Tutoriel : Corriger un ensemble de compétences en utilisant des sessions de débogage
Dans Recherche Azure AI, un ensemble de compétences coordonne les actions des compétences qui analysent, transforment ou créent du contenu pouvant faire l’objet d’une recherche. Souvent, la sortie d’une compétence devient l’entrée d’une autre. Lorsque les entrées sont tributaires des sorties, les erreurs dans les définitions des ensembles de compétences et les associations de champs peuvent se traduire par des données et des opérations omises.
Sessions de débogage est un outil du portail Azure qui fournit une visualisation holistique d’un ensemble de compétences qui s’exécute dans Recherche Azure AI. À l’aide de cet outil, vous pouvez atteindre des étapes spécifiques dans le but de découvrir facilement où peut se situer l’échec d’une action.
Dans cet article, utilisez des sessions de débogage pour rechercher et corriger des entrées et des sorties manquantes. Le tutoriel est complet. Il fournit des exemples de données, un fichier REST qui crée des objets et des instructions pour le débogage des problèmes dans l’ensemble de compétences.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Azure AI Search. Créez un service ou recherchez un service existant dans votre abonnement actuel. Vous pouvez utiliser un service gratuit pour ce tutoriel. Le niveau gratuit ne fournit pas de prise en charge des identités managées pour un service Recherche Azure AI. Vous devez utiliser des clés pour les connexions à Stockage Azure.
Compte de stockage Azure avec Stockage Blob, utilisé pour héberger des exemples de données et rendre persistantes les données mises en cache créées pendant une session de débogage. Si vous utilisez un service de recherche gratuit, le compte de stockage doit avoir des clés d’accès partagé activées et il doit autoriser l’accès au réseau public.
Visual Studio Code avec un client REST.
Exemple de fichier de debug-sessions.rest utilisé pour créer le pipeline d’enrichissement.
Remarque
Ce didacticiel utilise également Azure AI Services pour la détection de langue, la reconnaissance d’entité et l’extraction d’expressions clés. Comme la charge de travail est faible, Azure AI Services est utilisé en arrière-plan pour traiter gratuitement jusqu’à 20 transactions. Cela signifie que vous pouvez effectuer cet exercice sans avoir à créer une ressource Azure AI Services facturable.
Configurer les exemples de données
Cette section crée l’exemple de jeu de données dans le service Stockage Blob Azure pour permettre à l’indexeur et à l’ensemble de compétences de disposer d’un contenu à utiliser.
Téléchargez l’exemple de données (clinical-trials-pdf-19) composé de 19 fichiers.
Créez un compte de stockage Azure ou recherchez un compte existant.
Choisissez la même région que celle de la Recherche Azure AI pour éviter des frais de bande passante.
Il doit être de type StorageV2 (V2 universel).
Accédez aux pages des services du Stockage Azure dans le portail, et créez un conteneur de blobs. Une bonne pratique consiste à spécifier le niveau d’accès «privé ». Nommez votre conteneur
clinicaltrialdataset.Dans le conteneur, sélectionnez Charger pour charger les exemples de fichiers que vous avez téléchargés et décompressés au cours de la première étape.
Dans le portail, copiez la chaîne de connexion pour Stockage Azure. Vous pouvez obtenir la chaîne de connexion à partir de Paramètres>Clés d’accès dans le portail.
Copier une clé et une URL
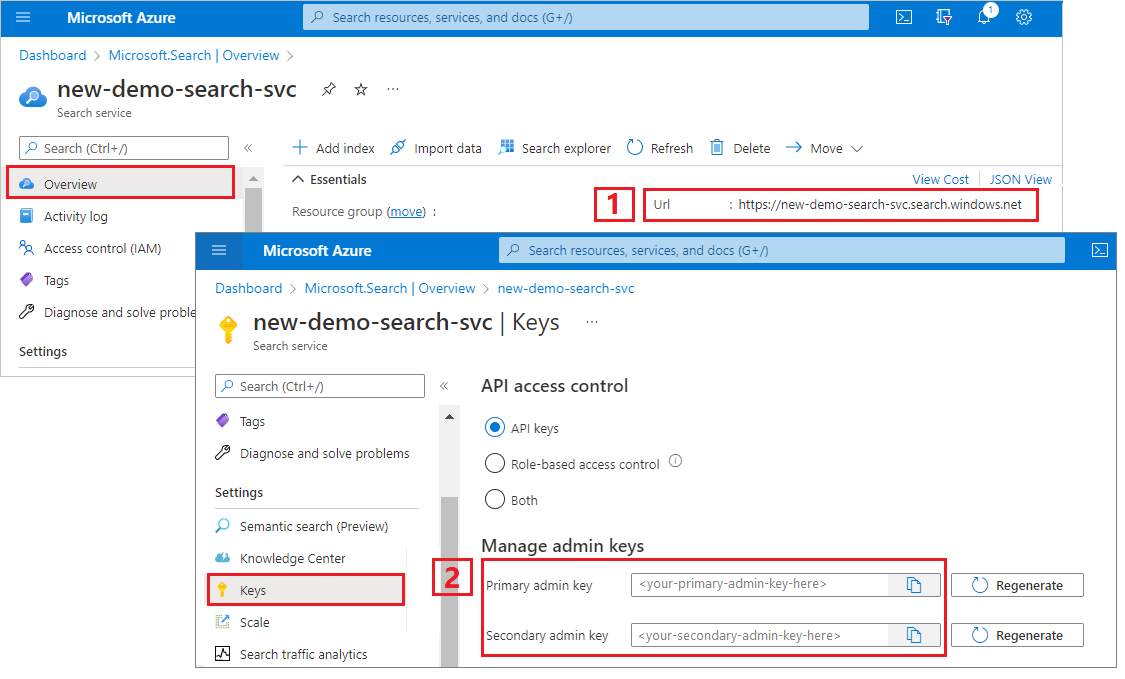
Ce tutoriel utilise des clés API pour l’authentification et l’autorisation. Vous avez besoin du point de terminaison du service de recherche et d’une clé API, que vous pouvez obtenir auprès du portail Azure.
Connectez-vous au portail Azure, accédez à la page Vue d’ensemble et copiez l’URL. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Sous Paramètres>Clés, copiez une clé d’administration. Les clés d’administration sont utilisées pour ajouter, modifier et supprimer des objets. Il existe deux clés d’administration interchangeables. Copiez l’une ou l’autre.
Une clé d’API valide permet d’établir, en fonction de chaque requête, une relation de confiance entre l’application qui envoie la requête et le service de recherche qui en assure le traitement.
Créer une source de données, un ensemble de compétences, un index et un indexeur
Dans cette section, créez un flux de travail « buggy » que vous pouvez corriger dans ce tutoriel.
Démarrez Visual Studio Code et ouvrez le fichier
debug-sessions.rest.Fournissez les variables suivantes : URL du service de recherche, clé API d’administration des services de recherche, chaîne de connexion de stockage et nom du conteneur d’objets blob stockant les fichiers PDF.
Envoyez à son tour chaque requête. La création de l’indexeur prend plusieurs minutes.
Fermez le fichier .
Contrôler les résultats sur le portail
L’exemple de code crée délibérément un index incorrect à la suite de problèmes qui se sont produits lors de l’exécution d’un ensemble de compétences. Le problème est que l’index manque de données.
Dans la page Vue d’ensemble du service de recherche dans le portail Azure, sélectionnez l’onglet Index.
Sélectionnez clinical-trials.
Entrez cette chaîne de requête JSON dans la vue JSON de l’Explorateur de recherche. Elle renvoie des champs pour des documents spécifiques (identifiés par le champ unique
metadata_storage_path)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueExécutez la requête. Vous devez voir des valeurs vides pour
organizationsetlocations.Ces champs auraient dû être remplis à l’aide de la compétence de reconnaissance d’entité de l’ensemble de compétences ; celle-ci est utilisée pour détecter des organisations et des emplacements n’importe où dans le contenu du blob. Dans l’exercice suivant, vous déboguez l’ensemble de compétences pour déterminer la cause du problème.
Vous pouvez également investiguer les erreurs et les avertissements en utilisant le portail Azure.
Ouvrez l’onglet Indexeurs et sélectionnez clinical-trials-idxr.
Remarquez que, même si le travail de l’indexeur a été globalement accompli avec succès, il y a eu des avertissements.
Cliquez sur Réussite pour afficher les avertissements (s’il y avait eu principalement des erreurs, le lien des détails serait libellé Échec). Vous voyez une liste exhaustive de tous les avertissements émis par l’indexeur.

Démarrer votre session de débogage
Dans le volet de navigation gauche du service de recherche, sous Gestion de la recherche, sélectionnez Sessions de débogage.
Sélectionnez + Ajouter une session de débogage.
Donnez un nom à la session.
Dans le modèle Indexeur, indiquez le nom de l’indexeur. L’indexeur a des références à la source de données, à l’ensemble de compétences et à l’index.
Sélectionnez le compte de stockage.
Enregistrez la session.

Une session de débogage s’ouvre sur la page des paramètres. Vous pouvez apporter des modifications à la configuration initiale et remplacer les valeurs par défaut. Une session de débogage ne fonctionne qu’avec un seul document. Le comportement par défaut est d’accepter le premier document de la collection comme base de vos sessions de débogage. Vous pouvez choisir un document spécifique à déboguer en fournissant son URI dans Stockage Azure.
Quand l’initialisation de la session de débogage est terminée, vous devez voir un workflow de compétences avec des mappages et un index de recherche. La structure de données du document enrichi apparaît dans un volet d’informations sur le côté. Nous l’avons exclu de la capture d’écran suivante pour vous permettre de voir une plus grande partie du workflow.
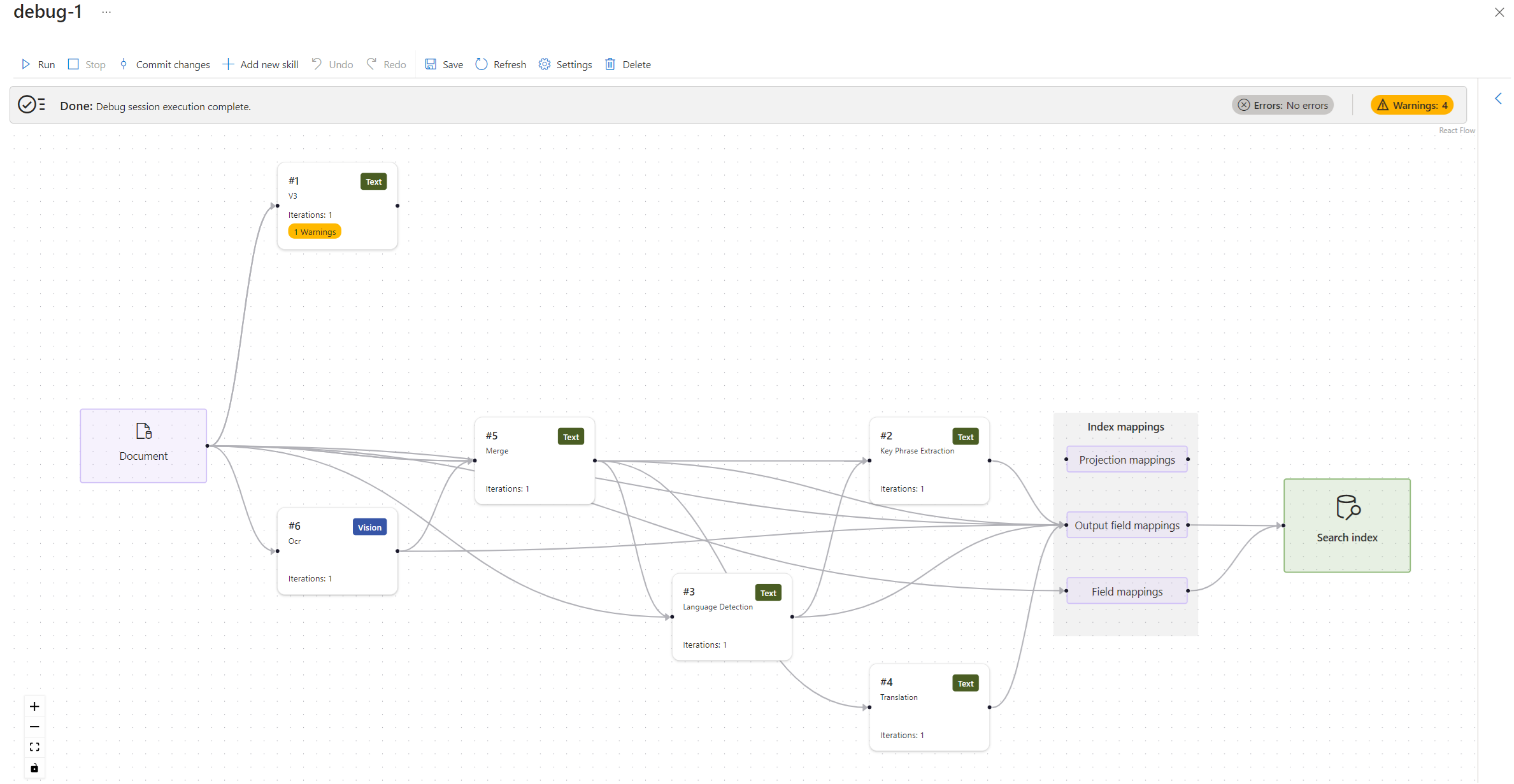


Trouver les problèmes liés à l’ensemble de compétences
Les problèmes signalés par l’indexeur sont indiqués sous forme d’Erreurs et d’Avertissements.
Notez que le nombre d’erreurs et d’avertissements est une liste bien plus petite que celle affichée précédemment, car elle comprend seulement les erreurs d’un seul document. Comme avec la liste affichée par l’indexeur, vous pouvez sélectionner un message d’avertissement pour voir les détails le concernant.
Sélectionnez Avertissements pour passer en revue les notifications. Vous devriez en voir quatre :
« Impossible d’exécuter la compétence parce qu’une ou plusieurs entrées de compétence ne sont pas valides. L’entrée de compétence requise est manquante. Nom : ’texte’, Source : ’/document/contenu'. »
« Impossible de mapper le champ de sortie "locations" à l’index de recherche. Vérifiez la propriété outputFieldMappings de votre indexeur. Valeur /document/merged_content/locations manquante ».
« Impossible de mapper le champ de sortie "organizations" à l’index de recherche. Vérifiez la propriété outputFieldMappings de votre indexeur. Valeur /document/merged_content/organizations manquante ».
« Compétence exécutée mais susceptible de présenter des résultats inattendus, car une ou plusieurs entrées de compétence ne sont pas valides. L’entrée de compétence facultative est manquante. Nom : languageCode, Source : /document/languageCode. Problèmes d’analyse de la langue d’expression : Valeur /document/languageCode manquante ».
Nombreuses sont les compétences assorties d’un paramètre « languageCode ». En examinant l’opération, vous pouvez voir que cette entrée du code de langue est absente de EntityRecognitionSkill.#1, qui est la même compétence de reconnaissance d’entités que celle qui rencontre des problèmes avec les sorties « locations » (emplacements) et « organizations » (organisations).
Étant donné que les quatre notifications se rapportent à cette compétence, l’étape suivante consiste à déboguer cette compétence. Dans la mesure du possible, commencez par résoudre les problèmes d’entrée avant de passer aux problèmes de sortie.
Corriger les valeurs d’entrée de compétence manquantes
Dans la surface de travail, sélectionnez la compétence qui signale les avertissements. Dans ce tutoriel, c’est la compétence de reconnaissance d’entités.
Le volet Détails de la compétence s’ouvre à droite avec des sections pour les itérations et leurs entrées et sorties respectives, les paramètres de la compétence pour la définition JSON de la compétence, et des messages pour les erreurs et avertissements émis par cette compétence.

Pointez sur chaque entrée (ou sélectionnez une entrée) pour afficher les valeurs dans l’Évaluateur d’expression. Le résultat affiché pour cette entrée ne ressemble pas à une entrée texte. Il ressemble plutôt à une série de caractères de nouvelle ligne
\n \n\n\n\n. L’absence de texte signifie qu’aucune entité ne peut être identifiée, de sorte que ce document ne répond pas aux conditions préalables de la compétence, ou qu’il existe une autre entrée qui devrait être utilisée à la place.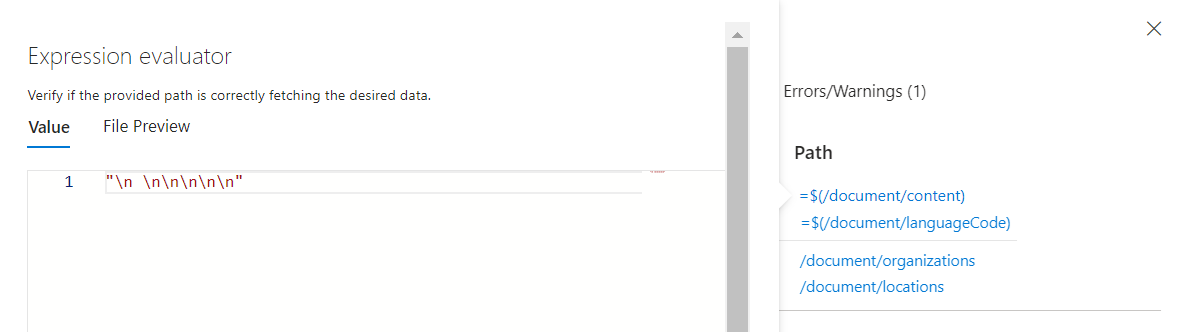
Revenez à Structure de données enrichie et passez en revue les nœuds d’enrichissement pour ce document. Notez que le
\n \n\n\n\npour « content » n’a pas de source d’origine, mais qu’une autre valeur pour « merged_content » a une sortie OCR. Bien qu’il n’y ait aucune indication, le contenu de ce fichier PDF semble être un fichier JPEG, comme le montre le texte extrait et traité dans « merged_content ».
Revenez à la compétence et sélectionnez Paramètres de l’ensemble de compétences pour ouvrir la définition JSON.
Remplacez l’expression
/document/contentpar/document/merged_content, puis sélectionnez Enregistrer. Notez que l’avertissement n’apparaît plus.
Cliquez sur Exécuter dans le menu Fenêtre de la session. Ceci lance une autre exécution de l’ensemble de compétences en utilisant le document.
Une fois l’exécution de la session de débogage terminée, notez que le nombre d’avertissements a été réduit d’une unité. Les avertissements indiquent que l’erreur d’entrée de texte a disparu, mais les autres avertissements demeurent. L’étape suivante consiste à traiter l’avertissement concernant la valeur de
/document/languageCodemanquante ou vide.
Sélectionnez la compétence et pointez sur
/document/languageCode. La valeur de cette entrée est null, qui n’est pas une entrée valide.Comme avec le problème précédent, commencez par examiner la structure de données enrichie pour trouver des indications de ses nœuds. Notez qu’il n’existe pas de nœud « languageCode », mais qu’il en existe un pour « language ». Par conséquent, il y a une faute de frappe dans les paramètres des compétences.
Copiez l’expression
/document/language.Dans le volet Détails de la compétence, sélectionnez Paramètres de compétence pour la compétence #1, puis collez la nouvelle valeur,
/document/language.Cliquez sur Enregistrer.
Sélectionnez Exécuter.
Une fois l’exécution de la session de débogage terminée, vous pouvez vérifier les résultats dans le volet Détails de la compétence. Quand vous pointez sur
/document/language, vous devez voirencomme valeur dans l’Évaluateur d’expression.
Notez que les avertissements d’entrée ont disparu. Il ne reste désormais plus que les deux avertissements sur les champs de sortie pour les organisations et les localisations.
Remédier aux valeurs de sortie de compétence manquantes
Les messages indiquent de vérifier la propriété « outputFieldMappings » de votre indexeur. Faisons donc cela.
Sélectionnez Mappages de champs de sortie dans la surface de travail. Notez que les mappages de champs de sortie sont manquants.

Pour commencer, vérifiez que l’index de recherche comporte les champs attendus. Dans le cas présent, l’index comporte des champs pour « locations » et « organizations ».
S’il n’y a aucun problème avec l’index, l’étape suivante consiste à vérifier les sorties de la compétence. Comme précédemment, sélectionnez la Structure de données enrichie, puis faites défiler les nœuds pour trouver « locations » et « organizations ». Notez que le parent est « content » au lieu de « merged_content ». Le contexte est incorrect.
Revenez au volet Détails de la compétence pour la compétence de reconnaissance d’entités.
Dans Paramètres de la compétence, remplacez
contextpardocument/merged_content. À ce stade, vous devez avoir trois modifications apportées à la définition de la compétence.
Cliquez sur Enregistrer.
Sélectionnez Exécuter.
Toutes les erreurs ont été résolues.
Valider les changements apportés à l’ensemble de compétences
Quand la session de débogage a été lancée, le service de recherche a créé une copie de l’ensemble de compétences. Cette opération a été effectuée pour protéger l’ensemble de compétences d’origine de votre service de recherche. Maintenant que vous avez terminé le débogage de votre ensemble de compétences, les correctifs peuvent être validés (remplacez l’ensemble de compétences d’origine).
Si vous n’êtes pas prêt à valider les modifications, vous pouvez également enregistrer la session de débogage et la rouvrir ultérieurement.
Sélectionnez Valider les changements dans le menu principal Sessions de débogage.
Sélectionnez OK pour vérifier que vous souhaitez mettre à jour votre ensemble de compétences.
Fermez la session Debug et ouvrez Indexers à partir du volet de navigation gauche.
Sélectionnez « clinical-trials-idxr ».
Sélectionnez Réinitialiser.
Sélectionnez Exécuter.
Sélectionnez Actualiser pour afficher les états des commandes de réinitialisation et d’exécution.
Une fois l’exécution de l’indexeur terminée, une coche verte et le mot « Réussite » doivent s’afficher en regard de l’horodatage de la dernière exécution, sous l’onglet Historique d’exécution. Pour vérifier que les changements ont été appliqués :
Dans le volet de navigation gauche, ouvrez Index.
Sélectionnez l’index « clinical-trials », puis sous l’onglet Explorateur de recherche, entrez la chaîne de requête
$select=metadata_storage_path, organizations, locations&$count=truepour retourner les champs de documents spécifiques (identifiés par le champmetadata_storage_pathunique).Sélectionnez Recherche.
Les résultats doivent indiquer que les organisations et les localisations sont maintenant renseignées avec les valeurs attendues.
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est recommandé, à la fin de chaque projet, de déterminer si vous avez toujours besoin des ressources que vous avez créées. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources une par une, ou choisir de supprimer le groupe de ressources afin de supprimer l’ensemble des ressources.
Vous pouvez rechercher et gérer les ressources dans le portail à l’aide des liens Toutes les ressources ou Groupes de ressources situés dans le volet de navigation de gauche.
Le service gratuit est limité à trois index, indexeurs et sources de données. Vous pouvez supprimer des éléments un par un dans le portail pour ne pas dépasser la limite.
Étapes suivantes
Ce tutoriel a abordé différents aspects de la définition et du traitement de l’ensemble de compétences. Pour en savoir plus sur les concepts et les workflows, consultez les articles suivants :