Effectuer une migration d’exécution de test
Votre équipe est maintenant prête à commencer le processus de démarrage d’une série de tests de votre migration, puis à une migration complète de production. Dans cette phase, nous abordons les dernières étapes de mise en file d’attente d’une migration en plus d’autres tâches qui se présentent généralement à la fin du projet de migration.

Prérequis
Terminez la phase De préparation de l’exécution du test avant de commencer une migration d’exécution de test.
Important
Pour garantir un processus de migration fluide, effectuez une ou plusieurs importations de test. Un import d'essai dure 45 jours pour tester et valider. Après 45 jours, l’exécution du test expire et est supprimée, ce qui vous oblige à recommencer si nécessaire. Plus le temps passe entre l’exécution de test et l’exécution de production, plus le service peut changer, ce qui peut entraîner des erreurs qu’une nouvelle exécution de test intercepterait. Vous pouvez relancer l’importation de test autant de fois que nécessaire. Chaque importation commence à partir de l’état initial de la base de données importée, car il n’est pas possible que les modifications d’une importation soient conservées vers une autre. Notez les points suivants :
- Vous ne pouvez pas étendre indéfiniment une exécution de test
- Vous ne pouvez pas promouvoir une exécution de test vers une exécution de production
- Une exécution de test est supprimée si l’une des opérations suivantes se produit :
- Le test expire.
- Une nouvelle exécution de test portant le même nom est exécutée
- Une exécution de production démarre
- L’organisation est supprimée manuellement via les paramètres de l’organisation
Valider une collection
Validez chaque collection que vous souhaitez migrer vers Azure DevOps Services. L’étape de validation examine différents aspects de votre collection, notamment la taille, le classement, l’identité et les processus.
Exécutez la validation à l’aide de l’outil de migration de données.
Téléchargez l’outil de migration de données.
Copiez le fichier zip dans l’un de vos niveaux d’application Azure DevOps Server.
Décompressez le fichier . Vous pouvez également exécuter l’outil à partir d’une autre machine sans qu’Azure DevOps Server soit installé, tant que la machine peut se connecter à la base de données de configuration de l’instance Azure DevOps Server.
Ouvrez une fenêtre d’invite de commandes sur le serveur et entrez une commande cd pour passer au répertoire dans lequel l’outil de migration de données est stocké. Prenez quelques instants pour passer en revue le contenu d’aide de l’outil.
a. Pour afficher l’aide et les conseils de niveau supérieur, exécutez la commande suivante.
Migrator /helpb. Affichez le texte d’aide de la commande.
Migrator validate /helpLors de la première validation d’une collection, votre commande doit avoir la structure simple suivante.
Migrator validate /collection:{collection URL} /tenantDomainName:{name} /region:{region}Où
{name}fournit le nom de votre locataire Microsoft Entra, par exemple, pour s’exécuter sur DefaultCollection et le locataire fabrikam , la commande ressemblerait à l’exemple suivant.Migrator validate /collection:http://localhost:8080/DefaultCollection /tenantDomainName:fabrikam.OnMicrosoft.com /region:{region}Pour exécuter l’outil à partir d’une machine autre que le Azure DevOps Server, vous avez besoin du paramètre /connectionString. Le paramètre de chaîne de connexion pointe vers votre base de données de configuration Azure DevOps Server. Par exemple, si la commande validée s’exécute par la société Fabrikam, la commande ressemble.
Migrator validate /collection:http://fabrikam:8080/DefaultCollection /tenantDomainName:fabrikam.OnMicrosoft.com /region:{region} /connectionString:"Data Source=fabrikam;Initial Catalog=Configuration;Integrated Security=True"Important
L’outil de migration de données ne modifie pas de données ni de structures dans la collection. Il lit la collection uniquement pour identifier les problèmes.
Une fois la validation terminée, vous pouvez afficher les fichiers journaux et les résultats.
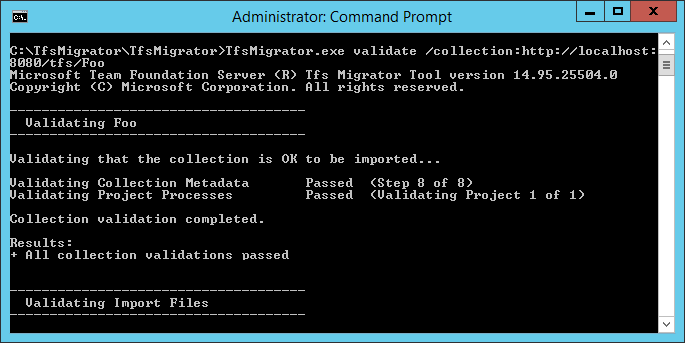
Pendant la validation, vous recevez un avertissement si certains de vos pipelines contiennent des règles de rétention par pipeline. Azure DevOps Services utilise un modèle de rétention basé sur un projet et ne prend pas en charge les stratégies de rétention par pipeline. Si vous poursuivez la migration, les stratégies ne sont pas transmises à la version hébergée. Au lieu de cela, les stratégies de rétention au niveau du projet par défaut s’appliquent. Conservez les builds importantes pour vous éviter leur perte.
Une fois toutes les validations passées, vous pouvez passer à l’étape suivante du processus de migration. Si l’outil de migration de données signale des erreurs, corrigez-les avant de continuer. Pour obtenir des conseils sur la correction des erreurs de validation, consultez Résoudre les erreurs de migration et de migration.
Importer des fichiers journaux
Lorsque vous ouvrez le répertoire des journaux, vous remarquerez peut-être plusieurs fichiers de journalisation.
Le fichier journal main est nommé DataMigrationTool.log. Il contient des détails sur tout ce qui a été exécuté. Pour faciliter le focus sur des domaines spécifiques, un journal génère pour chaque opération de validation majeure.
Par exemple, si TfsMigrator signale une erreur à l’étape « Validation des processus de projet », vous pouvez ouvrir le fichier ProjectProcessMap.log pour afficher tout ce qui a été exécuté pour cette étape au lieu d’avoir à faire défiler l’intégralité du journal.
Passez en revue le fichier TryMatchOobProcesses.log uniquement si vous essayez de migrer vos processus de projet pour utiliser le modèle hérité. Si vous ne souhaitez pas utiliser le modèle hérité, vous pouvez ignorer ces erreurs, car elles ne vous empêchent pas d’importer dans Azure DevOps Services. Pour plus d’informations, consultez la phase de validation de la migration.
Générer des fichiers de migration
L’outil de migration de données a validé la collection et retourne un résultat de « Toutes les validations de collecte passées ». Avant de mettre hors connexion une collection pour la migrer, générez les fichiers de migration. Lorsque vous exécutez la prepare commande, vous générez deux fichiers de migration :
- IdentityMapLog.csv : décrit votre carte d’identité entre Active Directory et Microsoft Entra ID.
- migration.json : vous devez remplir la spécification de migration que vous souhaitez utiliser pour lancer votre migration.
Préparer la commande
La prepare commande permet de générer les fichiers de migration requis. Essentiellement, cette commande analyse la collection pour rechercher une liste de tous les utilisateurs pour remplir le journal de carte d’identité, IdentityMapLog.csv, puis tente de se connecter à Microsoft Entra ID pour trouver la correspondance de chaque identité. Pour ce faire, votre entreprise doit utiliser l’outil Microsoft Entra Connect (anciennement outil de synchronisation d’annuaires, outil de synchronisation d’annuaires ou outil DirSync.exe).
Si la synchronisation d’annuaires est configurée, l’outil de migration de données doit rechercher les identités correspondantes et les marquer comme actives. S’il n’y a aucune correspondance, l’identité est marquée comme historique dans le journal des cartes d’identité. Vous devez donc examiner pourquoi l’utilisateur n’est pas inclus dans votre synchronisation d’annuaires. Le fichier de spécification de la migration, migration.json, doit être renseigné avant la migration.
Contrairement à la validate commande, preparenécessite une connexion Internet, car elle doit se connecter à l’ID Microsoft Entra pour remplir le fichier journal de la carte d’identité. Si votre instance Azure DevOps Server n’a pas d’accès à Internet, exécutez l’outil à partir d’un ordinateur qui le fait. Tant que vous pouvez trouver une machine avec une connexion intranet à votre Azure DevOps Server instance et une connexion Internet, vous pouvez exécuter cette commande. Pour obtenir de l’aide sur la prepare commande, exécutez la commande suivante :
Migrator prepare /help
La documentation d’aide comprend des instructions et des exemples d’exécution de la Migrator commande à partir du Azure DevOps Server instance lui-même et d’un ordinateur distant. Si vous exécutez la commande à partir de l’un des niveaux d’application de l’Azure DevOps Server instance, votre commande doit avoir la structure suivante :
Migrator prepare /collection:{collection URL} /tenantDomainName:{name} /region:{region}
Migrator prepare /collection:{collection URL} /tenantDomainName:{name} /region:{region} /connectionString:"Data Source={sqlserver};Initial Catalog=Configuration;Integrated Security=True"
Le paramètre connectionString est un pointeur vers la base de données de configuration de votre Azure DevOps Server instance. Par exemple, si la société Fabrikam exécute la prepare commande, la commande ressemble à l’exemple suivant :
Migrator prepare /collection:http://fabrikam:8080/DefaultCollection /tenantDomainName:fabrikam.OnMicrosoft.com /region:{region} /connectionString:"Data Source=fabrikam;Initial Catalog=Configuration;Integrated Security=True"
Lorsque l’outil de migration de données exécute la prepare commande, il exécute une validation complète pour vous assurer que rien n’a changé avec votre collection depuis la dernière validation complète. Si de nouveaux problèmes sont détectés, aucun fichier de migration n’est généré.
Peu après l’exécution de la commande, une fenêtre de connexion Microsoft Entra s’affiche. Connectez-vous avec une identité qui appartient au domaine client, qui est spécifié dans la commande. Assurez-vous que le locataire Microsoft Entra spécifié est celui avec lequel vous souhaitez que votre organisation future soit soutenue. Dans notre exemple Fabrikam, un utilisateur entre des informations d’identification similaires à l’exemple de capture d’écran suivant.
Important
N’utilisez pas de locataire Microsoft Entra de test pour une migration de test et votre locataire Microsoft Entra de production pour l’exécution de production. L’utilisation d’un locataire Microsoft Entra de test peut entraîner des problèmes de migration d’identité lorsque vous commencez votre exécution de production avec le locataire Microsoft Entra de production de votre organisation.
Lorsque vous exécutez la prepare commande avec succès dans l’outil de migration de données, la fenêtre de résultats affiche un ensemble de journaux et deux fichiers de migration. Dans le répertoire des journaux, recherchez un dossier de journaux et deux fichiers :
- migration.json est le fichier de spécification de migration. Nous vous recommandons de prendre le temps de le remplir.
- IdentityMapLog.csv contient le mappage généré d’Active Directory aux identités Microsoft Entra. Passez en revue la fin avant de lancer une migration.
Les deux fichiers sont décrits plus en détail dans les sections suivantes.
Fichier de spécification de migration
La spécification de migration, migration.json, est un fichier JSON qui fournit des paramètres de migration. Il inclut le nom de organization souhaité, les informations de compte de stockage et d’autres informations. La plupart des champs sont renseignés automatiquement et certains champs nécessitent votre entrée avant de tenter une migration.
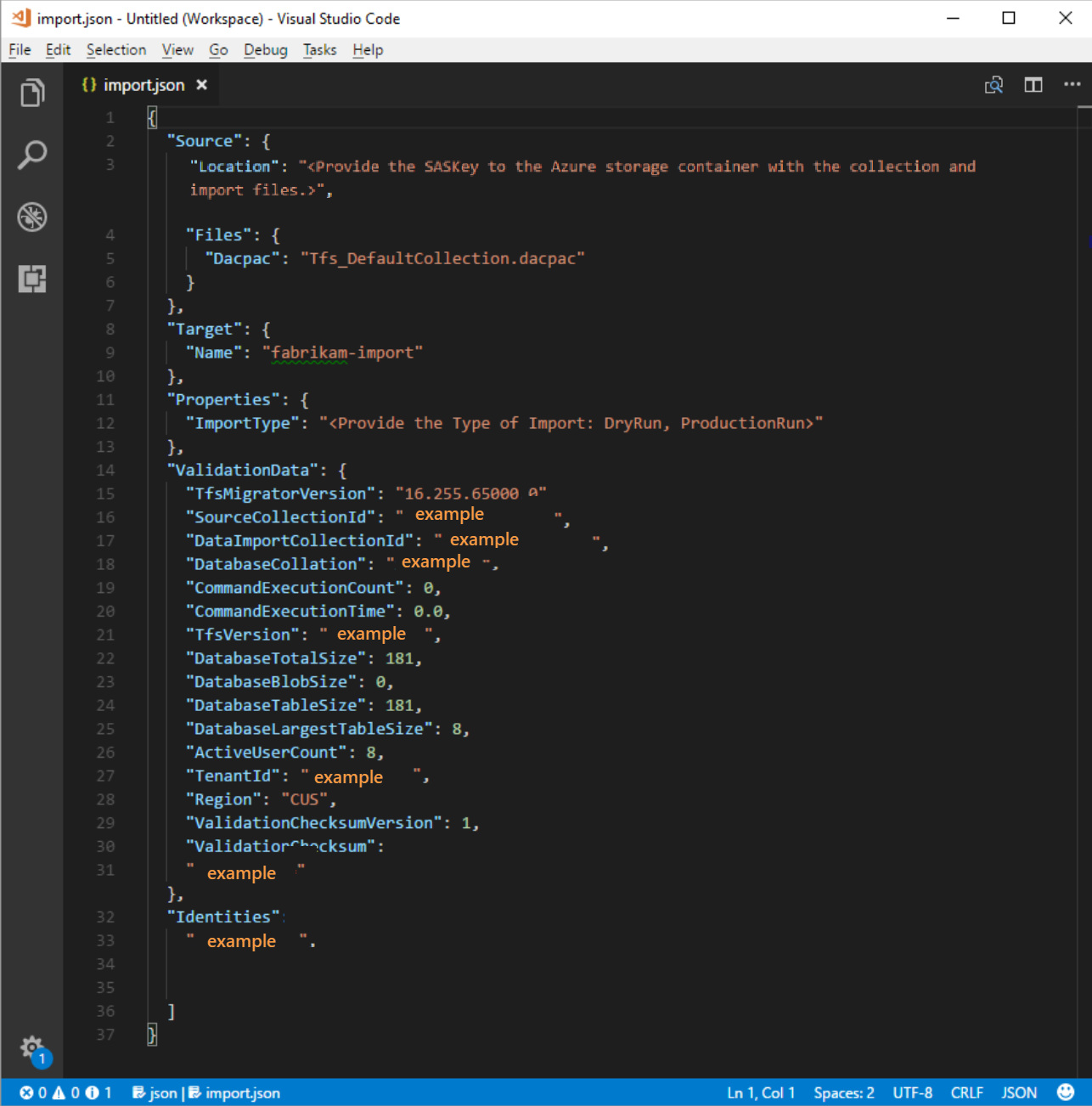
Les champs affichés du fichier migration.json et les actions requises sont décrites dans le tableau suivant :
| Champ | Description | Action requise |
|---|---|---|
| Source | Informations sur l’emplacement et les noms des fichiers de données sources utilisés pour la migration. | Aucune action requise. Passez en revue les informations relatives aux actions de sous-champ à suivre. |
| Emplacement | Clé de signature d’accès partagé au compte de stockage Azure qui héberge le package d’application de la couche Données (DACPAC). | Aucune action requise. Ce champ est abordé dans une étape ultérieure. |
| Fichiers | Noms des fichiers contenant des données de migration. | Aucune action requise. Passez en revue les informations relatives aux actions de sous-champ à suivre. |
| DACPAC | Fichier DACPAC qui empaquette la base de données de collecte à utiliser pour importer les données pendant la migration. | Aucune action requise. Dans une étape ultérieure, vous créez ce fichier à l’aide de votre collection, puis chargez-le dans un compte de stockage Azure. Mettez à jour le fichier en fonction du nom que vous utilisez lorsque vous le générez ultérieurement dans ce processus. |
| Cible | Propriétés de la nouvelle organisation vers laquelle effectuer la migration. | Aucune action requise. Passez en revue les informations relatives aux actions de sous-champ à suivre. |
| Nom | Nom de l’organisation à créer pendant la migration. | Donnez-lui un nom. Le nom peut être rapidement modifié ultérieurement une fois la migration terminée. REMARQUE : ne créez pas d’organisation portant ce nom avant d’exécuter la migration. L’organisation est créée dans le cadre du processus de migration. |
| ImportType | Type de migration que vous souhaitez exécuter. | Aucune action requise. Dans une étape ultérieure, sélectionnez le type de migration à exécuter. |
| Données de validation | Informations nécessaires pour faciliter votre expérience de migration. | L’outil de migration de données génère la section « ValidationData ». Il contient des informations pour faciliter votre expérience de migration. Ne modifiez pas* les valeurs de cette section, ou votre migration peut échouer. |
Une fois le processus précédent terminé, vous devez avoir un fichier qui ressemble à l’exemple suivant.
Dans l’image précédente, le planificateur de la migration Fabrikam a ajouté le nom de l’organisation fabrikam-import et sélectionné CUS (Central États-Unis) comme emplacement géographique pour la migration. D’autres valeurs ont été laissées telles qu’elles doivent être modifiées juste avant que le planificateur ne met la collection hors connexion pour la migration.
Remarque
Les importations d’exécution de test ont un « -dryrun » automatiquement ajouté à la fin du nom de l’organisation, que vous pouvez modifier après la migration.
Régions Azure prises en charge pour la migration
Azure DevOps Services est disponible dans plusieurs emplacements géographiques Azure. Toutefois, tous les emplacements où Azure DevOps Services est disponible ne sont pas pris en charge pour la migration. Le tableau suivant répertorie les emplacements géographiques Azure que vous pouvez sélectionner pour la migration. Également inclus est la valeur que vous devez placer dans le fichier de spécification de migration pour cibler cette zone géographique pour la migration.
| Emplacement géographique | Emplacement géographique Azure | Valeur de spécification d’importation |
|---|---|---|
| États-Unis | États-Unis central | CUS |
| Europe | Europe de l’Ouest | WEU |
| Royaume-Uni | Royaume-Uni Sud | UKS |
| Australie | Australie Est | EAU |
| Amérique du Sud | Brésil Sud | SBR |
| Asie-Pacifique | Inde Sud | MA |
| Asie-Pacifique | Asie Sud-Est (Singapour) | SEA |
| Canada | Canada central | CC |
Journal de la carte d’identité
Le journal des cartes d’identité est d’une importance égale aux données réelles que vous migrez vers Azure DevOps Services. Lorsque vous examinez le fichier, il est important de comprendre le fonctionnement de la migration des identités et les résultats potentiels. Lorsque vous migrez une identité, elle peut devenir active ou historique. Les identités actives peuvent se connecter à Azure DevOps Services, mais les identités historiques ne peuvent pas.
Identités actives
Les identités actives font référence aux identités utilisateur dans Azure DevOps Services après la migration. Dans Azure DevOps Services, ces identités sont concédées sous licence et sont affichées en tant qu’utilisateurs dans le organization. Les identités sont marquées comme actives dans la colonne État de l’importation attendue dans le fichier journal de la carte d’identité.
Identités historiques
Les identités historiques sont mappées en tant que telles dans la colonne État d’importation attendu du fichier journal de la carte d’identité. Les identités sans entrée de ligne dans le fichier deviennent également historiques. Un employé qui ne travaille plus dans une entreprise peut être un exemple d’identité sans entrée de ligne.
Contrairement aux identités actives, les identités historiques :
- N’avez pas accès à un organization après la migration.
- Vous n’avez pas de licences.
- Ne vous affichez pas en tant qu’utilisateurs dans le organization. Tout ce qui persiste, c’est la notion de nom de cette identité dans le organization, afin que son historique puisse être recherché plus tard. Nous vous recommandons d’utiliser des identités historiques pour les utilisateurs qui ne travaillent plus au sein de l’entreprise ou qui n’ont pas besoin d’un accès supplémentaire à l’organisation.
Remarque
Une fois qu’une identité est importée en tant qu’historique, elle ne peut pas devenir active.
Comprendre le fichier journal de carte d’identité
Le fichier journal de carte d’identité est similaire à l’exemple illustré ici :

Les colonnes du fichier journal de carte d’identité sont décrites dans le tableau suivant :
Vous et votre administrateur Microsoft Entra doivent examiner les utilisateurs marqués comme non trouvés (vérifier microsoft Entra ID Sync) pour comprendre pourquoi ils ne font pas partie de votre Synchronisation Microsoft Entra Connect.
| Colonne | Description |
|---|---|
| Active Directory : Utilisateur (Azure DevOps Server) | Nom complet convivial utilisé par l’identité dans Azure DevOps Server. Ce nom facilite l’identification de l’utilisateur auquel la ligne de la carte fait référence. |
| Active Directory : Identificateur de sécurité | Identificateur unique de l’identité Active Directory local dans Azure DevOps Server. Cette colonne est utilisée pour identifier les utilisateurs de la collection. |
| ID Microsoft Entra : Utilisateur d’importation attendu (Azure DevOps Services) | L’adresse de connexion attendue de l’utilisateur bientôt actif ou aucune correspondance trouvée (Vérifier microsoft Entra ID Sync), qui indique que l’identité a été perdue pendant la synchronisation d’ID Microsoft Entra et est importée comme historique. |
| État d’importation attendu | État de migration de l’utilisateur attendu : Actif s’il existe une correspondance entre votre Active Directory et l’ID Microsoft Entra, ou Historique s’il n’y a pas de correspondance. |
| Validation Date | La dernière fois que le journal de la carte d’identité a été validé. |
Lorsque vous lisez le fichier, notez si la valeur dans la colonne État de l’importation attendue est Active ou Historique. Active indique que l’identité de cette ligne est correctement mappée lors de la migration. Historique signifie que les identités deviennent historiques lors de la migration. Il est important de vérifier l’exhaustivité et l’exactitude du fichier de mappage généré.
Important
La migration échoue si des modifications majeures se produisent dans votre synchronisation d’ID de sécurité Microsoft Entra Connect entre les tentatives de migration. Vous pouvez ajouter de nouveaux utilisateurs entre les exécutions de test et apporter des corrections pour vous assurer que les identités historiques précédemment importées deviennent actives. Toutefois, vous ne pouvez pas modifier un utilisateur existant qui a été précédemment importé comme actif. Cela entraîne l’échec de votre migration. Un exemple de modification peut être l’exécution d’une migration d’exécution de test, la suppression d’une identité de votre ID Microsoft Entra importé activement, la recréation d’un utilisateur dans Microsoft Entra ID pour cette même identité, puis la tentative d’une autre migration. Dans ce cas, une migration d’identité active tente entre Active Directory et l’identité Microsoft Entra nouvellement créée, mais provoque un échec de migration.
Passez en revue les identités correctement mises en correspondance. Toutes les identités attendues sont-elles présentes ? Les utilisateurs sont-ils mappés à l’identité Microsoft Entra correcte ?
Si des valeurs doivent être modifiées, contactez votre administrateur Microsoft Entra pour vérifier que l’identité Active Directory local fait partie de la synchronisation avec l’ID Microsoft Entra et configurez correctement. Pour plus d’informations, consultez Intégrer vos identités locales à l’ID Microsoft Entra.
Ensuite, passez en revue les identités étiquetées comme historiques. Cette étiquetage implique qu’une identité Microsoft Entra correspondante n’a pas pu être trouvée, pour l’une des raisons suivantes :
- L’identité n’est pas configurée pour la synchronisation entre Active Directory local et l’ID Microsoft Entra.
- L’identité n’est pas encore remplie dans votre ID Microsoft Entra (par exemple, il y a un nouvel employé).
- L’identité n’existe pas dans votre instance Microsoft Entra.
- L’utilisateur propriétaire de cette identité ne travaille plus au sein de l’entreprise.
Pour répondre aux trois premières raisons, configurez l’identité Active Directory local prévue pour la synchronisation avec l’ID Microsoft Entra. Pour plus d’informations, consultez Intégrer vos identités locales à l’ID Microsoft Entra. Vous devez configurer et exécuter Microsoft Entra Connect pour que les identités soient importées comme actives dans Azure DevOps Services.
Vous pouvez ignorer la quatrième raison, car les employés qui ne sont plus dans l’entreprise doivent être importés comme historiques.
Identités historiques (petites équipes)
Remarque
Seules les petites équipes doivent envisager la stratégie de migration d’identité proposée dans cette section.
Si Microsoft Entra Connect n’est pas configuré, tous les utilisateurs du fichier journal de carte d’identité sont marqués comme historiques. L’exécution d’une migration de cette façon entraîne l’importation de tous les utilisateurs en tant qu’historique. Nous vous recommandons vivement de configurer Microsoft Entra Connect pour vous assurer que vos utilisateurs sont importés comme actifs.
L’exécution d’une migration avec toutes les identités historiques a des conséquences qui doivent être prises en compte avec soin. Seules les équipes avec quelques utilisateurs et pour lesquelles le coût de la configuration de Microsoft Entra Connect est jugé trop élevé doit être pris en compte.
Pour migrer toutes les identités en tant qu’historique, suivez les étapes décrites dans les sections ultérieures. Lorsque vous filez d’attente une migration, l’identité utilisée pour mettre en file d’attente la migration est démarrée dans l’organisation en tant que propriétaire d’organisation. Tous les autres utilisateurs sont importés en tant qu’historique. Les propriétaires de l’organisation peuvent ensuite ajouter les utilisateurs à l’aide de leur identité Microsoft Entra. Les utilisateurs ajoutés sont traités comme de nouveaux utilisateurs. Ils ne possèdent aucune de leur histoire, et il n’y a aucun moyen de réparer cette histoire à l’identité Microsoft Entra. Toutefois, les utilisateurs peuvent toujours rechercher leur historique de prémigration en recherchant leur \<domain>\<Active Directory username>.
L’outil de migration de données affiche un avertissement s’il détecte le scénario complet des identités historiques. Si vous décidez de descendre ce chemin de migration, vous devez donner votre consentement dans l’outil aux limitations.
Abonnements Visual Studio
L’outil de migration de données ne peut pas détecter les abonnements Visual Studio (anciennement les avantages MSDN) lorsqu’il génère le fichier journal de carte d’identité. Au lieu de cela, nous vous recommandons d’appliquer la fonctionnalité de mise à niveau de licence automatique après la migration. Tant que les comptes professionnels des utilisateurs sont correctement liés , Azure DevOps Services applique automatiquement leurs avantages d’abonnement Visual Studio lors de leur première connexion après la migration. Vous n’êtes jamais facturé pour les licences affectées pendant la migration. Vous pouvez donc gérer en toute sécurité les abonnements par la suite.
Vous n’avez pas besoin de répéter une migration d’exécution de test si les abonnements Visual Studio des utilisateurs ne sont pas automatiquement mis à niveau dans Azure DevOps Services. La liaison d’abonnement Visual Studio se produit en dehors de l’étendue d’une migration. Tant que leur compte professionnel est lié correctement avant ou après la migration, les licences des utilisateurs sont automatiquement mises à niveau sur leur prochaine connexion. Une fois leurs licences mises à niveau, la prochaine fois que vous exécutez une migration, les utilisateurs sont mis à niveau automatiquement sur leur première connexion à l’organisation.
Préparation de la migration
Vous disposez maintenant de tous les éléments prêts à s’exécuter sur votre migration d’exécution de test. Planifiez un temps d’arrêt avec votre équipe pour mettre le regroupement hors connexion pour la migration. Lorsque vous acceptez une heure d’exécution de la migration, chargez les ressources requises que vous avez générées et une copie de la base de données sur Azure. La préparation de la migration se compose des cinq étapes suivantes.
Étape 1 : Mettre la collection hors connexion et la détacher.
Étape 2 : Générer un fichier DACPAC à partir de la collection que vous allez migrer.
Étape 3 : Chargez le fichier DACPAC et les fichiers de migration vers un compte de stockage Azure.
Étape 4 : Générer un jeton SAP pour accéder au compte de stockage.
Étape 5 : Complétez la spécification de migration.
Remarque
Avant d’effectuer une migration de production, nous vous recommandons vivement d’effectuer une migration d’exécution de test. Avec une exécution de test, vous pouvez vérifier que le processus de migration fonctionne pour votre collection et qu’il n’existe aucune forme de données unique qui peut entraîner un échec de migration de production.
Étape 1 : Détacher votre collection
Le détachement de la collection est une étape cruciale du processus de migration. Les données d’identité de la collection résident dans la base de données de configuration du Azure DevOps Server instance pendant que la collection est attachée et en ligne. Lorsqu’une collection est détachée du Azure DevOps Server instance, elle prend une copie de ces données d’identité et la package avec la collection pour le transport. Sans ces données, la partie identité de la migration ne peut pas être exécutée.
Conseil
Nous vous recommandons de conserver la collection détachée jusqu’à ce que la migration se termine, car il n’existe aucun moyen de migrer les modifications qui se sont produites pendant la migration. Détachez votre collection une fois que vous l’avez sauvegardée pour la migration. Vous n’êtes donc pas préoccupé par l’utilisation des données les plus récentes pour ce type de migration. Pour éviter tout le temps hors connexion, vous pouvez également choisir d’utiliser un détachement hors connexion pour les exécutions de test.
Il est important de peser le coût du choix d’entraîner un temps d’arrêt nul pour une exécution de test. Il nécessite d’effectuer des sauvegardes de la base de données de collection et de configuration, de les restaurer sur un instance SQL, puis de créer une sauvegarde détachée. Une analyse des coûts peut prouver que le fait de prendre quelques heures d’arrêt pour effectuer directement la sauvegarde détachée est préférable à la fin.
Étape 2 : Générer un fichier DACPAC
Les DACPC offrent une méthode rapide et relativement simple pour déplacer des collections dans Azure DevOps Services. Toutefois, une fois qu’une taille de base de données de collection dépasse un certain seuil, les avantages de l’utilisation d’un DACPAC commencent à diminuer.
Remarque
Si l’outil de migration de données affiche un avertissement indiquant que vous ne pouvez pas utiliser la méthode DACPAC, vous devez effectuer la migration à l’aide de la méthode de machine virtuelle SQL Azure. Ignorez les étapes 2 à 5 dans ce cas et suivez les instructions de la phase De préparation de l’exécution du test, de la section Migrer des collections volumineuses, puis de continuer à déterminer le type de migration. Si l’outil de migration de données n’affiche pas d’avertissement, utilisez la méthode DACPAC décrite dans cette étape.
DACPAC est une fonctionnalité de SQL Server qui permet aux bases de données d’être empaquetées dans un seul fichier et déployées sur d’autres instances de SQL Server. Un fichier DACPAC peut également être restauré directement dans Azure DevOps Services. Vous pouvez donc l’utiliser comme méthode d’empaquetage pour obtenir les données de votre collection dans le cloud.
Important
- Lorsque vous utilisez SqlPackage.exe, vous devez utiliser la version .NET Framework de SqlPackage.exe pour préparer le DACPAC. Le programme d’installation MSI doit être utilisé pour installer la version de .NET Framework de SqlPackage.exe. N’utilisez pas les versions dotnet CLI ou .zip (Windows .NET 6) de SqlPackage.exe, car ces versions peuvent générer des DACPACs incompatibles avec Azure DevOps Services.
- La version 161 de SqlPackage chiffre les connexions de base de données par défaut et risque de ne pas se connecter. Si vous recevez une erreur de processus de connexion, ajoutez
;Encrypt=False;TrustServerCertificate=Trueà la chaîne de connexion de l’instruction SqlPackage.
Téléchargez et installez SqlPackage.exe à l’aide du dernier programme d’installation MSI à partir des notes de publication de SqlPackage.
Après avoir utilisé le programme d’installation MSI, SqlPackage.exe s’installe dans un chemin similaire à %PROGRAMFILES%\Microsoft SQL Server\160\DAC\bin\.
Lorsque vous générez un DACPAC, gardez à l’esprit deux considérations : le disque sur lequel le DACPAC est enregistré et l’espace disque sur l’ordinateur qui génère le DACPAC. Vous souhaitez vous assurer que vous disposez de suffisamment d’espace disque pour terminer l’opération.
Lors de la création du package, SqlPackage.exe stocke temporairement les données de votre collection dans le répertoire temporaire sur le lecteur C de l’ordinateur à partir duquel vous initiez la demande d’empaquetage.
Vous constaterez peut-être que votre lecteur C est trop petit pour prendre en charge la création d’un DACPAC. Vous pouvez estimer la quantité d’espace dont vous avez besoin en recherchant la table la plus importante dans votre base de données de collection. Les DACPC sont créés une table à la fois. L’espace maximal requis pour exécuter la génération est à peu près équivalent à la taille de la plus grande table de la base de données de la collection. Si vous enregistrez le DACPAC généré sur le lecteur C, tenez compte de la taille de la base de données de collecte comme indiqué dans le fichier DataMigrationTool.log à partir d’une exécution de validation.
Le fichier DataMigrationTool.log fournit une liste des tables les plus volumineuses de la collection chaque fois que la commande est exécutée. Pour obtenir un exemple de tailles de table pour une collection, consultez la sortie suivante. Comparez la taille de la plus grande table avec l’espace libre sur le lecteur qui héberge votre répertoire temporaire.
Important
Avant de générer un fichier DACPAC, assurez-vous que votre collection est détachée.
[Info @08:23:59.539] Table name Size in MB
[Info @08:23:59.539] dbo.tbl_Content 38984
[Info @08:23:59.539] dbo.tbl_LocalVersion 1935
[Info @08:23:59.539] dbo.tbl_Version 238
[Info @08:23:59.539] dbo.tbl_FileReference 85
[Info @08:23:59.539] dbo.Rules 68
[Info @08:23:59.539] dbo.tbl_FileMetadata 61
Assurez-vous que le lecteur qui héberge votre répertoire temporaire dispose d’au moins autant d’espace libre. Si ce n’est pas le cas, vous devez rediriger le répertoire temporaire en définissant une variable d’environnement.
SET TEMP={location on disk}
Une autre considération est l’emplacement où les données DACPAC sont enregistrées. Le fait de pointer l’emplacement enregistré vers un lecteur distant éloigné peut entraîner des temps de génération plus longs. Si un lecteur rapide tel qu’un disque SSD est disponible localement, nous vous recommandons de cibler le lecteur en tant qu’emplacement d’enregistrement DACPAC. Sinon, il est toujours plus rapide d’utiliser un disque qui se trouve sur l’ordinateur où réside la base de données de collection plutôt qu’un lecteur distant.
Maintenant que vous avez identifié l’emplacement cible de la DACPAC et que vous avez suffisamment d’espace, il est temps de générer le fichier DACPAC.
Ouvrez une fenêtre d’invite de commandes et accédez à l’emplacement SqlPackage.exe. Pour générer le DACPAC, remplacez les valeurs d’espace réservé par les valeurs requises, puis exécutez la commande suivante :
SqlPackage.exe /sourceconnectionstring:"Data Source={database server name};Initial Catalog={Database Name};Integrated Security=True" /targetFile:{Location & File name} /action:extract /p:ExtractAllTableData=true /p:IgnoreUserLoginMappings=true /p:IgnorePermissions=true /p:Storage=Memory
- Source de données : SQL Server instance qui héberge votre base de données de collection Azure DevOps Server.
- Catalogue initial : nom de la base de données de collection.
- targetFile : emplacement sur le disque et nom du fichier DACPAC.
Une commande de génération DACPAC qui s’exécute sur le niveau de données Azure DevOps Server lui-même est illustrée dans l’exemple suivant :
SqlPackage.exe /sourceconnectionstring:"Data Source=localhost;Initial Catalog=Foo;Integrated Security=True" /targetFile:C:\DACPAC\Foo.dacpac /action:extract /p:ExtractAllTableData=true /p:IgnoreUserLoginMappings=true /p:IgnorePermissions=true /p:Storage=Memory
La sortie de la commande est un fichier DACPAC, généré à partir de la base de données de collection Foo appelée Foo.dacpac.
Configurer votre collection pour la migration
Une fois votre base de données de collecte rétablie sur votre machine virtuelle Azure, configurez une connexion SQL pour permettre à Azure DevOps Services de se connecter à la base de données pour migrer les données. Cette connexion autorise uniquement l’accès en lecture à une base de données unique.
Pour commencer, ouvrez SQL Server Management Studio sur la machine virtuelle, puis ouvrez une nouvelle fenêtre de requête sur la base de données à importer.
Définissez la récupération de la base de données sur simple :
ALTER DATABASE [<Database name>] SET RECOVERY SIMPLE;
Créez une connexion SQL pour la base de données et affectez cette connexion à « TFSEXECROLE » :
USE [<database name>]
CREATE LOGIN <pick a username> WITH PASSWORD = '<pick a password>'
CREATE USER <username> FOR LOGIN <username> WITH DEFAULT_SCHEMA=[dbo]
EXEC sp_addrolemember @rolename='TFSEXECROLE', @membername='<username>'
À la suite de notre exemple Fabrikam, les deux commandes SQL ressemblent à l’exemple suivant :
ALTER DATABASE [Fabrikam] SET RECOVERY SIMPLE;
USE [Foo]
CREATE LOGIN fabrikam WITH PASSWORD = 'fabrikampassword'
CREATE USER fabrikam FOR LOGIN fabrikam WITH DEFAULT_SCHEMA=[dbo]
EXEC sp_addrolemember @rolename='TFSEXECROLE', @membername='fabrikam'
Remarque
Activez SQL Server et Authentification Windows mode dans SQL Server Management Studio sur la machine virtuelle. Si vous n’activez pas le mode d’authentification, la migration échoue.
Configurer le fichier de spécification de migration pour cibler la machine virtuelle
Mettez à jour le fichier de spécification de migration pour inclure des informations sur la connexion à l’instance SQL Server. Ouvrez votre fichier de spécification de migration et effectuez les mises à jour suivantes.
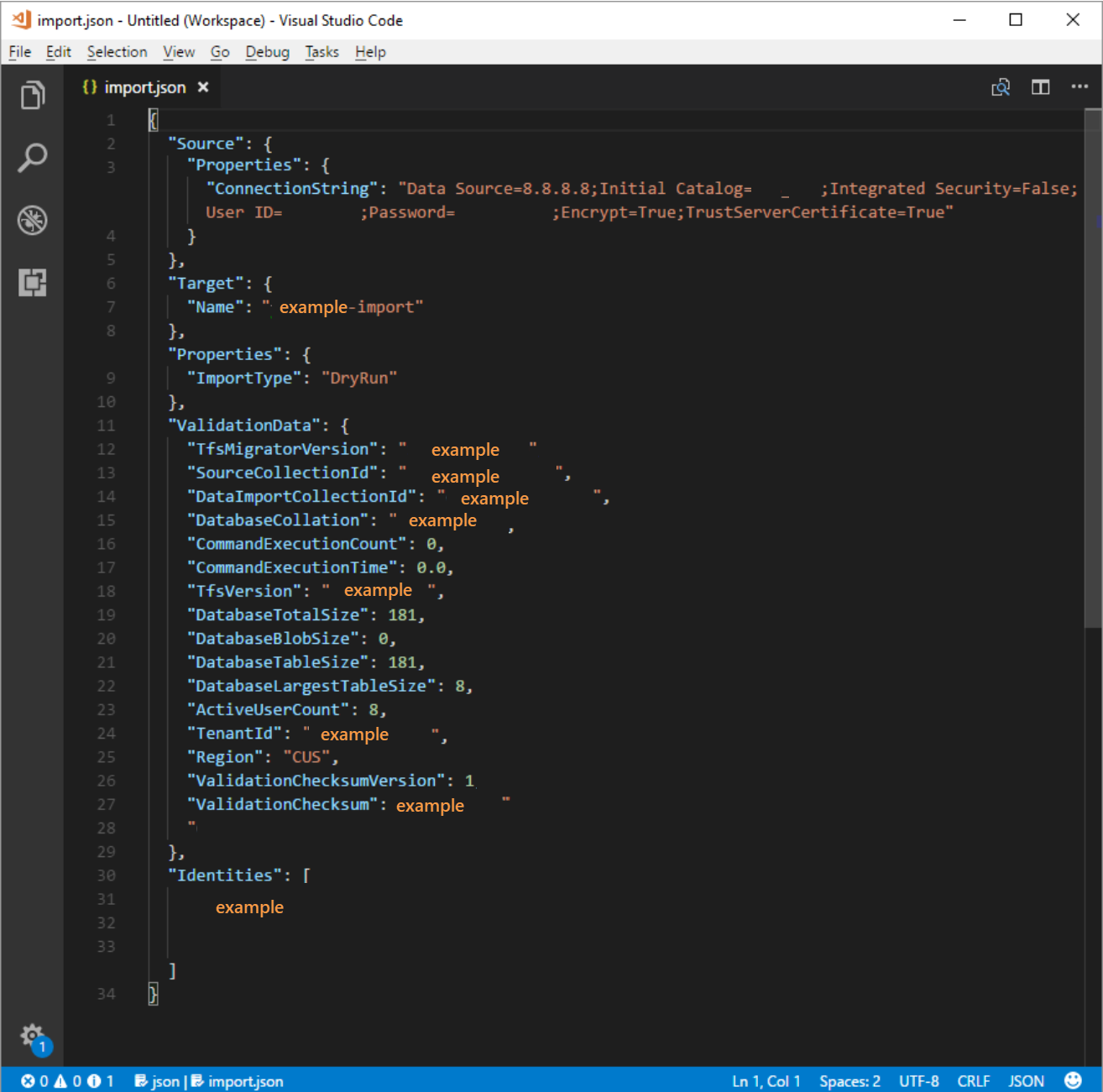
Supprimez le paramètre DACPAC de l’objet fichiers sources.
La spécification de migration avant la modification est affichée dans le code suivant.

La spécification de migration après la modification s’affiche dans le code suivant.

Renseignez les paramètres requis et ajoutez l’objet de propriétés suivant dans votre objet source dans le fichier de spécification.
"Properties": { "ConnectionString": "Data Source={SQL Azure VM Public IP};Initial Catalog={Database Name};Integrated Security=False;User ID={SQL Login Username};Password={SQL Login Password};Encrypt=True;TrustServerCertificate=True" }
Après avoir appliqué les modifications, la spécification de migration ressemble à l’exemple suivant.
Votre spécification de migration est maintenant configurée pour utiliser une machine virtuelle SQL Azure pour la migration. Passez au reste des étapes de préparation à la migration vers Azure DevOps Services. Une fois la migration terminée, veillez à supprimer la connexion SQL ou à faire pivoter le mot de passe. Microsoft ne conserve pas les informations de connexion une fois la migration terminée.
Étape 3 : Charger le fichier DACPAC
Remarque
Si vous utilisez la méthode de machine virtuelle SQL Azure, vous devez fournir uniquement la chaîne de connexion. Vous n’avez pas besoin de charger des fichiers et vous pouvez ignorer cette étape.
Votre DACPAC doit être placé dans un conteneur de stockage Azure, qui peut être un conteneur existant ou un conteneur créé spécifiquement pour votre effort de migration. Il est important de s’assurer que votre conteneur est créé dans les emplacements géographiques appropriés.
Azure DevOps Services est disponible dans plusieurs emplacements géographiques. Lorsque vous importez ces emplacements, il est essentiel de placer vos données correctement pour vous assurer que la migration peut démarrer correctement. Vos données doivent être placées dans le même emplacement géographique vers lequel vous importez. Le fait de placer les données partout ailleurs entraîne l’impossibilité de démarrer la migration. Le tableau suivant répertorie les emplacements géographiques acceptables pour la création de votre compte de stockage et le chargement de vos données.
| Emplacement géographique de la migration souhaité | Emplacement géographique du compte de stockage |
|---|---|
| États-Unis central | États-Unis central |
| Europe de l’Ouest | Europe de l’Ouest |
| Royaume-Uni | Royaume-Uni Sud |
| Australie Est | Australie Est |
| Brésil Sud | Brésil Sud |
| Sud de l’Inde | Sud de l’Inde |
| Centre du Canada | Centre du Canada |
| Asie-Pacifique (Singapour) | Asie-Pacifique (Singapour) |
Bien qu’Azure DevOps Services soit disponible dans plusieurs emplacements géographiques aux États-Unis, seul l’emplacement central États-Unis accepte de nouveaux services Azure DevOps. Vous ne pouvez pas migrer vos données vers d’autres emplacements Azure américains pour l’instant.
Créez un conteneur d’objets blob à partir de la Portail Azure. Après avoir créé le conteneur, chargez le fichier DACPAC Collection.
Une fois la migration terminée, supprimez le conteneur d’objets blob et le compte de stockage associé à des outils tels qu’AzCopy ou n’importe quel autre outil d’Explorateur stockage Azure, comme Explorateur Stockage Azure.
Remarque
Si votre fichier DACPAC dépasse 10 Go, nous vous recommandons d’utiliser AzCopy, car il prend en charge le téléversement multithread pour accélérer le processus.
Étape 4 : Générer un jeton SAS
Un jeton de signature d’accès partagé (SAP) fournit un accès délégué aux ressources d’un compte de stockage. Le jeton vous permet de donner à Microsoft le niveau de privilège le plus bas requis pour accéder à vos données pour l’exécution de la migration.
Vous pouvez générer des jetons SAP à l’aide de la Portail Azure. À partir d’un point de vue de sécurité, nous vous recommandons d’effectuer les tâches suivantes :
- Sélectionnez uniquement Lecture et Liste en tant qu’autorisations pour votre jeton SAP. Aucune autre autorisation n’est requise.
- Définissez une heure d’expiration pas plus de sept jours dans le futur.
- Restreindre l’accès aux adresses IP Azure DevOps Services uniquement.
- Traitez la clé SAP comme un secret. Ne laissez pas la clé dans un emplacement non sécurisé, car elle accorde l’accès en lecture et liste aux données stockées dans le conteneur.
Étape 5 : Terminer la spécification de migration
Plus haut dans le processus, vous avez partiellement rempli le fichier de spécification de migration, appelé migration.json. À ce stade, vous avez suffisamment d’informations pour terminer tous les champs restants, à l’exception du type de migration. Le type de migration est abordé plus loin, dans la section migration.
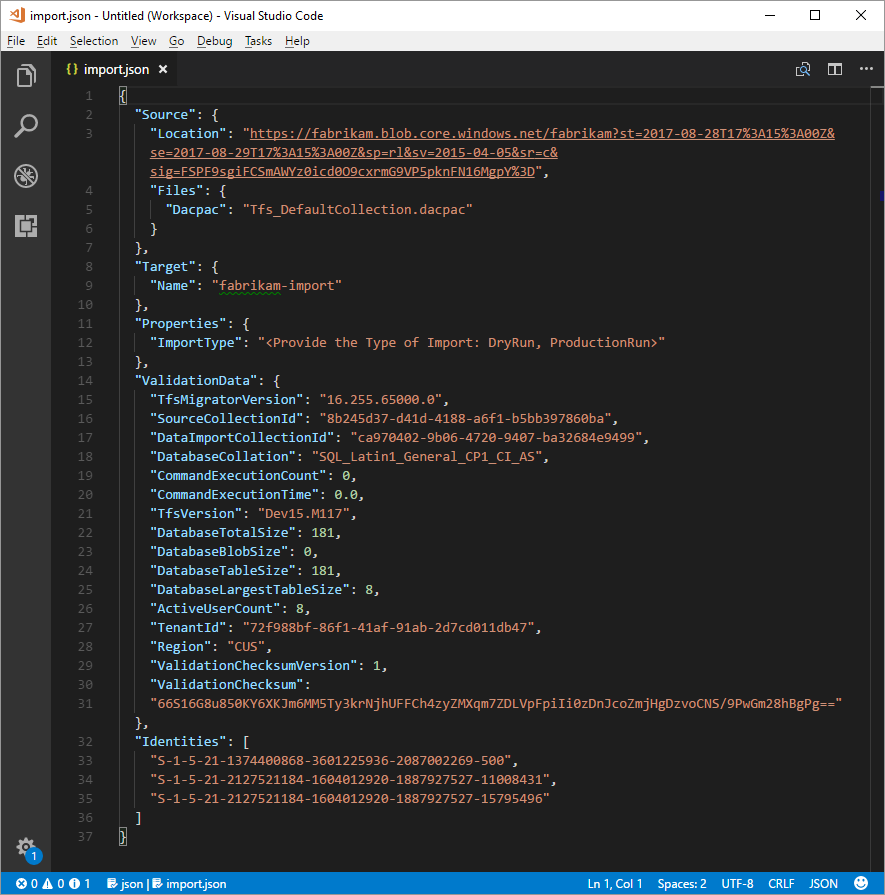
Dans le fichier de spécification migration.json , sous Source, renseignez les champs suivants.
- Emplacement : collez la clé SAP que vous avez générée à partir du script, puis copiée à l’étape précédente.
- Dacpac : vérifiez que le fichier, y compris l’extension de fichier .dacpac , porte le même nom que le fichier DACPAC que vous avez chargé sur le compte de stockage.
Le fichier de spécification de migration final doit ressembler à l’exemple suivant.
Déterminer le type de migration
Les importations peuvent être mises en file d’attente sous la forme d’une exécution de test (DryRun) ou d’une exécution de production (ProductionRun). Le paramètre ImportType détermine le type de migration :
- DryRun: également appelé exécution de test. Utiliser à des fins de test et de validation. Le système supprime les exécutions de test après 45 jours.
- ProductionRun : utilisez une exécution de production lorsque vous souhaitez conserver la migration résultante et utiliser l’organisation à temps plein dans Azure DevOps Services une fois la migration terminée.
Conseil
Nous vous recommandons toujours d’effectuer une migration d’exécution de test en premier.
Organisations de série de tests
Les organisations de série de tests aident les équipes à tester la migration de leurs regroupements. Avant qu’une migration de production puisse être exécutée, toutes les organisations de série de tests terminées doivent être supprimées. Toutes les organisations de série de tests ont une existence limitée et sont automatiquement supprimées après une période définie. Des informations sur la suppression de l’organisation sont incluses dans l’e-mail de réussite que vous devez recevoir une fois la migration terminée. Veillez à prendre note de cette date et à planifier en conséquence.
Les organisations de série de tests ont 45 jours avant leur suppression. Après la période spécifiée, l’organisation d’exécution de test est supprimée. Vous pouvez répéter les importations d’exécution de test autant de fois que nécessaire avant d’effectuer une migration de production.
Supprimer des séries de tests
Supprimez les exécutions de test précédentes avant de tenter une nouvelle exécution. Lorsque votre équipe est prête à effectuer une migration de production, vous devez supprimer manuellement l’organisation d’exécution de test. Avant de pouvoir exécuter une deuxième migration d’exécution de test ou la migration de production finale, veillez à supprimer les organisations Azure DevOps Services précédentes que vous avez créées lors d’une exécution de test précédente. Pour plus d’informations, consultez Supprimer l’organisation.
Conseil
Des informations facultatives pour aider un utilisateur à réussir la migration de l’exécution de testAny qui suit le premier devrait prendre plus de temps, étant donné le temps supplémentaire nécessaire pour nettoyer les ressources des exécutions de test précédentes.
La disponibilité d’un nom organization après la suppression ou le changement de nom peut prendre jusqu’à une heure. Pour plus d’informations, consultez l’article Des tâches post-migration.
Si vous rencontrez des problèmes de migration, consultez Résoudre les erreurs de migration et de migration.
Exécuter une migration
Votre équipe est maintenant prête à commencer le processus d’exécution d’une migration. Nous vous recommandons de commencer avec une migration réussie d’exécution de test avant de tenter une migration d’exécution de production. Avec les importations d’exécution de test, vous pouvez voir à l’avance l’apparence d’une migration, identifier les problèmes potentiels et acquérir de l’expérience avant de vous diriger vers votre exécution de production.
Remarque
- Si vous devez répéter une migration en production terminée pour une collection, par exemple en cas de retour en arrière (rollback), contactez le support client d’Azure DevOps Services avant de mettre en file d’attente une autre migration.
- Les administrateurs Azure peuvent empêcher les utilisateurs de créer des organisations Azure DevOps. Si la stratégie de locataire Microsoft Entra est activée, votre migration échoue. Avant de commencer, vérifiez que la stratégie n’est pas définie ou qu’il existe une exception pour l’utilisateur qui effectue la migration. Pour plus d’informations, consultez Restreindre la création de l’organisation via la stratégie de locataire Microsoft Entra.
- Azure DevOps Services ne prend pas en charge les stratégies de rétention par pipeline et elles ne sont pas transmises à la version hébergée.
Considérations relatives aux plans de restauration
Une préoccupation courante pour les équipes effectuant une dernière exécution de production est leur plan de restauration, si quelque chose ne va pas avec la migration. Nous vous recommandons vivement d’effectuer une série de tests pour vous assurer que vous pouvez tester les paramètres de migration que vous fournissez à l’outil de migration de données pour Azure DevOps.
La restauration pour la dernière exécution de production est assez simple. Avant de mettre en file d’attente la migration, détachez la collection de projets d’équipe d’Azure DevOps Server, ce qui le rend indisponible aux membres de votre équipe. Si, pour une raison quelconque, vous devez restaurer l’exécution de production et remettre le serveur local en ligne pour les membres de votre équipe, vous pouvez le faire. Joignez la collection de projets d’équipe localement et informez votre équipe qu’elle continue de fonctionner normalement pendant que votre équipe se regroupe pour comprendre les défaillances potentielles.
Vous pouvez ensuite contacter le support technique Azure DevOps Services pour obtenir de l’aide sur la cause de l’échec si vous ne pouvez pas déterminer la cause. Pour plus d’informations, consultez l’article résolution des problèmes. Les tickets de support client peuvent être ouverts à partir de la page https://aka.ms/AzureDevOpsImportSupportsuivante. Si le problème nécessite l’intervention des ingénieurs du groupe produit, ces cas sont traités pendant les heures ouvrées.
Détachez votre collection de projets d’équipe d’Azure DevOps Server pour la préparer à la migration.
Avant de générer une sauvegarde de votre base de données SQL, vous devez complètement détacher la collection d’Azure DevOps Server (et non de SQL) à l’aide de l’outil de migration des données. Le processus de détachement dans Azure DevOps Server transfère les informations d’identité des utilisateurs stockées en dehors de la base de données de la collection, ce qui la rend portable pour être déplacée vers un nouveau serveur ou, dans le cas présent, vers Azure DevOps Services.
Le détachement d’une collection est facilement effectué à partir de la console d’administration du serveur Azure DevOps sur votre instance Azure DevOps Server. Pour plus d’informations, consultez Déplacer la collection de projets, détacher la collection.
Mettre en file d’attente la migration
Important
Avant de continuer, assurez-vous que votre collection a été détachée avant de générer un fichier DACPAC ou de télécharger la base de données de la collection vers une machine virtuelle SQL Azure. Si vous n’effectuez pas cette étape, la migration échoue. Si votre migration échoue, consultez Résoudre les erreurs de migration.
Démarrez une migration à l’aide de la commande d’importation de l’outil de migration de données. La commande d’importation prend un fichier de spécification de migration comme entrée. Il analyse le fichier pour s’assurer que les valeurs fournies sont valides et, si elle réussit, elle met en file d’attente une migration vers Azure DevOps Services. La commande d’importation nécessite une connexion internet, mais pas* une connexion à votre instance Azure DevOps Server.
Pour commencer, ouvrez une fenêtre d’invite de commandes et remplacez les répertoires par le chemin d’accès à l’outil de migration de données. Nous vous recommandons de consulter le texte d’aide fourni avec l’outil. Exécutez la commande suivante pour voir les conseils et l’aide pour la commande d’importation :
Migrator import /help
La commande pour mettre en file d’attente une migration a la structure suivante :
Migrator import /importFile:{location of migration specification file}
L’exemple suivant montre une commande d’importation terminée :
Migrator import /importFile:C:\DataMigrationToolFiles\migration.json
Une fois la validation terminée, connectez-vous à Microsoft Entra ID avec une identité membre du même locataire Microsoft Entra que le fichier journal de mappage d’identité a été créé. L’utilisateur connecté est le propriétaire de l’organisation importée.
Remarque
Chaque locataire Microsoft Entra est limité à cinq importations par période de 24 heures. Seules les importations mises en file d’attente sont comptabilisées par rapport à cette limite.
Lorsque votre équipe lance une migration, une notification par e-mail est envoyée à l’utilisateur qui a mis en file d’attente la migration. Environ 5 à 10 minutes après qu’elle met en file d’attente la migration, votre équipe peut accéder à l’organisation pour vérifier l’état. Une fois la migration terminée, votre équipe est dirigée vers la connexion et une notification par e-mail est envoyée au propriétaire d’organisation.
L’outil de migration de données signale les erreurs que vous devez corriger avant la migration. Cet article décrit les avertissements et erreurs les plus courants que vous pouvez recevoir lorsque vous préparez la migration. Après avoir corrigé chaque erreur, réexécutez la commande de validation de migration pour vérifier la résolution.