Rendre un pipeline d’analytique de données opérationnel
Les pipelines de données sont à la base de nombreuses solutions d’analytique de données. Comme leur nom l’indique, ils partent de données brutes, les nettoient et les réorganisent en fonction des besoins, puis effectuent en général des calculs ou des agrégations avant de stocker les données traitées. Celles-ci sont consommées par des clients, des rapports ou des API. Un pipeline de données doit fournir des résultats reproductibles, à intervalles réguliers ou bien en cas de déclenchement par de nouvelles données.
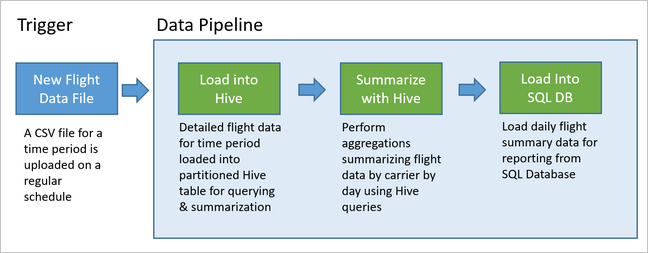
Cet article explique comment opérationnaliser des pipelines de données pour les rendre reproductibles, avec Oozie sur des clusters HDInsight Hadoop. L’exemple de scénario décrit un pipeline de données qui prépare et traite des séries chronologiques de vols de différentes compagnies aériennes.
Dans le scénario suivant, les données d’entrée sont un fichier plat contenant un lot de données de vol sur un mois. Celles-ci comprennent des informations telles que l’aéroport d’origine et de destination, la distance parcourue en miles, l’heure de départ et d’arrivée, etc. L’objectif de ce pipeline est de résumer les performances quotidiennes des compagnies aériennes, chacune d’entre elle étant associée à une ligne par jour, avec les retards moyens au départ et à l’arrivée en minutes, et la distance totale en miles parcourue dans la journée.
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10,142229 | 7,862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9,435449 | 5,482143 | 572289 |
| 2017 | 1 | 3 | DL | 6,935409 | -2,1893024 | 1909696 |
L’exemple de pipeline attend les données de vol d’une nouvelle période, puis stocke ces informations de vol détaillées dans l’entrepôt de données Apache Hive à des fins d’analyse à long terme. Il crée également un jeu de données beaucoup plus petit, qui résume simplement les données de vol quotidiennes. Ce résumé est envoyé à une base de données SQL pour générer des rapports, par exemple, pour un site web.
Le diagramme suivant illustre l’exemple de pipeline.
Vue d’ensemble de la solution Apache Oozie
Ce pipeline utilise Apache Oozie sur un cluster HDInsight Hadoop.
Oozie décrit ses pipelines en termes d’actions, de workflows et de coordinateurs. Les actions déterminent le travail à effectuer, par exemple, l’exécution d’une requête Hive. Les workflows définissent la séquence d’actions. Les coordinateurs définissent l’échéancier d’exécution du workflow. Les coordinateurs peuvent également attendre la disponibilité de nouvelles données avant de lancer une instance de workflow.
Le diagramme suivant illustre la conception générale de cet exemple de pipeline Oozie.

Approvisionner des ressources Azure
Ce pipeline a besoin d’une base de données Azure SQL Database et d’un cluster HDInsight Hadoop au même emplacement. La base de données Azure SQL Database stocke à la fois les données résumées produites par le pipeline et le magasin de métadonnées Oozie.
Provisionner Azure SQL Database
Créez une instance d’Azure SQL Database. Consultez Démarrage rapide : Créer et interroger une base de données unique dans Azure SQL Database à l’aide du Portail Microsoft Azure.
Pour vous assurer que votre cluster HDInsight pourra accéder à la base de données Azure SQL Database connectée, configurez les règles de pare-feu Azure SQL Database pour autoriser les services et ressources Azure à accéder au serveur. Vous pouvez activer cette option dans le portail Azure en sélectionnant Définir le pare-feu du serveur et ON sous Autoriser les services et les ressources Azure à accéder à ce serveur pour Azure SQL Database. Pour plus d’informations, consultez Créer et gérer des règles de pare-feu IP.
Utilisez l’Éditeur de requête pour exécuter les instructions SQL suivantes afin de créer le tableau
dailyflightsqui stockera les données résumées à partir de chaque exécution du pipeline.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Votre base de données Azure SQL Database est prête.
Approvisionner un cluster Apache Hadoop
Créer un cluster Apache Hadoop avec un metastore personnalisé. Pendant la création du cluster à partir du portail, à partir de l’onglet Stockage, veillez à sélectionner votre SQL Database sous Paramètres du metastore. Pour plus d’informations sur la sélection d’un metastore, voir Sélectionner un metastore personnalisé lors de la création d’un cluster. Pour plus d’informations sur la création de clusters, consultez Prise en main de HDInsight dans Linux.
Vérifier la configuration du tunneling SSH
Pour utiliser la console Web Oozie afin d’afficher l’état de vos instances de coordinateurs et de workflows, configurez un tunnel SSH vers votre cluster HDInsight. Pour plus d’informations, consultez la page Tunnel SSH.
Notes
Vous pouvez également utiliser Chrome avec l’extension FoxyProxy pour parcourir les ressources web de votre cluster à travers le tunnel SSH. Configurez-la de façon à rediriger toutes les requêtes via l’hôte localhost sur le port 9876 du tunnel. Cette approche est compatible avec le sous-système Windows pour Linux, également connu sous le nom de Bash sous Windows 10.
Exécutez la commande suivante pour ouvrir un tunnel SSH vers votre cluster, où
CLUSTERNAMEest le nom de votre cluster :ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netVérifiez que le tunnel est opérationnel en accédant à Ambari sur votre nœud principal à l’adresse :
http://headnodehost:8080Pour accéder à la console Web Oozie à partir de ambari, accédez à Oozie>Liens rapides> [Serveur actif] > Oozie UI Web.
Configurer Hive
Télécharger des données
Téléchargez un exemple de fichier CSV contenant les données de vol sur un mois. Téléchargez son fichier zip
2017-01-FlightData.zipà partir du Référentiel GitHub HDInsight et décompressez-le vers le fichier CSV2017-01-FlightData.csv.Copiez ce fichier CSV sur le compte de Stockage Azure associé à votre cluster HDInsight et placez-le dans le dossier
/example/data/flights.Utilisez SCP pour copier les fichiers de votre ordinateur local sur le stockage local du nœud principal de votre cluster HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvUtilisez la commande ssh pour vous connecter à votre cluster. Modifiez la commande ci-dessous en remplaçant
CLUSTERNAMEpar le nom de votre cluster, puis entrez la commande :ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netÀ partir de votre session SSH, utilisez la commande HDFS pour copier le fichier depuis le stockage local du nœud principal vers Stockage Azure.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Créer des tables
Les exemples de données sont maintenant disponibles. Toutefois, le pipeline a besoin de deux tables Hive pour le traitement, l’une pour les données entrantes (rawFlights) et l’autre pour les données résumées (flights). Créez ces tables dans Ambari de la façon suivante.
Connectez-vous à Ambari en accédant à
http://headnodehost:8080.Dans la liste des services, sélectionnez Hive.

Sélectionnez Atteindre la vue près de l’étiquette Hive View 2.0.

Dans la zone de texte de requête, collez les instructions suivantes pour créer la table
rawFlights. La tablerawFlightsfournit un « schema-on-read » des fichiers CSV dans le dossier/example/data/flightsdu Stockage Azure.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Sélectionnez Exécuter pour créer la table.

Pour créer la table
flights, remplacez le texte de la zone de texte de requête par les instructions suivantes. La tableflightsest une table managée Hive qui partitionne les données chargées dessus par année, par mois et par jour du mois. Elle contiendra toutes les données des historiques de vol, avec la plus grande précision possible selon les données sources d’une ligne par vol.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Sélectionnez Exécuter pour créer la table.
Créer le workflow Oozie
Les pipelines traitent en général les données par lots sur un intervalle de temps donné. Dans ce cas, il traite les données de vol une fois par jour. Cette approche permet aux fichiers CSV d’entrée d’arriver à une fréquence quotidienne, hebdomadaire, mensuelle ou annuelle.
L’exemple de workflow traite les données de vol jour par jour, en trois grandes étapes :
- Exécutez une requête Hive pour extraire les données de la plage de dates du jour à partir du fichier CSV source représenté par la table
rawFlightset pour les insérer dans la tableflights. - Exécutez une requête Hive pour créer dynamiquement une table de mise en lots dans Hive pour la journée, contenant une copie des données de vol résumées par jour et par compagnie.
- Utilisez Apache Sqoop pour copier toutes les données de la table de mise en lots quotidienne de Hive vers la table
dailyflightsde destination dans Azure SQL Database. Sqoop lit les lignes sources des données qui se trouvent derrière la table Hive résidant dans le Stockage Azure, et les charge dans SQL Database à l’aide d’une connexion JDBC.
Ces trois étapes sont coordonnées par un workflow Oozie.
À partir de votre station de travail locale, créez un fichier appelé
job.properties. Utilisez le texte ci-dessous comme contenu de départ pour le fichier. Mettez à jour les valeurs en fonction de votre environnement. Le tableau suivant résume chacune des propriétés et indique l’emplacement des valeurs dans votre propre environnement.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Propriété Source de la valeur nameNode Chemin d’accès complet du conteneur de Stockage Azure associé à votre cluster HDInsight. jobTracker Nom d’hôte interne du nœud principal YARN de votre cluster actif. Sur la page d’accueil Ambari, sélectionnez YARN dans la liste des services, puis choisissez Gestionnaire des ressources actif. L’URI du nom d’hôte s’affiche en haut de la page. Ajoutez le port 8050. queueName Nom de la file d’attente YARN utilisée lors de la planification des actions Hive. Laissez la valeur par défaut. oozie.use.system.libpath Laissez la valeur true. appBase Chemin d’accès du sous-dossier dans le Stockage Azure où sont déployés le workflow Oozie et les fichiers associés. oozie.wf.application.path Emplacement du workflow Oozie workflow.xmlà exécuter.hiveScriptLoadPartition Chemin d’accès dans le Stockage Azure du fichier de requête Hive hive-load-flights-partition.hql.hiveScriptCreateDailyTable Chemin d’accès dans le Stockage Azure du fichier de requête Hive hive-create-daily-summary-table.hql.hiveDailyTableName Nom généré de manière dynamique à utiliser pour la table de mise en lots. hiveDataFolder Chemin d’accès dans le Stockage Azure des données contenues dans la table de mise en lots. sqlDatabaseConnectionString Chaîne de connexion, suivant la syntaxe JDBC, à votre base de données Azure SQL Database. sqlDatabaseTableName Nom de la table dans Azure SQL Database dans laquelle sont insérées les lignes résumées. Laissez la valeur dailyflights.year Composant « année » de la journée pour laquelle sont calculés les résumés de vols. Laissez la valeur actuelle. month Composant « mois » de la journée pour laquelle sont calculés les résumés de vols. Laissez la valeur actuelle. day Composant « jour du mois » de la journée pour laquelle sont calculés les résumés de vols. Laissez la valeur actuelle. À partir de votre station de travail locale, créez un fichier appelé
hive-load-flights-partition.hql. Utilisez le code ci-dessous comme contenu du fichier.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Les variables Oozie utilisent la syntaxe
${variableName}. Ces variables sont définies dans le fichierjob.properties. Oozie les remplace par les valeurs réelles au moment de l’exécution.À partir de votre station de travail locale, créez un fichier appelé
hive-create-daily-summary-table.hql. Utilisez le code ci-dessous comme contenu du fichier.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Cette requête crée une table de mise en lots qui stocke uniquement les données résumées d’une journée ; remarquez l’instruction SELECT qui calcule les retards moyens et la distance totale parcourue par compagnie et par jour. Les données insérées dans cette table sont stockées dans un emplacement connu (le chemin d’accès indiqué par la variable hiveDataFolder) afin d’être utilisables comme sources pour Sqoop à l’étape suivante.
À partir de votre station de travail locale, créez un fichier appelé
workflow.xml. Utilisez le code ci-dessous comme contenu du fichier. Les étapes ci-dessus sont exprimées en tant qu’actions distinctes dans le fichier de flux de travail Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Les deux requêtes Hive sont accessibles par leur chemin d’accès dans le stockage Azure, et les valeurs des variables restantes sont fournies par le fichier job.properties. Ce fichier configure le flux de travail pour qu’il s’exécute à la date du 3 janvier 2017.
Déployer et exécuter le workflow Oozie
Utilisez SCP à partir de votre session Bash pour déployer votre workflow Oozie (workflow.xml), les requêtes Hive (hive-load-flights-partition.hql et hive-create-daily-summary-table.hql) et la configuration de la tâche (job.properties). Dans Oozie, seul le fichier job.properties peut se trouver sur le stockage local du nœud principal. Tous les autres fichiers doivent être stockés dans HDFS, dans ce cas le Stockage Azure. L’action Sqoop utilisée par le workflow dépend d’un pilote JDBC pour communiquer avec votre base de données SQL Database ; il doit être copié du nœud principal vers HDFS.
Créez le sous-dossier
load_flights_by_daysous le chemin d’accès de l’utilisateur, dans le stockage local du nœud principal. À partir de votre session SSH ouverte, exécutez la commande suivante :mkdir load_flights_by_dayCopiez tous les fichiers du répertoire actif (les fichiers
workflow.xmletjob.properties) jusqu’au sous-dossierload_flights_by_day. À partir de votre station de travail locale, exécutez la commande suivante :scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayCopiez les fichiers du workflow dans HDFS. À partir de votre session SSH ouverte, exécutez les commandes suivantes :
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayCopiez
mssql-jdbc-7.0.0.jre8.jardu nœud principal local vers le dossier du workflow dans HDFS. Modifiez la commande si nécessaire si votre cluster contient un fichier jar différent. Modifiezworkflow.xmlsi nécessaire pour refléter un fichier jar différent. À partir de votre session SSH ouverte, exécutez la commande suivante :hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayExécutez le workflow. À partir de votre session SSH ouverte, exécutez la commande suivante :
oozie job -config job.properties -runObservez l’état à l’aide de la console Web Oozie. Dans Ambari, sélectionnez Oozie, Liens rapides, puis Console web Oozie. Sous l’onglet Tâches du workflow, sélectionnez Toutes les tâches.
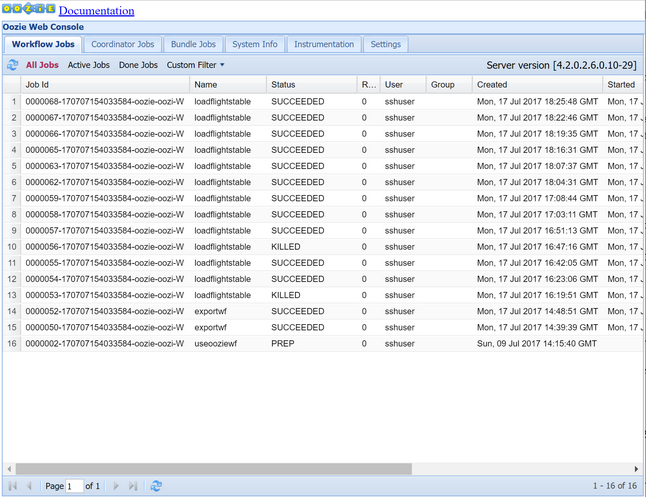
Lorsque l’état est RÉUSSI, interrogez la table de la Microsoft Azure SQL Database pour voir les lignes insérées. Sur le Portail Azure, accédez au volet de votre base de données SQL Database, sélectionnez Outils et ouvrez l’Éditeur de requêtes.
SELECT * FROM dailyflights
Maintenant que le workflow est en cours d’exécution pour le jour de test unique, vous pouvez l’encapsuler avec un coordinateur qui planifie son exécution une fois par jour.
Exécuter le workflow avec un coordinateur
Pour planifier une exécution quotidienne de ce workflow (ou tous les jours d’une plage de dates), vous pouvez utiliser un coordinateur. Un coordinateur est défini par un fichier XML, par exemple, coordinator.xml :
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Comme vous pouvez le voir, la majeure partie du coordinateur consiste en une simple transmission d’informations de configuration à l’instance de workflow. Toutefois, il existe quelques éléments importants à appeler.
Point 1 : les attributs
startetendde l’élémentcoordinator-applui-même contrôlent l’intervalle de temps pendant lequel s’exécute le coordinateur.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Un coordinateur est responsable de la planification d’actions pendant la plage de dates comprise entre
startetend, en fonction de l’intervalle spécifié par l’attributfrequency. Chaque action planifiée exécute à son tour le workflow tel qu’il est configuré. Dans la définition de coordinateur ci-dessus, le coordinateur est configuré pour exécuter des actions comprises entre le 1er janvier 2017 et le 5 janvier 2017. La fréquence est définie sur un jour par l’expression de fréquence${coord:days(1)}en Langage d’expression Oozie. En conséquence, le coordinateur planifie une action (et, par conséquent, le workflow) une fois par jour. Pour les plages de dates passées, comme dans cet exemple, l’action s’exécutera sans délai. Le début de la date à partir de laquelle une action doit s’exécuter s’appelle l’heure nominale. Par exemple, pour traiter les données du 1er janvier 2017, le coordinateur planifie une action avec une heure nominale de 2017-01-01T00:00:00 GMT.Point 2 : dans la plage de dates du workflow, l’élément
datasetindique l’endroit, dans HDFS, où rechercher les données d’une plage de dates donnée et configure la manière dont Oozie détermine si les données sont prêtes ou non pour le traitement.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Le chemin d’accès des données dans HDFS est construit dynamiquement en fonction de l’expression fournie dans l’élément
uri-template. Dans ce coordinateur, une fréquence d’un jour est également utilisée avec le jeu de données. Alors que les dates de début et de fin présentes sur l’élément de coordination contrôlent le moment où sont planifiées les actions (et définissent leur heure nominale), les valeursinitial-instanceetfrequencydu jeu de données déterminent le calcul de la date utilisée pour construire leuri-template. Dans ce cas, définissez l’instance initiale à un jour avant le début du coordinateur pour vous assurer qu’elle récupère l’équivalent du premier jour (1er janvier 2017) en données. Le calcul de la date du jeu de données s’effectue progressivement à partir de la valeur deinitial-instance(12/31/2016) par incréments de fréquence du jeu de données (00:00 jour) jusqu’à ce qu’il trouve la date la plus récente qui ne passe pas l’heure nominale définie par le coordinateur (2017-01-01T00:00:00 GMT pour la première action).L’élément
done-flagvide indique qu’Oozie détermine si les données d’entrée sont disponibles à l’heure prévue par la présence d’un répertoire ou d’un fichier. Dans ce cas, il s’agit d’un fichier CSV. S’il en existe un, Oozie suppose que les données sont prêtes et lance une instance de workflow pour le traiter. Si aucun fichier CSV n’est présent, Oozie suppose que les données ne sont pas encore prêtes et que l’exécution du flux de travail passe à l’état en attente.Point 3 : l’élément
data-inspécifie le timestamp à utiliser en particulier comme heure nominale lors du remplacement de valeurs dansuri-templatepour le jeu de données associé.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>Dans ce cas, définissez l’instance sur l’expression
${coord:current(0)}, ce qui correspond à l’utilisation de l’heure nominale de l’action planifiée à l’origine par le coordinateur. En d’autres termes, lorsque le coordinateur planifie l’exécution de l’action à la date nominale 01/01/2017, celle-ci est utilisée pour remplacer les variables YEAR (2017) et MONTH (01) dans le modèle d’URI. Dès que le modèle d’URI a été calculé pour cette instance, Oozie regarde si le répertoire ou le fichier attendu est disponible et planifie l’exécution suivante du workflow en conséquence.
Les trois points précédents se combinent pour créer une situation dans laquelle le coordinateur planifie le traitement des données sources jour après jour.
Point 1 : le coordinateur commence avec la date nominale 2017-01-01.
Point 2 : Oozie recherche les données disponibles dans
sourceDataFolder/2017-01-FlightData.csv.Point 3 : lorsque Oozie trouve ce fichier, il planifie une instance du workflow qui va traiter les données au 1er janvier 2017. Oozie continue alors le traitement pour 2017-01-02. Cette évaluation se répète jusqu’à 2017-01-05 non inclus.
Comme pour les workflows, la configuration d’un coordinateur est définie dans un fichier job.properties, qui contient un sur-ensemble des paramètres utilisés par le workflow.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Les seules propriétés nouvellement introduites dans ce fichier job.properties sont les suivantes :
| Propriété | Source de la valeur |
|---|---|
| oozie.coord.application.path | Indique l’emplacement du fichier coordinator.xml contenant le coordinateur Oozie à exécuter. |
| hiveDailyTableNamePrefix | Préfixe utilisé lors de la création dynamique du nom de la table de mise en lots. |
| hiveDataFolderPrefix | Préfixe du chemin d’accès où seront stockées toutes les tables de mise en lots. |
Déployer et exécuter le coordinateur Oozie
Pour exécuter le pipeline avec un coordinateur, procédez de la même manière que pour le workflow, mais en travaillant à partir d’un dossier se trouvant un niveau au-dessus du dossier qui contient votre workflow. Cette convention de dossier sépare les coordinateurs des workflows sur le disque, ce qui permet d’associer un coordinateur avec différents workflows enfants.
Utilisez SCP sur votre ordinateur local pour copier les fichiers du coordinateur sur le stockage local du nœud principal de votre cluster.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Établissez une connexion SSH vers votre nœud principal.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netCopiez les fichiers du coordinateur dans HDFS.
hdfs dfs -put ./* /oozie/Exécutez le coordinateur.
oozie job -config job.properties -runVérifier l’état à l’aide de la console Web Oozie, cette fois en sélectionnant l’onglet Tâches du coordinateur, puis Toutes les tâches.

Sélectionnez une instance de coordinateur pour afficher la liste des actions planifiées. Dans ce cas, vous devriez voir quatre actions dont la période nominale se trouve dans la plage entre le 1er janvier 2017 et le 4 janvier 2017.

Chacune des actions de cette liste correspond à une instance du workflow qui traite l’équivalent d’une journée de données, dont le début est indiqué par l’heure nominale.