Créer des travaux et des données d’entrée pour les points de terminaison de lot
Les points de terminaison de lot vous permettent d’effectuer de longues opérations de traitement par lots sur de grandes quantités de données. Les données peuvent être situées à différents endroits, par exemple dans des régions dispersées. Certains types de points de terminaison de lot peuvent également recevoir des paramètres de littéraux en tant qu’entrées.
Cet article explique comment spécifier des entrées de paramètres pour les points de terminaison de lot et créer des travaux de déploiement. Le processus prend en charge l’utilisation de différents types de données. Pour obtenir des exemples, consultez Présentation des entrées et sorties.
Prérequis
Pour appeler un point de terminaison de lot et créer des travaux avec succès, veillez à disposer des prérequis suivants :
Un point de terminaison par lots et un déploiement. Si vous ne disposez pas de ces ressources, consultez Déployer des modèles pour le scoring dans des points de terminaison de lot pour créer un déploiement.
Des autorisations pour exécuter un déploiement de point de terminaison par lots. Les rôles Scientifique des données, Contributeur et Propriétaire AzureML peuvent être utilisés pour exécuter un déploiement. Pour les définitions de rôles personnalisés, consultez Autorisation sur les points de terminaison de lot pour passer en revue les autorisations spécifiques nécessaires.
Un jeton Microsoft Entra ID valide représentant un principal de sécurité pour appeler le point de terminaison. Ce principal peut être un principal d’utilisateur ou un principal de service. Après que vous avez appelé un point de terminaison, Azure Machine Learning crée un travail de déploiement par lots sous l’identité associée au jeton. Vous pouvez utiliser vos propres informations d’identification pour l’appel, comme décrit dans les procédures suivantes.
Utilisez Azure CLI pour vous connecter avec l’authentification interactive ou par code d’appareil :
az loginPour en savoir plus sur la façon de démarrer des travaux de déploiement par lots en utilisant différents types d’informations d’identification, consultez Comment exécuter des travaux à l’aide de différents types d’informations d’identification.
Le cluster de calcul où le point de terminaison est déployé a accès pour lire les données d’entrée.
Conseil
Si vous utilisez un magasin de données sans informations d’identification ou un compte Stockage Azure externe comme entrée de données, veillez à configurer des clusters de calcul pour l’accès aux données. L’identité managée du cluster de calcul est utilisée pour le montage du compte de stockage. L’identité du travail (demandeur) est encore utilisée afin de lire les données sous-jacentes, ce qui vous permet d’obtenir un contrôle d’accès granulaire.
Principes de base pour créer des travaux
Pour créer un travail à partir d’un point de terminaison de lot, vous appelez le point de terminaison. L’appel peut être effectué avec Azure CLI, le kit SDK Azure Machine Learning pour Python, ou un appel d’API REST. Les exemples suivants montrent les principes de base d’un appel de point de terminaison de lot qui reçoit un seul dossier de données d’entrée à traiter. Pour obtenir des exemples avec différentes entrées et sorties, consultez Présentation des entrées et sorties.
Utilisez l’opération invoke sous des points de terminaison de lot :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Appeler un déploiement spécifique
Les points de terminaison par lots peuvent héberger plusieurs déploiements sous le même point de terminaison. Le point de terminaison par défaut est utilisé, sauf si l’utilisateur le spécifie autrement. Vous pouvez changer le déploiement à utiliser avec les procédures suivantes.
Utilisez l’argument --deployment-name ou -d pour spécifier le nom du déploiement :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Configurer les propriétés du travail
Vous pouvez configurer certaines propriétés du travail créé au moment de l’appel.
Remarque
À l’heure actuelle, la capacité à configurer les propriétés du travail n’est disponible que dans les points de terminaison de lot avec les déploiements de composants Pipeline.
Configurer le nom de l’expérience
Appliquez les procédures suivantes pour configurer le nom de l’expérience.
Utilisez l’argument --experiment-name pour spécifier le nom de l’expérience :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Présentation des entrées et des sorties
Les points de terminaison par lots fournissent une API durable que les consommateurs peuvent utiliser pour créer des programmes de traitement par lots. La même interface peut être utilisée pour spécifier les entrées et les sorties attendues par votre déploiement. Utilisez des entrées pour transmettre les informations dont votre point de terminaison a besoin pour effectuer le travail.
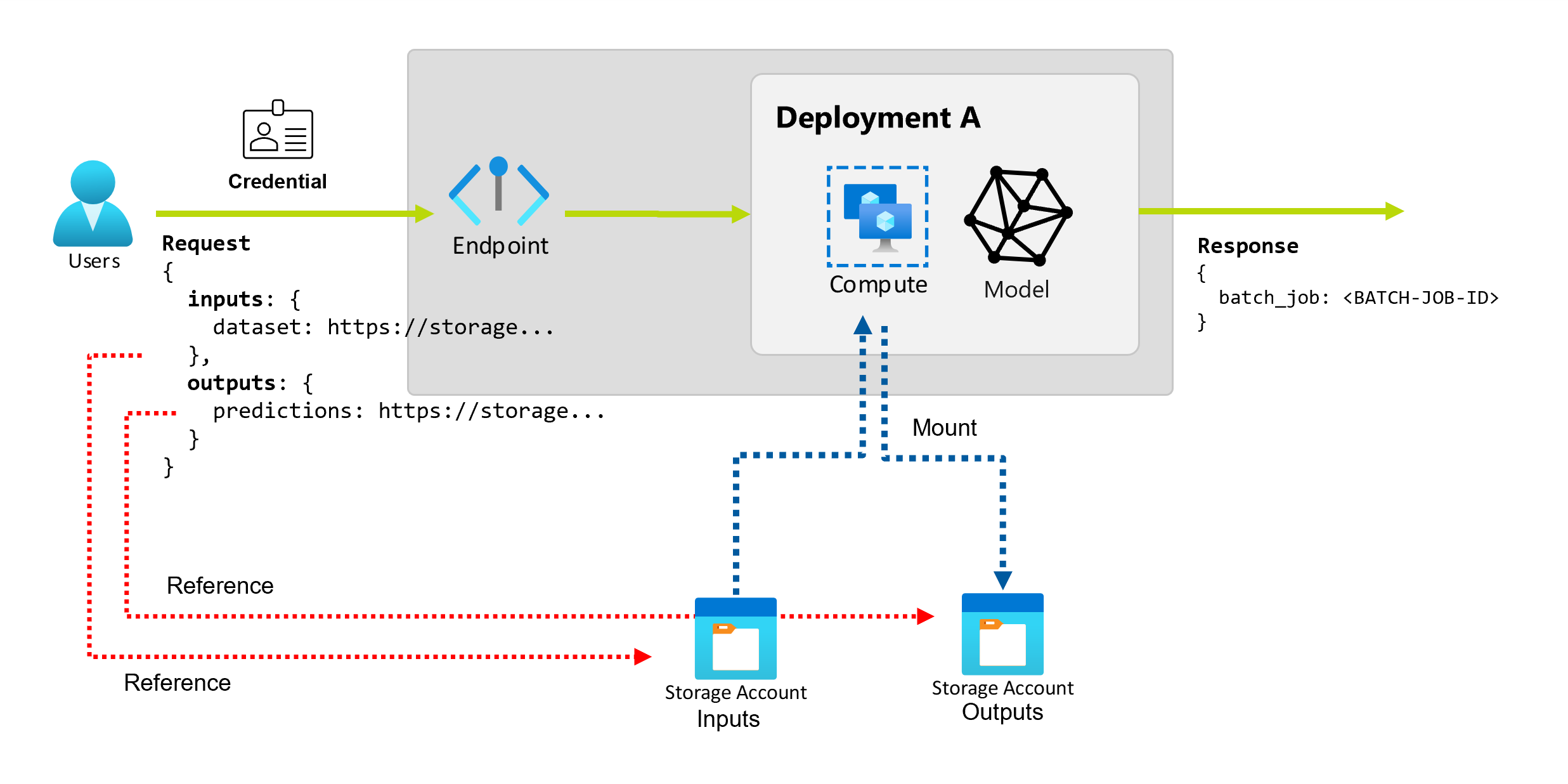
Les points de terminaison par lots prennent en charge deux types d’entrées :
- Entrées de données : pointeurs vers un emplacement de stockage spécifique ou une ressource Azure Machine Learning.
- Entrées littérales : valeurs littérales, comme des nombres ou des chaînes, que vous souhaitez transmettre au travail.
Le nombre et le type d’entrées et de sorties dépendent du type de déploiement par lots. Les modèles de déploiement nécessitent toujours une entrée de données et produisent une sortie de données. Les entrées littérales ne sont pas prises en charge. Toutefois, les déploiements de composants de pipeline fournissent une construction plus générale pour générer des points de terminaison et vous permettent de spécifier n’importe quel nombre d’entrées (données et littérales) et de sorties.
Le tableau suivant récapitule les entrées et sorties pour les déploiements par lots :
| Type de déploiement | Nombre d’entrées | Types d’entrée pris en charge | Nombre de sorties | Types de sortie pris en charge |
|---|---|---|---|---|
| Déploiement de modèle | 1 | Entrées de données | 1 | Sorties de données |
| Déploiement de composant de pipeline | [0..N] | Entrées de données et entrées de littéral | [0..N] | Sorties de données |
Conseil
Les entrées et sorties sont toujours nommées. Les noms servent de clés pour identifier les données et transmettre la valeur réelle lors de l’appel. Étant donné que les modèles de déploiement nécessitent toujours une entrée et une sortie, le nom est ignoré lors de l’appel. Vous pouvez attribuer le nom qui correspond le mieux à votre cas d’usage, par exemple « estimation_ventes ».
Explorer les entrées de données
Les entrées de données désignent les entrées qui pointent vers un emplacement où les données sont placées. Les points de terminaison de lot consommant généralement de grandes quantités de données, vous ne pouvez pas transmettre les données d’entrée dans le cadre de la demande d’appel. Au lieu de cela, vous devez spécifiez l’emplacement où le point de terminaison par lots doit se rendre pour rechercher les données. Les données d’entrée sont montées et diffusées en continu sur le calcul cible pour améliorer les performances.
Les points de terminaison par lots prennent en charge la lecture de fichiers situés dans les emplacements de stockage suivants :
- Ressources de données Azure Machine Learning, y compris dossier (
uri_folder) et fichier (uri_file). - Magasins de données Azure Machine Learning, y compris Stockage Blob Azure, Azure Data Lake Storage Gen1 et Azure Data Lake Storage Gen2.
- Comptes Stockage Azure, y compris Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 et Stockage Blob Azure.
- Fichiers/dossiers de données locales (CLI Azure Machine Learning ou kit de développement logiciel (SDK) Azure Machine Learning pour Python). Toutefois, cette opération entraîne le chargement des données locales dans la banque de données Azure Machine Learning par défaut de l’espace de travail sur lequel vous travaillez.
Important
Note relative à la suppression de fonctionnalités : les jeux de données de type FileDataset (V1) sont déconseillés et seront mis hors service à l’avenir. Les points de terminaison de lot existants qui s’appuient sur cette fonctionnalité continueront de fonctionner. Les points de terminaison de lot créés avec GA CLIv2 (version 2.4.0 et ultérieures) ou l’API REST GA (version 2022-05-01 et ultérieures) ne prendront pas en charge le jeu de données V1.
Explorer les entrées littérales
Les entrées de littéral font référence aux entrées qui peuvent être représentées et résolues au moment de l’appel, telles que les chaînes, les nombres et les valeurs booléennes. Vous utilisez généralement des entrées de littéral pour transmettre des paramètres à votre point de terminaison dans le cadre d’un déploiement de composants de pipeline. Les points de terminaison par lots prennent en charge les types de littéral suivants :
stringbooleanfloatinteger
Les entrées littérales ne sont prises en charge que dans les déploiements de composants de pipeline. Consultez Créer des tâches avec des entrées littérales pour savoir comment les spécifier.
Explorer les sorties de données
Les sorties de données font référence à l’emplacement où les résultats d’un programme de traitement par lots doivent être placés. Chaque sortie a un nom identifiable, et Azure Machine Learning attribue automatiquement un chemin d’accès unique à chaque sortie nommée. Vous pouvez spécifier un autre chemin d’accès, selon les besoins.
Important
Les points de terminaison Batch prennent uniquement en charge l’écriture de sorties dans les magasins de données du Stockage Blob Azure. Si vous devez écrire dans un compte de stockage avec des espaces de noms hiérarchiques activés (également appelé Azure Datalake Gen2 ou ADLS Gen2), vous pouvez inscrire le service de stockage en tant que magasin de données Stockage Blob Azure, car les services sont entièrement compatibles. De cette façon, vous pouvez écrire des sorties de points de terminaison de lot vers ADLS Gen2.
Créer des tâches avec des entrées de données
Les exemples suivants montrent comment créer des tâches et utiliser des entrées de données à partir de ressources de données, magasins de données et comptes de Stockage Azure.
Utiliser des données d’entrée à partir d’une ressource de données
Les ressources de données Azure Machine Learning (anciennement appelées jeux de données) sont prises en charge comme entrées pour les travaux. Effectuez ces étapes pour exécuter un travail de point de terminaison de lot à l’aide de données stockées dans une ressource de données inscrite dans Azure Machine Learning.
Avertissement
Les ressources de données de type Table (MLTable) ne sont actuellement pas prises en charge.
Tout d’abord, créez la ressource de données. Cette ressource de données se compose d’un dossier contenant plusieurs fichiers CSV que vous traitez en parallèle à l’aide de points de terminaison de lot. Vous pouvez ignorer cette étape si vos données sont déjà inscrites en tant que ressource de données.
Créez une définition de ressource de données dans
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataEnsuite, créez la ressource de données :
az ml data create -f heart-dataset-unlabeled.ymlCréez l’entrée ou la requête :
Exécutez le point de terminaison :
Utilisez l’argument
--setpour spécifier l’entrée :az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDPour un point de terminaison qui sert un déploiement de modèle, vous pouvez utiliser l’argument
--inputpour spécifier l’entrée de données, car un déploiement de modèle nécessite toujours une seule entrée de données.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDL’argument
--seta tendance à produire de longues commandes lorsque plusieurs entrées sont spécifiées. Dans ce cas, placez vos entrées dans un fichierYAMLet utilisez l’argument--filepour spécifier les entrées dont vous avez besoin pour l’appel de votre point de terminaison.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestExécutez la commande suivante :
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Utiliser des données d’entrée à partir de magasins de données
Vous pouvez directement référencer des données à partir de magasins de données inscrits auprès d’Azure Machine Learning avec des travaux de déploiements par lots. Dans cet exemple, vous allez d’abord devoir charger des données dans le magasin de données par défaut dans l’espace de travail Azure Machine Learning, puis exécuter un déploiement par lots dessus. Procédez comme suit pour exécuter un travail de point de terminaison par lots à l’aide de données stockées dans une banque de données.
Accédez à la banque de données par défaut dans l’espace de travail Azure Machine Learning. Si vos données se trouvent dans une autre banque, vous pouvez l’utiliser à la place. Il n’est pas obligatoire d’utiliser le magasin de données par défaut.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')L’ID des magasins de données ressemble à
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Conseil
Le magasin de données blob par défaut dans un espace de travail se nomme workspaceblobstore. Vous pouvez ignorer cette étape si vous connaissez déjà l’ID de ressource du magasin de données par défaut dans votre espace de travail.
Chargez des exemples de données dans le magasin de données.
Cet exemple part du principe que vous avez déjà chargé les exemples de données inclus dans le référentiel dans le dossier
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/datadans le dossierheart-disease-uci-unlabeleddu compte Stockage Blob. Veillez à effectuer cette étape avant de poursuivre.Créez l’entrée ou la requête :
Placez le chemin d’accès du fichier dans la variable
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Notez comment la variable
pathsdu chemin d’accès est ajoutée à l’ID de ressource du magasin de données. Ce format indique que la valeur qui suit est un chemin d’accès.Conseil
Vous pouvez également utiliser le format
azureml://datastores/<data-store>/paths/<data-path>pour spécifier l’entrée.Exécutez le point de terminaison :
Utilisez l’argument
--setpour spécifier l’entrée :az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHPour un point de terminaison qui sert un déploiement de modèle, vous pouvez utiliser l’argument
--inputpour spécifier l’entrée de données, car un déploiement de modèle nécessite toujours une seule entrée de données.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderL’argument
--seta tendance à produire de longues commandes lorsque plusieurs entrées sont spécifiées. Dans ce cas, placez vos entrées dans un fichierYAMLet utilisez l’argument--filepour spécifier les entrées dont vous avez besoin pour l’appel de votre point de terminaison.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>Exécutez la commande suivante :
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlSi vos données sont un fichier, utilisez plutôt le type
uri_filepour l’entrée.
Utiliser des données d’entrée à partir de comptes Stockage Azure
Les points de terminaison par lots Azure Machine Learning peuvent lire des données à partir d’emplacements cloud dans les comptes de stockage Azure publics et privés. Effectuez les étapes suivantes pour exécuter un travail de point de terminaison de lot avec des données stockées dans un compte de stockage.
Pour en savoir plus sur la configuration supplémentaire requise pour lire des données à partir de comptes de stockage, consultez Configurer des clusters de calcul pour l’accès aux données.
Créez l’entrée ou la requête :
Définissez la variable
INPUT_DATA:INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Si vos données sont un fichier, définissez la variable au format suivant :
INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Exécutez le point de terminaison :
Utilisez l’argument
--setpour spécifier l’entrée :az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAPour un point de terminaison qui sert un déploiement de modèle, vous pouvez utiliser l’argument
--inputpour spécifier l’entrée de données, car un déploiement de modèle nécessite toujours une seule entrée de données.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderL’argument
--seta tendance à produire de longues commandes lorsque plusieurs entrées sont spécifiées. Dans ce cas, placez vos entrées dans un fichierYAMLet utilisez l’argument--filepour spécifier les entrées dont vous avez besoin pour l’appel de votre point de terminaison.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataExécutez la commande suivante :
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlSi vos données sont un fichier, utilisez plutôt le type
uri_filepour l’entrée.
Créer des tâches avec des entrées littérales
Les déploiements de composants de pipeline prennent en charge les entrées littérales. L’exemple suivant montre comment spécifier une entrée nommée score_mode, de type string, avec la valeur append :
Placez vos entrées dans un fichier YAML et utilisez --file pour spécifier les entrées dont vous avez besoin pour l’appel de votre point de terminaison.
inputs.yml
inputs:
score_mode:
type: string
default: append
Exécutez la commande suivante :
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Vous pouvez également utiliser l’argument --set pour spécifier la valeur. Cette approche a toutefois tendance à produire de longues commandes quand plusieurs entrées sont spécifiées :
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Créer des tâches avec des sorties de données
L’exemple suivant montre comment modifier l’emplacement où une sortie nommée score est placée. À des fins d’exhaustivité, ces exemples configurent également une entrée nommée heart_dataset.
Enregistrez la sortie à l’aide du magasin de données par défaut dans l’espace de travail Azure Machine Learning. Vous pouvez utiliser n’importe quel autre magasin de données dans votre espace de travail, tant qu’il s’agit d’un compte Stockage Blob.
Créez une sortie de données :
Définissez la variable
OUTPUT_PATH:DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"À des fins d’exhaustivité, créez également une entrée de données :
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Remarque
Notez comment la variable
pathsdu chemin d’accès est ajoutée à l’ID de ressource du magasin de données. Ce format indique que la valeur qui suit est un chemin d’accès.Exécutez le déploiement :