Activer les dumps de tas pour les services Apache Hadoop sur HDInsight sur Linux
Les dumps de tas contiennent un instantané de la mémoire de l’application, y compris des valeurs des variables au moment de la création du dump. Ils sont donc utiles pour diagnostiquer les problèmes qui se produisent au moment de l’exécution.
Services
Vous pouvez activer des dumps de tas pour les services suivants :
- Apache hcatalog - tempelton
- Apache hive - hiveserver2, metastore, derbyserver
- mapreduce - jobhistoryserver
- Apache yarn - resourcemanager, nodemanager, timelineserver
- Apache hdfs - datanode, secondarynamenode, namenode
Vous pouvez également activer les dumps de tas du mappage et réduire les processus exécutés par HDInsight.
Présentation de la configuration des dumps de tas
Les dumps de tas sont activés par la transmission d’options (parfois appelées options ou paramètres) à la machine virtuelle Java au démarrage d’un service. Pour la plupart des services Apache Hadoop, vous pouvez modifier le script shell utilisé pour démarrer le service afin de passer ces options.
Dans chaque script, il existe une exportation pour *_OPTS, qui contient les options transmises à la machine virtuelle Java. Par exemple, dans le script hadoop-env.sh, la ligne qui commence par export HADOOP_NAMENODE_OPTS= contient les options du service NameNode.
Les processus de mappage et de réduction sont légèrement différents, car ces opérations sont des processus enfant du service MapReduce. Chaque processus de mappage ou de réduction s’exécute dans un conteneur enfant et deux entrées contiennent les options JVM. Ils sont contenus dans mapred-site.xml:
- mapreduce.admin.map.child.java.opts
- mapreduce.admin.reduce.child.java.opts
Notes
Nous recommandons d’utiliser Apache Ambari pour modifier les scripts et les paramètres de mapred-site.xml, car Ambari gère la réplication des modifications sur les nœuds du cluster. Consultez la section Utilisation d’Apache Ambari pour connaître les différentes étapes.
Activer les dumps de tas
L’option suivante active les dumps de tas quand OutOfMemoryError se produit :
-XX:+HeapDumpOnOutOfMemoryError
Le + indique que cette option est activée. La valeur par défaut est désactivée.
Avertissement
Les dumps de tas ne sont pas activés pour les services Hadoop sur HDInsight par défaut, car les fichiers dump peuvent être volumineux. Si vous les activez pour la résolution des problèmes, pensez à les désactiver après avoir reproduit le problème et regroupé les fichiers de vidage.
Emplacement du dump
L’emplacement par défaut pour le fichier dump est le répertoire de travail actuel. Vous pouvez contrôler l’endroit de stockage du fichier à l’aide de l’option suivante :
-XX:HeapDumpPath=/path
Par exemple, l’utilisation de -XX:HeapDumpPath=/tmp entraîne le stockage des dumps dans le répertoire /tmp.
Scripts
Vous pouvez également déclencher un script quand OutOfMemoryError se produit. Par exemple, vous pouvez déclencher une notification pour signaler que l’erreur s’est produite. Utilisez l’option suivante pour déclencher un script quand OutOfMemoryError survient :
-XX:OnOutOfMemoryError=/path/to/script
Notes
Apache Hadoop étant un système distribué, tout script utilisé doit être placé sur tous les nœuds du cluster où le service s’exécute.
Le script doit également être dans un emplacement accessible par le compte sur lequel s’exécute le service et doit fournir des autorisations d’exécution. Par exemple, vous souhaitez stocker les scripts dans /usr/local/bin et utiliser chmod go+rx /usr/local/bin/filename.sh pour accorder les autorisations de lecture et d’exécution.
Utilisation d’Apache Ambari
Pour modifier la configuration d’un service, procédez comme suit :
Dans un navigateur web, accédez à
https://CLUSTERNAME.azurehdinsight.net, oùCLUSTERNAMEest le nom de votre cluster.Dans la liste de gauche, sélectionnez la zone de service que vous souhaitez modifier. Par exemple, HDFS. Dans la zone centrale, sélectionnez l’onglet Configurations .

À l’aide de l’entrée Filtre..., entrez opts. Seuls les éléments contenant ce texte s’affichent.
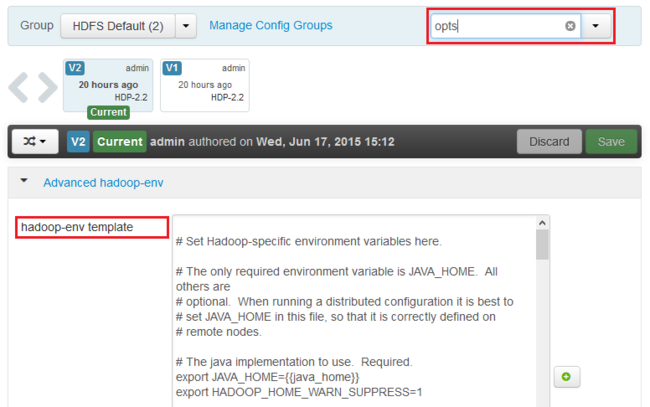
Recherchez l’entrée *_OPTS du service pour lequel vous souhaitez activer les dumps de tas et ajoutez les options que vous souhaitez activer. Dans l’image suivante, j’ai ajouté
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/à l’entrée HADOOP_NAMENODE_OPTS :
Remarque
Quand vous activez les dumps de tas du processus enfant de mappage ou de réduction, cherchez les champs intitulés mapreduce.admin.map.child.java.opts et mapreduce.admin.reduce.child.java.opts.
Utilisez le bouton Enregistrer pour enregistrer les modifications. Vous pouvez entrer une courte note décrivant les modifications.
Une fois que ces dernières ont été appliquées, l’icône Redémarrage requis s’affiche en regard d’un ou de plusieurs services.

Sélectionnez chaque service nécessitant un redémarrage et utilisez le bouton Actions de service pour Activer le mode de maintenance. Le mode de maintenance bloque la génération d’alertes au redémarrage de ce service.

Une fois le mode de maintenance activé, utilisez le bouton Redémarrer pour que le service puisse redémarrer tous les éléments affectés

Remarque
Les entrées du bouton Redémarrer peuvent être différentes pour d’autres services.
Une fois que les services ont été redémarrés, utilisez le bouton Actions de service pour Désactiver le mode de maintenance. Ambari reprend la surveillance des alertes du service.