Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article explique comment utiliser les modèles multimodaux Azure OpenAI pour générer des réponses aux messages utilisateur et aux images téléchargées dans une app de chat. Cet exemple d’application de conversation inclut également l’infrastructure et la configuration nécessaires pour approvisionner Azure ressources OpenAI et déployer l’application sur Azure Container Apps à l’aide de l’interface CLI Azure développeur.
En suivant les instructions de cet article, vous allez :
- Déployez une application de conversation de conteneur Azure qui utilise l’identité managée pour l’authentification.
- Chargez des images à utiliser dans le flux de conversation.
- Discutez avec un modèle de langage large multimodal Azure OpenAI à l'aide de l'API de réponses de la bibliothèque OpenAI.
Une fois cet article terminé, vous pouvez commencer à modifier le nouveau projet avec votre code personnalisé.
Remarque
Cet article utilise un ou plusieurs modèles d’application IA comme base pour les exemples et les conseils qu’il contient. Les modèles d’application IA vous fournissent des implémentations de référence bien gérées et faciles à déployer, qui constituent un point de départ de qualité pour vos applications IA.
Vue d’ensemble de l’architecture
Une architecture simple de l’application de conversation est illustrée dans le diagramme suivant : 
L’application de conversation s’exécute en tant qu’application conteneur Azure. L’application utilise une identité managée via Microsoft Entra ID pour s’authentifier auprès de Azure OpenAI en production, au lieu d’une clé API. Pendant le développement, l’application prend en charge plusieurs méthodes d’authentification, notamment les informations d’identification cli Azure développeur et les clés API.
L’architecture d’application s’appuie sur les services et composants suivants :
- Azure OpenAI représente le fournisseur d'IA auquel nous envoyons les requêtes de l'utilisateur.
- Azure Container Apps est l’environnement de conteneur où l’application est hébergée.
- Managed Identity nous aide à garantir une sécurité optimale et élimine la nécessité pour vous en tant que développeur de gérer en toute sécurité un secret.
- fichiers Bicep pour l’approvisionnement de ressources Azure, notamment Azure OpenAI, Azure Container Apps, Azure Container Registry, Azure Log Analytics et les rôles de contrôle d’accès en fonction du rôle (RBAC).
- Application Python Quart qui utilise le package
openaipour générer des réponses aux messages utilisateur avec des fichiers image chargés. - Frontend HTML/JavaScript de base qui diffuse des réponses du back-end à l’aide de JSON Lines sur un ReadableStream.
Coût
Dans une tentative de maintenir la tarification aussi faible que possible dans cet exemple, la plupart des ressources utilisent un niveau tarifaire de base ou de consommation. Modifiez votre niveau selon vos besoins en fonction de votre utilisation prévue. Pour arrêter d'encourir des frais, supprimez les ressources quand vous avez terminé l'article.
En savoir plus sur le coût dans l'exemple de dépôt.
Prérequis
Un environnement de conteneur de développement est disponible avec toutes les dépendances requises pour terminer cet article. Vous pouvez exécuter le conteneur de développement dans GitHub Codespaces (dans un navigateur) ou localement à l’aide de Visual Studio Code.
Pour utiliser cet article, vous devez remplir les conditions préalables suivantes :
Un abonnement Azure - Create one gratuitement
autorisations de compte Azure : votre compte de Azure doit disposer d’autorisations
Microsoft.Authorization/roleAssignments/write, telles que Utilisateur Access Administrator ou Owner.compte GitHub
Environnement de développement ouvert
Utilisez les instructions suivantes pour déployer un environnement de développement préconfiguré contenant toutes les dépendances requises pour terminer cet article.
GitHub Codespaces exécute un conteneur de développement géré par GitHub avec Visual Studio Code pour le web comme interface utilisateur. Pour l’environnement de développement le plus simple, utilisez GitHub Codespaces afin que vous ayez les outils de développement et les dépendances appropriés préinstallés pour terminer cet article.
Important
Tous les comptes GitHub peuvent utiliser des espaces de code pour jusqu’à 60 heures gratuites chaque mois avec deux instances principales. Pour plus d'informations, consultez stockage mensuel inclus et heures centrales de GitHub Codespaces.
Procédez comme suit pour créer un espace de code GitHub sur la branche main du référentiel Azure-Samples/openai-chat-vision-quickstart GitHub.
Cliquez avec le bouton droit sur le bouton suivant, puis sélectionnez Ouvrir le lien dans la nouvelle fenêtre. Cette action vous permet d’avoir l’environnement de développement et la documentation disponible pour révision.

Dans la page Create codespace, passez en revue et sélectionnez ensuite Create new codespace
Attendez que le codespace démarre. Ce processus de démarrage peut prendre quelques minutes.
Connectez-vous à Azure avec l’interface CLI Azure développeur dans le terminal en bas de l’écran.
azd auth loginCopiez le code à partir du terminal, puis collez-le dans un navigateur. Suivez les instructions pour vous authentifier auprès de votre compte Azure.
Les tâches restantes de cet article s’effectuent dans ce conteneur de développement.
Déployer et exécuter des applications
Le dépôt d'exemples contient tous les fichiers de code et de configuration pour le déploiement de l'application de chat Azure. Les étapes suivantes vous guident à travers le processus de déploiement de l'application de chat Azure.
Déployer l’application de conversation sur Azure
Important
Pour réduire les coûts, cet exemple utilise des niveaux tarifaires de base ou de consommation pour la plupart des ressources. Ajustez le niveau en fonction des besoins, puis supprimez les ressources une fois terminé pour éviter des frais.
Exécutez la commande CLI de développement Azure suivante pour le déploiement des ressources Azure et du code source :
azd upUtilisez le tableau suivant pour répondre aux instructions :
Prompt Réponse Nom de l’environnement Gardez-le court et en minuscules. Ajoutez votre nom ou votre pseudo. Par exemple : chat-vision. Il est utilisé comme partie du nom du groupe de ressources.Abonnement Sélectionnez l’abonnement dans lequel créer les ressources. Emplacement (pour l’hébergement) Sélectionnez un emplacement près de chez vous dans la liste. Emplacement du modèle OpenAI Azure Sélectionnez un emplacement près de chez vous dans la liste. Si le premier emplacement choisi est également disponible, sélectionnez-le. Attendez que l’application soit déployée. Le déploiement prend généralement entre 5 et 10 minutes.
Utiliser l’application de messagerie instantanée pour poser des questions au grand modèle de langage
Le terminal affiche une URL après le déploiement réussi de l’application.
Sélectionnez cette URL étiquetée
Deploying service webpour ouvrir l’application de conversation dans un navigateur.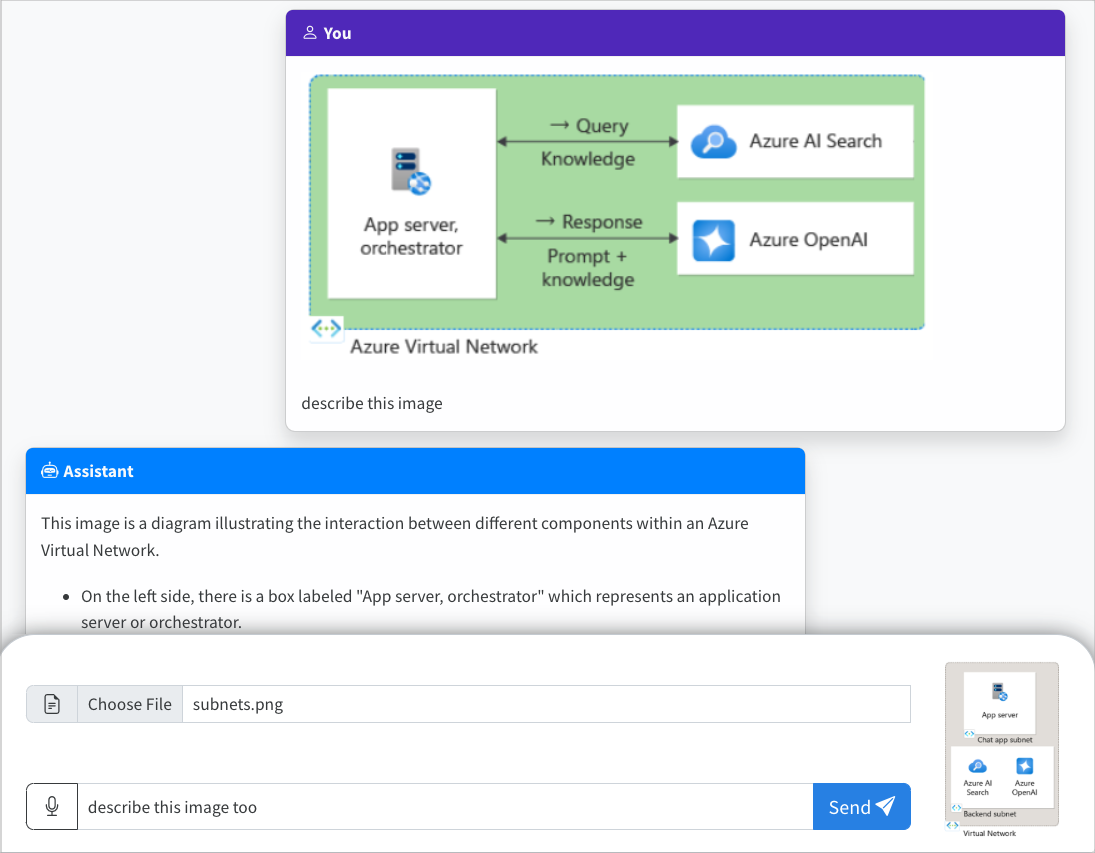
Dans le navigateur, chargez une image en cliquant sur Choisir un fichier et en sélectionnant une image.
Posez une question sur l’image chargée, telle que « De quoi parle l'image ? ».
La réponse provient de Azure OpenAI et le résultat est affiché.

Exploration de l’exemple de code
Cet exemple utilise un modèle multimodal Azure OpenAI pour générer des réponses aux messages des utilisateurs et aux images chargées.
Encodage base64 de l’image chargée dans le front-end
L’image chargée doit être encodée en Base64 afin qu’elle puisse être utilisée directement en tant qu’URI de données dans le cadre du message.
Dans l’exemple, l’extrait de code frontal suivant dans la balise script du fichier src/quartapp/templates/index.html gère cette fonctionnalité. La toBase64 fonction flèche utilise la méthode readAsDataURL pour lire de manière asynchrone le fichier image chargé en tant que chaîne encodée en base64.
const toBase64 = file => new Promise((resolve, reject) => {
const reader = new FileReader();
reader.readAsDataURL(file);
reader.onload = () => resolve(reader.result);
reader.onerror = reject;
});
La fonction toBase64 est appelée par un écouteur sur l'événement submit du formulaire.
L'écouteur d'événement submit gère le flux complet d'interaction de chat. Lorsque l’utilisateur envoie un message, le flux suivant se produit :
- Obtient le fichier image chargé (le cas échéant) et encode en base64
- Crée et affiche le message de l’utilisateur dans la conversation, y compris l’image chargée
- Préprare un conteneur de messages d’assistant avec un indicateur « saisie… »
- Ajoute le message de l’utilisateur au tableau d’historique des messages au format de l’API Réponses
- Envoie une
fetchrequête POST au point de terminaison avec l’historique et le/chat/streamcontexte des messages (y compris l’image et le nom de fichier codés en Base64) - Traite la réponse de lignes JSON diffusées en continu pour afficher chaque delta de texte de manière incrémentielle
- Gère les erreurs lors de la diffusion en continu
- Ajoute un bouton de sortie vocale après avoir reçu la réponse complète afin que les utilisateurs puissent entendre la réponse
- Efface le champ d’entrée et retourne le focus pour le message suivant
form.addEventListener("submit", async function(e) {
e.preventDefault();
// Hide the no-messages-heading when a message is added
document.getElementById("no-messages-heading").style.display = "none";
const file = document.getElementById("file").files[0];
const fileData = file ? await toBase64(file) : null;
const message = messageInput.value;
const userTemplateClone = userTemplate.content.cloneNode(true);
userTemplateClone.querySelector(".message-content").innerText = message;
if (file) {
const img = document.createElement("img");
img.src = fileData;
userTemplateClone.querySelector(".message-file").appendChild(img);
}
targetContainer.appendChild(userTemplateClone);
const assistantTemplateClone = assistantTemplate.content.cloneNode(true);
let messageDiv = assistantTemplateClone.querySelector(".message-content");
targetContainer.appendChild(assistantTemplateClone);
messages.push({
"role": "user",
"content": [{"type": "input_text", "text": message}]
});
try {
messageDiv.scrollIntoView();
const response = await fetch("/chat/stream", {
method: "POST",
headers: {"Content-Type": "application/json"},
body: JSON.stringify({
messages: messages,
context: {
file: fileData,
file_name: file ? file.name : null
}
})
});
if (!response.ok || !response.body) {
throw new Error(`Request failed (${response.status})`);
}
let answer = "";
for await (const chunk of readNDJSONStream(response.body)) {
if (chunk.type === "error" || chunk.type === "response.failed") {
messageDiv.innerHTML = "Error: " + (chunk.error || "Unknown error");
break;
}
if (chunk.type === "response.output_text.delta") {
// Clear out the DIV if its the first answer chunk we've received
if (answer == "") {
messageDiv.innerHTML = "";
}
answer += chunk.delta;
messageDiv.innerHTML = converter.makeHtml(answer);
messageDiv.scrollIntoView();
}
}
messages.push({
"role": "assistant",
"content": [{"type": "output_text", "text": answer}]
});
messageInput.value = "";
const speechOutput = document.createElement("speech-output-button");
speechOutput.setAttribute("text", answer);
messageDiv.appendChild(speechOutput);
messageInput.focus();
} catch (error) {
messageDiv.innerHTML = "Error: " + error;
}
});
Gestion de l’image avec le back-end
Dans le fichier, le code principal pour la src\quartapp\chat.py gestion des images démarre après la configuration de l’authentification sans clé.
Remarque
Pour plus d'informations sur l'utilisation des connexions sans clé pour l'authentification et l'autorisation à Azure OpenAI, consultez l'article Commencez avec le bloc de construction de sécurité Azure OpenAI sur Microsoft Learn.
Configuration de l'authentification
La configure_openai() fonction configure le client OpenAI avant que l’application commence à traiter les requêtes. Il utilise le décorateur @bp.before_app_serving de Quart pour configurer l’authentification basée sur des variables d’environnement. Ce système flexible permet aux développeurs de travailler dans différents contextes sans modifier le code.
Modes d’authentification expliqués
-
Développement local (
OPENAI_HOST=local) : se connecte à un service d’API compatible OpenAI local (tel que Ollama ou LocalAI) sans authentification. Utilisez ce mode pour les tests sans coût Internet ou API. -
Azure OpenAI avec la clé API (variable d’environnement
AZURE_OPENAI_KEY_FOR_CHATVISION) : utilise une clé API pour l’authentification. Évitez ce mode en production, car les clés API nécessitent une rotation manuelle et présentent des risques de sécurité en cas d’exposition. Utilisez-le pour les tests locaux à l’intérieur d’un conteneur Docker sans les informations d’identification Azure CLI. -
Production avec l'identité managée (
RUNNING_IN_PRODUCTION=true) : utiliseManagedIdentityCredentialpour s'authentifier auprès de Azure OpenAI via l'identité managée de l'application conteneur. Cette méthode est recommandée pour la production, car elle supprime la nécessité de gérer les secrets. Azure Container Apps fournit automatiquement l’identité gérée et accorde des autorisations lors du déploiement via Bicep. -
Development avec Azure CLI (mode par défaut) : utilise
AzureDeveloperCliCredentialpour s’authentifier auprès de Azure OpenAI à l’aide des informations d’identification de Azure CLI connectées localement. Ce mode simplifie le développement local sans gérer les clés API.
Détails de l’implémentation clé
- La fonction
get_bearer_token_provider()actualise les identifiants Azure et les utilise comme jetons d'accès. - Le chemin du point de terminaison Azure OpenAI se termine par
/openai/v1/, le point de terminaison compatible OpenAI généralement disponible pour les modèles Microsoft Foundry. - La fonction est asynchrone, car Quart est une infrastructure d’application web asynchrone. Quart permet aux gestionnaires de requêtes d’être asynchrones. Par conséquent, alors que l’application attend des réponses lentes de l’API LLM, le serveur peut continuer à gérer d’autres requêtes.
Voici le code complet de configuration de l’authentification à partir de chat.py:
@bp.before_app_serving
async def configure_openai():
bp.model_name = os.getenv("OPENAI_MODEL", "gpt-4o")
openai_host = os.getenv("OPENAI_HOST", "azure")
if openai_host == "local":
bp.openai_client = AsyncOpenAI(api_key="no-key-required", base_url=os.getenv("LOCAL_OPENAI_ENDPOINT"))
current_app.logger.info("Using local OpenAI-compatible API service with no key")
elif os.getenv("AZURE_OPENAI_KEY_FOR_CHATVISION"):
bp.openai_client = AsyncOpenAI(
base_url=os.environ["AZURE_OPENAI_ENDPOINT"].rstrip("/") + "/openai/v1",
api_key=os.getenv("AZURE_OPENAI_KEY_FOR_CHATVISION"),
)
current_app.logger.info("Using Azure OpenAI with key")
elif os.getenv("RUNNING_IN_PRODUCTION"):
client_id = os.environ["AZURE_CLIENT_ID"]
azure_credential = ManagedIdentityCredential(client_id=client_id)
token_provider = get_bearer_token_provider(azure_credential, "https://cognitiveservices.azure.com/.default")
bp.openai_client = AsyncOpenAI(
base_url=os.environ["AZURE_OPENAI_ENDPOINT"].rstrip("/") + "/openai/v1",
api_key=token_provider,
)
current_app.logger.info("Using Azure OpenAI with managed identity credential for client ID %s", client_id)
else:
tenant_id = os.environ["AZURE_TENANT_ID"]
azure_credential = AzureDeveloperCliCredential(tenant_id=tenant_id)
token_provider = get_bearer_token_provider(azure_credential, "https://cognitiveservices.azure.com/.default")
bp.openai_client = AsyncOpenAI(
base_url=os.environ["AZURE_OPENAI_ENDPOINT"].rstrip("/") + "/openai/v1",
api_key=token_provider,
)
current_app.logger.info("Using Azure OpenAI with az CLI credential for tenant ID: %s", tenant_id)
Fonction de gestionnaire de conversation
La fonction chat_handler() traite les requêtes de chat envoyées au point de terminaison /chat/stream. Il reçoit une requête POST avec une charge utile JSON.
La charge utile JSON comprend :
-
messages : liste de l’historique des conversations. Chaque message a un
role(« utilisateur » ou « Assistant ») etcontent(tableau de parties de contenu à l’aide du format d’entrée de l’API Réponses). -
contexte : Données supplémentaires pour le traitement, notamment :
-
fichier : données d’image encodées en base64 (par exemple,
data:image/png;base64,...). - file_name : nom de fichier d’origine de l’image chargée (utile pour la journalisation ou l’identification du type d’image).
-
fichier : données d’image encodées en base64 (par exemple,
Le gestionnaire extrait l’historique des messages et les données d’image. Si aucune image n’est chargée, la valeur de l’image est nullet le code gère ce cas.
@bp.post("/chat/stream")
async def chat_handler():
request_json = await request.get_json()
request_messages = request_json["messages"]
# Get the base64 encoded image from the request context
# This will be None if no image was uploaded
image = request_json["context"]["file"]
Construction du tableau d’entrée pour les requêtes de vision
La fonction response_stream() prépare le tableau d’entrée envoyé à l’API réponses OpenAI Azure. Le @stream_with_context décorateur conserve le contexte de la requête lors de la diffusion en continu de la réponse.
Logique de préparation d’entrée
-
Commencer par l’historique des conversations : la fonction commence par
all_input, qui inclut tous les messages précédents à l’exception de la dernière (request_messages[0:-1]). Les messages sont déjà au format de l’API Réponses à partir du front-end. -
Gérez le message utilisateur actuel en fonction de la présence d’image :
-
Avec l’image : ajoutez un
input_imagecomposant de contenu au tableau de contenu existant de l’utilisateur. - Sans image : ajoutez le message de l’utilisateur as-is.
-
Avec l’image : ajoutez un
@stream_with_context
async def response_stream():
# This sends all messages, so API request may exceed token limits
all_input = list(request_messages[0:-1])
# Add the current user message, appending image if provided
if image:
user_content = request_messages[-1]["content"] + [{"type": "input_image", "image_url": image}]
all_input.append({"role": "user", "content": user_content})
else:
all_input.append(request_messages[-1])
Ensuite, bp.openai_client.responses.create appelle l’API réponses OpenAI Azure et diffuse la réponse. Le store=False paramètre indique à l’API de ne pas stocker les réponses sur le serveur, en effectuant l’appel sans état.
openai_stream = await bp.openai_client.responses.create(
model=bp.model_name,
input=all_input,
stream=True,
temperature=0.3,
store=False,
)
Enfin, la réponse est redirigée vers le client. L’API Réponses émet de nombreux types d’événements, mais seul l’événement est nécessaire pour la response.output_text.delta diffusion en continu du texte généré. Les événements d’erreur sont consignés et transférés vers le serveur frontal.
try:
async for event in openai_stream:
if event.type == "response.output_text.delta":
yield json.dumps({"type": event.type, "delta": event.delta}, ensure_ascii=False) + "\n"
elif event.type in ("response.failed", "error"):
current_app.logger.error("Responses API error: %s", event)
yield json.dumps({"type": event.type}, ensure_ascii=False) + "\n"
except Exception as e:
current_app.logger.exception("Error in response stream")
yield json.dumps({"error": str(e)}, ensure_ascii=False) + "\n"
return Response(response_stream())
Bibliothèques et fonctionnalités front-end
Le serveur frontal utilise des API et des bibliothèques de navigateur modernes pour créer une expérience de conversation interactive. Les développeurs peuvent personnaliser l’interface ou ajouter des fonctionnalités en comprenant ces composants :
Entrée/sortie vocale : les composants web personnalisés utilisent les API Speech du navigateur :
<speech-input-button>: convertit la voix en texte à l’aide deSpeechRecognitionl’API Web Speech. Il fournit un bouton de microphone qui écoute l’entrée vocale et émet unspeech-input-resultévénement avec le texte transcrit.<speech-output-button>: lit le texte à haute voix à l’aide de l’APISpeechSynthesis. Il apparaît après chaque réponse de l’Assistant avec une icône de haut-parleur, ce qui permet aux utilisateurs d’entendre la réponse.
Pourquoi utiliser les API de navigateur au lieu d'Azure Speech Services ?
- Aucun coût - s’exécute entièrement dans le navigateur
- Réponse instantanée : aucune latence réseau
- Confidentialité : les données vocales restent sur l’appareil de l’utilisateur
- Il n’est pas nécessaire de disposer de ressources Azure supplémentaires
Ces composants sont dans
src/quartapp/static/speech-input.jsetspeech-output.js.Aperçu de l’image : affiche l’image chargée dans la conversation avant l’envoi de l’analyse pour confirmation. La préversion est mise à jour automatiquement lorsqu’un fichier est sélectionné.
fileInput.addEventListener("change", async function() { const file = fileInput.files[0]; if (file) { const fileData = await toBase64(file); imagePreview.src = fileData; imagePreview.style.display = "block"; } });Bootstrap 5 et Bootstrap Icons : fournit des composants d'interface utilisateur et des icônes réactifs. L’application utilise le thème Cosmo de Bootswatch pour une apparence moderne.
Rendu de message basé sur un modèle : utilise des éléments HTML
<template>pour les dispositions de messages réutilisables, ce qui garantit un style et une structure cohérents.
Autres exemples de ressources à explorer
En plus de l’exemple d’application de conversation, il existe d’autres ressources dans le référentiel pour explorer davantage d’apprentissage. Consultez les blocs-notes suivants dans le notebooks répertoire :
| Ordinateur portable | Description |
|---|---|
| chat_pdf_images.ipynb | Ce bloc-notes montre comment convertir des pages PDF en images et les envoyer à un modèle de vision pour l’inférence. |
| chat_vision.ipynb | Ce notebook est fourni pour l’expérimentation manuelle avec le modèle de vision utilisé dans l’application. |
Contenu localisé : les versions espagnoles des blocs-notes se trouvent dans le notebooks/Spanish/ répertoire, offrant la même formation pratique pour les développeurs espagnols. Les blocs-notes anglais et espagnols montrent :
- Comment appeler des modèles de vision directement pour l’expérimentation
- Comment convertir des pages PDF en images à des fins d’analyse
- Comment ajuster les paramètres et les invites de test
Nettoyer les ressources
Nettoyer les ressources Azure
Les ressources Azure créées dans cet article sont facturées à votre abonnement Azure. Si vous pensez ne plus avoir besoin de ces ressources, supprimez-les pour éviter des frais supplémentaires.
Pour supprimer les ressources Azure et supprimer le code source, exécutez la commande CLI Azure développeur suivante :
azd down --purge
Nettoyer les espaces de code GitHub
La suppression de l’environnement GitHub Codespaces garantit que vous pouvez optimiser la quantité d’heures de travail gratuites par cœur que vous obtenez pour votre compte.
Important
Pour plus d'informations sur les droits de votre compte GitHub, consultez GitHub Codespaces : stockage inclus mensuellement et heures de base.
Connectez-vous au tableau de bord GitHub Codespaces.
Recherchez vos espaces de code en cours d’exécution provenant du référentiel
Azure-Samples//openai-chat-vision-quickstartGitHub.Ouvrez le menu contextuel du codespace et sélectionnez Supprimer.

Obtenir de l’aide
Consignez votre problème dans le Issues du référentiel.