Architectures de continuité de l’activité Azure HDInsight
Cet article présente quelques exemples d’architectures de continuité d’activité que vous pouvez envisager pour Azure HDInsight. La tolérance vis à vis d’une limitation de fonctionnalités au cours d’une défaillance majeure est une appréciation qui appartient à l’entreprise et qui varie d’une application à une autre. Ainsi, l’indisponibilité totale ou partielle de certaines applications avec des limitations de fonctionnalités ou des retards de traitements sur une période donnée pourra-t-elle être jugée acceptable. Pour d’autres applications, la moindre limitation de fonctionnalités sera inacceptable.
Notes
Les architectures présentées dans cet article ne sont pas exhaustives. Vous avez tout intérêt à concevoir vos propres architectures après avoir déterminé objectivement vos attentes en matière de continuité d’activité, de complexité opérationnelle et de coût de possession.
Apache Hive et Interactive Query
Hive Replication V2 est la solution de continuité d’activité recommandée pour les clusters HDInsight Hive et Interactive Query. Les parties persistantes d’un cluster Hive autonome qui ont besoin d’être répliquées sont la couche de stockage et le metastore Hive. Dans un scénario multi-utilisateur avec le Pack Sécurité Entreprise, les clusters Hive ont besoin de Microsoft Entra Domain Services et du metastore Ranger.
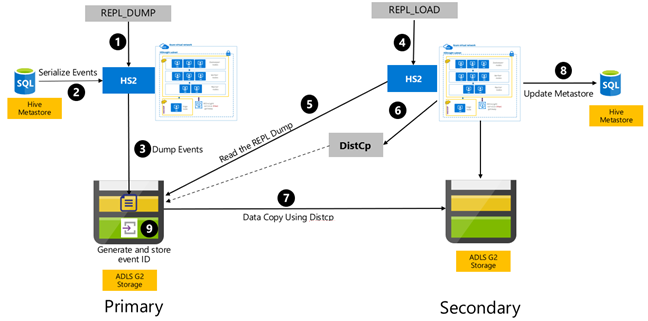
La réplication basée sur les événements Hive est configurée entre le cluster principal et le cluster secondaire. Elle se compose des deux phases distinctes que sont l’amorçage et les exécutions incrémentielles :
L’amorçage réplique l’intégralité de l’entrepôt Hive, notamment les informations du metastore Hive du cluster principal vers le cluster secondaire.
Les exécutions incrémentielles sont automatisées sur le cluster principal et les événements générés pendant les exécutions incrémentielles sont lus sur le cluster secondaire. Le cluster secondaire récupère les événements générés par le cluster principal, assurant ainsi la cohérence du cluster secondaire par rapport aux événements du cluster principal à l’issue de la réplication.
Le cluster secondaire n’est nécessaire qu’au moment de la réplication pour exécuter la copie distribuée, DistCp, mais le stockage et les metastores doivent être persistants. Vous pourriez choisir de mettre en service un cluster secondaire scripté à la demande avant la réplication, d’exécuter le script de réplication sur celui-ci, puis de le supprimer à l’issue de la réplication.
Le cluster secondaire est généralement en lecture seule. Vous pouvez faire en sorte que le cluster secondaire soit accessible en lecture-écriture, mais cela ajoute en complexité, puisque les modifications apportées au cluster secondaire doivent être répliquées sur le cluster principal.
RTO et RPO de la réplication basée sur les événements Hive
RPO : la perte de données est limitée au dernier événement de réplication incrémentielle réussi du cluster principal vers le cluster secondaire.
RTO : délai entre la défaillance et la reprise des transactions en amont et en aval avec le cluster secondaire.
Architectures Apache Hive et Interactive Query
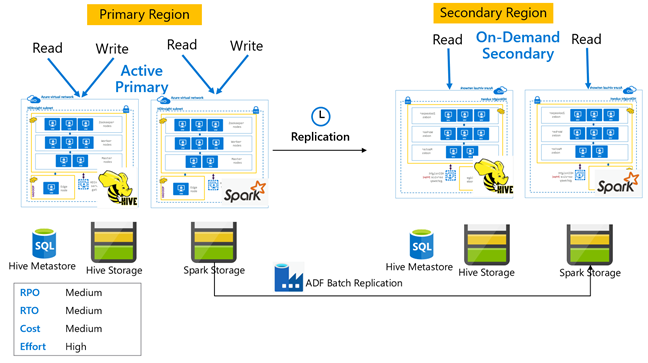
Région primaire active Hive et région secondaire à la demande
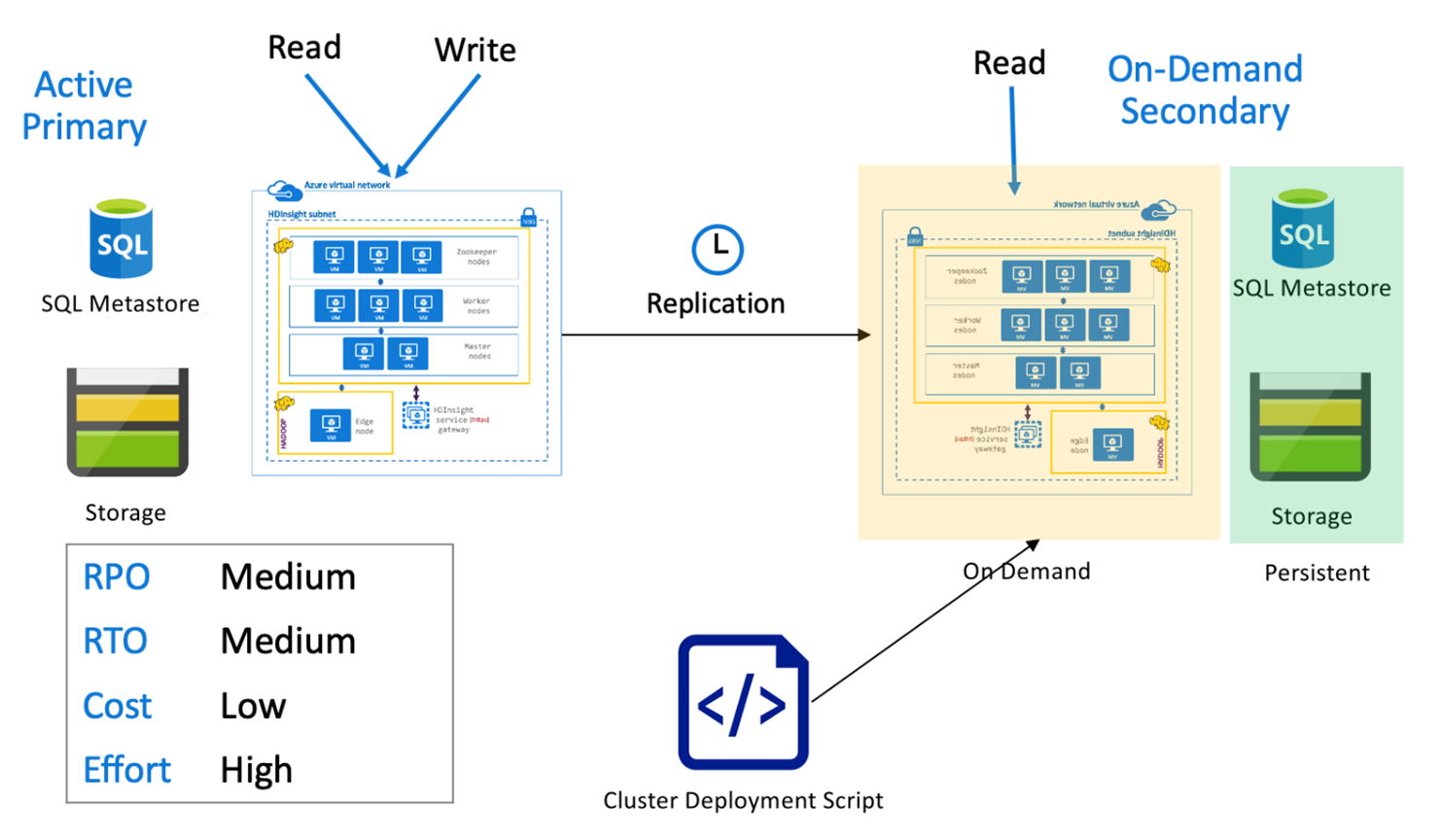
Dans une architecture constituée d’une région primaire active et d’une région secondaire à la demande, les applications écrivent dans la région primaire active, alors qu’aucun cluster n’est provisionné dans la région secondaire pendant les opérations normales. Le metastore SQL et le stockage de la région secondaire sont persistants, tandis que le cluster HDInsight n’est scripté et déployé à la demande qu’avant les exécutions planifiées de la réplication Hive.
Région primaire active Hive et région secondaire de secours
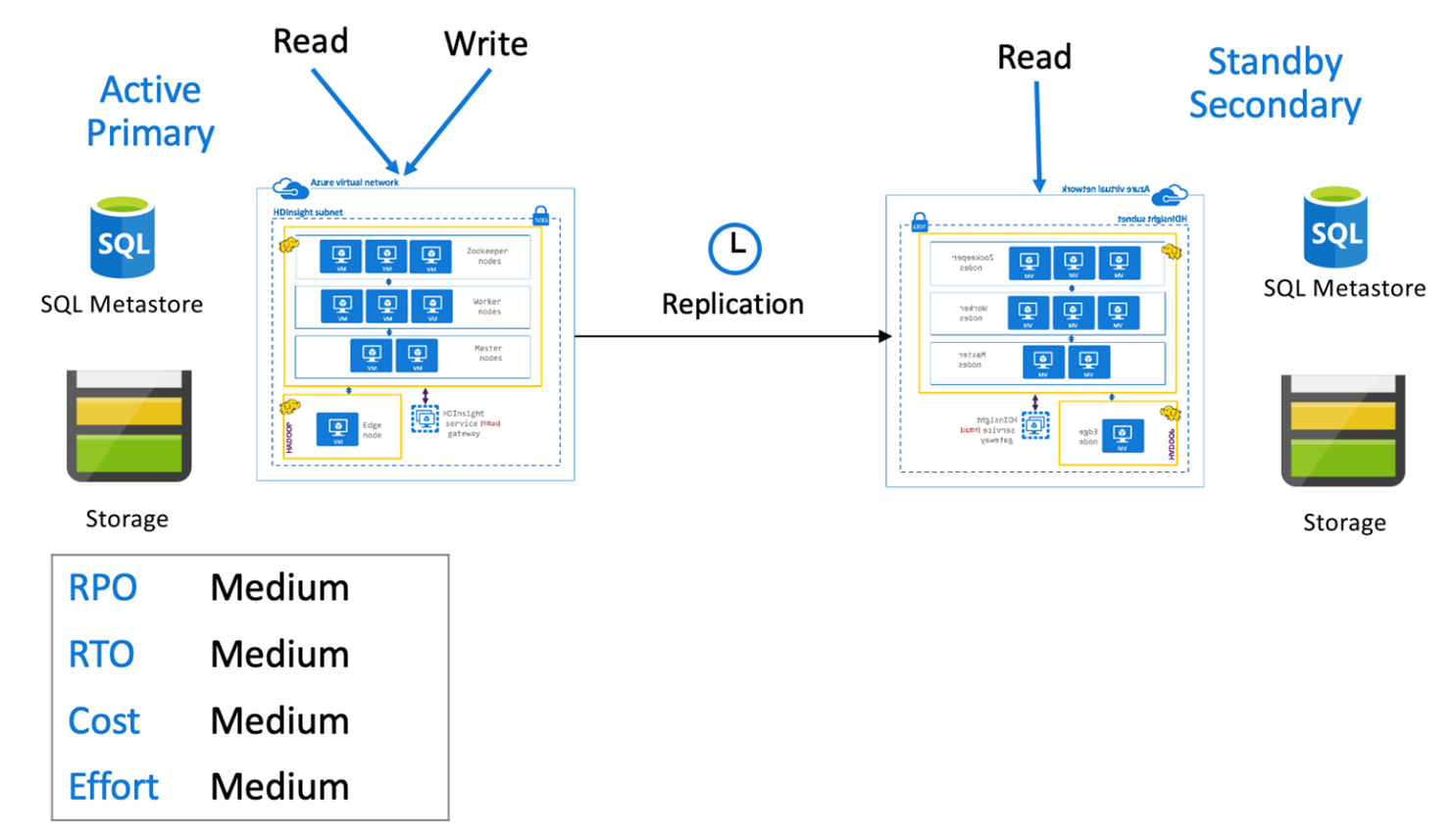
Dans une architecture constituée d’une région primaire active et d’une région secondaire de secours, les applications écrivent dans la région primaire active, tandis qu’un cluster secondaire de secours en mode lecture seule ayant fait l’objet d’un scale-down s’exécute pendant les opérations normales. Pendant les opérations normales, vous pouvez choisir de décharger certaines opérations de lecture sur la région secondaire.
Pour plus d’informations sur la réplication Hive et des exemples de code, consultez Réplication Apache Hive dans les clusters Azure HDInsight
Apache Spark
Les charges de travail Spark peuvent ou non faire appel à un composant Hive. Pour permettre aux charges de travail Spark SQL de lire et écrire des données à partir de Hive, les clusters HDInsight Spark partagent les metastores personnalisés Hive des clusters Hive/Interactive Query d’une même région. Dans les scénarios de ce type, la réplication inter-région des charges de travail Spark doit également accompagner la réplication des metastores et du stockage Hive. Les scénarios de basculement présentés dans cette section s’appliquent à :
- Spark SQL sur les tables ACID avec la configuration Hive Warehouse Connector (HWC) et un cluster HDInsight Interactive Query.
- Charge de travail SQL Spark sur les tables non ACID avec un cluster HDInsight Hadoop.
Pour les scénarios où Spark fonctionne en mode autonome, les données organisées et les fichiers jar Spark stockés (pour les travaux Livy) doivent être répliqués régulièrement de la région primaire vers la région secondaire en utilisant DistCP dans Azure Data Factory.
Nous vous recommandons d’utiliser des systèmes de gestion de version pour stocker les notebooks et bibliothèques Spark où ils peuvent être facilement déployés sur le cluster principal ou le cluster secondaire. Veillez à ce que les solutions basées ou non sur des notebooks sont prêtes à charger les bons montages de données dans l’espace de travail principal ou secondaire.
S’il existe des bibliothèques propres aux clients qui vont au-delà de ce que HDInsight fournit en mode natif, elles doivent être suivies et chargées périodiquement sur le cluster secondaire de secours.
RPO et RTO de la réplication Apache Spark
RPO : la perte de données est limitée à la dernière réplication incrémentielle réussie (Spark et Hive) du cluster principal vers le cluster secondaire.
RTO : délai entre la défaillance et la reprise des transactions en amont et en aval avec le cluster secondaire.
Architectures Apache Spark
Région primaire active Spark et région secondaire à la demande
Les applications lisent et écrivent sur les clusters Spark et Hive de la région primaire, alors qu’aucun cluster n’est provisionné dans la région secondaire pendant les opérations normales. Le metastore SQL, le stockage Hive et le stockage Spark sont persistants dans la région secondaire. Les clusters Spark et Hive sont scriptés et déployés à la demande. La réplication Hive est utilisée pour répliquer le stockage Hive et les metastores Hive, tandis que DistCP d’Azure Data Factory peut être utilisé pour copier le stockage Spark autonome. Les clusters Hive doivent être déployés avant chaque réplication Hive en raison du calcul DistCp de dépendance.
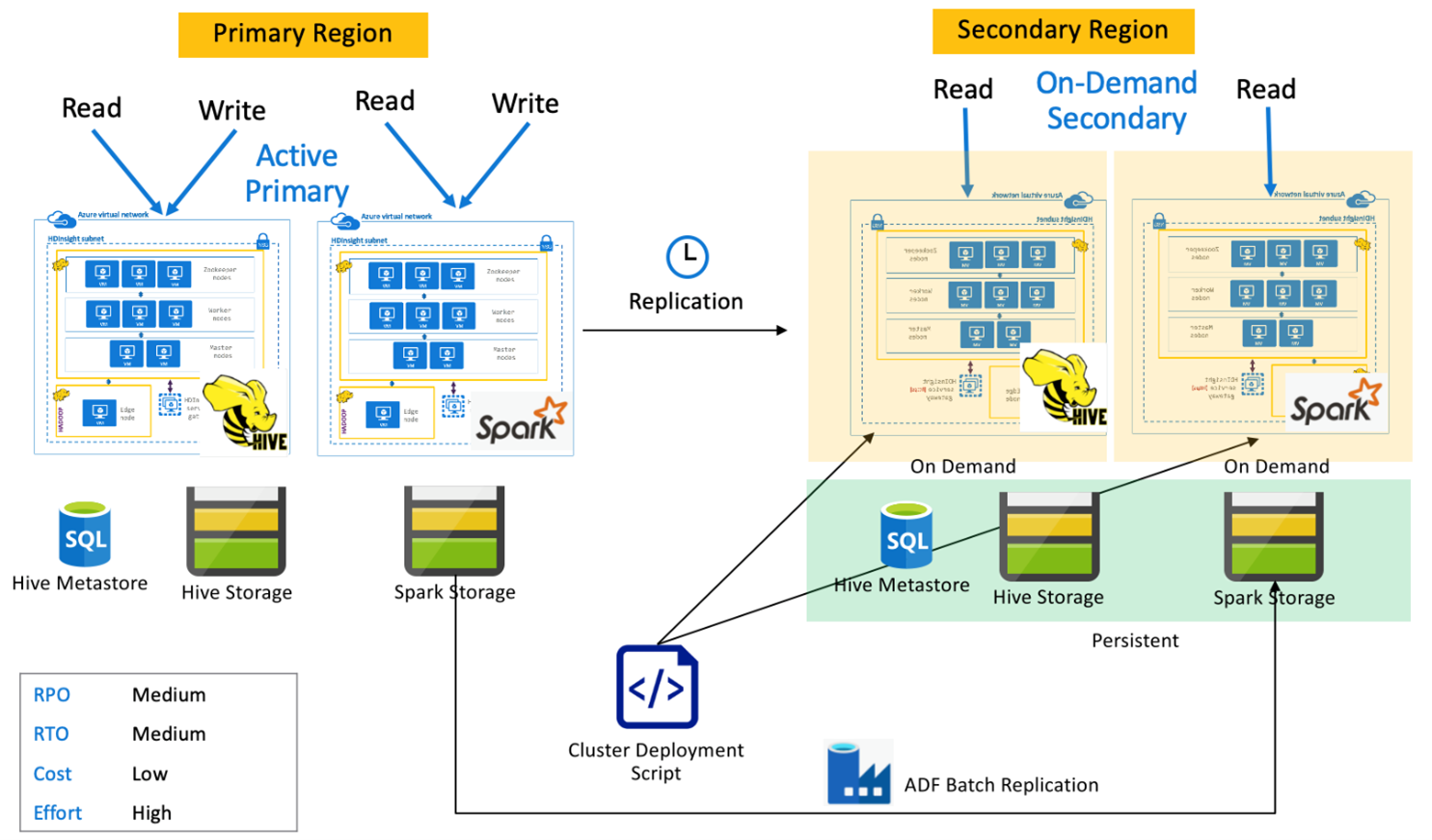
Région primaire active et région secondaire de secours Spark
Les applications lisent et écrivent sur les clusters Spark et Hive de la région primaire, alors que les clusters Hive et Spark de secours en mode lecture seule ayant fait l’objet d’un scale-down s’exécutent dans la région secondaire pendant les opérations normales. Pendant les opérations normales, vous pouvez choisir de décharger des opérations de lecture Hive et Spark propres à une région sur une région secondaire.
Apache HBase
L’exportation et la réplication HBase sont des moyens courants pour assurer la continuité d’activité entre les clusters HDInsight HBase.
L’exportation HBase est un processus de réplication par lots qui s’appuie sur l’utilitaire d’exportation HBase pour exporter des tables du cluster HBase principal vers son stockage Azure Data Lake Storage Gen 2 sous-jacent. Les données exportées deviennent alors accessibles au cluster HBase secondaire qui peut les importer dans des tables qui doivent déjà exister sur le cluster secondaire. Bien que l’exportation HBase n’offre pas de granularité au niveau de la table, dans les situations de mise à jour incrémentielle, le moteur d’automatisation de l’exportation contrôle la plage de lignes incrémentielles à inclure dans chaque exécution. Pour plus d’informations, consultez Sauvegarde et réplication HDInsight HBase.
La réplication HBase utilise une réplication en quasi-réel temps réel entre les clusters HBase de manière entièrement automatisée. La réplication s’effectue au niveau de la table. La réplication peut cibler toutes les tables ou des tables spécifiques. La réplication HBase est éventuellement cohérente, ce qui signifie que les modifications récentes apportées à une table de la région primaire peuvent ne pas être immédiatement accessibles à toutes les régions secondaires. Les régions secondaires sont en fin de compte assurées de devenir cohérentes avec la région primaire. La réplication HBase peut être configurée entre deux clusters HBase HDInsight ou plus à condition que :
- Le cluster principal et le cluster secondaire se trouvent sur le même réseau virtuel.
- Le cluster principal et le cluster secondaire se trouvent sur des réseaux virtuels distincts appairés dans une même région.
- Le cluster principal et le cluster secondaire se trouvent sur des réseaux virtuels distincts et appairés dans des régions différentes.
Pour plus d’informations, consultez Configurer la réplication de clusters Apache HBase sur des réseaux virtuels Azure.
Il existe d’autres façons d’effectuer des sauvegardes de clusters HBase comme la copie du dossier hbase, la copie des tables et les captures instantanées.
RPO et RTO HBase
Exportation HBase
- RPO : la perte de données est limitée à la dernière importation incrémentielle par lots réussie par le cluster secondaire à partir du cluster principal.
- RTO : délai entre la défaillance du cluster principal et le rétablissement des opérations d’E/S sur le cluster secondaire.
Réplication HBase
- RPO : la perte de données est limitée à la dernière expédition WalEdit reçue sur le cluster secondaire.
- RTO : délai entre la défaillance du cluster principal et le rétablissement des opérations d’E/S sur le cluster secondaire.
Architectures HBase
La réplication HBase peut être configurée dans trois modes : Meneur-Suiveur, Meneur-Meneur et Cyclique.
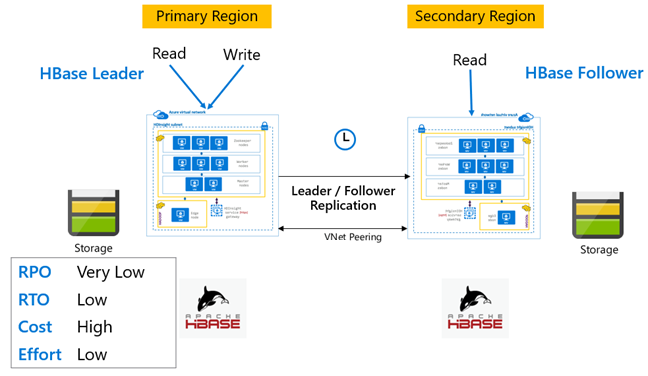
Réplication HBase : Modèle Meneur – Suiveur
Dans cette configuration inter-région, la réplication est unidirectionnelle de la région primaire vers la région secondaire. Tout ou partie des tables de la région primaire peuvent être identifiées pour la réplication unidirectionnelle. Pendant les opérations normales, le cluster secondaire peut être utilisé pour traiter les demandes de lecture dans sa propre région.
Le cluster secondaire fonctionne comme un cluster HBase normal, pouvant héberger ses propres tables et traiter les lectures et les écritures des applications régionales. En revanche, les écritures dans les tables répliquées ou les tables natives du cluster secondaire ne sont pas répliquées sur le cluster principal.
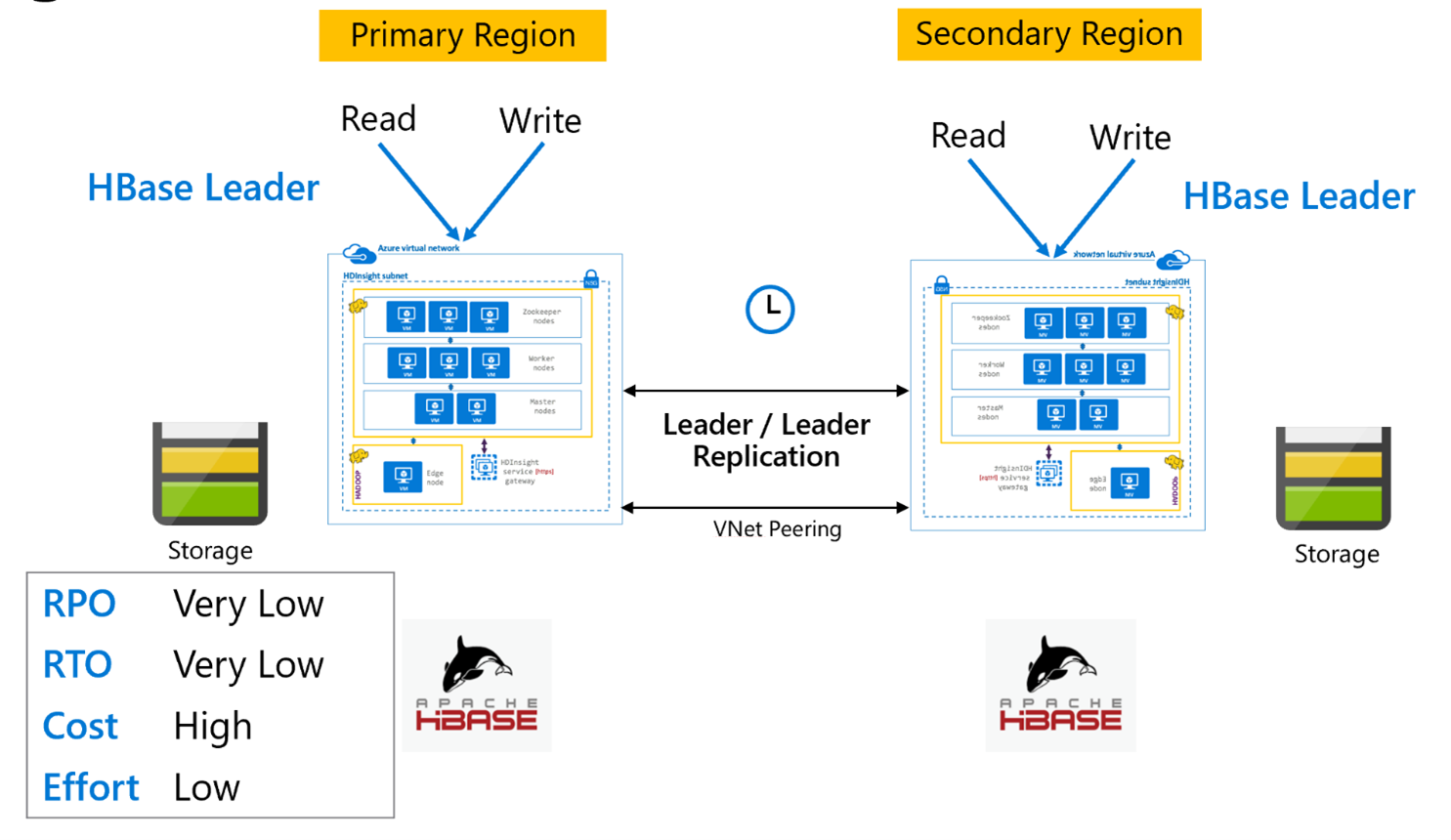
Réplication HBase : Modèle Meneur – Meneur
Cette configuration inter-région est très similaire à la configuration unidirectionnelle, sauf que la réplication se produit de manière bidirectionnelle entre la région primaire et la région secondaire. Les applications peuvent utiliser les deux clusters dans les modes lecture-écriture et les mises à jour sont échangées de manière asynchrones entre elles.
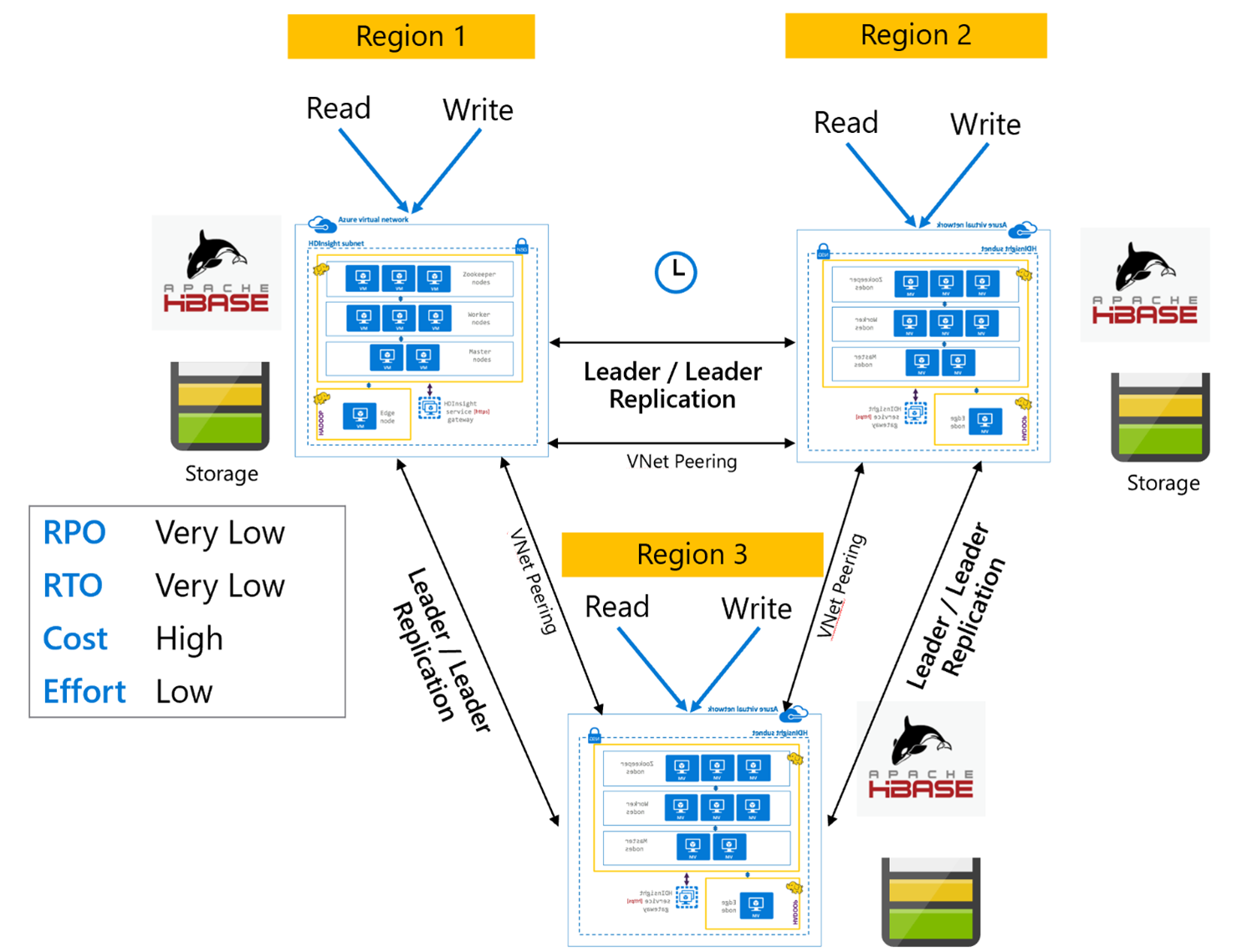
Réplication HBase : Multirégion ou Cyclique
Le modèle de réplication Multirégion/Cyclique est une extension de la réplication HBase qui permet de créer une architecture HBase globalement redondante où plusieurs applications lisent et écrivent sur les clusters HBase spécifiques d’une région. Les clusters peuvent être configurés dans différentes combinaisons Meneur/Meneur ou Meneur/Suiveur selon les besoins métier.
Apache Kafka
Pour offrir une disponibilité inter-région, HDInsight 4.0 prend en charge Kafka MirrorMaker qui permet de gérer un réplica secondaire du cluster Kafka principal dans une région différente. MirrorMaker joue le rôle d’une paire consommateur-producteur générale, qui consomme dans une rubrique spécifique du cluster principal et produit dans une rubrique de même nom sur le cluster secondaire. La réplication intercluster pour une haute disponibilité et une reprise après sinistre avec MirrorMaker se fonde sur l’hypothèse que les producteurs et les consommateurs doivent basculer sur le cluster de réplication. Pour plus d’informations, consultez Utiliser MirrorMaker pour répliquer des rubriques Apache Kafka avec Kafka sur HDInsight
Selon la durée de vie des rubriques au lancement de la réplication, la réplication de rubriques MirrorMaker peut entraîner différents décalages entre les rubriques source et réplica. Les clusters Kafka HDInsight prennent aussi en charge la réplication de partitions de rubriques, qui est une fonctionnalité de haute disponibilité au niveau du cluster individuel.
Architectures Apache Kafka
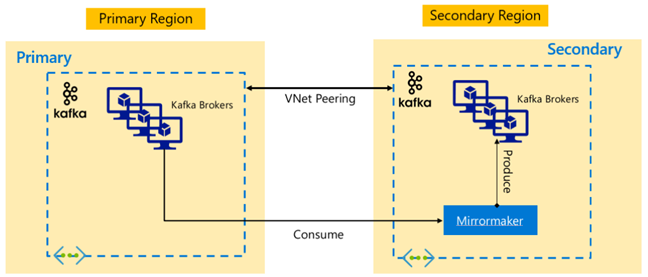
Réplication Apache Kafka : Actif – Passif
La configuration Actif-Passif permet une mise en miroir unidirectionnelle asynchrone du cluster actif vers le cluster passif. Les producteurs et les consommateurs doivent être conscients de l’existence d’un cluster actif et passif et doivent être prêts à basculer sur le cluster passif en cas de défaillance du cluster actif. Voici quelques-uns des avantages et inconvénients de la configuration Actif-Passif.
Avantages :
- La latence réseau entre les clusters n’affecte pas le niveau de performance du cluster actif.
- Simplicité de la réplication unidirectionnelle.
Inconvénients :
- Le cluster passif peut rester sous-utilisé.
- Complexité de conception de l’incorporation de la sensibilisation au basculement dans les producteurs et les consommateurs d’application.
- Risque de perte de données pendant la défaillance du cluster actif.
- Cohérence éventuelle entre les rubriques des clusters actif et passif.
- Les restaurations sur le cluster principal peuvent entraîner une incohérence des messages dans les rubriques.
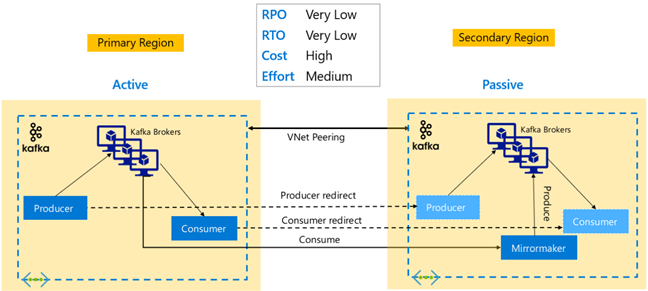
Réplication Apache Kafka : Actif – Actif
La configuration Actif-Actif implique deux clusters HDInsight Kafka de réseaux virtuels appairés appartenant à des régions distinctes avec une réplication asynchrone bidirectionnelle assurée par MirrorMaker. Dans cette conception, les messages consommés par les consommateurs du cluster principal sont également mis à la disposition des consommateurs du cluster secondaire, et inversement. Voici quelques-uns des avantages et inconvénients de la configuration Actif-Actif.
Avantages :
- En raison de leur état dupliqué, les basculements et les restaurations sont plus faciles à exécuter.
Inconvénients :
- La configuration, la gestion et la supervision sont plus complexes que dans le modèle Active/Passif.
- Le problème de la réplication circulaire doit être résolu.
- La réplication bidirectionnelle se traduit par des coûts de sortie des données régionales supérieurs.
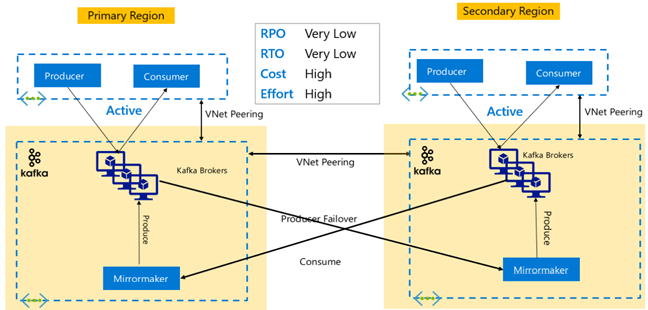
Pack Sécurité Entreprise HDInsight
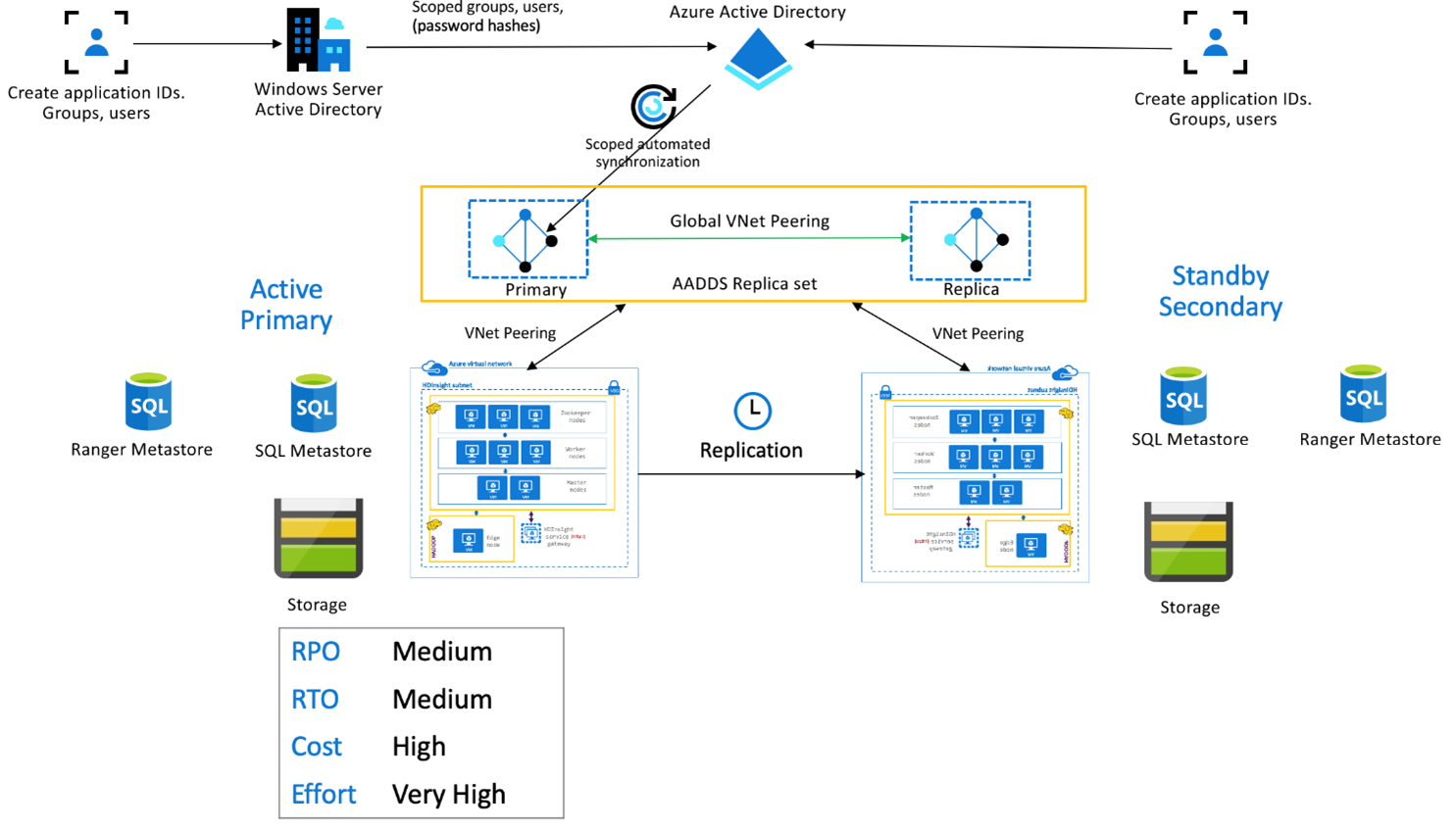
Cette configuration vise à activer la fonctionnalité multi-utilisateur dans le cluster principal et le cluster secondaire ainsi que les jeux de réplicas Microsoft Entra Domain Services pour permettre aux utilisateurs de s’authentifier auprès des deux clusters. Pendant les opérations normales, les stratégies Ranger doivent être configurées dans le cluster secondaire de façon à limiter les utilisateurs aux opérations de lecture. L’architecture ci-dessous explique comment peut se présenter une configuration Hive ESP constituée d’un cluster principal actif et d’un cluster secondaire de secours.
Réplication du metastore Ranger :
Le metastore Ranger sert à stocker de manière permanente les stratégies Ranger et à les mettre à disposition pour contrôler l’autorisation des données. Nous vous recommandons de conserver les stratégies Ranger indépendantes dans le cluster principal et le cluster secondaire et de maintenir le cluster secondaire comme réplica de lecture.
Si les stratégies Ranger doivent rester synchronisées entre le cluster principal et le cluster secondaire, utilisez l’importation/exportation Ranger pour sauvegarder et importer périodiquement les stratégies Ranger du cluster principal vers le cluster secondaire.
Le risque d’une réplication des stratégies Ranger entre le cluster principal et le cluster secondaire est qu’il devienne possible d’écrire sur ce dernier, ce qui peut aboutir à des écritures involontaires sur le cluster secondaire et donc à des incohérences de données.
Étapes suivantes
Pour en savoir plus sur les fonctionnalités présentées dans cet article, voir :
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour