Utiliser Apache Hive comme un outil d’extraction, de transformation et de chargement (ETL)
En règle générale, vous devez nettoyer et transformer les données entrantes avant de les charger dans une destination appropriée à des fins d’analytique. Les opérations d’extraction, de transformation et de chargement (ETL) sont utilisées pour préparer les données et les charger dans une destination de données. Apache Hive sur HDInsight peut lire les données non structurées, traiter les données en fonction des besoins, puis charger les données dans un entrepôt de données relationnelles pour les systèmes de support de décision (DSS). Dans cette approche, les données sont extraites de la source. Ensuite, elles sont placées dans un stockage adaptable, tel qu’Azure Data Lake Storage ou des objets blob Stockage Azure. Les données sont ensuite transformées à l’aide d’une séquence de requêtes Hive. Elles passent ensuite en préproduction dans Hive en vue de leur chargement en masse dans le magasin de données de destination.
Cas d’usage et vue d’ensemble du modèle
L’illustration suivante montre une vue d’ensemble du modèle et du cas d’usage pour l’automatisation du processus ETL. Les données en entrée sont transformées afin de générer la sortie appropriée. Au cours de cette transformation, les données changent de forme, de type de données et même de langue. Les processus ETL peuvent effectuer un conversion du système métrique au système impérial, modifier le fuseau horaire et améliorer la précision afin d’obtenir un alignement correct avec les données existantes dans la destination. Les processus ETL peuvent également combiner les nouvelles données avec des données existantes pour avoir des rapports à jour ou afin de fournir de nouveaux insights sur les données existantes. Les applications telles que les services et outils de reporting peuvent ensuite consommer ces données dans le format souhaité.
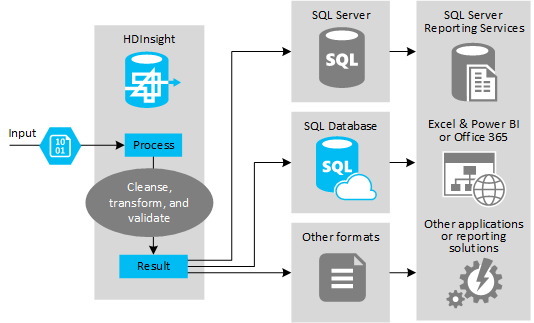
Hadoop est généralement utilisé dans les processus ETL qui importent un nombre important de fichiers texte (tels que des fichiers CSV) ou un petit nombre (changeant fréquemment) de fichiers texte, ou les deux. Hive est un excellent outil pour préparer les données avant leur chargement dans la destination des données. Hive vous permet de créer un schéma du fichier CSV et d’utiliser un langage de type SQL pour générer des programmes MapReduce qui interagissent avec les données.
Voici les étapes classiques lors de l’utilisation de Hive dans le cadre des processus ETL :
Chargez des données dans Azure Data Lake Storage ou Stockage Blob Azure.
Créez une base de données du magasin de métadonnées (à l’aide d’Azure SQL Database) pour une utilisation par Hive lors du stockage de vos schémas.
Créez un cluster HDInsight et connectez le magasin de données.
Définissez le schéma à appliquer au moment de la lecture des données dans le magasin de données :
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Transformez les données et chargez-les dans la destination. Il existe plusieurs manières d’utiliser Hive lors de la transformation et du chargement :
- Interrogez et préparez des données à l’aide de Hive et enregistrez-les au format CSV dans Azure Data Lake Storage ou Stockage Blob Azure. Utilisez ensuite un outil tel que SSIS (SQL Server Integration Services) pour acquérir ces fichiers CSV et charger les données dans une base de données relationnelle de destination telle que SQL Server.
- Interrogez les données directement à partir d’Excel ou C# à l’aide du pilote ODBC Hive.
- Utilisez Apache Sqoop pour lire les fichiers CSV plats préparés et les charger dans la base de données relationnelle de destination.
Sources de données
Les sources de données sont en général des données externes qui peuvent être mises en correspondance avec les données existantes dans votre magasin de données, par exemple :
- Données de réseaux sociaux, fichiers journaux, capteurs et applications qui génèrent des fichiers de données.
- Jeux de données obtenus à partir des fournisseurs de données, tels que des statistiques météo ou des chiffres sur les ventes.
- Données de streaming capturées, filtrées et traitées via un outil ou une infrastructure appropriée.
Cibles de sortie
Vous pouvez utiliser Hive pour générer des données dans différents types de cibles, notamment :
- Une base de données relationnelle, telle que SQL Server ou Azure SQL Database.
- Un entrepôt de données, tel qu’Azure Synapse Analytics.
- Excel.
- Stockage Table et Blob Azure.
- Applications ou services qui requièrent de traiter les données dans un format spécifique, ou en tant que fichiers contenant des types spécifiques de structure d’informations.
- Une banque de documents JSON comme Azure Cosmos DB.
Considérations
Le modèle ETL est généralement utilisé lorsque vous souhaitez :
* Charger les données de flux ou de grands volumes de données non structurées ou semi-structurées provenant de sources externes dans une base de données ou un système d’information existant.
* Nettoyer, transformer et valider les données avant de les charger, par exemple en utilisant plusieurs transformations via le cluster.
* Générer des rapports et des visualisations régulièrement mis à jour. Par exemple, si le rapport est trop long à générer pendant la journée, vous pouvez planifier son exécution pendant la nuit. Pour exécuter automatiquement une requête Hive, vous pouvez utiliser Azure Logic Apps et PowerShell.
Si la cible des données n’est pas une base de données, vous pouvez générer un fichier au format approprié au sein de la requête, par exemple un fichier CSV. Ce fichier peut ensuite être importé dans Excel ou Power BI.
Si vous avez besoin d’exécuter plusieurs opérations sur les données dans le cadre du processus ETL, réfléchissez à la façon de les gérer. Quand les opérations sont contrôlées par un programme externe, plutôt que comme un workflow au sein de la solution, décidez si certaines opérations peuvent être exécutées en parallèle et détectez à quel moment chaque tâche se termine. L’utilisation d’un mécanisme de flux de travail tel qu’Oozie dans Hadoop peut être plus facile que d’orchestrer une séquence d’opérations à l’aide de scripts externes ou de programmes personnalisés.