Guide pratique pour utiliser la réplication Apache Hive dans les clusters Azure HDInsight
Dans le contexte des bases de données et des entrepôts, la réplication représente le processus de duplication d’entités d’un entrepôt à un autre. La duplication peut s’appliquer à une base de données entière, ou à plus petite échelle, par exemple à une table ou une partition. L’objectif est d’obtenir un réplica qui change à chaque fois que l’entité de base change. La réplication sur Apache Hive cible essentiellement la récupération d’urgence, et offre une réplication de copie principale unidirectionnelle. Dans les clusters HDInsight, la réplication Hive peut être utilisée pour répliquer de façon unidirectionnelle le metastore Hive et le lac de données sous-jacent associé, sur Azure Data Lake Storage Gen2.
La réplication Hive a évolué au fil des années, avec des versions plus récentes offrant de meilleures fonctionnalités tout en étant plus rapides et moins gourmandes en ressources. Dans cet article, nous abordons la réplication Hive (Replv2) qui est prise en charge dans les types de cluster HDInsight 3.6 et HDInsight 4.0.
Avantages de Replv2
Hive ReplicationV2 (également appelé Replv2) présente les avantages suivants par rapport à la première version de la réplication Hive qui utilisait Hive IMPORT-EXPORT :
- Réplication incrémentielle basée sur les événements
- Réplication à un instant dans le passé
- Réduction des besoins en bande passante
- Réduction du nombre de copies intermédiaires
- L’état de réplication est conservé
- Réplication avec contraintes
- Prise en charge d’un modèle Hub-and-Spoke
- Prise en charge des tables ACID (dans HDInsight 4.0)
Phases de validation
La réplication Hive basée sur les événements est configurée entre le cluster principal et le cluster secondaire. Elle se compose de deux phases distinctes que sont l’amorçage et les exécutions incrémentielles.
Amorçage
L’amorçage est destiné à être exécuté une seule fois, pour répliquer l’état de base des bases de données, du cluster principal vers le cluster secondaire. Vous pouvez configurer l’amorçage, si nécessaire, pour inclure un sous-ensemble des tables de la base de données ciblée sur lesquelles la réplication doit être activée.
Exécutions incrémentielles
Après l’amorçage, les exécutions incrémentielles sont automatisées sur le cluster principal, et les événements générés pendant les exécutions incrémentielles sont lus sur le cluster secondaire. Lorsque le cluster secondaire rattrape le cluster principal, il se met en concordance avec les événements du cluster principal.
Commandes de réplication
Hive offre un ensemble de commandes REPL (DUMP, LOAD et STATUS) pour orchestrer le flux des événements. La commande DUMP génère un journal local de tous les événements DDL/DML sur le cluster principal. La commande LOAD est une approche de copie différée des métadonnées et données journalisées dans la sortie de vidage de la réplication extraite, et est exécutée sur le cluster cible. La commande STATUS s’exécute à partir du cluster cible pour fournir le tout dernier ID d’événement informant que la charge de réplication la plus récente a été répliquée avec succès.
Définir la source de réplication
Avant de commencer la réplication, assurez-vous que la base de données à répliquer est définie en tant que source de réplication. Vous pouvez utiliser la commande DESC DATABASE EXTENDED <db_name> pour déterminer si le paramètre repl.source.for est défini avec le nom de la stratégie.
Si la stratégie est planifiée et que le paramètre repl.source.for n’est pas défini, vous devez d’abord définir ce paramètre à l’aide de ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Vider les métadonnées dans le lac de données
La commande REPL DUMP [database name]. => location / event_id est utilisée dans la phase de démarrage pour vider les métadonnées pertinentes dans Azure Data Lake Storage Gen2. event_id spécifie l’événement minimal pour lequel des métadonnées pertinentes ont été placées dans Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Exemple de sortie :
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Charger les données dans le cluster cible
La commande REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } permet de charger des données dans le cluster cible pour le démarrage et les phases incrémentielles de la réplication. [database name] peut être identique à la source ou à un autre nom sur le cluster cible. [location] représente l’emplacement depuis la sortie de la commande REPL DUMP précédente. Cela signifie que le cluster cible doit être en mesure de communiquer avec le cluster source. La clause WITH a été ajoutée principalement pour empêcher le redémarrage du cluster cible, ce qui permet la réplication.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Sortir le dernier ID d’événement répliqué
La commande REPL STATUS [database name] est exécutée sur les clusters cibles et génère le dernier event_id répliqué. La commande permet également aux utilisateurs de savoir dans quel état leur cluster cible est répliqué. Vous pouvez utiliser la sortie de cette commande pour élaborer la commande REPL DUMP suivante destinée à la réplication incrémentielle.
repl status tpcds_orc;
Exemple de sortie :
| last_repl_id |
|---|
| 2925 |
Vider les données et métadonnées pertinentes dans le lac de données
La commande REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } est utilisée pour vider les métadonnées et données pertinentes dans Azure Data Lake Storage. Cette commande est utilisée dans la phase incrémentielle, et elle est exécutée sur l’entrepôt source. FROM [event-id] est obligatoire pour la phase incrémentielle, et la valeur de event-id peut être dérivée en exécutant la commande REPL STATUS [database name] sur l’entrepôt cible.
repl dump tpcds_orc from 2925;
Exemple de sortie :
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
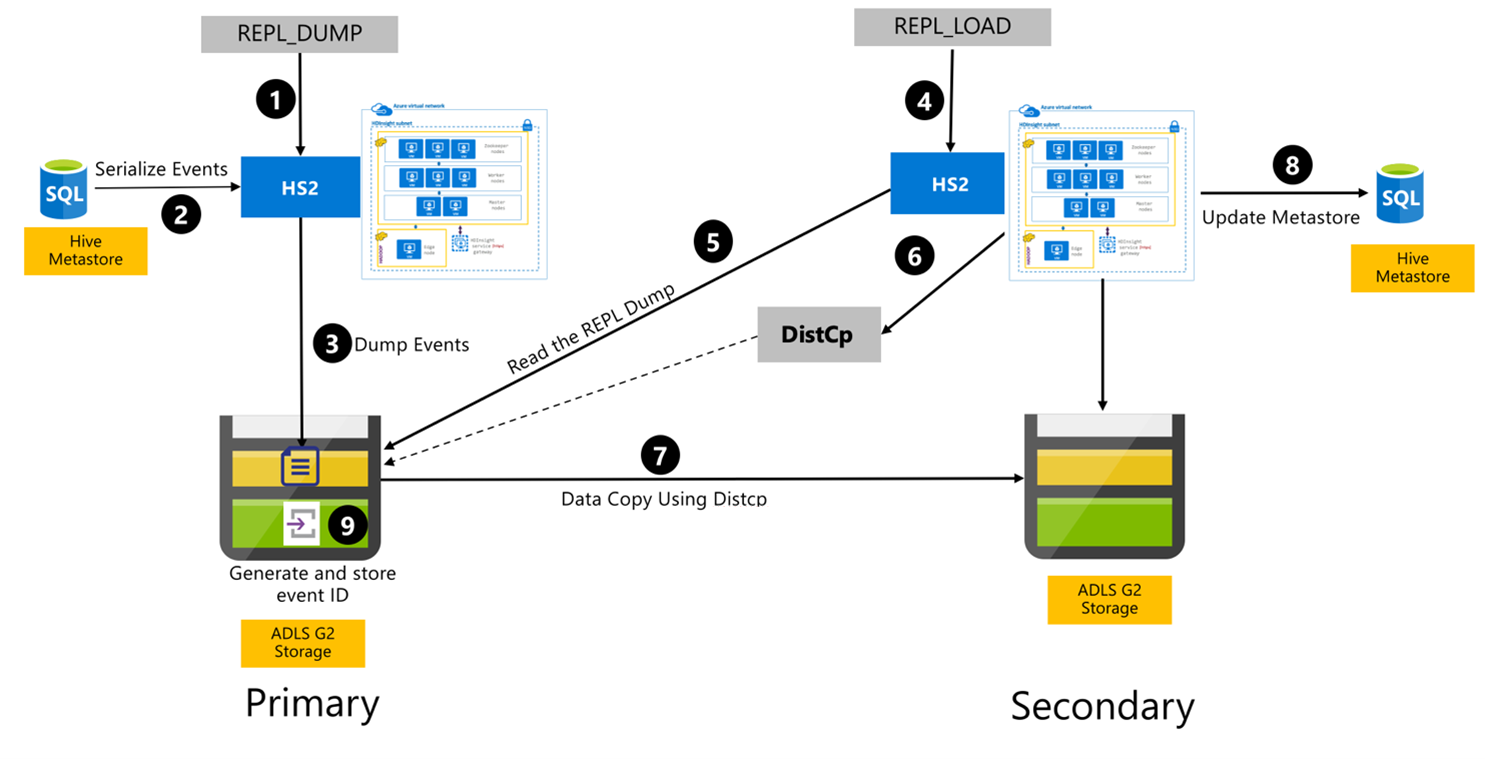
Processus de réplication Hive
Les étapes suivantes représentent les événements séquentiels qui ont lieu pendant le processus de réplication Hive.
Assurez-vous que les tables à répliquer sont définies comme source de réplication pour une certaine stratégie.
La commande
REPL_DUMPest émise sur le cluster principal avec les contraintes associées, telles que le nom de la base de données, la plage d’ID d’événement et l’URL de stockage Azure Data Lake Storage Gen2.Le système sérialise un vidage de tous les événements suivis, du metastore jusqu’au tout dernier événement. Ce vidage est stocké dans le compte de stockage Azure Data Lake Storage Gen2 sur le cluster principal, à l’URL spécifiée par
REPL_DUMP.Le cluster principal conserve les métadonnées de réplication dans le stockage Azure Data Lake Storage Gen2 du cluster principal. Le chemin est configurable au niveau de l’interface utilisateur Hive Config dans Ambari. Le processus fournit le chemin dans lequel les métadonnées sont stockées, et l’ID du dernier événement DML/DDL suivi.
La commande
REPL_LOADest émise à partir du cluster secondaire. La commande pointe vers le chemin configuré à l’étape 3.Le cluster secondaire lit le fichier de métadonnées avec les événements suivis qui ont été créés à l’étape 3. Assurez-vous que le cluster secondaire dispose d’une connectivité réseau vers le stockage Azure Data Lake Storage Gen2 du cluster principal dans lequel sont stockés les événements suivis provenant de
REPL_DUMP.Le cluster secondaire génère le calcul de copie distribuée (
DistCP).Le cluster secondaire copie les données à partir du stockage du cluster principal.
Le metastore sur le cluster secondaire est mis à jour.
Le dernier ID d’événement suivi est stocké dans le metastore principal.
La réplication incrémentielle suit le même processus et nécessite le dernier ID d’événement répliqué comme entrée. Cela aboutit à une copie incrémentielle depuis le dernier événement de réplication. Les réplications incrémentielles sont normalement automatisées avec une fréquence prédéfinie pour atteindre les objectifs de point de récupération (RPO) voulus.
Modèles de réplication
La réplication est normalement configurée de manière unidirectionnelle, entre le serveur principal et le serveur secondaire, sachant que le serveur principal traite les demandes de lecture et d’écriture. Le cluster secondaire traite les demandes de lecture uniquement. Les écritures sont autorisées sur le serveur secondaire en cas d’incident, mais la réplication inverse doit être reconfigurée sur le serveur principal.
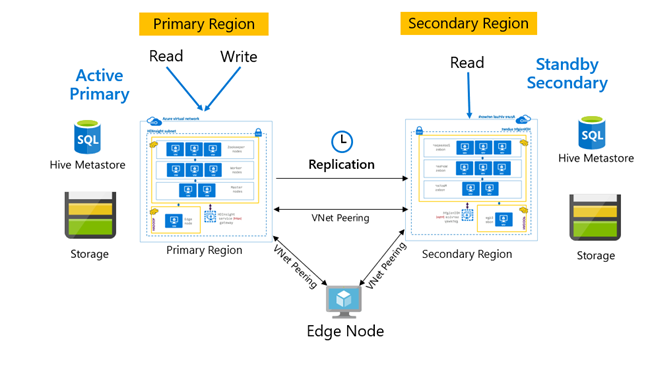
De nombreux modèles sont adaptés à la réplication Hive, y compris Principal – Secondaire, Hub and Spoke et Relais.
Dans HDInsight, le type Région primaire active et région secondaire de secours constitue un modèle courant de continuité d’activité et reprise d’activité (BCDR). HiveReplicationV2 peut utiliser ce modèle avec des clusters HDInsight Hadoop distincts au niveau régional et avec VNet Peering. Un machine virtuelle courante, appairée aux deux clusters peut être utilisée pour héberger les scripts d’automatisation de la réplication. Pour plus d’informations sur les modèles BCDR HDInsight possibles, reportez-vous à la documentation sur la continuité d’activité HDInsight.
Réplication Hive avec le Pack Sécurité Entreprise
Dans les cas où la réplication Hive est prévue sur des clusters HDInsight Hadoop avec Pack Sécurité Entreprise, vous devez prendre en compte les mécanismes de réplication pour le méta-store Ranger et Microsoft Entra Domain Services.
Utilisez la fonctionnalité de jeux de réplicas Microsoft Entra Domain Services pour créer plusieurs jeux de réplicas Microsoft Entra Domain Services par locataire Microsoft Entra dans plusieurs régions. Tous les ensembles de réplicas doivent être appairés aux réseaux virtuels HDInsight dans leurs régions respectives. Dans cette configuration, les modifications apportées aux services Microsoft Entra Domain, notamment la configuration, l'identité et les informations d'identification de l'utilisateur, les groupes, les objets de stratégie de groupe, les objets ordinateur et d'autres modifications, sont appliquées à tous les jeux de réplicas du domaine géré à l'aide de la réplication des services Microsoft Entra Domain.
Les stratégies Ranger peuvent être régulièrement sauvegardées et répliquées, de la région primaire vers la région secondaire, à l’aide de la fonctionnalité d’importation/exportation de Ranger. Vous pouvez choisir de répliquer tout ou une partie des stratégies Ranger en fonction du niveau des autorisations que vous cherchez à implémenter sur le cluster secondaire.
Exemple de code
La séquence de code suivante fournit un exemple de la façon dont l’amorçage et la réplication incrémentielle peuvent être implémentées sur un exemple de table appelée tpcds_orc.
Définition de la table comme source pour une stratégie de réplication.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Vidage des données d’amorçage au niveau du cluster principal.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Exemple de sortie :
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Charge des données d’amorçage au niveau du cluster secondaire.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Vérification de l’état
REPLau niveau du cluster secondaire.repl status tpcds_orc;last_repl_id 2925 Vidage incrémentiel au niveau du cluster principal.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Exemple de sortie :
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Charge incrémentielle au niveau du cluster secondaire.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Vérification de l’état
REPLau niveau du cluster secondaire.repl status tpcds_orc;last_repl_id 2960
Étapes suivantes
Pour en savoir plus sur les fonctionnalités présentées dans cet article, voir :
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour