nécessaire et fournit un mécanisme de sauvegarde.
- Contrôle de version de document : utilisez un système de contrôle de version pour suivre systématiquement les modifications apportées aux documents. Cela permet de conserver l’historique des modifications et de simplifier le processus de mise à jour.
- Mises à jour en temps réel :
- Traitement de flux : utilisez les technologies de traitement de flux pour mettre à jour la base de données vectorielle en temps réel à mesure que des modifications sont apportées aux documents. Cela peut être essentiel pour les applications où la chronologie des informations est primordiale.
- Interrogation dynamique : au lieu de s’appuyer uniquement sur des vecteurs préindexés, implémentez un mécanisme permettant d’interroger les données actives pour les réponses les plus à jour, en combinant cela avec des résultats mis en cache pour une efficacité.
- Techniques d’optimisation :
- Traitement par lots : accumulez les modifications et traitez-les par lots pour optimiser l’utilisation des ressources et réduire la surcharge causée par les mises à jour fréquentes.
- Approches hybrides : combinez différentes stratégies, telles que l’utilisation de mises à jour incrémentielles pour les modifications mineures et la réindexation complète pour les mises à jour majeures ou les changements structurels dans le corpus de documents.
Le choix de la stratégie de mise à jour appropriée ou de la combinaison de stratégies dépend d’exigences spécifiques telles que la taille du corpus de documents, la fréquence des mises à jour, la nécessité de données en temps réel et la disponibilité des ressources. Chaque approche a ses compromis en termes de complexité, de coût et de latence de mise à jour. Il est donc essentiel d’évaluer ces facteurs en fonction des besoins spécifiques de l’application.
Pipeline d’inférence
Maintenant que les articles ont été segmentés, vectorisés et stockés dans une base de données vectorielle, le focus se transforme en défis à l’achèvement.
- La requête de l’utilisateur est-elle écrite de façon à obtenir les résultats du système que l’utilisateur recherche ?
- La requête de l’utilisateur viole-t-elle l’une de nos stratégies ?
- Comment réécrire la requête de l’utilisateur pour améliorer ses chances de trouver des correspondances les plus proches dans la base de données vectorielle ?
- Comment évaluer les résultats de la requête pour vous assurer que les blocs d’article sont alignés sur la requête ?
- Comment évaluer et modifier les résultats de la requête avant de les transmettre au LLM pour vous assurer que les détails les plus pertinents sont inclus dans l’achèvement du LLM ?
- Comment évaluer la réponse de LLM pour s’assurer que l’achèvement de LLM répond à la requête d’origine de l’utilisateur ?
- Comment assurer que la réponse de LLM est conforme à nos stratégies ?
Comme vous pouvez le voir, il existe de nombreuses tâches que les développeurs doivent prendre en compte, principalement sous la forme suivante :
- Prétraitement des entrées pour optimiser la probabilité d’obtenir les résultats souhaités
- Sorties post-traitement pour garantir les résultats souhaités
N’oubliez pas que tout le pipeline d’inférence s’exécute en temps réel. Bien qu’il n’existe aucun moyen approprié de concevoir la logique qui effectue les étapes de pré-traitement et de post-traitement, il est probable qu’il s’agit d’une combinaison de logique de programmation et d’appels supplémentaires à un LLM. L’un des points les plus importants à prendre en compte est le compromis entre la création du pipeline le plus précis et le plus conforme possible, ainsi que le coût et la latence nécessaires pour qu’il se produise.
Examinons chaque étape pour identifier des stratégies spécifiques.
Étapes de prétraitement des requêtes
Le prétraitement de la requête se produit immédiatement après que votre utilisateur a envoyé sa requête, comme illustré dans ce diagramme :

L’objectif de ces étapes est de s’assurer que l’utilisateur pose des questions dans l’étendue de notre système (et ne pas essayer de « jailbreaker » le système pour faire quelque chose de inattendu) et préparer la requête de l’utilisateur pour augmenter la probabilité qu’il trouve les meilleurs segments d’article possibles à l’aide de la similarité cosinus / « voisin le plus proche ».
Vérification de stratégie : cette étape peut impliquer une logique qui identifie, supprime, indicateurs ou rejette certains contenus. Certains exemples peuvent inclure la suppression d’informations d’identification personnelle, la suppression d’explétifs et l’identification des tentatives de « jailbreak ». Le jailbreaking fait référence aux méthodes que les utilisateurs peuvent employer pour contourner ou manipuler les directives intégrées en matière de sécurité, éthique ou opérationnelle du modèle.
Réécriture des requêtes : il peut s’agir de l’extension des acronymes et de la suppression de l’lang pour retranscrire la question pour la poser de manière plus abstraite pour extraire des concepts et des principes de haut niveau (« invite de retour en arrière »).
Une variante de l’invite de retours à pas est des incorporations de documents hypothétiques (HyDE) qui utilise le LLM pour répondre à la question de l’utilisateur, crée une incorporation pour cette réponse (l’incorporation hypothétique de document) et utilise cette incorporation pour effectuer une recherche sur la base de données vectorielle.
Sous-requêtes
Cette étape de traitement concerne la requête d’origine. Si la requête d’origine est longue et complexe, il peut être utile de la décomposer par programmation en plusieurs requêtes plus petites, puis de combiner toutes les réponses.
Par exemple, considérez une question liée aux découvertes scientifiques, en particulier dans le domaine de la physique. La requête de l’utilisateur peut être : « Qui a apporté des contributions plus significatives à la physique moderne, Albert Einstein ou Niels Bohr ? »
Cette requête peut être complexe à gérer directement, car les « contributions significatives » peuvent être subjectives et multiformes. Le décomposer en sous-requêtes peut le rendre plus gérable :
- Sous-requête 1 : « Quelles sont les principales contributions d’Albert Einstein à la physique moderne ? »
- Sous-requête 2 : « Quelles sont les principales contributions de Niels Bohr à la physique moderne ? »
Les résultats de ces sous-requêtes détaillent les principales théories et découvertes par chaque physicien. Par exemple :
- Pour Einstein, les contributions peuvent inclure la théorie de la relativité, l’effet photoélectrique et E=mc^2.
- Pour Bohr, les contributions peuvent inclure son modèle de l’atome d’hydrogène, son travail sur la mécanique quantique et son principe d’extrèmement.
Une fois ces contributions présentées, elles peuvent être évaluées pour déterminer :
- Sous-requête 3 : « Comment les théories d’Einstein ont-ils impacté le développement de la physique moderne ? »
- Sous-requête 4 : « Comment les théories de Bohr ont-ils eu un impact sur le développement de la physique moderne ? »
Ces sous-requêtes exploreraient l’influence du travail de chaque scientifique sur le terrain, comme la façon dont les théories d’Einstein ont conduit à des avancées dans la théorie cosmologie et quantique, et comment le travail de Bohr a contribué à la compréhension de la structure atomique et de la mécanique quantique.
La combinaison des résultats de ces sous-requêtes peut aider le modèle de langage à former une réponse plus complète concernant les personnes qui ont apporté des contributions plus importantes à la physique moderne, en fonction de l’étendue et de l’impact de leurs progrès théoriques. Cette méthode simplifie la requête complexe d’origine en traitant des composants plus spécifiques et accessibles, puis en synthétisant ces résultats en une réponse cohérente.
Routeur de requête
Il est possible que votre organisation décide de diviser son corpus de contenu en plusieurs magasins vectoriels ou systèmes de récupération entiers. Dans ce cas, les développeurs peuvent utiliser un routeur de requête, qui est un mécanisme qui détermine intelligemment quels index ou moteurs de récupération utiliser en fonction de la requête fournie. La fonction principale d’un routeur de requête consiste à optimiser la récupération des informations en sélectionnant la base de données ou l’index le plus approprié qui peut fournir les meilleures réponses à une requête spécifique.
Le routeur de requête fonctionne généralement à un point après la formulation de la requête par l’utilisateur, mais avant son envoi à tous les systèmes de récupération. Voici un flux de travail simplifié :
- Analyse des requêtes : le LLM ou un autre composant analyse la requête entrante pour comprendre son contenu, son contexte et le type d’informations probablement nécessaires.
- Sélection d’index : en fonction de l’analyse, le routeur de requête sélectionne un ou plusieurs index potentiellement disponibles. Chaque index peut être optimisé pour différents types de données ou de requêtes, par exemple, certains peuvent être plus adaptés aux requêtes factuelles, tandis que d’autres peuvent exceller dans la fourniture d’opinions ou de contenu subjectif.
- Répartition des requêtes : la requête est ensuite distribuée à l’index sélectionné.
- Agrégation des résultats : les réponses des index sélectionnés sont récupérées et éventuellement agrégées ou traitées pour former une réponse complète.
- Génération de réponse : la dernière étape consiste à générer une réponse cohérente basée sur les informations récupérées, éventuellement en intégrant ou synthétisant du contenu à partir de plusieurs sources.
Votre organisation peut utiliser plusieurs moteurs de récupération ou index pour les cas d’usage suivants :
- Spécialisation de type de données : certains index peuvent se spécialiser dans des articles d’actualités, d’autres dans des articles universitaires, et encore d’autres dans du contenu web général ou des bases de données spécifiques comme celles pour des informations médicales ou juridiques.
- Optimisation du type de requête : certains index peuvent être optimisés pour des recherches factuelles rapides (par exemple, des dates, des événements), tandis que d’autres peuvent être mieux pour des tâches de raisonnement complexes ou des requêtes nécessitant une connaissance approfondie du domaine.
- Différences algorithmiques : différents algorithmes de récupération peuvent être utilisés dans différents moteurs, tels que les recherches de similarité basées sur des vecteurs, les recherches basées sur des mots clés traditionnelles ou des modèles de compréhension sémantique plus avancés.
Imaginez un système basé sur RAG utilisé dans un contexte de conseil médical. Le système a accès à plusieurs index :
- Un index de document de recherche médicale optimisé pour des explications détaillées et techniques.
- Index d’étude de cas clinique qui fournit des exemples réels de symptômes et de traitements.
- Index d’informations générales sur l’intégrité pour les requêtes de base et les informations sur l’intégrité publique.
Si un utilisateur pose une question technique sur les effets biochimiques d’un nouveau médicament, le routeur de requête peut hiérarchiser l’index du document de recherche médicale en raison de sa profondeur et de son focus technique. Pour une question sur les symptômes typiques d’une maladie courante, cependant, l’indice général de santé peut être choisi pour son contenu large et facile à comprendre.
Étapes de traitement post-récupération
Le traitement post-récupération se produit après que le composant retriever récupère les blocs de contenu pertinents de la base de données vectorielle, comme illustré dans le diagramme :

Avec les blocs de contenu candidats récupérés, les étapes suivantes sont de vérifier que les blocs d’article seront utiles lors de l’augmentation de l’invite LLM, puis commencent à préparer l’invite à être présentés au LLM.
Les développeurs doivent prendre en compte plusieurs aspects de l’invite. Une invite qui inclut trop d’informations supplémentaires et certaines (éventuellement les informations les plus importantes) peuvent être ignorées. De même, une invite qui inclut des informations non pertinentes pourrait avoir un impact indu sur la réponse.
Une autre considération est l’aiguille dans un problème de botte de foin , un terme qui fait référence à un quirk connu de certaines llMs où le contenu au début et à la fin d’une invite a plus de poids à la LLM que le contenu au milieu.
Enfin, la longueur maximale de la fenêtre de contexte de LLM et le nombre de jetons requis pour effectuer des invites extraordinairement longues (en particulier lorsque vous traitez des requêtes à grande échelle) doivent être pris en compte.
Pour résoudre ces problèmes, un pipeline de traitement post-récupération peut inclure les étapes suivantes :
- Résultats de filtrage : dans cette étape, les développeurs garantissent que les blocs d’article retournés par la base de données vectorielle sont pertinents pour la requête. Si ce n’est pas le cas, le résultat est ignoré lors de la composition de l’invite pour le LLM.
- Re-classement : classer les blocs d’article récupérés à partir du magasin vectoriel pour garantir que les détails pertinents vivent près des bords (début et fin) de l’invite.
- Compression d’invite - Utilisation d’un petit modèle peu coûteux conçu pour combiner et synthétiser plusieurs blocs d’articles en une seule invite compressée avant de l’envoyer au LLM.
Étapes de traitement postérieures à l’achèvement
Le traitement post-achèvement se produit après l’envoi de la requête de l’utilisateur et de tous les blocs de contenu au LLM, comme illustré dans le diagramme suivant :

Une fois l’invite terminée par le LLM, il est temps de valider l’achèvement pour vous assurer que la réponse est exacte. Un pipeline de traitement post-achèvement peut inclure les étapes suivantes :
- Vérification des faits - Cela peut prendre de nombreuses formes, mais l’intention est d’identifier des revendications spécifiques faites dans l’article qui sont présentées comme des faits, puis de vérifier ces faits à des fins d’exactitude. Si l’étape de vérification des faits échoue, il peut être approprié de réexéciser le LLM dans l’espoir d’obtenir une meilleure réponse ou de renvoyer un message d’erreur à l’utilisateur.
- Vérification de la stratégie : il s’agit de la dernière ligne de défense pour s’assurer que les réponses ne contiennent pas de contenu dangereux, qu’il s’agisse de l’utilisateur ou de l’organisation.
Évaluation
L’évaluation des résultats d’un système non déterministe n’est pas aussi simple que les tests unitaires ou d’intégration que la plupart des développeurs connaissent. Il existe plusieurs facteurs à prendre en compte :
- Les utilisateurs sont-ils satisfaits des résultats qu’ils obtiennent ?
- Les utilisateurs reçoivent-ils des réponses précises à leurs questions ?
- Comment capturer les commentaires des utilisateurs ? Avons-nous des stratégies en place qui limitent les données que nous sommes en mesure de collecter sur les données utilisateur ?
- Pour le diagnostic sur les réponses insatisfaisantes, avons-nous une visibilité sur tous les travaux qui ont répondu à la question ? Maintenons-nous un journal de chaque étape dans le pipeline d’inférence des entrées et des sorties afin que nous puissions effectuer une analyse de la cause racine ?
- Comment pouvons-nous apporter des modifications au système sans régression ni dégradation des résultats ?
Capture et action sur les commentaires des utilisateurs
Comme mentionné précédemment, les développeurs peuvent avoir besoin de travailler avec l’équipe de confidentialité de leur organisation pour concevoir des mécanismes de capture de commentaires et des données de télémétrie, la journalisation, etc. afin d’activer l’analyse de la cause légale et de la cause racine sur une session de requête donnée.
L’étape suivante consiste à développer un pipeline d’évaluation. La nécessité d’un pipeline d’évaluation découle de la complexité et de la nature intensive de l’analyse des commentaires détaillé et des causes racines des réponses fournies par un système IA. Cette analyse est cruciale, car elle implique d’examiner chaque réponse pour comprendre comment la requête IA a produit les résultats, en vérifiant l’adéquation des blocs de contenu utilisés à partir de la documentation et les stratégies utilisées pour diviser ces documents.
En outre, il implique de prendre en compte toutes les étapes supplémentaires de pré-traitement ou de post-traitement susceptibles d’améliorer les résultats. Cet examen détaillé révèle souvent les lacunes de contenu, en particulier lorsqu’aucune documentation appropriée n’existe en réponse à la requête d’un utilisateur.
La création d’un pipeline d’évaluation devient donc essentielle pour gérer efficacement l’échelle de ces tâches. Un pipeline efficace utilise des outils personnalisés pour évaluer les métriques qui correspondent approximativement à la qualité des réponses fournies par l’IA. Ce système simplifie le processus de détermination de la raison pour laquelle une réponse spécifique a été donnée à la question d’un utilisateur, les documents utilisés pour générer cette réponse et l’efficacité du pipeline d’inférence qui traite les requêtes.
Jeu de données Golden
Une stratégie d’évaluation des résultats d’un système non déterministe comme un système RAG-chat consiste à implémenter un « jeu de données d’or ». Un jeu de données doré est un ensemble organisé de questions avec des réponses approuvées, des métadonnées (comme la rubrique et le type de question), des références aux documents sources qui peuvent servir de vérité de base pour les réponses, et même des variantes (différentes formulations pour capturer la diversité de la façon dont les utilisateurs peuvent poser les mêmes questions).
Le « jeu de données d’or » représente le « meilleur scénario de cas » et permet aux développeurs d’évaluer le système pour voir comment il fonctionne et effectuer des tests de régression lors de l’implémentation de nouvelles fonctionnalités ou mises à jour.
Évaluation des dommages
La modélisation des préjudices est une méthodologie visant à prévoir des préjudices potentiels, à repérer les lacunes dans un produit susceptibles de poser des risques pour les individus et à élaborer des stratégies proactives pour atténuer ces risques.
L’outil conçu pour évaluer l’impact de la technologie, en particulier les systèmes d’IA, comporterait plusieurs composants clés basés sur les principes de modélisation des préjudices, comme indiqué dans les ressources fournies.
Les principales fonctionnalités d’un outil d’évaluation des dommages peuvent inclure :
Identification des parties prenantes : l’outil aiderait les utilisateurs à identifier et à classer divers intervenants affectés par la technologie, y compris les utilisateurs directs, les parties indirectement affectées et d’autres entités comme les générations futures ou les facteurs non humains tels que les préoccupations environnementales (.
Catégories et descriptions des préjudices : il s’agirait d’une liste complète de préjudices potentiels, tels que la perte de vie privée, la détresse émotionnelle ou l’exploitation économique. L’outil pourrait guider l’utilisateur dans différents scénarios illustrant comment la technologie pourrait causer ces dommages, ce qui contribue à évaluer les conséquences prévues et inattendues.
Évaluations de gravité et de probabilité : l’outil permet aux utilisateurs d’évaluer la gravité et la probabilité de chaque préjudice identifié, ce qui leur permet de hiérarchiser les problèmes à résoudre en premier. Cela peut inclure des évaluations qualitatives et être pris en charge par les données lorsqu’elles sont disponibles.
Stratégies d’atténuation : lors de l’identification et de l’évaluation des préjudices, l’outil suggère des stratégies d’atténuation potentielles. Cela peut inclure des modifications apportées à la conception du système, à des mesures de protection supplémentaires ou à d’autres solutions technologiques qui réduisent les risques identifiés.
Mécanismes de commentaires : L’outil doit intégrer des mécanismes permettant de recueillir des commentaires des parties prenantes, en s’assurant que le processus d’évaluation des préjudices est dynamique et réactif aux nouvelles informations et perspectives.
Documentation et rapports : Pour faciliter la transparence et la responsabilité, l’outil faciliterait la création de rapports détaillés qui documentent le processus d’évaluation des préjudices, les résultats et les mesures prises pour atténuer les risques potentiels.
Ces fonctionnalités aideraient non seulement à identifier et à atténuer les risques, mais aussi à concevoir des systèmes d’IA plus éthiques et responsables en tenant compte d’un large éventail d’impacts dès le départ.
Pour plus d’informations, consultez l’article suivant :
Test et vérification des dispositifs de protection
Cet article a décrit plusieurs processus visant à atténuer la possibilité que le système de conversation basé sur RAG puisse être exploité ou compromis. L’équipe rouge joue un rôle crucial dans la garantie que les atténuations sont efficaces. L’association rouge implique la simulation des actions d’un adversaire visant l’application à découvrir les faiblesses ou vulnérabilités potentielles. Cette approche est particulièrement essentielle pour résoudre le risque important de jailbreakage.
Pour tester et vérifier efficacement les protections d’un système de conversation basé sur RAG, les développeurs doivent évaluer rigoureusement ces systèmes dans différents scénarios où ces directives pourraient être testées. Cela garantit non seulement la robustesse, mais aide également à affiner les réponses du système pour respecter strictement les normes éthiques et les procédures opérationnelles définies.
Considérations finales susceptibles d’influencer vos décisions de conception d’application
Voici une courte liste des éléments à prendre en compte et d’autres points à prendre en compte dans cet article qui affectent vos décisions de conception d’application :
- Reconnaissez la nature non déterministe de l’IA générative dans votre conception, la planification de la variabilité des sorties et la configuration de mécanismes pour garantir la cohérence et la pertinence dans les réponses.
- Évaluez les avantages de la prétraitement des invites utilisateur par rapport à l’augmentation potentielle de la latence et des coûts. La simplification ou la modification des invites avant la soumission peut améliorer la qualité de la réponse, mais peut ajouter de la complexité et du temps au cycle de réponse.
- Examinez les stratégies de parallélisation des requêtes LLM pour améliorer les performances. Cette approche peut réduire la latence, mais nécessite une gestion minutieuse pour éviter une complexité accrue et des implications potentielles sur les coûts.
Si vous souhaitez commencer à expérimenter immédiatement la création d’une solution d’INTELLIGENCE artificielle générative, nous vous recommandons de vous familiariser avec la conversation à l’aide de votre propre exemple de données pour Python. Il existe également des versions du didacticiel disponibles dans .NET, Java et JavaScript.