Tutoriel : Créer des clusters Apache Hadoop à la demande dans HDInsight avec Azure Data Factory
Dans ce tutoriel, vous allez apprendre à créer un cluster Apache Hadoop à la demande dans Azure HDInsight, à l’aide d’Azure Data Factory. Ensuite, vous utiliserez des pipelines de données dans Azure Data Factory pour exécuter des travaux Hive et supprimer le cluster. À la fin de ce tutoriel, vous saurez operationalize l’exécution d’un travail Big Data, où la création du cluster, l’exécution du travail et la suppression du cluster sont accomplies selon une planification.
Ce tutoriel décrit les tâches suivantes :
- Créer un compte de stockage Azure
- Comprendre l’activité Azure Data Factory
- Créer une fabrique de données à l’aide du portail Azure
- Créez des services liés
- Créer un pipeline
- Déclencher un pipeline
- Surveiller un pipeline
- Vérifier la sortie
Si vous ne disposez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Le module Az PowerShell installé.
Un principal de service Microsoft Entra. Une fois que vous avez créé le principal de service, n’oubliez pas de récupérer l’ID d’application et la clé d’authentification en suivant les instructions dans l’article dont le lien est indiqué ci-après. Vous aurez besoin de ces valeurs plus loin dans ce didacticiel. En outre, vérifiez que ce principal de service est membre du rôle Contributeur de l’abonnement ou du groupe de ressources dans lequel le cluster est créé. Pour savoir comment récupérer les valeurs requises et attribuer les rôles adéquats, consultez Créer un principal de service Microsoft Entra.
Créer des objets Azure préliminaires
Dans cette section, vous allez créer différents objets qui seront utilisés pour le cluster HDInsight que vous créez à la demande. Le compte de stockage créé contiendra également l’exemple de script HiveQL, partitionweblogs.hql, qui permet de simuler un exemple de travail Apache Hive qui s’exécute sur le cluster.
Cette section utilise un script Azure PowerShell pour créer le compte de stockage et y copier les fichiers requis. L’exemple de script Azure PowerShell de cette section accomplit les tâches suivantes :
- Se connecte à Azure.
- Crée un groupe de ressources Azure.
- Crée un compte de stockage Azure.
- Crée un conteneur d’objets blob dans le compte de stockage.
- Copie l’exemple de script HiveQL (partitionweblogs.hql) dans le conteneur d’objets blob. L’exemple de script est déjà disponible dans un autre conteneur d’objets blob public. Le script PowerShell ci-dessous crée une copie de ces fichiers dans le compte de stockage Azure qu’il crée.
Créer un compte de stockage et copier des fichiers
Important
Spécifiez des noms pour le groupe de ressources Azure et le compte de stockage Azure qui seront créés par le script. Notez le nom du groupe de ressources, le nom du compte de stockage et la clé du compte de stockage générés en sortie par le script. Vous aurez besoin de ces informations dans la section suivante.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Vérifier le compte de stockage
- Connectez-vous au Portail Azure.
- À gauche, accédez à Tous les services>Général>Groupes de ressources.
- Sélectionnez le nom du groupe de ressources que vous avez créé dans votre script PowerShell. Utilisez le filtre si la liste des groupes de ressources est trop longue.
- La fenêtre Vue d’ensemble présente une ressource, sauf si vous partagez le groupe de ressources avec d’autres projets. Cette ressource correspond au compte de stockage avec le nom que vous avez spécifié précédemment. Sélectionnez le nom du compte de stockage.
- Sélectionnez la vignette Conteneurs.
- Sélectionnez le conteneur adfgetstarted. Vous voyez un dossier nommé
hivescripts. - Ouvrez le dossier et vérifiez qu’il contient l’exemple de fichier de script, partitionweblogs.hql.
Comprendre l’activité Azure Data Factory
Azure Data Factory gère et automatise le déplacement et la transformation des données. Azure Data Factory peut créer un cluster Hadoop HDInsight juste-à-temps pour traiter une tranche de données d’entrée et supprimer le cluster à l’issue du traitement.
Dans Azure Data Factory, une fabrique de données peut comporter un ou plusieurs pipelines de données. Un pipeline de données comprend une ou plusieurs activités. Il existe deux types d’activité :
- Activités de déplacement des données. Vous utilisez les activités de déplacement des données pour déplacer des données d’un magasin de données source vers un magasin de données de destination.
- Activités de transformation des données. Vous utilisez les activités de transformation des données pour transformer/traiter les données. L’activité Hive HDInsight est l’une des activités de transformation prises en charge par Data Factory. Dans ce didacticiel, vous utilisez l’activité de transformation Hive.
Dans cet article, vous configurez l’activité Hive pour créer un cluster HDInsight Hadoop à la demande. Quand l’activité s’exécute pour traiter des données, le déroulement des opérations est le suivant :
Un cluster Hadoop HDInsight est automatiquement créé juste-à-temps à votre intention pour traiter la tranche.
Les données d’entrée sont traitées par l’exécution d’un script HiveQL sur le cluster. Dans ce tutoriel, le script HiveQL associé à l’activité Hive réalise les opérations suivantes :
- Il utilise la table existante (hivesampletable) pour créer une autre table HiveSampleOut.
- Il remplit la table HiveSampleOut uniquement avec des colonnes spécifiques issues de la table d’origine hivesampletable.
Le cluster Hadoop HDInsight est supprimé à l’issue du traitement et reste inactif pendant l’intervalle de temps configuré (paramètre timeToLive). Si la tranche de données suivante peut être traitée au cours de cette durée d’inactivité timeToLive, elle est traitée à l’aide du même cluster.
Créer une fabrique de données
Connectez-vous au portail Azure.
À partir du menu de gauche, accédez à
+ Create a resource>Analytics>Data Factory.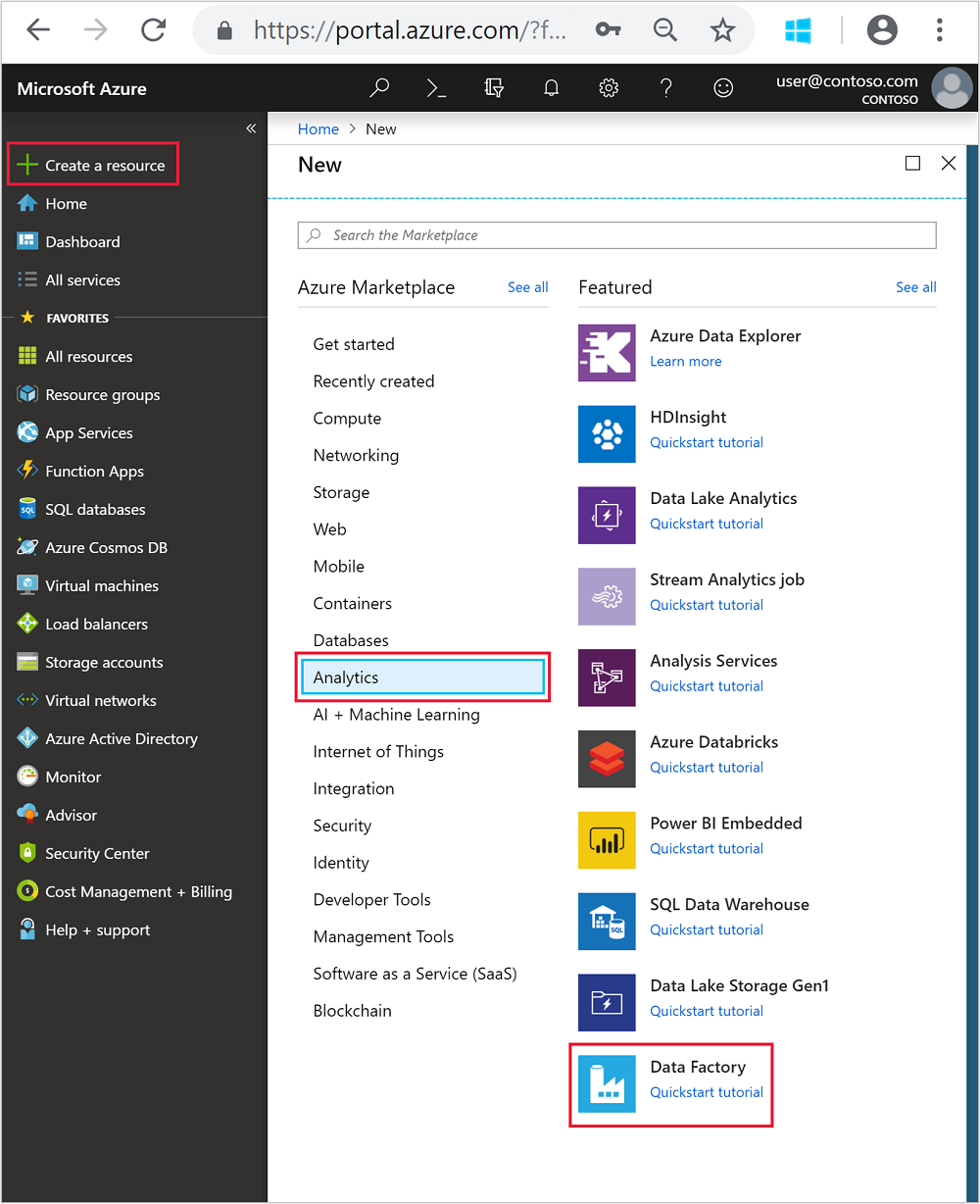
Entrez ou sélectionnez les valeurs suivantes pour la vignette Nouvelle fabrique de données :
Propriété Valeur Nom Entrez un nom pour la fabrique de données. Ce nom doit être globalement unique. Version Conservez V2. Abonnement Sélectionnez votre abonnement Azure. Resource group Sélectionnez le groupe de ressources que vous avez créé à l’aide du script PowerShell. Emplacement L’emplacement est automatiquement défini sur l’emplacement que vous avez spécifié au moment de la création du groupe de ressources. Pour ce tutoriel, l’emplacement est défini sur USA Est. Activer GIT Décochez cette case. 
Cliquez sur Créer. La création d’une fabrique de données peut prendre de 2 à 4 minutes.
Une fois la fabrique de données créée, vous recevez une notification Déploiement réussi contenant un bouton Accéder à la ressource. Sélectionnez Accéder à la ressource pour ouvrir la vue par défaut de Data Factory.
Sélectionnez Créer & surveiller pour lancer le portail de création et de surveillance Azure Data Factory.
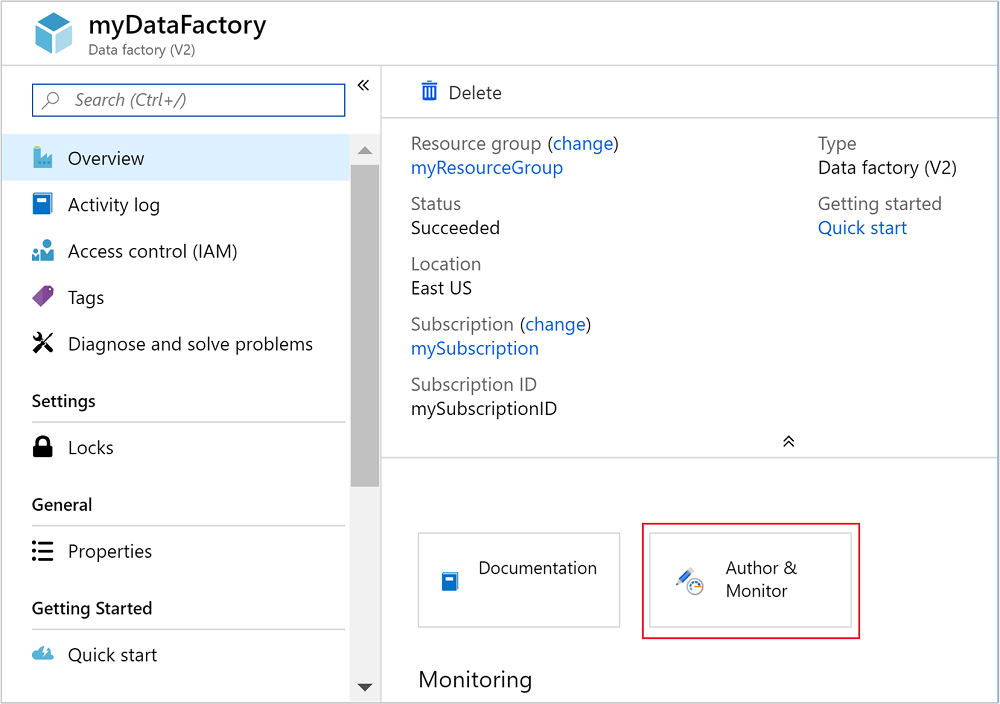
Créez des services liés
Dans cette section, vous créez deux services liés au sein de votre fabrique de données.
- Un service lié au stockage Azure relie un compte de stockage Azure à la fabrique de données. Ce stockage est utilisé par le cluster HDInsight à la demande. Il contient également le script Hive qui est exécuté sur le cluster.
- Un service lié HDInsight à la demande. Azure Data Factory crée un cluster HDInsight et exécute le script Hive automatiquement. Il supprime ensuite le cluster HDInsight une fois que le cluster inactif pendant une période préconfigurée.
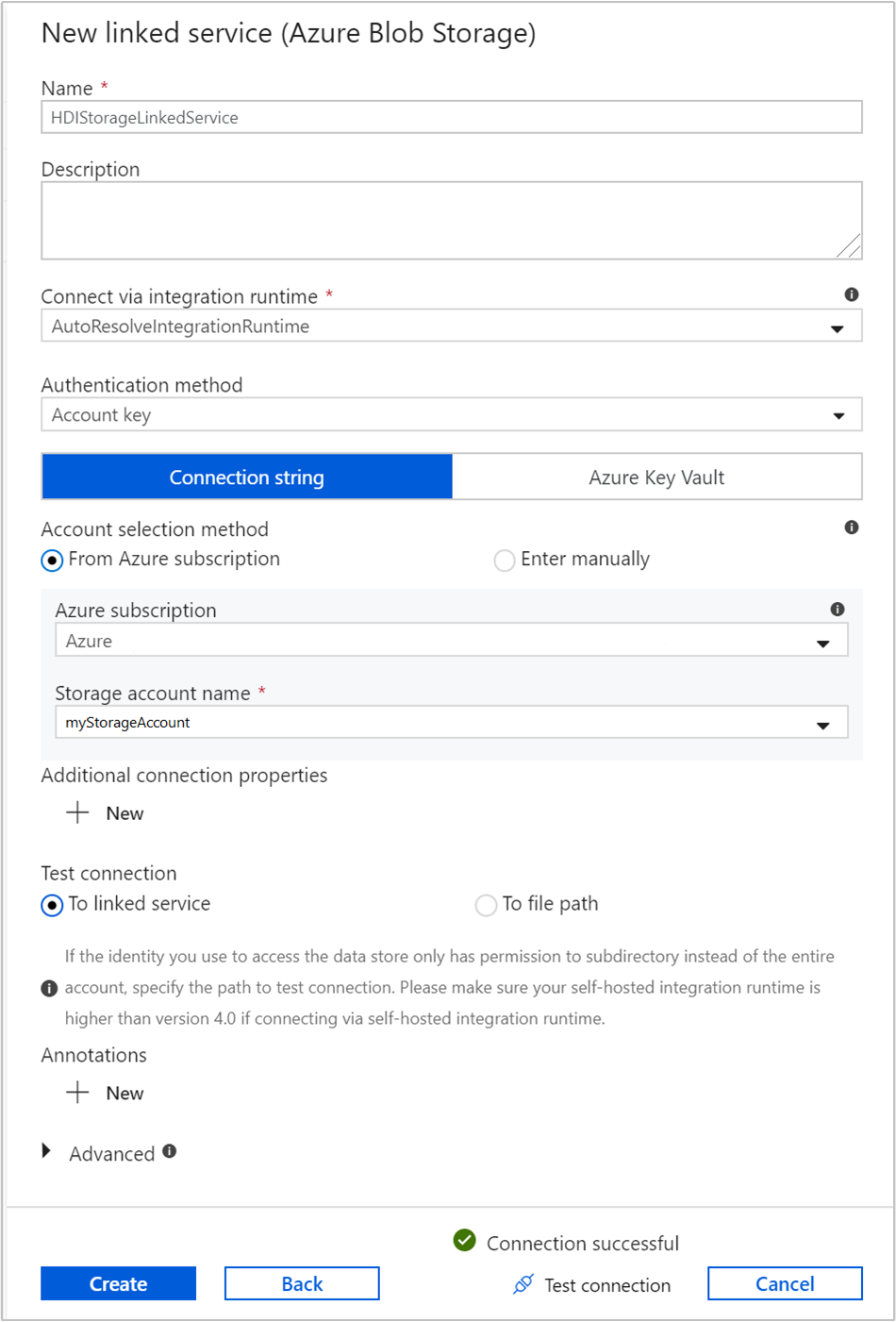
Créer un service lié Stockage Azure
Dans le volet gauche de la page Prise en main, sélectionnez l’icône Créer.

Sélectionnez Connexions dans le coin inférieur gauche de la fenêtre, puis sélectionnez + Nouveau.
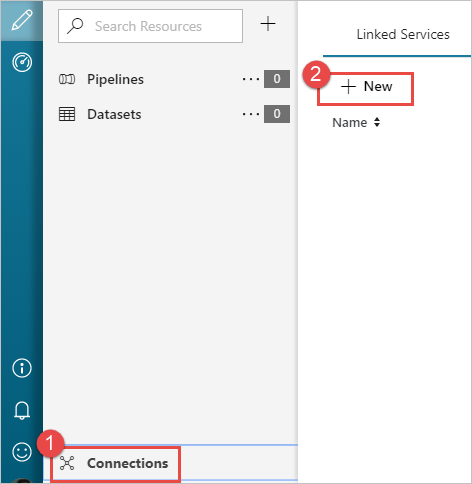
Dans la boîte de dialogue Nouveau service lié, sélectionnez Stockage Blob Azure, puis sélectionnez Continuer.
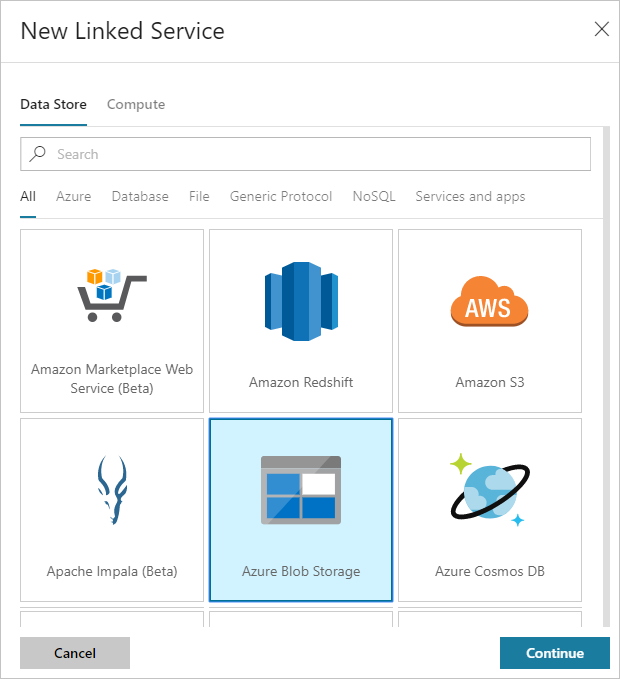
Fournissez les valeurs suivantes pour le service lié de stockage :
Propriété Valeur Nom Entrez HDIStorageLinkedService.Abonnement Azure Sélectionnez votre abonnement dans la liste déroulante. Nom du compte de stockage Sélectionnez le compte de stockage Azure que vous avez créé avec le script PowerShell. Sélectionnez Tester la connexion. Si le test réussit, sélectionnez Créer.
Créer un service lié HDInsight à la demande
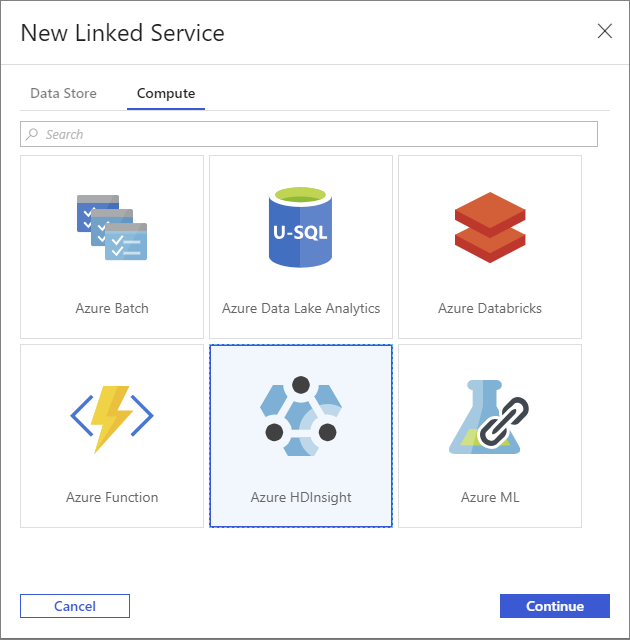
Cliquez de nouveau sur le bouton + Nouveau pour créer un nouveau service lié.
Dans la fenêtre Nouveau Service lié, sélectionnez l’onglet Calcul.
Sélectionnez Azure HDInsight, puis Continuer.
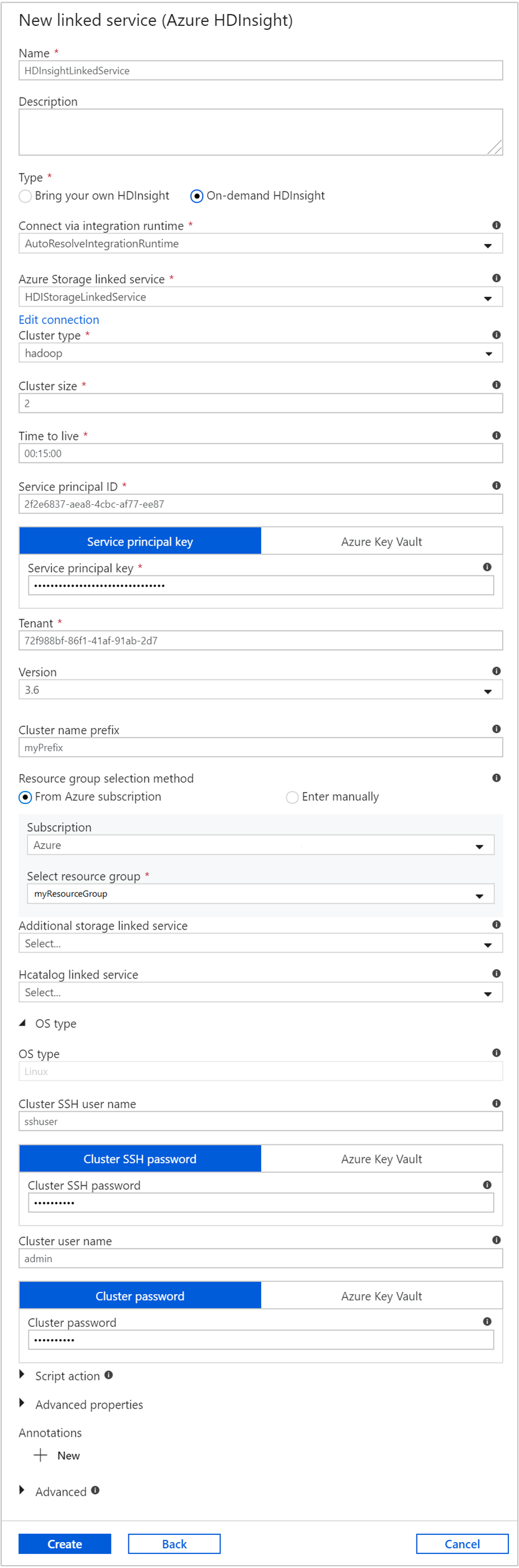
Dans la fenêtre Nouveau service lié, entrez les valeurs suivantes et conservez les autres valeurs par défaut :
Propriété Valeur Nom Entrez HDInsightLinkedService.Type Sélectionnez HDInsight à la demande. Service lié Stockage Azure Sélectionnez HDIStorageLinkedService.Type de cluster Sélectionnez hadoop. Durée de vie Indiquez la durée pendant laquelle le cluster HDInsight doit être disponible avant d’être automatiquement supprimé. ID de principal de service Indiquez l’ID d’application du principal de service Microsoft Entra que vous avez créé en lien avec les prérequis. Clé de principal de service Indiquez la clé d’authentification pour le principal de service Microsoft Entra. Préfixe du nom du cluster Indiquez une valeur qui fera office de préfixe pour tous les types de clusters créés par la fabrique de données. Abonnement Sélectionnez votre abonnement dans la liste déroulante. Sélection du groupe de ressources Sélectionnez le groupe de ressources que vous avez créé en lien avec le script PowerShell utilisé précédemment. Nom d’utilisateur SSH du cluster/type de système d’exploitation Entrez un nom d’utilisateur SSH, généralement sshuser.Mot de passe du cluster/type de système d’exploitation Indiquez un mot de passe pour l’utilisateur SSH. Nom d’utilisateur du cluster/type de système d’exploitation Entrez un nom d’utilisateur du cluster, généralement admin.Mot de passe de cluster/type de système d’exploitation Fournissez un mot de passe pour l’utilisateur du cluster. Sélectionnez ensuite Créer.
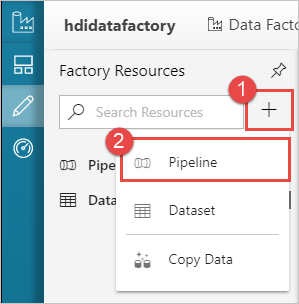
Créer un pipeline
Sélectionnez le bouton + (plus), puis sélectionnez Pipeline.
Dans la boîte à outils Activités, développez l’activité HDInsight et faites glisser l’activité Hive vers la surface du concepteur de pipeline. Sous l’onglet Général, fournissez un nom pour l’activité.
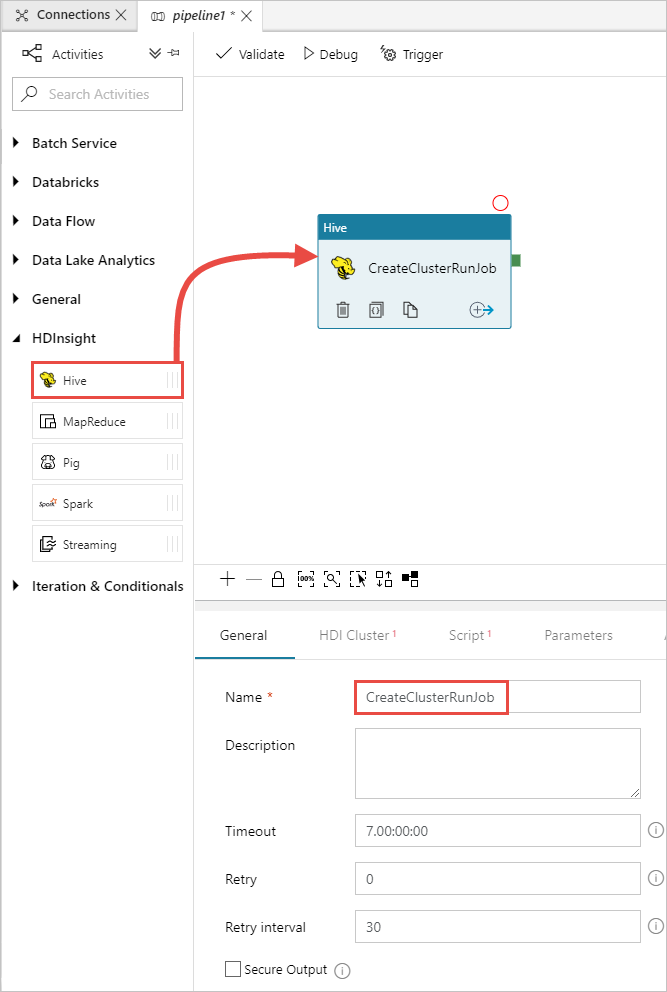
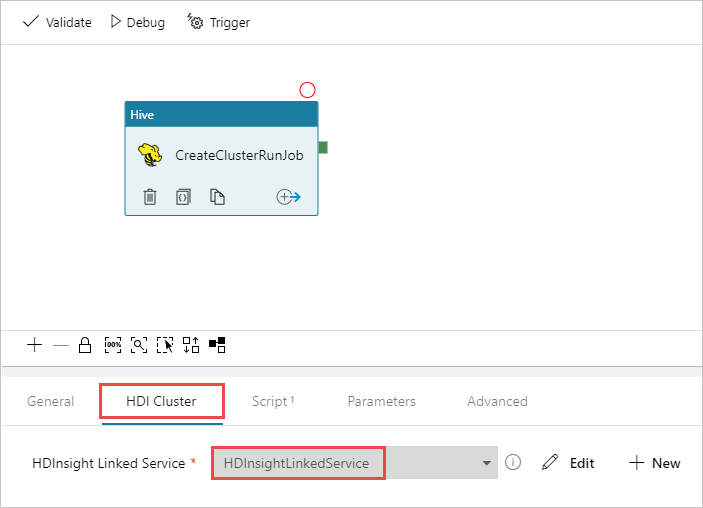
Vérifiez que l’activité Hive est sélectionnée, puis sélectionnez l’onglet Cluster HDI. Dans la liste déroulante Service lié HDInsight, sélectionnez le service lié que vous avez créé précédemment, HDInsightLinkedService, pour HDInsight.
Sélectionnez l’onglet Script, puis effectuez les étapes suivantes :
Pour Service lié au script, sélectionnez HDIStorageLinkedService dans la liste déroulante. Cette valeur est le service lié de stockage que vous avez préalablement créé.
Pour Chemin d’accès du fichier, sélectionnez Parcourir le stockage et accédez à l’emplacement de l’exemple de script Hive. Si vous avez exécuté le script PowerShell précédemment, cet emplacement doit être
adfgetstarted/hivescripts/partitionweblogs.hql.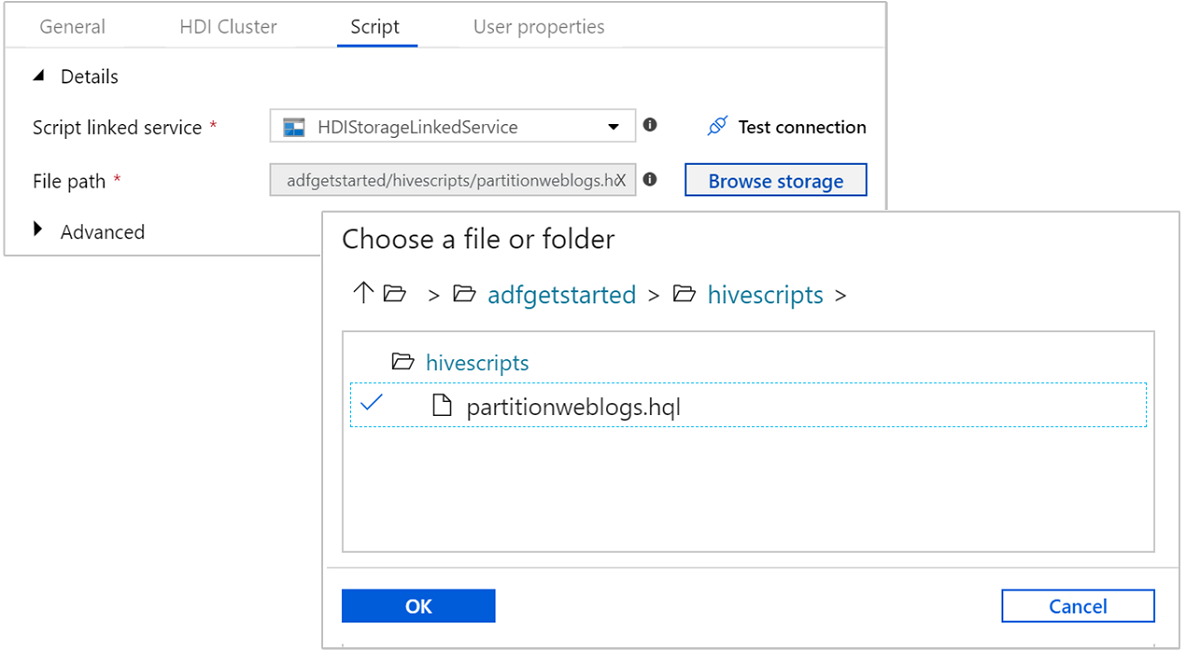
Sous Avancé>Paramètres, sélectionnez
Auto-fill from script. Cette option recherche tous les paramètres dans le script Hive qui requièrent des valeurs à l’exécution.Dans la zone de texte Valeur, ajoutez le dossier existant au format
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. Le chemin d'accès respecte la casse. Il s’agit du chemin où sera stockée la sortie du script. Le schémawasbsest nécessaire, car le transfert sécurisé est désormais activé par défaut pour les comptes de stockage.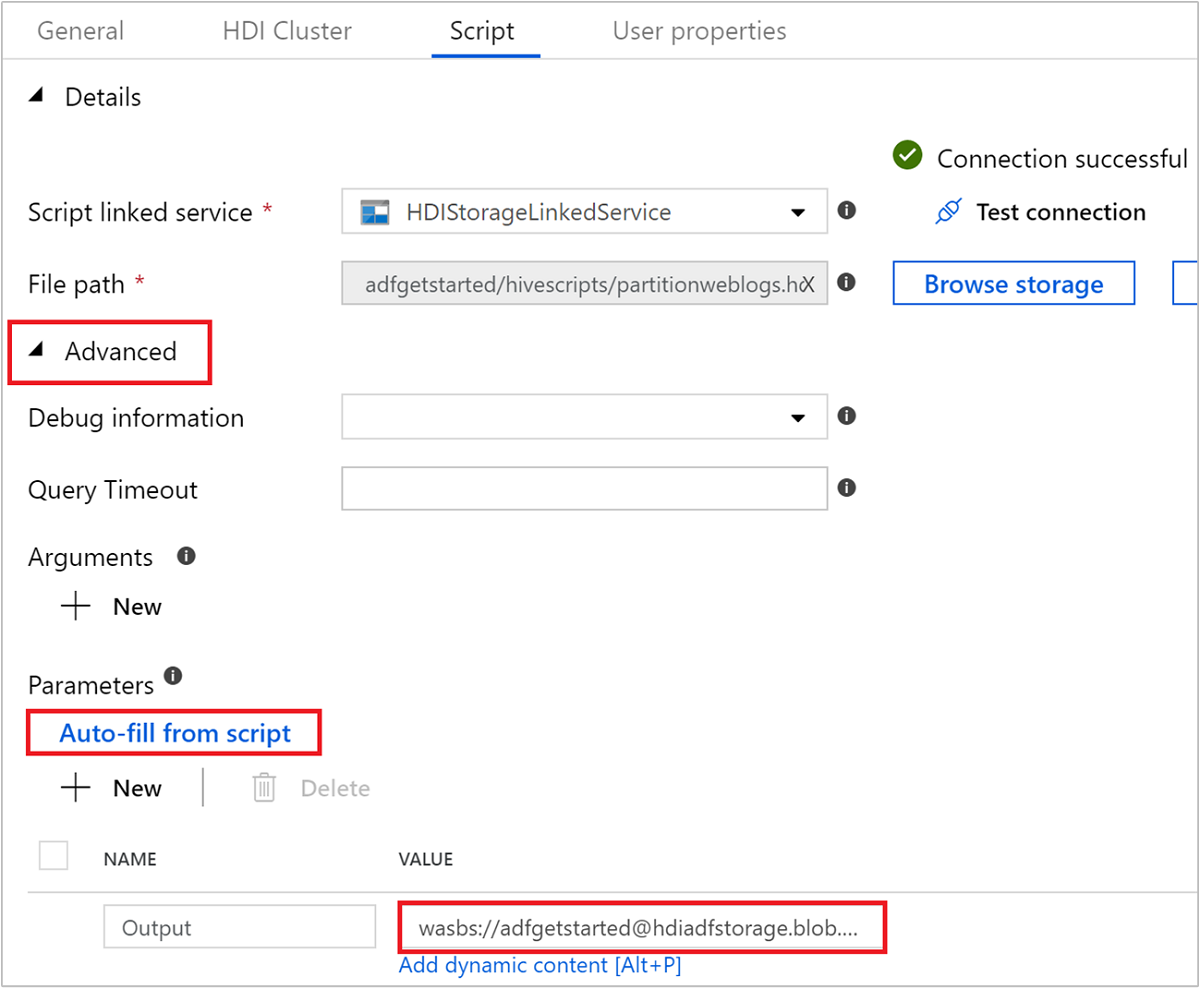
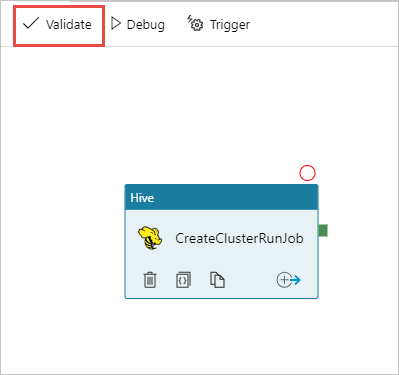
Sélectionnez Valider pour valider le pipeline. Cliquez sur le bouton >> flèche droite (>>) pour fermer la fenêtre de validation.
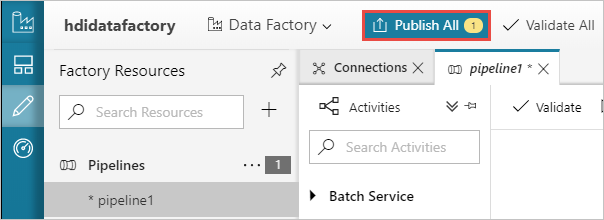
Enfin, sélectionnez Tout publier pour publier les artefacts sur Azure Data Factory.
Déclencher un pipeline
Dans la barre d’outils sur l’aire du concepteur, sélectionnez Ajouter un déclencheur>Déclencher maintenant.
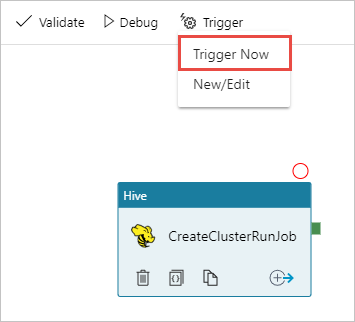
Sélectionnez OK dans la barre latérale contextuelle.
Surveiller un pipeline
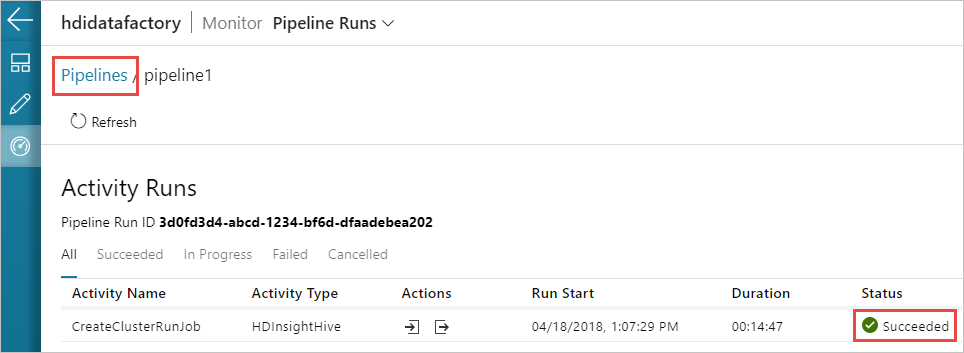
Basculez vers l’onglet Surveiller sur la gauche. Vous voyez une exécution du pipeline dans la liste Exécutions du pipeline. Notez l’état de l’exécution dans la colonne État.
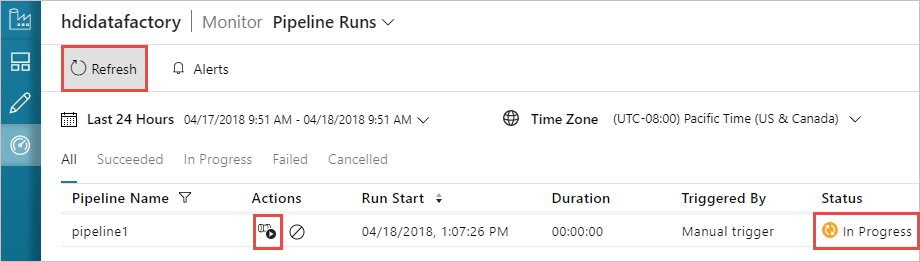
Sélectionnez Actualiser pour actualiser l’état.
Vous pouvez également sélectionner l’icône Afficher les exécutions d’activités pour voir l’exécution d’activité associée au pipeline. Dans la capture d’écran ci-après, vous ne voyez qu’une seule exécution d’activité, car il n’y a qu’une seule activité dans le pipeline que vous avez créé. Pour revenir à la vue précédente, sélectionnez Pipelines en haut de la page.
Vérifier la sortie
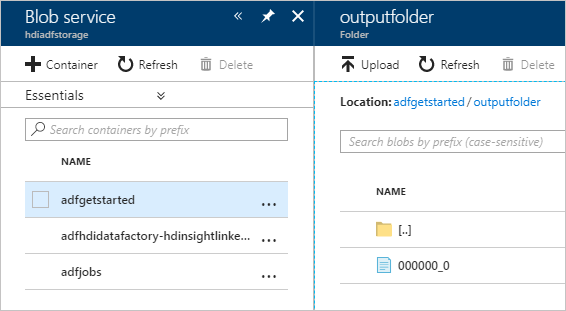
Pour vérifier la sortie, dans le portail Azure, accédez au compte de stockage que vous avez utilisé pour ce tutoriel. Vous devez voir les dossiers ou conteneurs suivants :
Vous voyez un emplacement adfgerstarted/outputfolder qui contient la sortie du script Hive qui a été exécuté dans le cadre du pipeline.
Vous voyez un conteneur adfhdidatafactory-<nom-service-lié>-<timestamp>. Ce conteneur est l’emplacement de stockage par défaut du cluster HDInsight qui a été créé dans le cadre de l’exécution du pipeline.
Vous voyez un conteneur adfjobs qui contient les journaux d’activité des tâches Azure Data Factory.
Nettoyer les ressources
Avec la création de cluster HDInsight à la demande, vous n’avez pas besoin de supprimer explicitement le cluster HDInsight. Le cluster est supprimé en fonction de la configuration que vous avez fournie durant la création du pipeline. Néanmoins, la suppression du cluster n’entraîne pas celle des comptes de stockage associés à celui-ci. Ce comportement par défaut permet de préserver vos données. Toutefois, si vous ne souhaitez pas conserver les données, vous pouvez supprimer le compte de stockage que vous avez créé.
Vous pouvez également supprimer l’intégralité du groupe de ressources que vous avez créé pour ce tutoriel. Ce processus supprime le compte de stockage et la fabrique de données Azure Data Factory que vous avez créés.
Supprimer le groupe de ressources
Connectez-vous au Portail Azure.
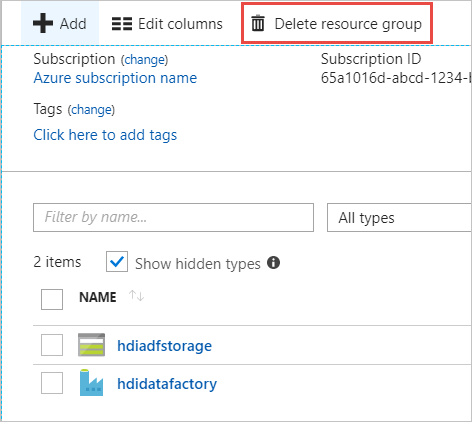
Sélectionnez Groupes de ressources dans le volet de gauche.
Sélectionnez le nom du groupe de ressources que vous avez créé dans votre script PowerShell. Utilisez le filtre si la liste des groupes de ressources est trop longue. Le groupe de ressources s’ouvre.
Dans la mosaïque Ressources, vous devez voir le compte de stockage par défaut et la fabrique de données, sauf si vous partagez le groupe de ressources avec d’autres projets.
Sélectionnez Supprimer le groupe de ressources. Ce faisant, vous supprimez le compte de stockage et les données stockées dans ce dernier.
Entrez le nom du groupe de ressources pour confirmer la suppression, puis sélectionnez Supprimer.
Étapes suivantes
Dans cet article, vous avez appris à utiliser Azure Data Factory pour créer un cluster HDInsight à la demande et exécuter des travaux Apache Hive. Passez à l’article suivant pour apprendre à créer des clusters HDInsight avec une configuration personnalisée.
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour